在单机的Redis的使用下,Redis的分布式锁可以通过Lua进行实现,通过setnx和expire命令连用的方式,但是假如在以下情况下,就会造成无锁的现象。
注:分布式锁能不用就不用,尤其是在高并发的情况下。最近也在学Lua,就是为了和Redis和Nginx做整合,简单的学习一下。
不该释放的锁
但是,直接执行del mylock 是有问题的,我们不能直接执行 del mylock 为什么?—— 会导致 “信号错误”,释放了不该释放的锁 。假设如下场景:
| 时间线 | 线程1 | 线程2 | 线程3 |
|---|---|---|---|
| 时刻1 | 执行 setnx mylock val1 加锁 | 执行 setnx mylock val2 加锁 | 执行 setnx mylock val2 加锁 |
| 时刻2 | 加锁成功 | 加锁失败 | 加锁失败 |
| 时刻3 | 执行任务... | 尝试加锁... | 尝试加锁... |
| 时刻4 | 任务继续(锁超时,自动释放了) | setnx 获得了锁(因为线程1的锁超时释放了) | 仍然尝试加锁... |
| 时刻5 | 任务完毕,del mylock 释放锁 | 执行任务中... | 获得了锁(因为线程1释放了线程2的) |
| ... |
上面的表格中,有两个维度,一个是纵向的时间线,一个是横线的线程并发竞争。我们可以发现线程 1 在开始的时候比较幸运,获得了锁,最先开始执行任务,但是,由于他比较耗时,最后锁超时自动释放了他都还没执行完。 因此,线程 2 和线程3 的机会来了。而这一轮,线程2 比较幸运,得到了锁。可是,当线程2正在执行任务期间,线程1 执行完了,还把线程2的锁给释放了。这就相当于,本来你锁着门在厕所里边尿尿,进行到一半的时候,别人进来了,因为他配了一把和你一模一样的钥匙!这就乱套了啊
因此,我们需要安全的释放锁——“不是我的锁,我不能瞎释放”。所以,我们在加锁的时候,就需要标记“这是我的锁”,在释放的时候在判断 “ 这是不是我的锁?”。这里就需要在释放锁的时候加上逻辑判断,合理的逻辑应该是这样的:
1. 线程1 准备释放锁 , 锁的key 为 mylock 锁的 value 为 thread1_magic_num 2. 查询当前锁 current_value = get mylock 3. 判断 if current_value == thread1_magic_num -- > 是 我(线程1)的锁 else -- >不是 我(线程1)的锁 4. 是我的锁就释放,否则不能释放(而是执行自己的其他逻辑)。
为了实现上面这个逻辑,我们是无法通过 redis 自带的命令直接完成的。如果,再写复杂的代码去控制释放锁,则会让整体代码太过于复杂了。所以,我们引入了lua脚本。结合Lua 脚本实现释放锁的功能,更简单,redis 执行lua脚本也是原子的,所以更合适,让合适的人干合适的事,岂不更好。
Lua实现分布式锁
加锁:
--[[ 思路: 1.用2个局部变量接受参数 2.由于redis内置lua解析器,执行加锁命令 3.如果加锁成功,则设置超时时间 4.返回加锁命令的执行结果 ]] local key = KEYS[1] local value = KEYS[2] local rs1 = redis.call('SETNX',key,value) if rs1 == true then redis.call('SETEX', key,3600, value) end return rs1
解锁:
--[[ 思路: 1.接受redis传来的参数 2.判断是否是自己的锁,是则删掉 3.返回结果值 ]] local key = KEYS[1] local value = KEYS[2] if redis.call('get',key) == value then return redis.call('del',key) else return false end
如此,我们便实现了锁的安全释放。同时,我们还需要结合业务逻辑,进行具体健壮性的保证,比如如果结束了一定不能忘记释放锁,异常了也要释放锁,某种情况下是否需要回滚事务等。总结这个分布式锁使用的过程便是:
- 加锁时 key 同,value 不同。
- 释放锁时,根据value判断,是不是我的锁,不能释放别人的锁。
- 及时释放锁,而不是利用自动超时。
- 锁超时时间一定要结合业务情况权衡,过长,过短都不行。
- 程序异常之处,要捕获,并释放锁。如果需要回滚的,主动做回滚、补偿。保证整体的健壮性,一致性。
用redis做分布式锁真的靠谱吗
上面的文字中,我们讨论如何使用redis作为分布式锁,并讨论了一些细节问题,如锁超时的问题、安全释放锁的问题。目前为止,似乎很完美的解决的我们想要的分布式锁功能。然而事情并没有这么简单,用redis做分布式锁并不“靠谱”。
不靠谱的情况
比如在 Sentinel 集群中,主节点挂掉时,从节点会取而代之,客户端上却并没有明显感知。原先第一个客户端在主节点中申请成功了一把锁,但是这把锁还没有来得及同步到从节点,主节点突然挂掉了。然后从节点变成了主节点,这个新的节点内部没有这个锁,所以当
另一个客户端过来请求加锁时,立即就批准了。这样就会导致系统中同样一把锁被两个客户端同时持有,不安全性由此产生。不过这种不安全也仅仅是在主从发生 failover 的情况下才会产生,而且持续时间极短,业务系统多数情况下可以容忍。
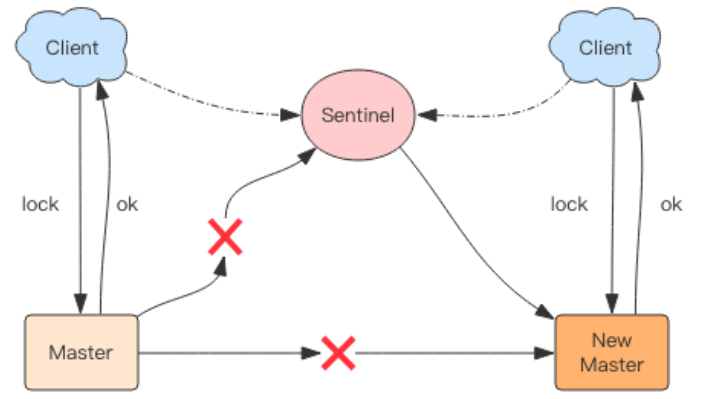
redlock
为了解决故障转移情况下的缺陷,Antirez 发明了 Redlock 算法,使用redlock算法,需要多个redis实例,加锁的时候,它会想多半节点发送 setex mykey myvalue 命令,只要过半节点成功了,那么就算加锁成功了。释放锁的时候需要想所有节点发送del命令。这是一种基于【大多数都同意】的一种机制。感兴趣的可以查询相关资料。在实际工作中使用的时候,我们可以选择已有的开源实现,python有redlock-py,java 中有Redisson redlock。
为了使用 Redlock,需要提供多个 Redis 实例,这些实例之前相互独立没有主从关系。同很多分布式算法一样,redlock 也使用「大多数机制」。
加锁时,它会向过半节点发送 set(key, value, nx=True, ex=xxx) 指令,只要过半节点 set成功,那就认为加锁成功。释放锁时,需要向所有节点发送 del 指令。不过 Redlock 算法还
需要考虑出错重试、时钟漂移等很多细节问题,同时因为 Redlock 需要向多个节点进行读写,意味着相比单实例 Redis 性能会下降一些。
Redlock 使用场景
如果你很在乎高可用性,希望挂了一台 redis 完全不受影响,那就应该考虑 redlock。不过代价也是有的,需要更多的 redis 实例,性能也下降了,代码上还需要引入额外的library,运维上也需要特殊对待,这些都是需要考虑的成本,使用前请再三斟酌