Zipkin的概述
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以
解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。 我们可以使用它来收集各个服务
器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助我们查询跟踪数据以实现对分布式系
统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发
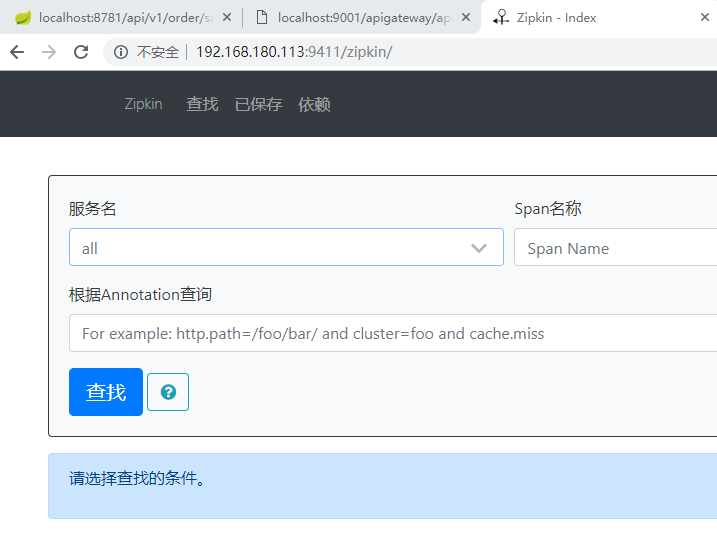
的 API 接口之外,它也提供了方便的 UI 组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比
如:可以查询某段时间内各用户请求的处理时间等。 Zipkin 提供了可插拔数据存储方式:In-
Memory、MySql、Cassandra 以及 Elasticsearch。
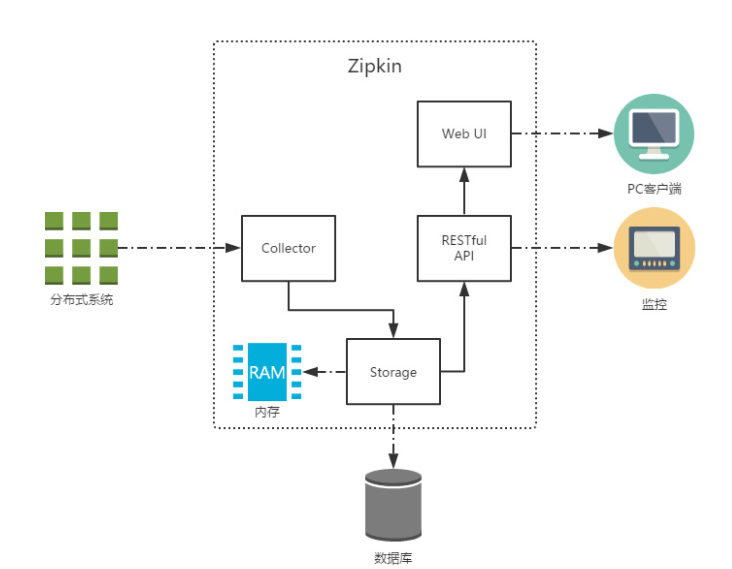
上图展示了 Zipkin 的基础架构,它主要由 4 个核心组件构成:
Collector :收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为
Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
Storage :存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,
