1.1 kafka
Kafka最初是由LinkedIn公司采用Scala语言开发的一个多分区、多副本并且基于ZooKeeper协调的分布式消息系统,现在已经捐献给了Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流处理等多种特性而被广泛应用。
Apache Kafka是一个分布式的发布-订阅消息系统,能够支撑海量数据的数据传递。在离线和实时的消息处理业务系统中,Kafka都有广泛的应用。Kafka将消息持久化到磁盘中,并对消息创建了备份保证了数据的安全。Kafka在保证了较高的处理速度的同时,又能保证数据处理的低延迟和数据的零丢失。
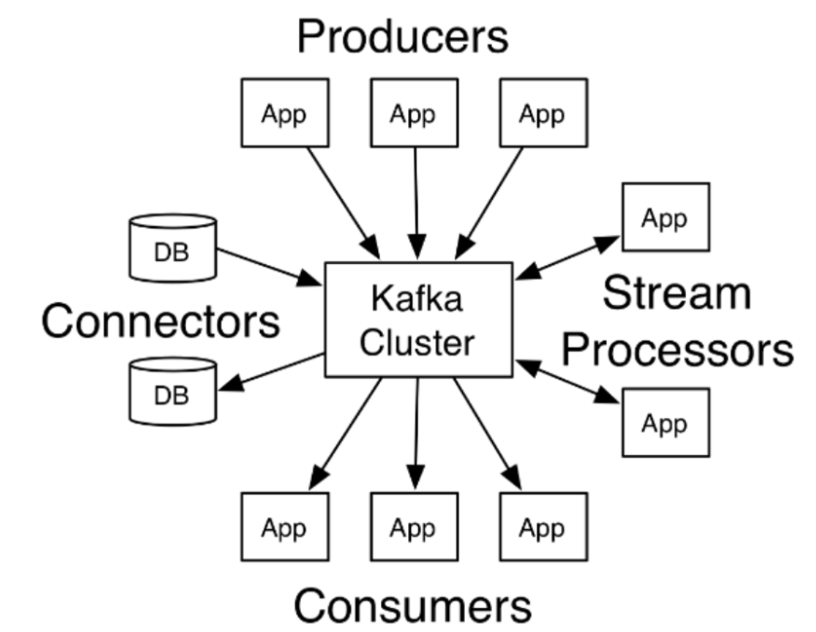
特性
(1)高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个主题可以分多个分区, 消费组对分区进行消费操作;
(2)可扩展性:kafka集群支持热扩展;
(3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
(4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
(5)高并发:支持数千个客户端同时读写;
使用场景
(1)日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等;
(2)消息系统:解耦和生产者和消费者、缓存消息等;
(3)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
(4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
(5)流式处理:比如spark streaming和storm;
技术优势
可伸缩性:
Kafka 的两个重要特性造就了它的可伸缩性。
1、Kafka 集群在运行期间可以轻松地扩展或收缩(可以添加或删除代理),而不会宕机。
2、可以扩展一个 Kafka 主题来包含更多的分区。由于一个分区无法扩展到多个代理,所以它的容量受到代理磁盘空间的限制。能够增加分区和代理的数量意味着单个主题可以存储的数据量是没有限制的。
容错性和可靠性:
Kafka 的设计方式使某个代理的故障能够被集群中的其他代理检测到。由于每个主题都可以在多个代理上复制,所以集群可以在不中断服务的情况下从此类故障中恢复并继续运行。
吞吐量:
代理能够以超快的速度有效地存储和检索数据。
概念详解
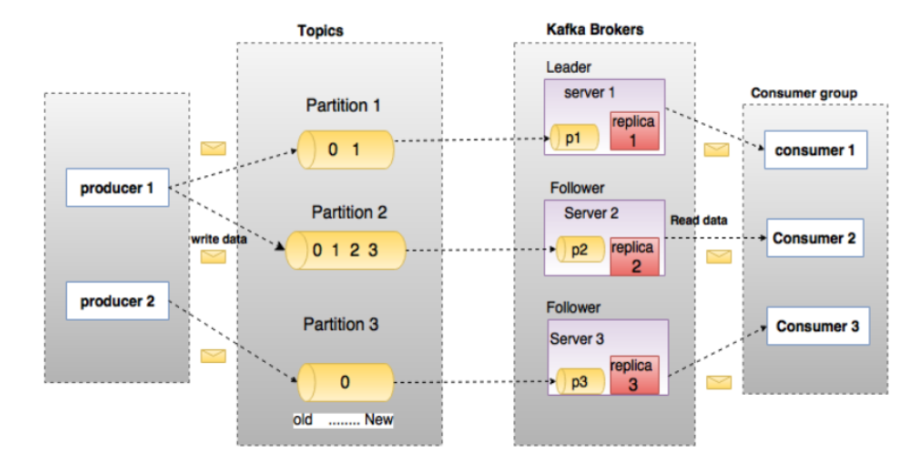
Producer 生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,
broker 将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer 消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。 Topic 在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把Kafka看做 为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。 Partition
topic 中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Partition offset 每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。 Replicas of partition 副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower 的partition中消费数据,而是从为leader的partition中读取数据。副本之间是一主多从的关系。
Broker Kafka 集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Leader 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Zookeeper Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据的发布和订阅任务。
AR(Assigned Replicas) 分区中所有的副本统称为AR。
ISR(In-Sync Replicas) 所有与Leader部分保持一定程度的副(包括Leader副本在内)本组成ISR。
OSR(Out-of-Sync-Replicas) 与Leader副本同步滞后过多的副本。
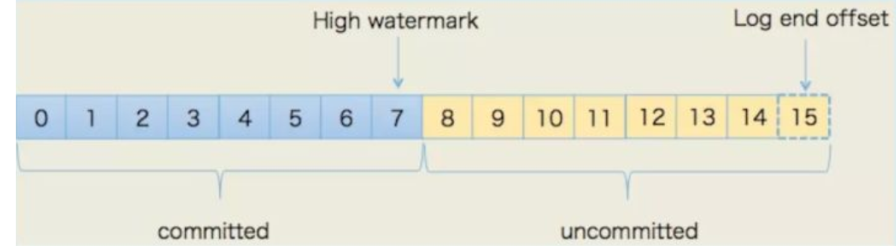
HW(High Watermark) 高水位,标识了一个特定的offset,消费者只能拉取到这个offset之前的消息。
LEO(Log End Offset) 即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。
1.2 安装与配置
1.2.1 java环境
首先需要安装Java环境,同时配置环境变量,步骤如下:
安装openjdk
1.2.2 ZooKeeper 的安装
Zookeeper是安装Kafka集群的必要组件,Kafka通过Zookeeper来实施对元数据信息的管理,包括集群、主题、分区等内容。
同样在官网下载安装包到指定目录解压缩,步骤如下:
ZooKeeper 官网: http://zookeeper.apache.org/
[root@localhost apache-zookeeper-3.5.8-bin]# ll
