面向过程与面向对象比较
- 面向过程:
- 优点:复杂过程简单化进而流程化。
- 缺点:可扩展性差
- 面向对象:
- 优点:可扩展性好
- 缺点:编程复杂度高
对象和类的区别
对象:特征和技能的结合体。
类:一系列对象相似的特征和技能的结合体。
在python程序中,先定义类,然后调用类来产生对象。
调用类的过程称为类的实例化,而实例化的结果称为类的实例或类的对象。
class Student: # 定义类
school = 'oldboy' # 数据属性:所有对象共享
def __init__(self, name): # 函数属性
"""为对象初始化自己独有的特征:先产生空对象,再自动触发__init__执行,将stu1和参数传入"""
self.name = name
def learn(self): # 函数属性:绑定给对象使用
print(f'{self.name} is learning')
stu1 = Student('allen') # 实例化
print(stu1.__dict__) # {'name': 'allen'}
print(Student.__dict__)
# 函数在定义阶段只检测语法,不执行代码;而类在定义阶段就执行并产生类的名称空间。
绑定方法和非绑定方法
绑定到对象的方法:在类中没有被装饰器修改过的方法,专门为对象定制。用于当函数体代码需要用外部传入的对象
class Student:
school = 'oldboy'
def __init__(self, name):
self.name = name
def learn(self, age):
print(f'he is {age},{self.name} is learning ')
stu1 = Student('allen')
stu1.learn(18) # 对象调用绑定方法,谁调用将谁作为第一个参数传给self,已自动传入不需再传。
Student.learn(stu1, 18) # 类调用对象的方法,该方法相当于普通函数,第一个参数需要手动传入,不建议使用。
绑定到类的方法:类中使用@classmethod装饰的方法,专门为类定制。用于当函数体代码需要用外部传入的类,如pikcle序列化时读取文件。
class Student:
school = 'oldboy'
def __init__(self, name):
self.name = name
@classmethod
def learn(cls, age):
print(f'he is {age},{stu1.name} is learning ')
stu1 = Student('allen')
Student.learn(18) # 通过类名调用绑定到类的方法时,会将类本身当做参数传给类方法的第一个参数。
stu1.learn(18) # 通过对象也可以调用,只是默认传递的第一个参数还是这个对象对应的类,不推荐使用。
非绑定方法(静态方法):在类内部使用@staticmethod装饰的方法,与普通函数无区别,不与类和函数绑定,谁都可以调用且没有自动传参一说。用于函数体代码既不需要外部传入的类也不需要外部传入的对象
import hashlib
class Operate_database():
def __init__(self, host, port, user, password):
self.host = host
self.port = port
self.user = user
self.password = password
@staticmethod
def get_passwrod(salt, password):
m = hashlib.md5(salt.encode('utf-8')) # 加盐处理
m.update(password.encode('utf-8'))
return m.hexdigest()
hash_password = Operate_database.get_passwrod('lala', '123456') # 通过类来调用
print(hash_password)
p = Operate_database('192.168.0.5', '3306', 'abc', '123456')
hash_password = p.get_passwrod(p.user, p.password) # 也可以通过对象调用
print(hash_password)
菱形继承问题
新式类:继承了object的类以及该类的子类,py3中都是新式类,默认继承object类。
经典类:没有继承object的类以及该类的子类,py2独有。
原因:因python可继承多个父类,当继承关系为非菱形结构,则会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性;如果继承关系为菱形结构,即子类的父类最后继承了同一个类,那么属性的查找方式有两种:经典类(深度优先)和新式类(广度优先)。
如何实现多继承:按照MRO列表(所有基类的线性顺序列表)


class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D,E):
# def test(self):
# print('from F')
pass
f1=F()
f1.test()
print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性
#新式类继承顺序:F->D->B->E->C->A
#经典类继承顺序:F->D->B->A->E->C
#python3中统一都是新式类
#pyhon2中才分新式类与经典类
类的派生和组合
派生:子类新定义的属性过程且子类使用派生的属性以自己为准。
# 派生方式一:指名道姓访问某一个类函数,该方式与继承无关。
class OldboyPeople:
"""由于学生和老师都是人,因此人都有姓名、年龄、性别"""
school = 'oldboy'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class OldboyStudent(OldboyPeople):
"""由于学生类没有独自的__init__()方法,因此不需要声明继承父类的__init__()方法,会自动继承"""
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
"""由于老师类有独自的__init__()方法,因此需要声明继承父类的__init__()"""
def __init__(self, name, age, gender, level):
OldboyPeople.__init__(self, name, age, gender)
self.level = level # 派生
def score(self, stu_obj, num):
print('%s is scoring' % self.name)
stu_obj.score = num
stu1 = OldboyStudent('tank', 18, 'male')
tea1 = OldboyTeacher('nick', 18, 'male', 10)
print(stu1.__dict__) # {'name': 'tank', 'age': 18, 'gender': 'male'}
print(tea1.__dict__) # {'name': 'nick', 'age': 18, 'gender': 'male', 'level': 10}
# 派生方式二:super()会得到一个特殊的对象,专门用来访问父类的属性的。
class OldboyPeople:
school = 'oldboy'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class OldboyStudent(OldboyPeople):
def __init__(self, name, age, sex, stu_id):
# OldboyPeople.__init__(self,name,age,sex) #类调用
# super(OldboyStudent, self).__init__(name, age, sex) #完整用法是super(自己的类名,self),在python2中需要写完整
super().__init__(name, age, sex) # super().__init__(不用为self传值),py3写法
self.stu_id = stu_id
def choose_course(self):
print('%s is choosing course' % self.name)
stu1 = OldboyStudent('tank', 19, 'male', 1)
print(stu1.__dict__) # {'name': 'tank', 'age': 19, 'sex': 'male', 'stu_id': 1}
组合:一个类的对象具备某一个属性,该属性的值是指向另外一个类的对象。目的是解决类与类之间代码冗余问题。
class Course:
def __init__(self, name, period, price):
self.name = name
self.period = period
self.price = price
def tell_info(self):
msg = """
课程名:%s
课程周期:%s
课程价钱:%s
""" % (self.name, self.period, self.price)
print(msg)
class OldboyPeople:
school = 'oldboy'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class OldboyStudent(OldboyPeople):
def __init__(self, name, age, sex, stu_id):
OldboyPeople.__init__(self, name, age, sex)
self.stu_id = stu_id
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
def __init__(self, name, age, sex, level):
OldboyPeople.__init__(self, name, age, sex)
self.level = level
def score(self, stu, num):
stu.score = num
print('老师[%s]为学生[%s]打分[%s]' % (self.name, stu.name, num))
# 创造课程
python = Course('python全栈开发', '5mons', 3000)
python.tell_info()
linux = Course('linux运维', '5mons', 800)
linux.tell_info()
# 创造学生与老师
stu1 = OldboyStudent('tank', 19, 'male', 1)
tea1 = OldboyTeacher('nick', 18, 'male', 10)
# 组合:将学生、老师与课程对象关联/组合
stu1.course = python
tea1.course = linux
stu1.course.tell_info()
tea1.course.tell_info()
类的特殊属性
类名.__name__# 类的名字(字符串)
类名.__doc__# 类的文档字符串
类名.__bases__# 类所有父类构成的元组
类名.__dict__# 类的字典属性
类名.__module__# 类定义所在的模块
类名.__class__# 实例对应的类(仅新式类中)
类的三大特性
(单、多)继承:既是一种新建类的方式,又是一种什么是什么的关系,新建类称为子类或派生类,被继承类称为父类或基类。目的是减少代码冗余问题。
class OldboyPeople:
"""由于学生和老师都是人,因此人都有姓名、年龄、性别"""
school = 'oldboy'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class OldboyStudent(OldboyPeople):
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
def score(self, stu_obj, num):
print('%s is scoring' % self.name)
stu_obj.score = num
stu1 = OldboyStudent('tank', 18, 'male')
tea1 = OldboyTeacher('nick', 18, 'male')
多态:一类事物有多种形态。
多态性:一种调用方式,不同的执行结果。
多态性的好处:增加程序灵活性和可扩展性。
import abc
class Animal(metaclass=abc.ABCMeta): # 同一类事物:动物
@abc.abstractmethod # 上述代码子类是约定俗称的实现这个方法,加上@abc.abstractmethod装饰器后严格控制子类必须实现这个方法
def talk(self):
raise AttributeError('子类必须实现这个方法')
class People(Animal): # 动物的形态之一:人
def talk(self):
print('say hello')
class Pig(Animal): # 动物的形态之二:猪
def talk(self):
print('say aoao')
peo2 = People()
pig2 = Pig()
peo2.talk() # say hello
pig2.talk() # say aoao
# 多态性依赖于:继承
# 多态性:定义统一的接口
def func(obj): # obj这个参数没有类型限制,可以传入不同类型的值
obj.talk() # 调用的逻辑都一样,执行的结果却不一样
func(peo2) # say hello
func(pig2) # say aoao
封装:既封装数据(保护隐私)又封装方法(隔离复杂度)。
在编程语言里,对外提供的接口(接口可理解为了一个入口),就是函数,称为接口函数,这与接口的概念还不一样,接口代表一组接口函数的集合体。
#其实这仅仅这是一种变形操作且仅仅只在类定义阶段发生变形
#类中所有双下划线开头的名称如__x都会在类定义时自动变形成:_类名__x的形式:
class A:
__N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N
def __init__(self):
self.__X=10 #变形为self._A__X
def __foo(self): #变形为_A__foo
print('from A')
def bar(self):
self.__foo() #只有在类内部才可以通过__foo的形式访问到.
#A._A__N是可以访问到的,
#这种,在外部是无法通过__x这个名字访问到。
# 封装数据
class Teacher:
def __init__(self, name, age):
# self.__name=name
# self.__age=age
self.set_info(name, age)
def tell_info(self):
print('姓名:%s,年龄:%s' % (self.__name, self.__age))
def set_info(self, name, age):
if not isinstance(name, str):
raise TypeError('姓名必须是字符串类型')
if not isinstance(age, int):
raise TypeError('年龄必须是整型')
self.__name = name
self.__age = age
t = Teacher('egon', 18)
t.tell_info()
t.set_info('egon', 19)
t.tell_info()
# 封装方法
class ATM:
def __card(self):
print('插卡')
def __auth(self):
print('用户认证')
def __input(self):
print('输入取款金额')
def __print_bill(self):
print('打印账单')
def __take_money(self):
print('取款')
def withdraw(self):
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money()
a = ATM()
a.withdraw()
类的property特性
property特性:用于将被装饰的方法伪装成一个数据属性,在使用时可以不用加括号而直接使用。
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
@property
def price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
@price.setter
def price(self, value):
self.original_price = value
@price.deleter
def price(self):
print('del')
del self.original_price
obj = Goods()
print(obj.price) # 获取商品价格80.0
obj.price = 200 # 修改商品原价
print(obj.price) # 160.0
del obj.price # 删除商品原价
# 新式类中的属性有三种访问方式,并分别对应了三个被 @property、@方法名.setter、@方法名.deleter 修饰的方法
断点调试
定义:在程序运行过程中,在代码某一处打上断点,当程序跑到该位置时,则会中断下来,可看到运行过的程序变量。
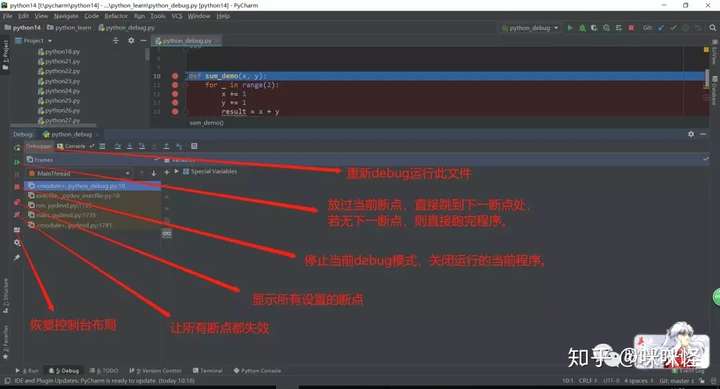
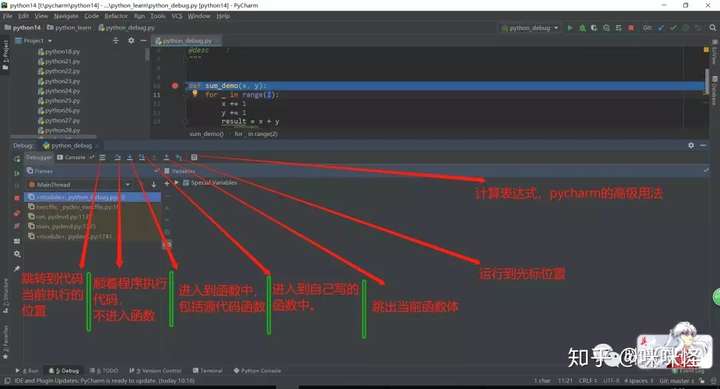
issubclass和isinstance
class BaseClass:
pass
class Parents(BaseClass):
pass
class Student(BaseClass):
pass
p1 = Parents()
print(issubclass(Parents, BaseClass)) # True
print(issubclass(Student, BaseClass)) # True
print(isinstance(p1, Parents)) # True
print(isinstance(p1, BaseClass)) # True
# issubclass判断第一个类是否继承第二个类
# isinstance判断第一个参数是否是第二个参数(家族体系)的对象
反射
定义:通过字符串来获取,设置,删除对象中的属性或方法。
- hasattr:判断一个方法是否存在这个类中
- getattr:根据字符串去获取obj对象里的对应的方法的内存地址,加"()"括号即可执行
- setattr:通过setattr将外部的一个函数绑定到实例中
- delattr:删除一个实例或者类中的方法
class People:
country = 'China'
def __init__(self, name):
self.name = name
def eat(self):
print(f'{self.name} is eating')
peo1 = People('allen')
print(hasattr(peo1, 'eat')) # True
print(getattr(peo1, 'eat')) # <bound method People.eat of <__main__.People object at 0x000001F3D9D930B8>>
print(getattr(peo1, 'eatt', None)) # None
setattr(peo1, 'age', 18)
print(peo1.age) # 18
print(peo1.__dict__) # {'name': 'allen', 'age': 18}
delattr(peo1, 'age')
print(peo1.__dict__) # {'name': 'allen'}
# 需求:通过用户输入命令启动功能
class Ftp:
def __init__(self, ip, port):
self.ip = ip
self.port = port
def run(self):
while True:
choose = input('>>>:').strip()
if choose == 'q':
print('break')
break
method = getattr(conn, choose, None)
if method is None:
print('命令不存在')
else:
method()
conn = Ftp('127.0.0.1', 8888)
conn.run()
# 需求:模块如何使用反射
# 模块也是对象,也可以用四个方法
import os
print(hasattr(os,'path1'))
# 使用自己写的模块,通过反射来获取模块中是否有我要使用的属性或方法,如果有就执行,没有,就报错
import utils
utils.speak()
if hasattr(utils,'speak'):
speak=getattr(utils,'speak')
speak()
# 我以为它写完了
utils.eat()
# 更安全
if hasattr(utils,'eat'):
eat=getattr(utils,'eat')
eat()
else:
print('那个人还没写完呢')
importlib模块
定义:根据字符串的模块名实现动态导入模块的库。
目录结构:
├── aaa.py
├── bbb.py
└── mypackage
├── __init__.py
└── xxx.py
import importlib
func = importlib.import_module('aaa')
print(func)
func.f1()
m = importlib.import_module('mypackage.xxx')
print(m.age)
类的内置方法(魔法方法)
__str__:改变对象的字符串显示。可以理解为使用print函数打印一个对象时,会自动调用对象的__str__方法
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
# 定义对象的字符串表示
def __str__(self):
return self.name
s1 = Student('张三', 24)
print(s1) #张三 # 会调用s1的__str__方法
__repr__:在python解释器环境下,会默认显示对象的__repr__表示。
>>> class Student:
... def __init__(self, name, age):
... self.name = name
... self.age = age
... def __repr__(self):
... return self.name
...
>>> s1 = Student('张三', 24)
>>> s1
张三
#如果__str__没有被定义,那么就会使用__repr__来代替输出。__str__和__repr__方法的返回值都必须是字符串。
__format__:格式化输出
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
__format_dict = {
'n-a': '名字是:{obj.name}-年龄是:{obj.age}', # 名字是:lqz-年龄是:18
'n:a': '名字是:{obj.name}:年龄是:{obj.age}', # 名字是:lqz:年龄是:18
'n/a': '名字是:{obj.name}/年龄是:{obj.age}', # 名字是:/年龄是:18
}
def __format__(self, format_spec):
if not format_spec or format_spec not in self.__format_dict:
format_spec = 'n-a'
fmt = self.__format_dict[format_spec]
print(fmt) #{obj.name}:{obj.age}
return fmt.format(obj=self)
s1 = Student('lqz', 24)
ret = format(s1, 'n/a')
print(ret) # lqz/24
__del__:析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
class A:
def __del__(self):
print('删除了...')
a = A()
print(a) # <__main__.A object at 0x10164fb00>
del a # 删除了...
print(a) # NameError: name 'a' is not defined
__dict__和__solts__:Python中的类,都会从object里继承一个__dict__属性,这个属性中存放着类的属性和方法对应的键值对。一个类实例化之后,这个类的实例也具有这么一个__dict__属性。但是二者并不相同。
class A:
some = 1
def __init__(self, num):
self.num = num
a = A(10)
print(a.__dict__) # {'num': 10}
a.age = 10
print(a.__dict__) # {'num': 10, 'age': 10}
从上面的例子可以看出来,实例只保存实例的属性和方法,类的属性和方法它是不保存的。正是由于类和实例有__dict__属性,所以类和实例可以在运行过程动态添加属性和方法。
但是由于每实例化一个类都要分配一个__dict__变量,容易浪费内存。因此在Python中有一个内置的__slots__属性。当一个类设置了__slots__属性后,这个类的__dict__属性就不存在了(同理,该类的实例也不存在__dict__属性),如此一来,设置了__slots__属性的类的属性,只能是预先设定好的。
当你定义__slots__后,__slots__就会为实例使用一种更加紧凑的内部表示。实例通过一个很小的固定大小的小型数组来构建的,而不是为每个实例都定义一个__dict__字典,在__slots__中列出的属性名在内部被映射到这个数组的特定索引上。使用__slots__带来的副作用是我们没有办法给实例添加任何新的属性了。
注意:尽管__slots__看起来是个非常有用的特性,但是除非你十分确切的知道要使用它,否则尽量不要使用它。比如定义了__slots__属性的类就不支持多继承。__slots__通常都是作为一种优化工具来使用。
class A:
__slots__ = ['name', 'age']
a1 = A()
# print(a1.__dict__) # AttributeError: 'A' object has no attribute '__dict__'
a1.name = '张三'
a1.age = 24
# a1.hobby = '泡妞' # AttributeError: 'A' object has no attribute 'hobby'
print(a1.__slots__)
注意事项:
__slots__的很多特性都依赖于普通的基于字典的实现。
另外,定义了__slots__后的类不再 支持一些普通类特性了,比如多继承。大多数情况下,你应该只在那些经常被使用到的用作数据结构的类上定义__slots__,比如在程序中需要创建某个类的几百万个实例对象 。
关于__slots__的一个常见误区是它可以作为一个封装工具来防止用户给实例增加新的属性。尽管使用__slots__可以达到这样的目的,但是这个并不是它的初衷。它更多的是用来作为一个内存优化工具。
__item__系列
class Foo:
def __init__(self, name):
self.name = name
def __getitem__(self, item):
print(self.__dict__[item])
def __setitem__(self, key, value):
print('obj[key]=lqz赋值时,执行我')
self.__dict__[key] = value
def __delitem__(self, key):
print('del obj[key]时,执行我')
self.__dict__.pop(key)
def __delattr__(self, item):
print('del obj.key时,执行我')
self.__dict__.pop(item)
f1 = Foo('sb')
print(f1.__dict__)
f1['age'] = 18
f1.hobby = '泡妞'
del f1.hobby
del f1['age']
f1['name'] = 'lqz'
print(f1.__dict__)
__init__:使用Python写面向对象的代码的时候我们都会习惯性写一个 __init__ 方法,__init__ 方法通常用在初始化一个类实例的时候。例如:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return '<Person: {}({})>'.format(self.name, self.age)
p1 = Person('张三', 24)
print(p1)
上面是__init__最普通的用法了。但是__init__其实不是实例化一个类的时候第一个被调用的方法。当使用 Persion(name, age) 来实例化一个类时,最先被调用的方法其实是 __new__ 方法。
__new__:其实__init__是在类实例被创建之后调用的,它完成的是类实例的初始化操作,而 __new__方法正是创建这个类实例的方法。
class Person:
def __new__(cls, *args, **kwargs):
print('调用__new__,创建类实例')
return super().__new__(Person)
def __init__(self, name, age):
print('调用__init__,初始化实例')
self.name = name
self.age = age
def __str__(self):
return '<Person: {}({})>'.format(self.name, self.age)
p1 = Person('张三', 24)
print(p1)
# 调用__new__,创建类实例
# 调用__init__,初始化实例
# <Person: 张三(24)>
__new__方法在类定义中不是必须写的,如果没定义的话默认会调用object.__new__去创建一个对象(因为创建类的时候默认继承的就是object)。
如果我们在类中定义了__new__方法,就是重写了默认的__new__方法,我们可以借此自定义创建对象的行为。
举个例子:
重写类的__new__方法来实现单例模式。
class Singleton:
# 重写__new__方法,实现每一次实例化的时候,返回同一个instance对象
def __new__(cls, *args, **kw):
if not hasattr(cls, '_instance'):
cls._instance = super().__new__(Singleton)
return cls._instance
def __init__(self, name, age):
self.name = name
self.age = age
s1 = Singleton('张三', 24)
s2 = Singleton('李四', 20)
print(s1, s2) # 这两实例都一样
print(s1.name, s2.name) #李四 李四
__call__:由对象后加括号触发的,即:对象()。拥有此方法的对象可以像函数一样被调用。
class People():
def __init__(self, name):
self.name = name
p1 = People('allen')
p1() #TypeError: 'People' object is not callable此时不能调用
class People():
def __init__(self, name):
self.name = name
def __call__(self, *args, **kwargs):
print('哈哈,对象也可以调用啦')
p1 = People('allen')
p1() # 哈哈,对象也可以调用啦
__doc__:定义类的描述信息。注意该信息无法被继承。
class A:
"""我是A类的描述信息"""
pass
print(A.__doc__)
__iter__和__next__:如果一个对象拥有了__iter__和__next__方法,那这个对象就是可迭代对象。
class A:
def __init__(self, start, stop=None):
if not stop:
start, stop = 0, start
self.start = start
self.stop = stop
def __iter__(self):
return self
def __next__(self):
if self.start >= self.stop:
raise StopIteration
n = self.start
self.start += 1
return n
a = A(1, 5)
from collections import Iterator
print(isinstance(a, Iterator))
for i in A(1, 5):
print(i)
for i in A(5):
print(i)
aaa=A(1)
print(next(aaa))
print(next(aaa)) #抛异常
__enter__和__exit__:一个对象如果实现了__enter__和__exit__方法,那么这个对象就支持上下文管理协议,即with语句。上下文管理协议适用于那些进入和退出之后自动执行一些代码的场景,比如文件、网络连接、数据库连接或使用锁的编码场景等。
class A:
def __enter__(self):
print('进入with语句块时执行此方法,此方法如果有返回值会赋值给as声明的变量')
return 'oo'
def __exit__(self, exc_type, exc_val, exc_tb):
print('退出with代码块时执行此方法')
print('1', exc_type)
print('2', exc_val)
print('3', exc_tb)
with A() as f:
print('进入with语句块')
# with语句中代码块出现异常,则with后的代码都无法执行。
# raise AttributeError('sb')
print(f) #f打印出oo
print('嘿嘿嘿')
__len__:拥有__len__方法的对象支持len(obj)操作。
class A:
def __init__(self):
self.x = 1
self.y = 2
def __len__(self):
return len(self.__dict__)
a = A()
print(a.__dict__) # {'x': 1, 'y': 2}
print(len(a)) # 2
__hash__:拥有__hash__方法的对象支持hash(obj)操作。
class A:
def __init__(self):
self.x = 1
self.y = 2
def __hash__(self):
return hash(str(self.x) + str(self.y))
a = A()
print(hash(a)) # 3051682962090161259
__eq__:拥有__eq__方法的对象支持相等的比较操作。
class A:
def __init__(self, x, y):
self.x = x
self.y = y
def __eq__(self, other):
# 打印出比较的第二个对象的x值
print(other.x) # 2
if self.x + self.y == other.x + other.y:
return True
else:
return False
a = A(1, 2)
b = A(2, 1)
print(a == b) # True
__getattr__、__setattr__、delattr__:点拦截方法
如果去对象中取属性,一旦取不到,会进入到__getattr__
如果去对象中赋值属性,一旦取不到,会进入到__setattr__
如果删除对象中的属性,会进入__delattr__
class Foo:
def __init__(self,name):
self.name=name
# def __getattr__(self, item):
# # print('xxxx')
# return '你傻逼啊,没有这个字段'
# def __setattr__(self, key, value):
# print('yyyyy')
def __delattr__(self, item):
print('zzzzz')
f=Foo('nick')
# print(f.name)
# # print(f.age)
print(f.__dict__)
# print(f.name)
# f.sex='male'
del f.name
print(f.__dict__)
# 需求:类继承字典,使其具备赋值和取值的功能。
class Mydict(dict):
def __init__(self,**kwargs):
super().__init__(**kwargs)
def __getattr__(self, item):
# print(item)
return self[item]
def __setattr__(self, key, value):
self[key]=value
di=Mydict(name='lqz',age=18)
print(di['name'])
print(di.name)
di.sex='male'
di['sex']='male'
#
# # print(di['name'])
# # print(di.name)
# # di.sex=19
# # print(di.sex)
# di['sex']='male'
# print(di.sex)
元类
定义:在python中一切皆对象,而用class关键字定义的类本身也是一个对象,负责产生该对象的类称为元类,即类的类。
class Person:
def __init__(self, name):
self.name = name
p1 = Person('allen')
print(type(p1)) # <class '__main__.Person'>
print(type(Person)) # <class 'type'>
print(type(dict), type(list)) # <class 'type'> <class 'type'>
内置函数exec():把exec命令的执行当成是一个函数的执行,会将执行期间产生的名字存放于局部和全局名称空间中。
exec(object,globals,locals)三个参数介绍:
参数一:包含一系列python代码的字符串
参数二:全局作用域(字典形式),如果不指定,默认为globals()
参数三:局部作用域(字典形式),如果不指定,默认为locals()
g = {
'x': 1,
'y': 2
}
l = {}
exec('''
global x
x=100
z=200
''', g, l)
print(g) # {'x': 100, 'y': 2......}
print(l) # {'z': 200}
class底层原理分析:通过type类实例化来得到类。
type(name, bases, dict) -> a new type:创建类的三个参数
参数一:字符串形式的类名
参数二:以元组形式存在的所有父类
参数三:以字典形式存在的类名称空间
class_name = 'People' # 类名
class_bases = (object,) # 基类
# 类的名称空间
class_dic = {}
class_body = """
school = 'oldboy'
def __init__(self, name):
self.name = name
def learn(self):
print(f'{self.name} is learning')
"""
exec(class_body, {}, class_dic)
print(class_dic) # {'school': 'oldboy', '__init__': <function __init__ at 0x00000205DB894E18>, 'learn': <function learn at 0x00000205DBC05C80>}
# 创建类
People1 = type(class_name, class_bases, class_dic)
# 实例化
p1 = People1('allen')
p1.learn() # allen is learning
自定义元类控制类的行为:控制类名、控制类的继承、控制类的名称空间、控制类必须有文档。
class Mymeta(type): # 只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
def __init__(self, class_name, class_bases, class_dic):
print(self) # <class '__main__.People'>
print(class_name) # People
super(Mymeta, self).__init__(class_name, class_bases, class_dic) # 重用父类的功能
if class_name.islower():
raise Exception(f'{class_name}类名必须使用驼峰体')
if not class_dic['__doc__']:
raise Exception('类中必须有注释文档且不能为空')
class People(object, metaclass=Mymeta):
"""注释"""
school = 'oldboy'
def __init__(self, name):
self.name = name
def learn(self):
print(f'{self.name} is learning')
__call__:让对象变成一个可调用的对象
class Foo:
def __call__(self, *args, **kwargs):
print(self) # <__main__.Foo object at 0x0000015E35DBA828>
print(args) # (1, 2)
print(kwargs) # {'x': 3, 'y': 4}
return '居然对象也可变成可调用对象'
f = Foo()
res = f(1, 2, x=3, y=4)
# 1、要想让obj这个对象变成一个可调用的对象,需要在该对象的类中定义一个方法__call__方法,该方法会在调用对象时自动触发
# 2、调用obj的返回值就是__call__方法的返回值
print(res) # 居然对象也可变成可调用对象
由上例得知,调用一个对象,就是触发对象所在类中的__call__方法的执行,如果把People也当做一个对象,那么在People这个对象的类中也必然存在一个__call__方法。
class Mymeta(type):
def __call__(self, *args, **kwargs):
print(self) # <class '__main__.People'>
print(args) # ('allen',)
print(kwargs) # {}
return '居然元类中也存在__call__方法'
class People(object, metaclass=Mymeta):
def __init__(self, name):
self.name = name
def learn(self):
print(f'{self.name} is learning')
# 调用People就是在调用People类中的__call__方法
# 然后将People传给self,溢出的位置参数传给*,溢出的关键字参数传给**
# 调用People的返回值就是调用__call__的返回值
p1 = People('allen')
print(p1) # 居然元类中也存在__call__方法
默认地,调用p1 = People('allen')会做三件事
1、产生一个空对象obj
2、调用__init__方法初始化对象obj
3、返回初始化好的obj
对应着,People类中的__call__方法也应该做这三件事:
class Mymeta(type):
def __call__(self, *args, **kwargs):
print(self) # <class '__main__.People'>
# 1、调用__new__产生一个空对象obj
obj = self.__new__(self) # 此处的self是类People,必须传参,代表创建一个People的对象obj
# 2、调用__init__初始化空对象obj
self.__init__(obj, *args, **kwargs)
# 3、返回初始化好的对象obj
return obj
class People(object, metaclass=Mymeta):
def __init__(self, name):
self.name = name
def learn(self):
print(f'{self.name} is learning')
p1 = People('allen')
print(p1.__dict__) # {'name': 'allen'}
上例的__call__相当于一个模板,我们可以在该基础上改写__call__的逻辑从而控制调用People的过程,比如将People的对象的所有属性都变成私有的。
class Mymeta(type):
def __call__(self, *args, **kwargs):
print(self) # <class '__main__.People'>
# 1、调用__new__产生一个空对象obj
obj = self.__new__(self) # 此处的self是类People,必须传参,代表创建一个People的对象obj
# 2、调用__init__初始化空对象obj
self.__init__(obj, *args, **kwargs)
# 在初始化之后,obj.__dict__里就有值了
obj.__dict__ = {f'_{self.__name__}__{k}': v for k, v in obj.__dict__.items()}
# 3、返回初始化好的对象obj
return obj
class People(object, metaclass=Mymeta):
def __init__(self, name):
self.name = name
def learn(self):
print(f'{self.name} is learning')
p1 = People('allen')
print(p1.__dict__) # {'_People__name': 'allen'}
有了元类之后的属性查找顺序:
类的属性查找顺序:先从类本身中找--->mro继承关系去父类中找---->去自己定义的元类中找--->type中--->报错。
对象的属性查找顺序:先从对象自身找--->类中找--->mro继承关系去父类中找--->报错。
__new__方法
创建空对象(非真正意义上的空类对象)
class Person():
def __init__(self, name, age):
print('__init__')
self.name = name
self.age = age
def __new__(cls, *args, **kwargs): #先触发__new__方法,再触发__init__方法
print('__new__')
# 生成一个Person类的空对象
return object.__new__(cls)
p = Person('allen', 19)
print(p)
# object.__new__ 传哪个类就得到哪个类的空对象
p=object.__new__(Person)
print(p)
# __new__和__init__的区别
# __new__ 创建空对象
# __init__ 初始化空对象
# object.__new__(Person) :生成Person类的对象 空的
# type.__new__(cls,name,bases,dic) :生了cls这个类对象,里面有东西
# __init__:控制类的产生,在__new__之后
# __call__:对着对象的产生
# __new__:控制类产生最根上,其实本质最根上也不是它,是type的__call__,但是我们控制不了了
class Mymeta(type):
def __init__(self, name, bases, dic):
# self 是Person类,Person类中有名称空间之类的了
print(dic)
def __new__(cls, name, bases, dic):
# print(dic)
# 产生空对象(空类),在这里面生成的并不是空类,是有数据的类了
# 如何完成类的初始化,并且把name,bases,dic这些东西放入
# return type.__new__(cls,name,bases,dic)
dic2 = {'attr': {}}
for k, v in dic.items():
# 加入这一句,类名称空间中带__的就不会放到attr中
if not k.startswith('__'):
dic2['attr'][k] = v
print('-------', dic2)
return type.__new__(cls, name, bases, dic2)
class Person(metaclass=Mymeta): # Person=Mymeta(name,bases,dic) 调用type的__call__,内部调用了Mymeta.__new__,又调Mymeta的__init__
school = 'oldboy'
age = 10
def __init__(self, name, age):
self.name = name
self.age = age
print(Person.__dict__)
print(Person.attr['school'])
__call__方法
通过元类控制类的调用过程来控制对象的产生。
class Person:
def __init__(self, name):
self.name = name
p1 = Person('allen')
p1()# 'Person' object is not callable
class Person:
def __init__(self, name):
self.name = name
def __call__(self, *args, **kwargs): # 加上__call__方法,此时对象就可以被调用
print('哈哈哈')
p1 = Person('allen')
p1() # 哈哈哈
class Mymeta(type):
def __call__(self, *args, **kwargs): # 该方法必须返回一个类对象,这个地方返回什么,p=Person('allen'),p就是什么
# return 111
# 如何返回一个真正的Person对象:
# 1.产生一个空对象
obj = self.__new__(self) # 把类当做参数传入,产生一个该类的空对象
# 2.初始化该对象
obj.__init__(*args, **kwargs) # 对象调自己的绑定方法
# 3.返回该对象
return obj
class Person(metaclass=Mymeta):
def __init__(self, name):
self.name = name
p1 = Person('allen')#这个位置会调用元类的__call__方法,所以在__call__方法中调用了Person,__init__方法,来完成对象的初始化。
print(p1)
__init__方法
通过自定义元类,重写__init__方法来控制类的产生、名称空间、基类、类名。
# 普通类__init__的使用
class Person:
def __init__(self, name):
self.name = name
raise Exception('就不让你创建') # 实例化失败
p1 = Person('allen') # 自动触发Person类的__init__的执行
# 元类中__init__的使用
class Mymeta(type):
def __init__(self, class_name, class_bases, class_dic):
print(self)#<class '__main__.Person'>类对象
print(class_dic)#Person并非真正意义上的空类
if not class_dic.get('name'):
raise Exception('没有name属性,不能创建')
class Person(metaclass=Mymeta): # Person=Mymeta('Person',(object,),{...}) Mymeta类实例化,会把三个参数传到Mymeta的__init__方法中
def __init__(self, name):
self.name = name
p1 = Person('allen') # 自动触发Person类的__init__的执行
单例模式
定义:即单个实例,是同一个类实例化多次的结果指向同一个对象,用于节省内存空间
# 如果我们从配置文件中读取配置来进行实例化,在配置相同的情况下,就没必要重复产生对象浪费内存了
# 当用户输入端口和地址,实例化产生新对象;当用户不输入端口和地址,每次拿到的对象,都是同一个内存地址。
#settings.py
HOST='1.1.1.1'
PORT=3306
# 实现单例模式的方式一:通过类的绑定方法
import settings
class Mysql:
_instance = None
def __init__(self, host, port):
self.host = host
self.port = port
@classmethod
def singleton(cls):
if not cls._instance:
cls._instance = Mysql(settings.HOST, settings.PORT)
return cls._instance
obj1 = Mysql('127.0.0.1', '3307')
obj2 = Mysql('127.0.0.1', '3308')
print(obj1 is obj2) # False
obj3 = Mysql.singleton()
obj4 = Mysql.singleton()
print(obj3 is obj4) # True
# 实现单例模式的方式二:通过装饰器
import settings
def singleton(cls): # cls=Mysql
_instance = cls(settings.HOST, settings.PORT)
def inner(*args, **kwargs):
if args or kwargs:
res = cls(*args, **kwargs)
return res
return _instance
return inner
@singleton # Mysql=singleton(Mysql)
class Mysql:
def __init__(self, host, port):
self.host = host
self.port = port
sql1 = Mysql('127.0.0.1', 3306)
sql2 = Mysql('127.0.0.1', 3307)
print(sql1 is sql2) # False
sql3 = Mysql()
sql4 = Mysql()
print(sql3 is sql4) # True
# 实现单例模式的方式三:通过元类
import settings
class Mymeta(type):
def __init__(self, class_name, class_bases, class_dic):
# 把实例化的对象放到类名称空间中
self._instance = self(settings.HOST, settings.PORT)
def __call__(self, *args, **kwargs):
if args or kwargs:
obj = object.__new__(self)
obj.__init__(*args, **kwargs)
return obj
return self._instance
class Mysql(metaclass=Mymeta):
def __init__(self, host, port):
self.host = host
self.port = port
sql1 = Mysql('127.0.0.1', 3306)
sql2 = Mysql('127.0.0.1', 3307)
print(sql1 is sql2) # False
sql3 = Mysql()
sql4 = Mysql()
print(sql3 is sql4) # True
# 实现单例模式的方式四:通过模块导入(python模块是天然的单例)
from singleton import sql
def sql1():
print(sql)
def sql2():
print(sql)
print(sql1() is sql2()) # True