说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. 快速生成Flink项目
1.推荐开发工具
idea+maven+git
2.推荐开发语言
Java或者Scala
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/java_api_quickstart.html
3.Flink项目构建步骤
1)通过maven构建Flink项目
这里我们选择构建1.6.2版本的Flink项目,打开终端输入如下命令:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.6.2

项目构建过程中需要输入groupId,artifactId,version和package

然后输入y确认
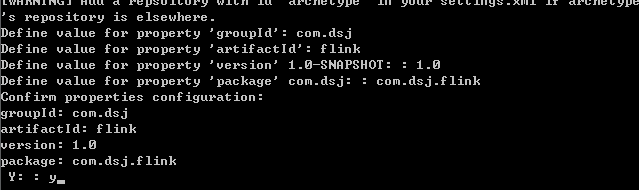
然后显示Maven项目构建成功

2)打开IDEA导入Flink 构建的maven项目
打开IDEA开发工具,点击open选项

选择刚刚创建的Flink项目

IDEA打开Flink项目
2. Flink Batch版WordCount
新建一个batch package

打开github Flink源码,将批处理WordCount代码copy到batch包下。
打开批处理WordCount代码:



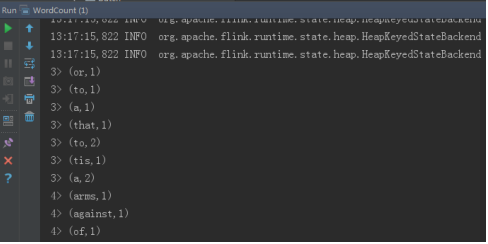
右键选择run,运行Flink批处理WordCount,运行结果如下所示:

3. Flink Stream版WordCount
同样,流处理我们也单独创建一个包stream
打开github Flink源码,将流处理WordCount代码copy到stream包下。

打开流处理WordCount代码:

右键选择run,运行Flink流处理WordCount,运行结果如下所示:
(3)Flink核心概念与编程模型
1. Flink分层架构
1.1 Flink生态之核心组件栈
大家回顾一下Flink生态圈中的核心组件栈即可,前面已经详细讲过,这里就不再赘叙。

1.2 Flink分层架构
Flink一共分为四个层级,具体如下图所示:
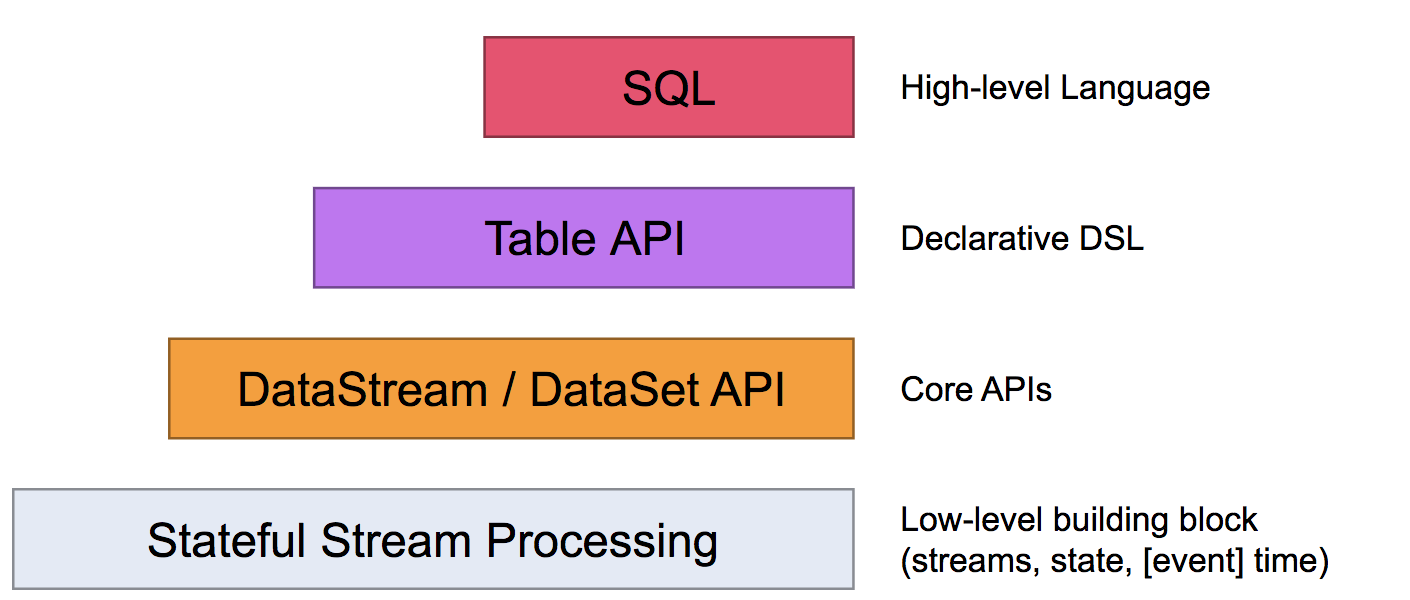
Flink 最下面的一层API为Stateful Stream Processing,它是Flink最底层的API,控制更灵活但一般很少使用。然后上面一层就是Flink Core(核心)API,它包含DataStream和DataSet API,应用层的用户经常使用 Core API。然后再上面一层就是 Table API,它相当于在Core API中可以定义数据的Table结构,可以做table操作。最上面一层就是SQL 操作,用户可以直接使用SQL语句对数据处理,更简单更方便。
注意:越底层的API越灵活,但越复杂。越上层的API越轻便,但灵活性差。
- Stateful Stream Processing
a)它位于最底层,是Core API 的底层实现。
b)它是嵌入到Stream流里面的处理函数(processFunction)。
c)当Core API满足不了用户需求,可以利用低阶API构建一些新的组件或者算子。
d)它虽然灵活性高,但开发比较复杂,需要具备一定的编码能力。
- Core API
a) DataSet API 是批处理API,处理有限的数据集。
b) DataStream API是流处理API,处理无限的数据集。
- Table API & SQL
a)SQL 构建在Table 之上,都需要构建Table 环境。
b)不同的类型的Table 构建不同的Table 环境中。
c)Table 可以与DataStream或者DataSet进行相互转换。
d)Streaming SQL不同于存储的SQL,最终会转化为流式执行计划。
1.3Flink DataFlow
Flink DataFlow基本套路:先创建Data Source读取数据,然后对数据进行转化操作,然后创建DataSink对数据输出。

结合代码和示意图理解DataFlow
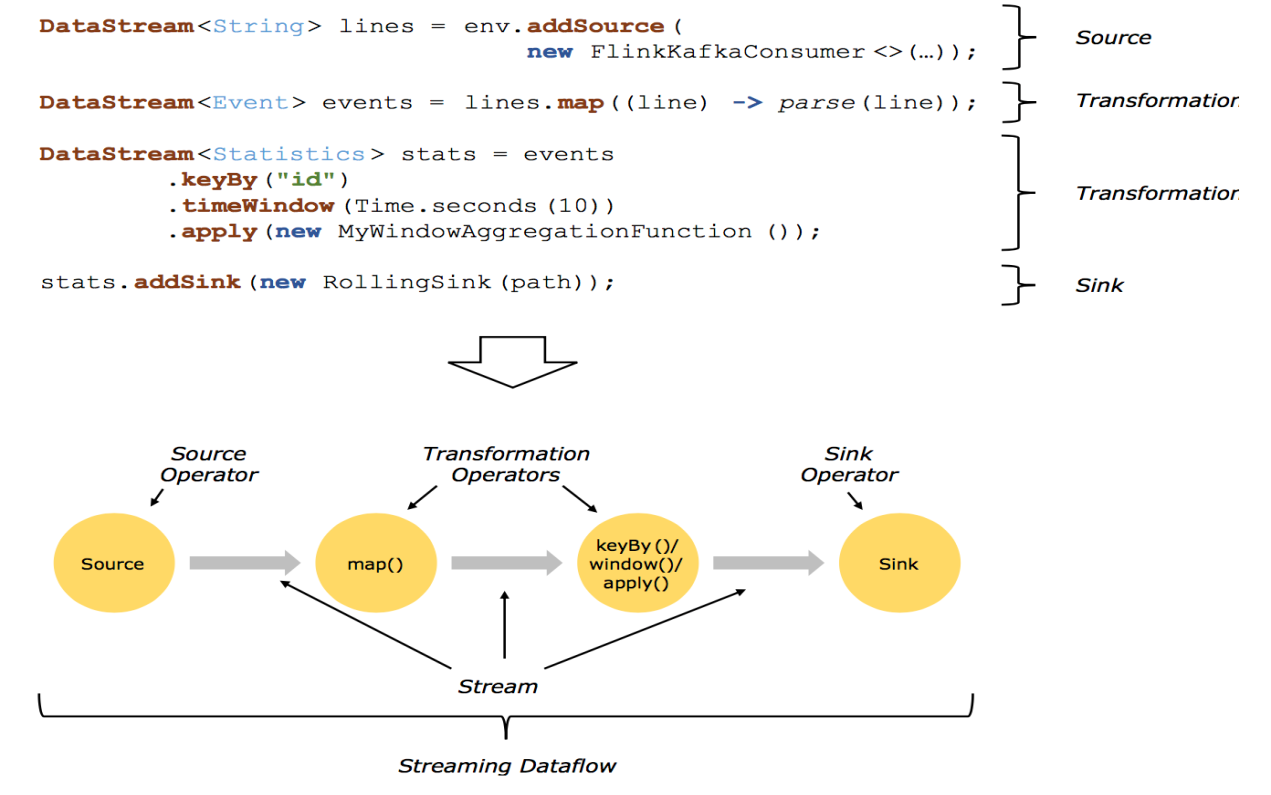
Flink DataFlow 基本套路如下所示:
步骤1:构建计算环境(决定采用哪种计算执行方式)
步骤2:创建Source(可以多个数据源)
步骤3:对数据进行不同方式的转换(提供了丰富的算子)
步骤4:对结果的数据进行Sink(可以输出到多个地方)
并行化DataFlow
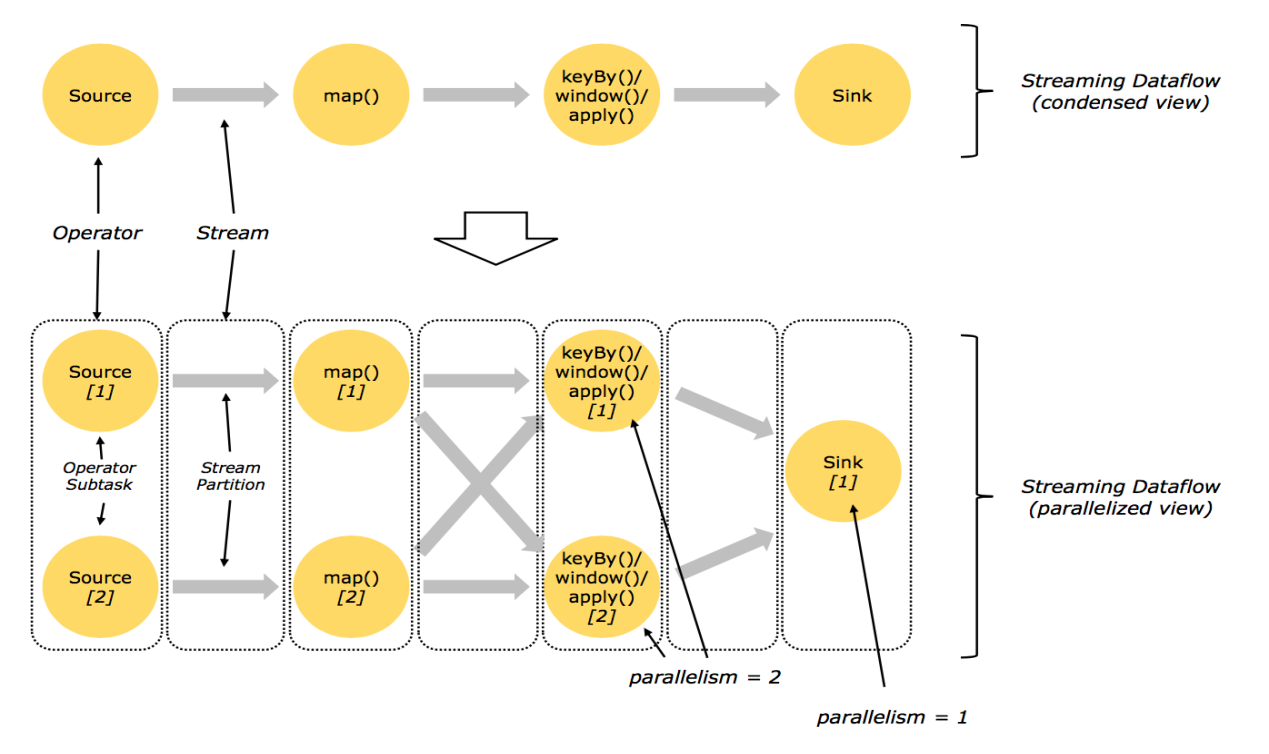
从上图可以看出Source的并行度为2,它们可以并行运行在不同的节点上。Map的并行度也为2,source读取数据后做Stream Partition操作,source1将数据交给map1,source2将数据交给map2。keyBy(或者window等)的并行度为2,map处理后的数据需要经过shuffle操作,然后交给keyBy进行分组统计。Sink的并行度为1,keyBy最后分组统计后的数据交给sink,将数据进行输出操作。
算子间数据传递模式
从上图可以看出,Flink算子间的数据传递模式大概分为两种:
1.One-to-one streams:保持元素的分区和顺序,比如数据做map操作。
2.Redistributing streams: 它会改变流的分区,重新分区策略取决于使用的算子
keyBy() (re-partitions by hashing the key) :根据hash key对数据重新分区。
broadcast():即为广播操作,比如map1有100条数据,发送给keyBy1是100条数据,发给keyBy2也是100条数据。
rebalance() (which re-partitions randomly):即随机打散,数据随机分区发送给下游操作。
2. Windows
前面我们已经了解了Flink的Stream流处理和Batch批处理,那么我们这里讲的Windows操作是对一段数据进行操作,它可以按照固定数据量进行Windows操作,也可以按照固定时间进行windows操作,它是Stream 流处理所特有的窗口操作。
Flink Windows操作的类型大概分为以下几类:
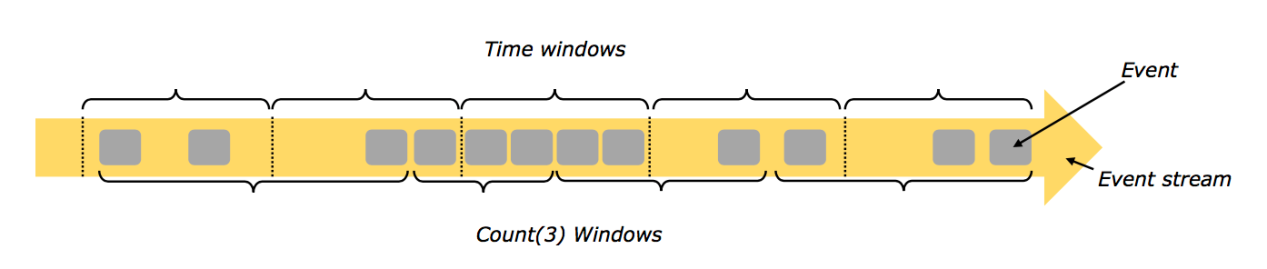
- Count Windows
顾名思义,是按照Events的数量进行操作,比如每3个Event做一次windows操作。
- Time Windows
基于时间长度进行Windows操作
a) Tumbling Windows:即翻滚窗口,不会重叠,比如每隔3s操作一次。
b) Sliding Windows:即滑动窗口,有重叠,比如窗口大小为3s,每次向前滑动1s。
c) Session Windows:类似于Web编程里的Session,以不活动间隙作为窗口进行操作,比如每10s内没有活动,就会做一次Windows操作。
- 自定义Windows
当Flink内置的windows不能满足用户的需求,我们可以自定义Windows操作。