看到教育部“关于发布中小学国家课程教材电子版链接的通告”,公示了各中小学教材编写出版单位提供免费电子版教材链接,整整一个excel表格。有人民教育出版社,江苏凤凰教育出版社等等,因此萌生了重拾写python爬虫的想法。看看能不能将一些出版社的电子书全部下载下来。
简单的Python爬虫脚本主要用到两个模块,bs4模块和requests模块
1.首先安装两个模块:pip install requests,pip install bs4
2. 以凤凰教材电子版免费下载 网页为例,浏览器右击查看页面源代码
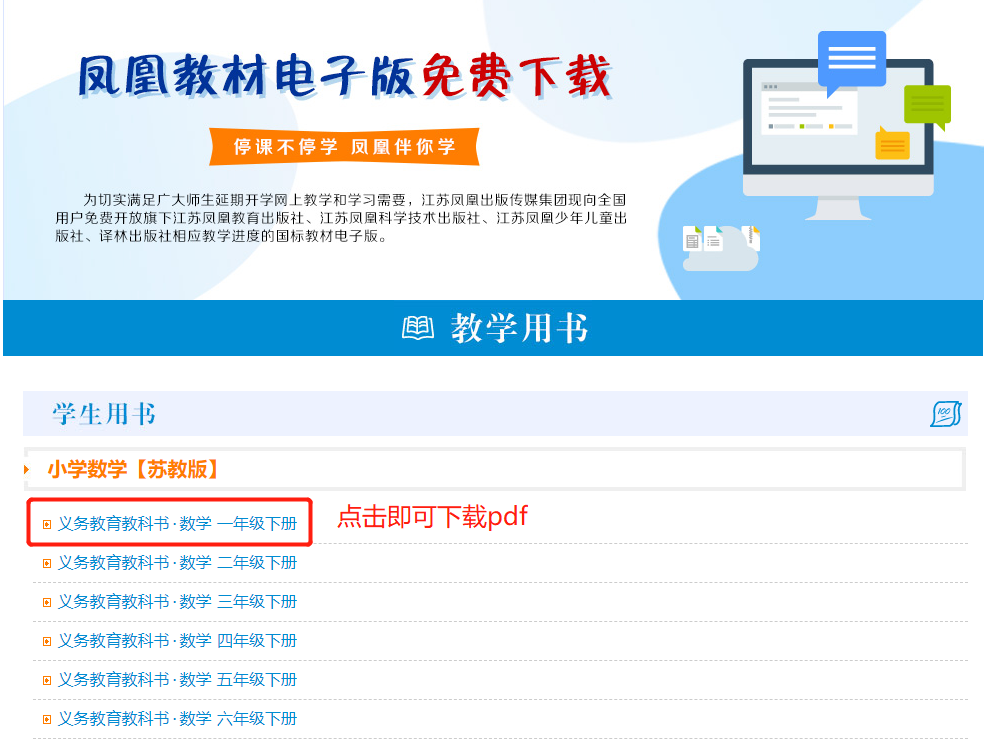

源代码与网页中一一对应,也就是网页中的书名其实加了一个pdf文件的超链接。因此我们只要查找书名,对应的pdf,然后保存下来即可。
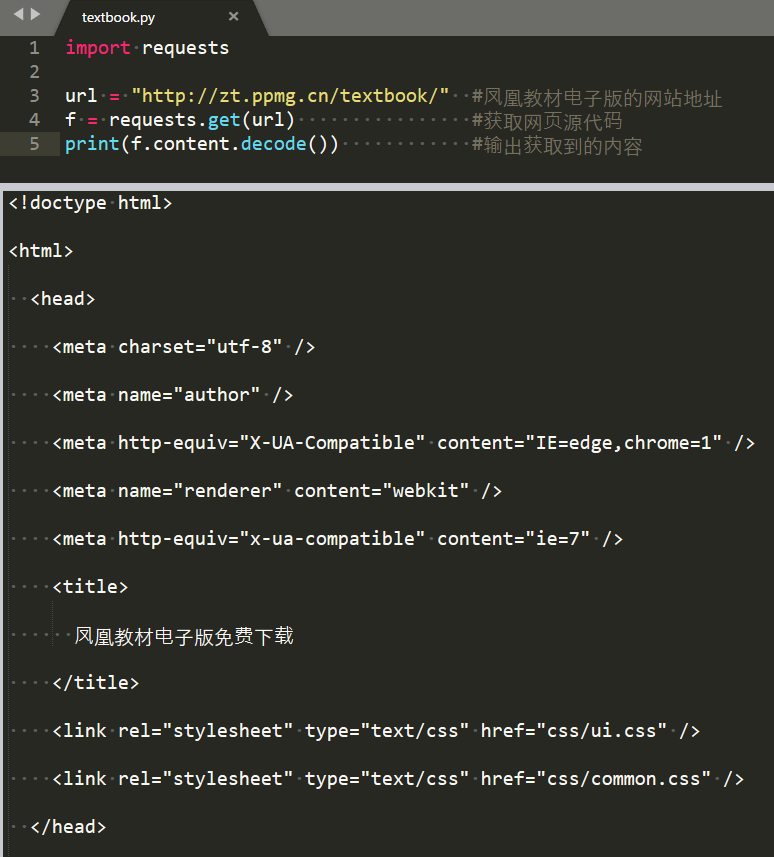
3. 首先应用requests库,将网页源代码读取下来以备分析
import requestsurl = "http://zt.ppmg.cn/textbook/" #凤凰教材电子版的网站地址f = requests.get(url) #获取网页源代码print(f.content.decode()) #输出获取到的内容
运行输出结果即为网页源代码,即获取成功。
4. 另外我们可以看到,该网页中教材的分类是,先是科目版本如“小学数学【苏教版】”、“小学英语【译林版】”,然后每个科目版本下面是包含的是若干本书。对应到源代码中,每个科目源代码的格式是一致的。如下图,关键字“box”代表的是一个科目版本块,然后我们找到所有的科目版本块,再分别找到科目版本的名字,以及每个科目版本下面包含的所有书本。

知道需要找到什么内容后,使用BeautifulSoup很容易将需要的信息挑选出来。

运行代码,我们想要的信息已经被提取出来了。
5. 下面就是将该网页的教材全部下载下来,并分门别类。
新建文件夹调用了os库,教材电子书pdf分别保存对应的科目文件夹下。值得一提的是,我们获取到的下载地址并不是完整的,需要前面加上该网站的地址。代码完善后如下图
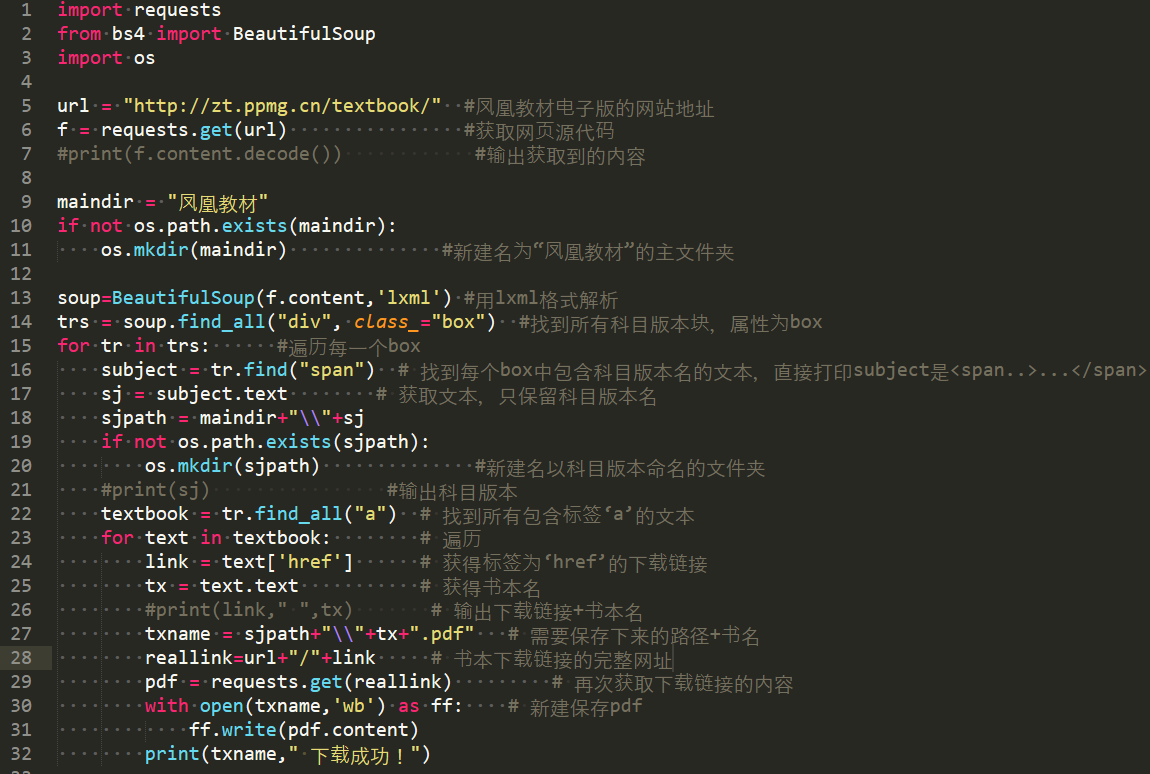
运行本程序,最终可以将该网页的所有电子书下载下来啦。
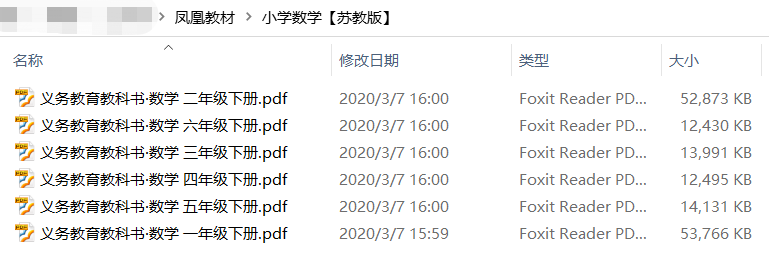
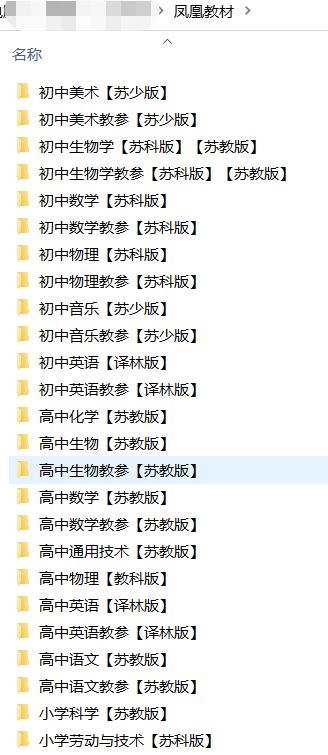
由于大蓝鲸水平有限,这里只是介绍了简单的爬虫技巧,对于对复杂的网页内容爬取,还需要进一步的研究。当然,用这个爬虫脚本改改爬妹子图也是很方便的哦。
另外有需要这些教材或者本文的爬虫代码,关注公众号,回复“教材爬虫”即可。