总用量 32
drwxr-xr-x. 2 root root 232 5月 4 21:26 bin
drwxr-xr-x. 2 root root 70 10月 19 19:55 conf
drwxr-xr-x. 5 root root 4096 5月 4 23:07 docs
drwxr-xr-x. 2 root root 4096 10月 19 19:45 lib
-rw-r--r--. 1 root root 11358 5月 4 21:26 LICENSE.txt
drwxr-xr-x. 2 root root 49 10月 19 19:55 logs
-rw-r--r--. 1 root root 432 5月 4 22:22 NOTICE.txt
-rw-r--r--. 1 root root 1560 5月 4 21:26 README.md
-rw-r--r--. 1 root root 1347 5月 4 21:26 README_packaging.txt
[root@localhost apache-zookeeper-3.5.8-bin]#
修改 Zookeeper的配置文件,首先进入安装路径conf目录,并将zoo_sample.cfg文件修改为zoo.cfg,并对核心参数进行配置。
文件内容如下:
[root@localhost conf]# cat zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/wgr/zookeeper/data
dataLogDir=/wgr/zookeeper/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
[root@localhost conf]#
启动 Zookeeper命令:bin/zkServer.sh start
1.2.3 Kafka的安装与配置
官网下载安装解压缩: http://kafka.apache.org/downloads
[root@localhost kafka_2.13-2.5.1]# ll
总用量 252
drwxr-xr-x. 3 root root 4096 7月 24 08:09 bin
drwxr-xr-x. 2 root root 4096 7月 24 08:09 config
drwxr-xr-x. 2 root root 8192 10月 19 20:02 libs
-rw-r--r--. 1 root root 32216 7月 24 08:05 LICENSE
drwxr-xr-x. 2 root root 4096 10月 20 13:08 logs
-rw-------. 1 root root 196340 10月 20 13:48 nohup.out
-rw-r--r--. 1 root root 337 7月 24 08:05 NOTICE
drwxr-xr-x. 2 root root 44 7月 24 08:10 site-docs
[root@localhost kafka_2.13-2.5.1]#
下载解压启动
启动命令:bin/kafka-server-start.sh config/server.properties
server.properties配置中需要关注以下几个参数:
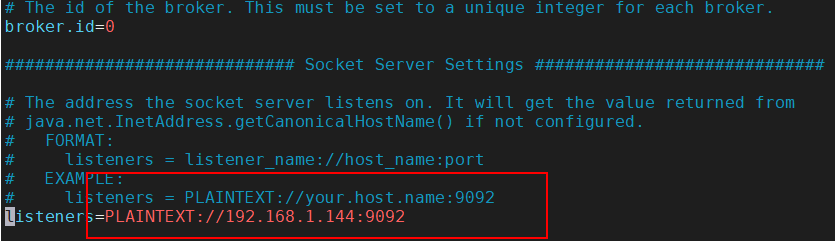
broker.id=0 表示broker的编号,如果集群中有多个broker,则每个broker的编号需要设置的不同
listeners=PLAINTEXT://:9092 brokder对外提供的服务入口地址
log.dirs=/tmp/kafka/log 设置存放消息日志文件的地址
zookeeper.connect=localhost:2181 Kafka所需Zookeeper集群地址,教学中Zookeeper和Kafka都安装本机
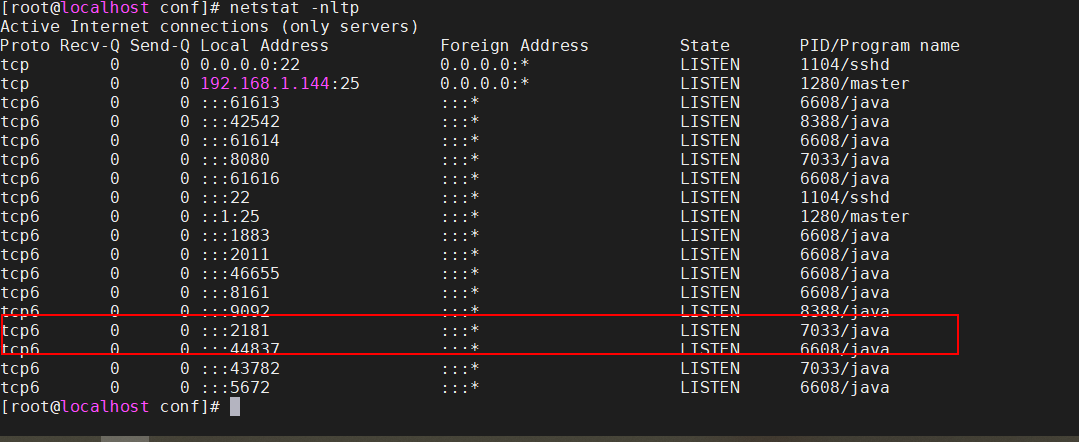
查看进程:
[root@localhost kafka_2.13-2.5.1]# jps -l
6608 /root/apache-activemq-5.14.0//bin/activemq.jar
8388 kafka.Kafka
7033 org.apache.zookeeper.server.quorum.QuorumPeerMain
11770 sun.tools.jps.Jps
[root@localhost kafka_2.13-2.5.1]#
1.2.4 Kafka 测试消息生产与消费
首先创建一个主题
命令如下:
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic wgr --partitions 2 --replication-factor 1
[root@localhost kafka_2.13-2.5.1]# bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic wgr --partitions 2 --replication-factor 1
Created topic wgr.
[root@localhost kafka_2.13-2.5.1]#
--zookeeper:指定了Kafka所连接的Zookeeper服务地址
--topic:指定了所要创建主题的名称
--partitions:指定了分区个数
--replication-factor:指定了副本因子
--create:创建主题的动作指令
展示所有主题
命令:bin/kafka-topics.sh --zookeeper localhost:2181 --list
[root@localhost kafka_2.13-2.5.1]# bin/kafka-topics.sh --zookeeper localhost:2181 --list
