ES的分词
1.什么是分析
分析是在文档被发送并加入倒排索引之前,Elasticsearch在其主体上进行的操作。一般会经历下面几个阶段。
字符过滤:使用字符串过滤器转变字符串。
文本切分为分词:将文本切分为单个或多个分词。
分词过滤:使用分词过滤器转变每个分词。
分词索引:将这些分词存储到索引中。
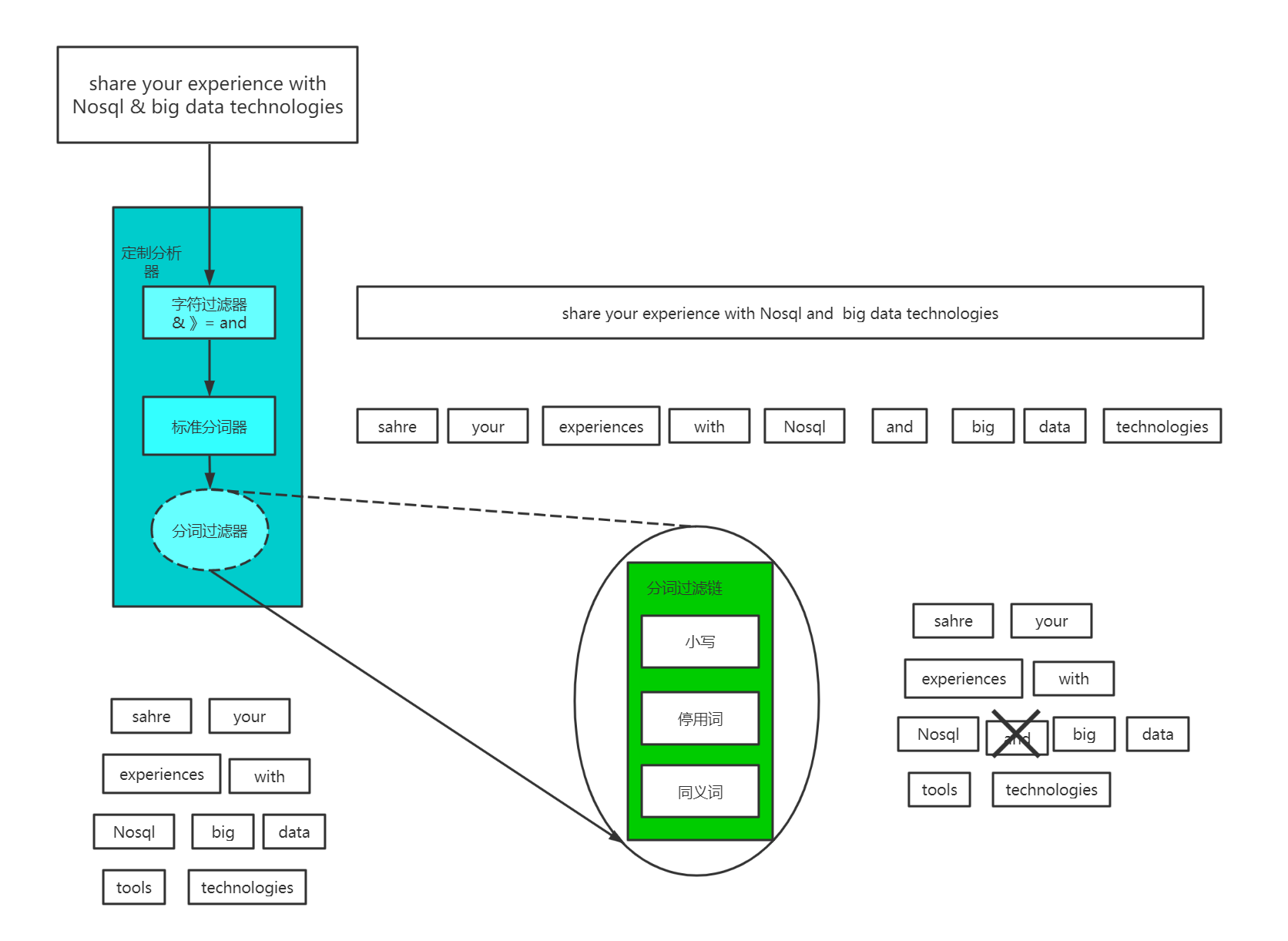
1、character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
2、tokenizer:分词,hello you and me --> hello, you, and, me
3、token filter:lowercase,stop word,synonymom,dogs --> dog,liked --> like,Tom --> tom,a/the/an --> 干掉,mother --> mom,small --> little
stop word 停用词: 了 的 呢。
字符过滤
Elasticsearch首先运行字符过滤器。这些过滤器将特定的字符序列转变为其他的字符序列。这个可以用于将HTML从文本中剥离,或者是将任意数量的字符转化为
其他字符(也许是将“I love u 2”这种缩写的短消息纠正为“I love you too”)。
切分为分词
在应用了字符过滤器之后,文本需要被分割为可以操作的片段。Lucene自己不会对大块的字符串数据进行操作。相反,它处理的是被称为分词的数据。分词是从文本片段生成的,可能会产生任意数量(甚至是0)的分词。例如,在英文中一个通用的分词是标准分词器,它根据空格,换行和破折号等其他字符,将文本切割为分词。
分词过滤器
一旦文本块被转换为分词,Elasticsearch将会对每个分词运用分词过滤器(token filter)。这些分词过滤器可以将一个分词作为输人,然后根据需要进行修改,添加或者是删除。最为有用的和常用的分司过滤器是小写分词过滤器,它将输人的分词变为小写,确保在搜索词条“nosql”的时候,可以发现关于“NoSql”的聚会。分词可以经过多于1个的分词过滤器,每个过滤器对分词进行不同的操作,将数据塑造为最佳的形式,便于之后的索引。
2. 字符过滤
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/analysis-charfilters.html
2.1 HTML Strip Char Filter
请求:
POST /_analyze
{
"tokenizer": "keyword",
"char_filter": [ "html_strip" ],
"text": "<p>I'm so <b>happy</b>!</p>"
}
响应:
{
"tokens": [
{
"token": "
I'm so happy!
",
"start_offset": 0,
"end_offset": 32,
"type": "word",
"position": 0
}
]
}
2.2 Mapping Char Filter
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"٠ => 0",
"١ => 1",
"٢ => 2",
"٣ => 3",
"٤ => 4",
"٥ => 5",
"٦ => 6",
"٧ => 7",
"٨ => 8",
"٩ => 9"
]
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "My license plate is ٢٥٠١٥"
}
响应:
{
"tokens": [
{
"token": "My license plate is 25015",
"start_offset": 0,
"end_offset": 25,
"type": "word",
"position": 0
}
]
}
2.3 Pattern Replace Char Filter
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\d+)-(?=\d)",
"replacement": "$1_"
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "My credit card is 123-456-789"
}
响应:
{
"tokens": [
{
"token": "My",
"start_offset": 0,
"end_offset": 2,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "credit",
"start_offset": 3,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "card",
"start_offset": 10,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "is",
"start_offset": 15,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "123_456_789",
"start_offset": 18,
"end_offset": 29,
"type": "<NUM>",
"position": 4
}
]
}
3.分词
3.1 Word Oriented Tokenizers
3.1.1 Standard Tokenizer
请求:
POST _analyze
{
"tokenizer": "standard",
"text": "The 2 QUICKww Brown-Foxes "
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "<NUM>",
