文档
在Elasticsearch中,文档以JSON格式进行存储,可以是复杂的结构,如:
{ "_index": "haoke", "_type": "user", "_id": "1001", "_version": 1, "found": true, "_source": { "id": 1001, "name": "张三", "age": 21, "sex": "女" } }
元数据(metadata)
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:
_index
- 索引(index)类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。
提示:事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分片。
_type
- 在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。每个对象都属于一个类(class),这个类定义了属性或与对象关联的数据。 user 类的对象可能包含姓名、性别、年龄和Email地址。
- 在关系型数据库中,我们经常将相同类的对象存储在一个表里,因为它们有着相同的结构。同理,在Elasticsearch中,我们使用相同类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。
- 每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。
- _type 的名字可以是大写或小写,不能包含下划线或逗号。我们将使用 blog 做为类型名。
_id
- id仅仅是一个字符串,它与 _index 和 _type 组合时,就可以在Elasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义 _id ,也可以让Elasticsearch帮你自动生成(32位长度)。
查询响应
pretty
可以在查询url后面添加pretty参数,使得返回的json更易查看。

指定响应字段
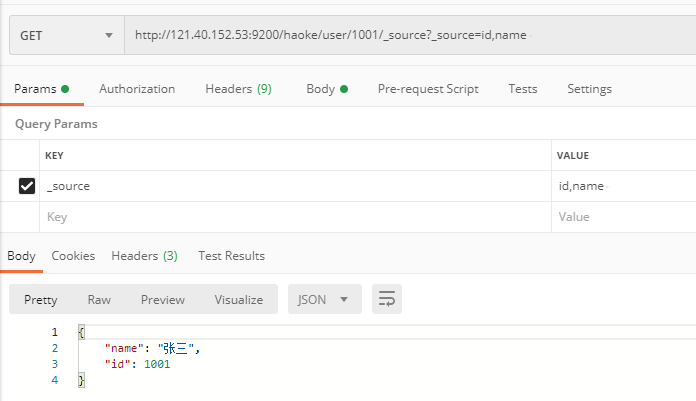
在响应的数据中,如果我们不需要全部的字段,可以指定某些需要的字段进行返回。
http://121.40.152.53:9200/haoke/user/1001?_source=id,name
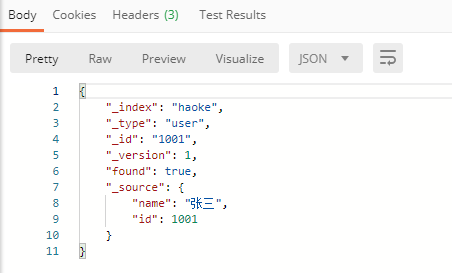
如不需要返回元数据,仅仅返回原始数据,可以这样:
还可这样:
判断文档是否存在
如果我们只需要判断文档是否存在,而不是查询文档内容,那么可以这样:
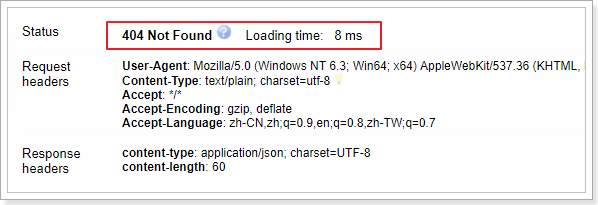
当然,这只表示你在查询的那一刻文档不存在,但并不表示几毫秒后依旧不存在。另一个进程在这期间可能创建新文档。
批量查询
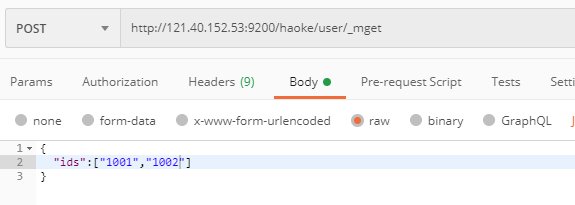
{ "docs": [ { "_index": "haoke", "_type": "user", "_id": "1001", "_version": 1, "found": true, "_source": { "id": 1001, "name": "张三", "age": 21, "sex": "女" } }, { "_index": "haoke", "_type": "user", "_id": "1002", "_version": 1, "found": true, "_source": { "id": 1001, "name": "张三1", "age": 22, "sex": "女" } } ] }
如果,某一条数据不存在,不影响整体响应,需要通过found的值进行判断是否查询到数据。

_bulk操作
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。
请求格式如下:(请求格式不同寻常)