__consumer_offsets
dalianpai
wgr
[root@localhost kafka_2.13-2.5.1]#
查看主题详情
命令:bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic wgr
[root@localhost kafka_2.13-2.5.1]# bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic wgr
Topic: wgr PartitionCount: 2 ReplicationFactor: 1 Configs:
Topic: wgr Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: wgr Partition: 1 Leader: 0 Replicas: 0 Isr: 0
[root@localhost kafka_2.13-2.5.1]#
启动消费端接收消息
命令:bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic heima
--bootstrap-server 指定了连接Kafka集群的地址
--topic 指定了消费端订阅的主题
[root@localhost kafka_2.13-2.5.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic dalianpai
wgr
生产端发送消息
命令:bin/kafka-console-producer.sh --broker-list localhost:9092 --topic heima
--broker-list 指定了连接的Kafka集群的地址
--topic 指定了发送消息时的主题
[root@localhost kafka_2.13-2.5.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dalianpai
>wgr
>
1.3 Java第一个程序
通过Java程序来进行Kafka收发消息的教学演示
生产者:
/**
* Kafka 消息生产者
*/
public class ProducerFastStart {
// Kafka集群地址
private static final String brokerList = "192.168.1.144:9092";
// 主题名称-之前已经创建
private static final String topic = "dalianpai";
public static void main(String[] args) {
Properties properties = new Properties();
// 设置key序列化器
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//另外一种写法
//properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 设置重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
// 设置值序列化器
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置集群地址
properties.put("bootstrap.servers", brokerList);
// KafkaProducer 线程安全
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Kafka-demo-001", "hello, Kafka!");
try {
// producer.send(record);
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println("part:" + recordMetadata.partition() + ";topic:" + recordMetadata.topic());
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
}
}
消费者:
/**
* Kafka 消息消费者
*/
public class ConsumerFastStart {
// Kafka集群地址
private static final String brokerList = "192.168.1.144:9092";
// 主题名称-之前已经创建
private static final String topic = "dalianpai";
// 消费组
private static
final String groupId = "group.demo";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("bootstrap.servers", brokerList);
properties.put("group.id", groupId);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}
}
注意要需改配置,不然会报错:Failed to send; nested exception is org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for topic1-0: 30025 ms has passed since batch creation plus linger time
测试结果:

