本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. Window CoGroup与Join
1.1回顾RDBMS各种join
假设有两个表A和B
1.CROSS JOIN(AB的笛卡尔积/交叉联接)
省略写法为join,由于其返回的结果为被连接的两个数据表的乘积,因此当有WHERE, ON或USING条件的时候一般不建议使用,因为当数据表项目太多的时候,会非常慢。
2.outer join
a)left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录。
b)right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录。
c)FULL JOIN 产生A和B的并集。对于没有匹配的记录,则会以null做为值。
3.inner join(AB的交集)--默认就是这种join,又叫等值连接
inner join(等值连接) 只返回两个表中联结字段相等的行。
1.2Flink中CoGroup vs Join Connect
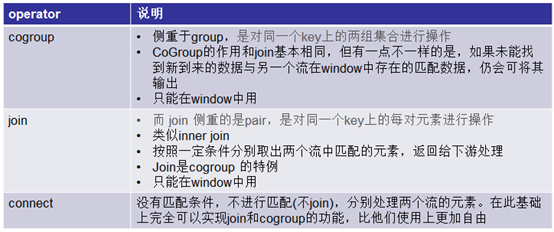
1.3CoGroup
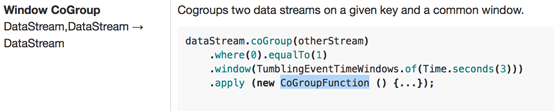
1.4Join

上图可以做如下理解:
1、双流上的数据在同一个key的会被分别分配到同一个window窗口的左右两个篮子里
2、当window结束的时候,会对左右篮子进行笛卡尔积从而得到每一对pair,对每一对pair应用 JoinFunction
3、因为目前join窗口的双流数据都是被缓存在内存中的,如果某个key对应的数据太多导致jvm OOM(数据倾斜是常态)-这也算是目前社区的优化优化方向
4、有局限性,受制于时间窗口

1.5Tumbling Window Join
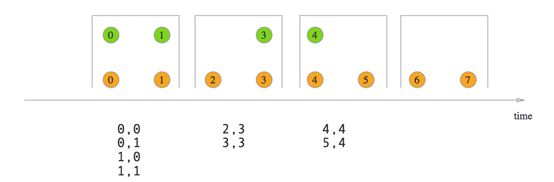
1.6Tumbling Window Join
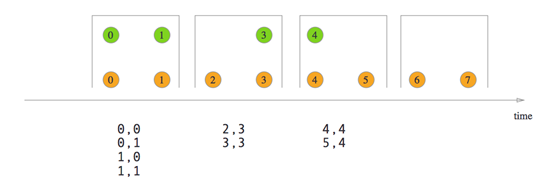
1.7Sliding Window Join

1.8Session Window Join
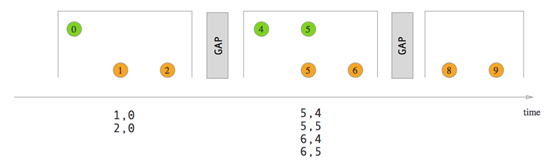
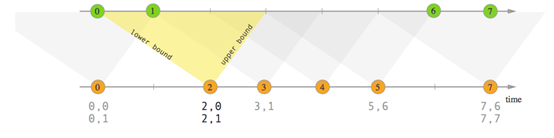
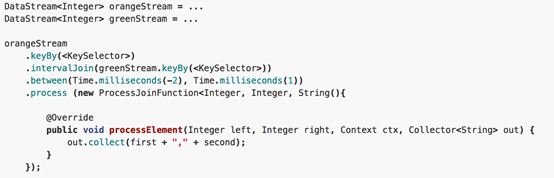
2. Interval Join
KeyedStream,KeyedStream → DataStream
在给定的时间边界内(默认包含边界),相当于一个窗口,按照指定的key对两个KeyedStream进行join操作,把符合join条件的两个event拉到一起,然后怎么处理由用户你来定义。
key1 == key2 && e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
场景:把一定时间范围内相关的分组数据拉成一个宽表