"position": 1
},
{
"token": "QUICKww",
"start_offset": 6,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "Brown",
"start_offset": 14,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "Foxes",
"start_offset": 20,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 4
}
]
}
自定义的时候
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "standard",
"max_token_length": 5
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "The 2 QUICKww Brown-Foxes "
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "<NUM>",
"position": 1
},
{
"token": "QUICK",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "ww",
"start_offset": 11,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "Brown",
"start_offset": 14,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "Foxes",
"start_offset": 20,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 5
}
]
}
注意这里的字符串长度超过5,就被分词了
3.1.2 Letter Tokenizer
字母分词
请求:
POST _analyze
{
"tokenizer": "letter",
"text": "The 2 Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "Brown",
"start_offset": 7,
"end_offset": 12,
"type": "word",
"position": 1
},
{
"token": "Foxes",
"start_offset": 13,
"end_offset": 18,
"type": "word",
"position": 2
},
{
"token": "dog",
"start_offset": 20,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "s",
"start_offset": 24,
"end_offset": 25,
"type": "word",
"position": 4
},
{
"token": "bone",
"start_offset": 26,
"end_offset": 30,
"type": "word",
"position": 5
}
]
}
3.1.3 Lowercase Tokenizer
他是基于上面的字母分词的
请求:
POST _analyze
{
"tokenizer": "lowercase",
"text": "The 2 Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "brown",
"start_offset": 7,
"end_offset": 12,
"type": "word",
"position": 1
},
{
"token": "foxes",
"start_offset": 13,
"end_offset": 18,
"type": "word",
"position": 2
},
{
"token": "dog",
"start_offset": 20,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "s",
"start_offset": 24,
"end_offset": 25,
"type": "word",
"position": 4
},
{
"token": "bone",
"start_offset": 26,
"end_offset": 30,
"type": "word",
"position": 5
}
]
}
3.1.4 Whitespace Tokenizer
请求:
POST _analyze
{
"tokenizer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
响应:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]
3.1.5 UAX URL Email Tokenizer
请求:
POST _analyze
{
"tokenizer": "uax_url_email",
"text": "Email me at john.smith@global-international.com"
}
响应:
[ Email, me, at, john.smith@global-international.com ]
3.2 Partial Word Tokenizers
里面的2个有点分词,就没有进行测试。
3.3 Structured Text Tokenizers
3.3.1 Keyword Tokenizer
请求:
POST _analyze
{
"tokenizer": "keyword",
"text": "New York"
}
响应:
[ New York ]
3.3.2 Pattern Tokenizer
请求:
POST _analyze
{
"tokenizer": "pattern",
"text": "The foo_bar_size's default is 5."
响应:
[ The, foo_bar_size, s, default, is, 5 ]
自定义的匹配
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": ","
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "comma,separated,values"
}
响应:
[ comma, separated, values ]
3.3.3 Simple Pattern Tokenizer
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern",
"pattern": "[0123456789]{3}"
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "fd-786-335-514-x"
}
响应:
[ 786, 335, 514 ]
3.3.4 Char Group Tokenizer
请求:
POST _analyze
{
"tokenizer": {
"type": "char_group",
"tokenize_on_chars": [
"whitespace",
"-",
"
"
]
},
"text": "The QUICK brown-fox"
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "QUICK",
"start_offset": 4,
"end_offset": 9,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 10,
"end_offset": 15,
"type": "word",
"position": 2
},
{
"token": "fox",
"start_offset": 16,
"end_offset": 19,
"type": "word",
"position": 3
}
]
}
3.3.5 Simple Pattern Split Tokenizer
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern_split",
"pattern": "_"
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "an_underscored_phrase"
}
响应:
[ an, underscored, phrase ]
3.3.6 Path Hierarchy Tokenizer
请求:
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/one/two/three"
}
响应:
{
"tokens": [
{
"token": "/one",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "/one/two",
"start_offset": 0,
"end_offset": 8,
"type": "word",
"position": 0
},
{
"token": "/one/two/three",
"start_offset": 0,
"end_offset": 14,
"type": "word",
"position": 0
}
]
}
自定义:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "path_hierarchy",
"delimiter": "-",
"replacement": "/",
"skip": 2
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "one-two-three-four-five"
}
响应:
[ /three, /three/four, /three/four/five ]
4.Token Filters
这个比较简单,具体看官网 https://www.elastic.co/guide/en/elasticsearch/reference/7.4/analysis-tokenfilters.html
5 分词
官网一共有2中推荐,第一种就是自带的,当然也可以自己在上面进行扩展,另外一种就是自己自定义,但是类型要自定成type:custom
5.1 官方自带分词
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引。
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/analysis-analyzers.html

停顿词:
_arabic_, _armenian_, _basque_, _bengali_, _brazilian_, _bulgarian_, _catalan_, _czech_, _danish_, _dutch_, _english_, _finnish_, _french_, _galician_, _german_, _greek_, _hindi_, _hungarian_, _indonesian_, _irish_, _italian_, _latvian_, _norwegian_, _persian_, _portuguese_, _romanian_, _russian_, _sorani_, _spanish_, _swedish_, _thai_, _turkish_.
下面对几大分词进行简单的测试。
5.1.1 Standard Analyzer
请求:
{
"analyzer":"standard",
"text":"hello world"
}
响应:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}
token 实际存储的term 关键字
position 在此词条在原文本中的位置
start_offset/end_offset字符在原始字符串中的位置
5.1.2 Simple Analyzer
它只使用了小写转化分词器,这意味着在非字母处进行分词,并将分词自动转化为小写。
请求:
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog",
"start_offset": 25,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "s",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "bone",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
}
]
}
5.1.3 Whitespace Analyzer
只是根据空白将文本切分成若干分词。
请求:
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 1
},
{
"token": "QUICK",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 2
},
{
"token": "Brown-Foxes",
"start_offset": 12,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog's",
"start_offset": 25,
"end_offset": 30,
"type": "word",
"position": 4
},
{
"token": "bone.",
"start_offset": 31,
"end_offset": 36,
"type": "word",
"position": 5
}
]
}
5.1.4 Stop Analyzer
只是在分词流中额外地过滤了停用词
请求:
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog",
"start_offset": 25,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "s",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "bone",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
}
]
}
如果是自己自定义的话:
PUT /stop_example
{
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"rebuilt_stop": {
"tokenizer": "lowercase",
"filter": [
"english_stop"
]
}
}
}
}
}
POST /stop_example/_analyze
{
"analyzer": "rebuilt_stop",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog",
"start_offset": 25,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "s",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "bone",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
}
]
}
5.1.5 Keyword Analyzer
就是把整个字段当作一个单独的分词。
请求:
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes"
}
响应:
{
"tokens": [
{
"token": "The 2 QUICK Brown-Foxes",
"start_offset": 0,
"end_offset": 23,
"type": "word",
"position": 0
}
]
}
5.1.6 Pattern Analyzer
允许指定一个分词切分的模式。
请求:
PUT /mypattern
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer": {
"type": "pattern",
"pattern": "\W|_",
"lowercase": true
}
}
}
}
}
POST /mypattern/_analyze
{
"analyzer": "my_email_analyzer",
"text": "John_Smith@foo-bar.com"
}
响应:
{
"tokens": [
{
"token": "john",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "smith",
"start_offset": 5,
"end_offset": 10,
"type": "word",
"position": 1
},
{
"token": "foo",
"start_offset": 11,
"end_offset": 14,
"type": "word",
"position": 2
},
{
"token": "bar",
"start_offset": 15,
"end_offset": 18,
"type": "word",
"position": 3
},
{
"token": "com",
"start_offset": 19,
"end_offset": 22,
"type": "word",
"position": 4
}
]
}
5.2 自定义分词
官网说明:自定义的分词中,必须要有一个分词器,其他2个可以有,也可以没有。
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "&_to_and"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
响应:
{
"analyzer": "my_analyzer",
"text": "tom&jerry are a friend in the house, <a>, HAHA!!"
}