我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
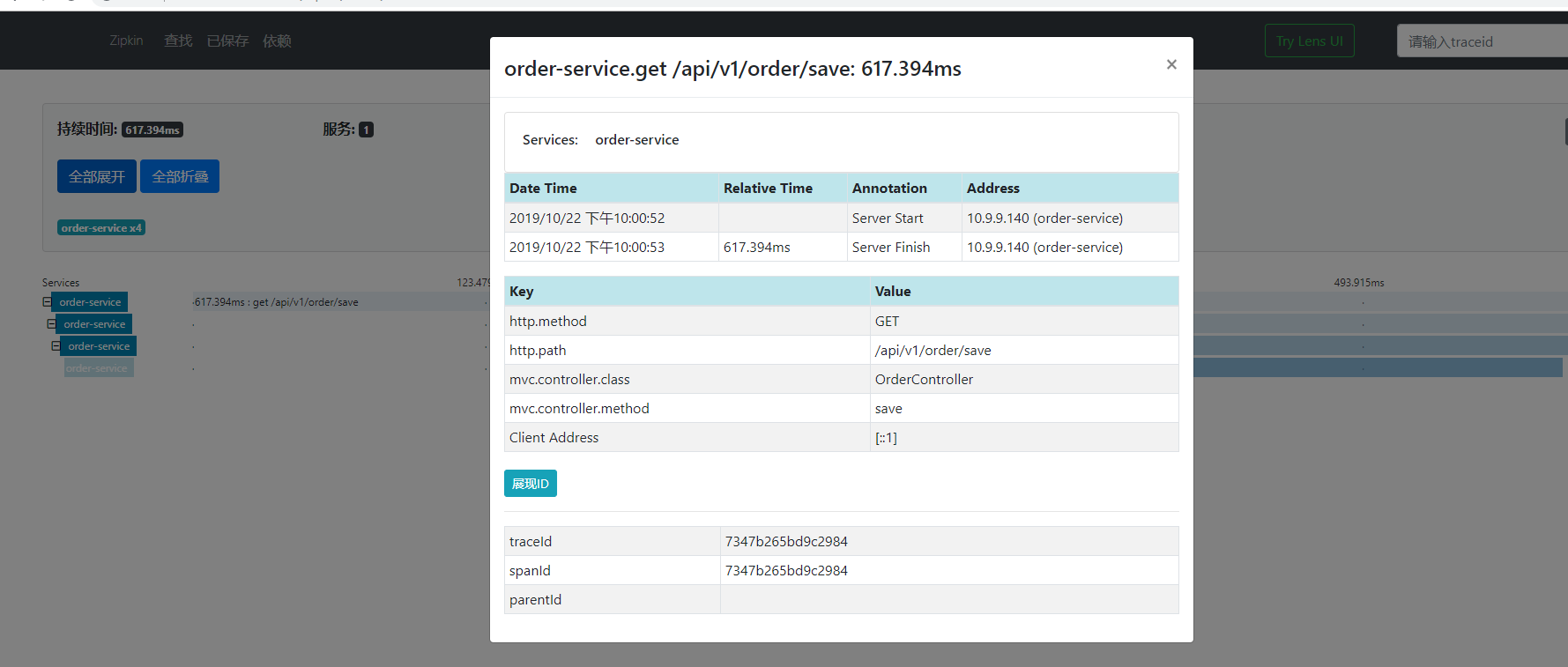
RESTful API :API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接
系统访问以实现监控等。
Web UI :UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和
分析跟踪信息。
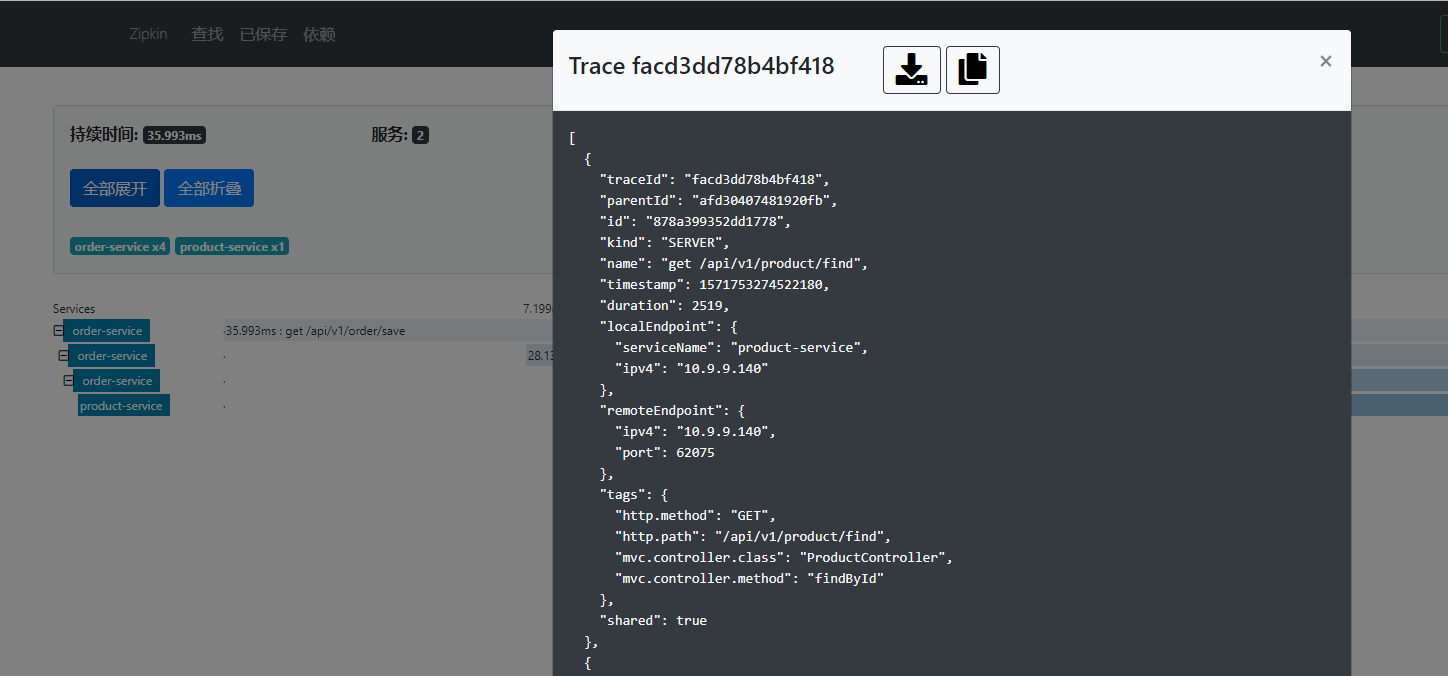
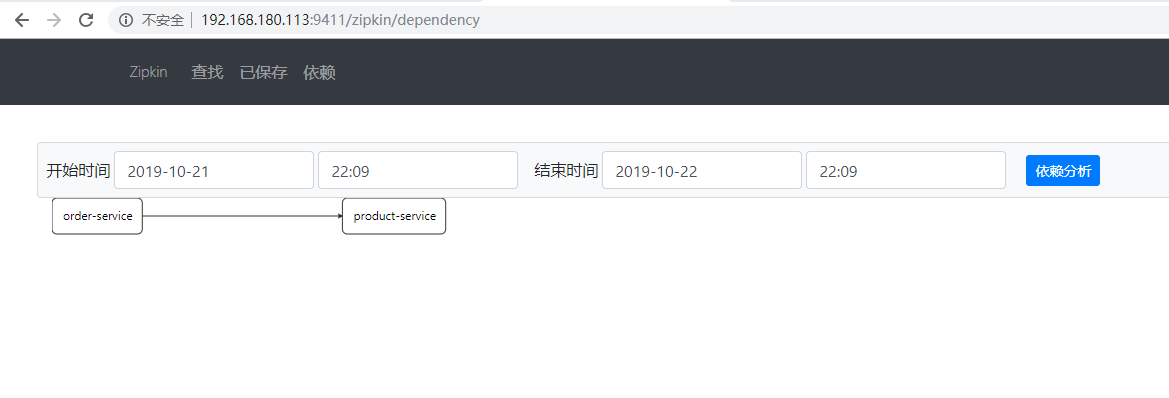
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用。
客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的
监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。
发送的方式主要有两种,一种是 HTTP 报文的方式,还有一种是消息总线的方式如 RabbitMQ。
不论哪种方式,我们都需要:
一个 Eureka 服务注册中心,这里我们就用之前的 eureka 项目来当注册中心。
一个 Zipkin 服务端。
多个微服务,这些微服务中配置 Zipkin 客户端。
在项目的pom.xml文件中添加下面依赖
<!--里面包含两个依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2. 修改配置
主要修改两个配置:
-
base-url:zipkin地址,默认值是:"http://192.168.180.113:9411/" -
probability: 采集日志的百分比,默认值是:0.1,由于测试中需要才改成1,生产环境就使用默认值
#zipkin服务所在地址 zipkin: base-url: http://192.168.180.113:9411/ #配置采样百分比,开发环境可以设置为1,表示全部,生产就用默认 sleuth: sampler: probability: 1
3. 开启Zipkin
docker中有现成的镜像直接拉去下来使用
拉去镜像 docker pull docker.io/openzipkin/zipkin 启动容器 [root@topcheer ~]# docker run -d -p 9411:9411 --name myzipkin 17c2bb09f482 5a1707edb7a6c57887537577f7e5775b3f5313fe6b5f703f71b453763d61a506 [root@topcheer ~]# docker ps -l CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5a1707edb7a6 17c2bb09f482 "/busybox/sh run.sh" 6 seconds ago Up 4 seconds 9410-9411/tcp myzipkin [root@topcheer ~]#