结果:
{ "took": 71, "errors": false, "items": [ { "create": { "_index": "haoke", "_type": "user", "_id": "2001", "_version": 1, "result": "created", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "created": true, "status": 201 } }, { "create": { "_index": "haoke", "_type": "user", "_id": "2002", "_version": 1, "result": "created", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "created": true, "status": 201 } }, { "create": { "_index": "haoke", "_type": "user", "_id": "2003", "_version": 1, "result": "created", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "created": true, "status": 201 } } ] }
批量删除:
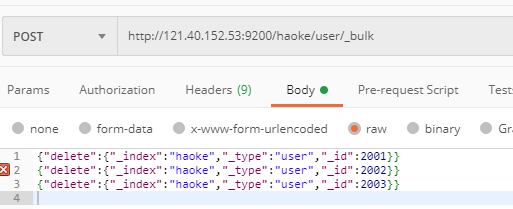
结果:
{ "took": 3, "errors": false, "items": [ { "delete": { "found": true, "_index": "haoke", "_type": "user", "_id": "2001", "_version": 2, "result": "deleted", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "status": 200 } }, { "delete": { "found": true, "_index": "haoke", "_type": "user", "_id": "2002", "_version": 2, "result": "deleted", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "status": 200 } }, { "delete": { "found": true, "_index": "haoke", "_type": "user", "_id": "2003", "_version": 2, "result": "deleted", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "status": 200 } } ] }
一次请求多少性能最高?
整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一
个最佳的bulk请求大小。超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。
幸运的是,这个最佳点(sweetspot)还是容易找到的:试着批量索引标准的文档,随着大小的增长,当性能开始
降低,说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以
使用较小的批次。
通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的
批次最好保持在5-15MB大小间。
分页
和SQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
size: 结果数,默认10 from: 跳过开始的结果数,默认0
http://121.40.152.53:9200/haoke/user/_search?size=2&from=1
{ "took": 1, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1.0, "hits": [ { "_index": "haoke", "_type": "user", "_id": "1002", "_score": 1.0, "_source": { "id": 1001, "name": "张三1", "age": 22, "sex": "女" } }, { "_index": "haoke", "_type": "user", "_id": "1003", "_score": 1.0, "_source": { "id": 1003, "name": "张1", "age": 25, "sex": "女" } } ] } }
映射
前面我们创建的索引以及插入数据,都是由Elasticsearch进行自动判断类型,有些时候我们是需要进行明确字段类型的,否则,自动判断的类型和实际需求是不相符的。
自动判断的规则如下:
| JSON type | Field type |
| Boolean: true or false | "boolean" |
| Whole number: 123 | "long" |
| Floating point: 123.45 | "double" |
| String, valid date: "2014-09-15" | "date" |
| String: "foo bar" | "string" |
Elasticsearch中支持的类型如下:
| 类型 | 表示的数据类型 |
| String | string , text , keyword |
| Whole number | byte , short , integer , long |
| Floating point | float , double |
| Boolean | boolean |
| Date | date |
string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
text 类型,当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型
以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段
不用于排序,很少用于聚合。
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过
滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精
确值搜索到。
http://121.40.152.53:9200/dalianpai
{ "settings": { "index": { "number_of_shards": "2", "number_of_replicas": "0" } }, "mappings": { "person": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "mail": { "type": "keyword" }, "hobby": { "type": "text" } } } } }
查看映射:
http://121.40.152.53:9200/dalianpai/_mapping
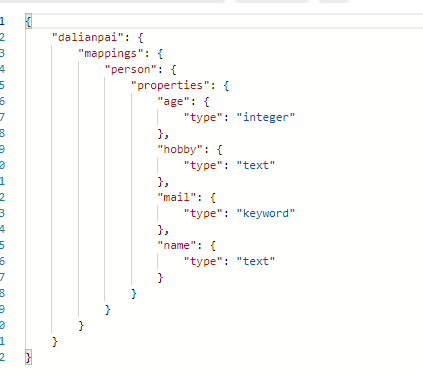
插入数据:
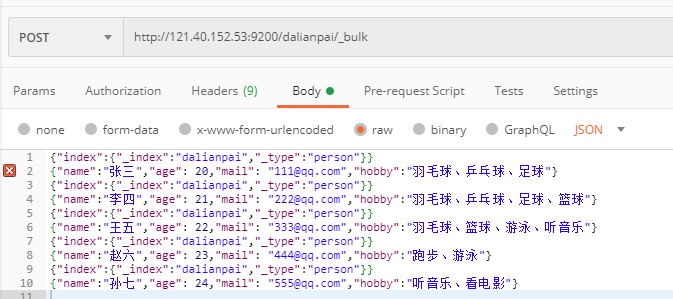
结果:


结果:
{ "took": 10, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1.3773504, "hits": [ { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZhA", "_score": 1.3773504, "_source": { "name": "孙七", "age": 24, "mail": "555@qq.com", "hobby": "听音乐、看电影" } }, { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg-", "_score": 1.1655893, "_source": { "name": "王五", "age": 22, "mail": "333@qq.com", "hobby": "羽毛球、篮球、游泳、听音乐" } } ] } }
term查询
term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型):
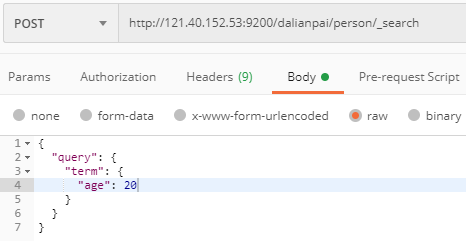
结果:
{ "took": 31, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1.0, "hits": [ { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg8", "_score": 1.0, "_source": { "name": "张三", "age": 20, "mail": "111@qq.com", "hobby": "羽毛球、乒乓球、足球" } } ] } }
terms查询
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:

结果:
{ "took": 2, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1.0, "hits": [ { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg9", "_score": 1.0, "_source": { "name": "李四", "age": 21, "mail": "222@qq.com", "hobby": "羽毛球、乒乓球、足球、篮球" } }, { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg8", "_score": 1.0, "_source": { "name": "张三", "age": 20, "mail": "111@qq.com", "hobby": "羽毛球、乒乓球、足球" } } ] } }
range查询
range 过滤允许我们按照指定范围查找一批数据:
范围操作符包含:
gt :: 大于
gte :: 大于等于
lt :: 小于
lte :: 小于等于
示例:

结果:
{ "took": 4, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1.0, "hits": [ { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg9", "_score": 1.0, "_source": { "name": "李四", "age": 21, "mail": "222@qq.com", "hobby": "羽毛球、乒乓球、足球、篮球" } }, { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg8", "_score": 1.0, "_source": { "name": "张三", "age": 20, "mail": "111@qq.com", "hobby": "羽毛球、乒乓球、足球" } }, { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg-", "_score": 1.0, "_source": { "name": "王五", "age": 22, "mail": "333@qq.com", "hobby": "羽毛球、篮球、游泳、听音乐" } } ] } }
exists 查询
exists 查询可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的 IS_NULL 条件
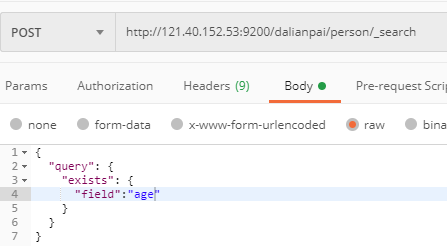
结果:

match查询
match 查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析 match 一下查询字符:
结果:
{ "took": 1, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.25811607, "hits": [ { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg9", "_score": 0.25811607, "_source": { "name": "李四", "age": 21, "mail": "222@qq.com", "hobby": "羽毛球、乒乓球、足球、篮球" } } ] } }
bool查询
bool 查询可以用来合并多个条件查询结果的布尔逻辑,它包含一下操作符:
must :: 多个查询条件的完全匹配,相当于 and 。
must_not :: 多个查询条件的相反匹配,相当于 not 。
should :: 至少有一个查询条件匹配, 相当于 or 。
这些参数可以分别继承一个查询条件或者一个查询条件的数组:
{ "bool": { "must": { "term": { "folder": "inbox" }}, "must_not": { "term": { "tag": "spam" }}, "should": [ { "term": { "starred": true }}, { "term": { "unread": true }} ] } }
过滤查询
Elasticsearch也支持过滤查询,如term、range、match等。
示例:查询年龄为20岁的用户。

结果:
{ "took": 3, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.0, "hits": [ { "_index": "dalianpai", "_type": "person", "_id": "AXFeHQMrEXg1j8gSlZg8", "_score": 0.0, "_source": { "name": "张三", "age": 20, "mail": "111@qq.com", "hobby": "羽毛球、乒乓球、足球" } } ] } }
查询和过滤的对比:
- 一条过滤语句会询问每个文档的字段值是否包含着特定值。
- 查询语句会询问每个文档的字段值与特定值的匹配程度如何。
一条查询语句会计算每个文档与查询语句的相关性,会给出一个相关性评分 _score,并且 按照相关性对匹配到的文档进行排序。 这种评分方式非常适用于一个没有完全配置结果的全文本搜索。
- 一个简单的文档列表,快速匹配运算并存入内存是十分方便的, 每个文档仅需要1个字节。这些缓存的过滤结果集与后续请求的结合使用是非常高效的。
- 查询语句不仅要查找相匹配的文档,还需要计算每个文档的相关性,所以一般来说查询语句要比 过滤语句更耗时,并且查询结果也不可缓存。
建议:做精确匹配搜索时,最好用过滤语句,因为过滤语句可以缓存数据。