Zookeeper
1. Zookeeper
1.1. ZooKeeper 概述
Zookeeper 是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题。
ZooKeeper 本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。诸如:统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等功能。
1.2. ZooKeeper 集群角色

Leader: Zookeeper 集群工作的核心,主要工作如下
事物请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性; 集群内部各个服务器的调度者。
对于 create,setData,delete 等有写操作的请求,则需要统一转发给leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
Follower:
处理客户端非事物(读操作)请求,转发事物请求给 Leader; 参与集群 Leader 选举投票。
Observer:
充当观察者角色,观察 Zookeeper 集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给
Leader 服务器进行处理。
不会参与任何形式的投票只提供非事物服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事物处理能力。
1.3. zookeeper 特性
- 全局数据一致:每个 server 保存一份相同的数据副本,client 无论连接到哪个 server,展示的数据都是一致的,这是最重要的特征;
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必将排在 b 前面。
- 数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态;
- 实时性:Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
1.4. ZooKeeper 集群搭建
Zookeeper 集群搭建指的是 ZooKeeper 分布式模式安装。通常由 2n+1 台 servers 组成。这是因为为了保证 Leader 选举(基于 Paxos 算法的实现)能过得到多数的支持,所以 ZooKeeper 集群的数量一般为奇数。
Zookeeper 运行需要 java 环境,所以需要提前安装 jdk。对于安装
leader+follower 模式的集群,大致过程如下:
l 配置主机名称到 IP 地址映射配置
l 修改 ZooKeeper 配置文件
l 远程复制分发安装文件
l 设置 myid
l 启动 ZooKeeper 集群
如果要想使用 Observer 模式,可在对应节点的配置文件添加如下配置: peerType=observer
其次,必须在配置文件指定哪些节点被指定为 Observer,如: server.1:localhost:2181:3181:observer
详细步骤请参考附件安装资料。
2. Zookeeper shell
2.1. 客户端连接
运行 zkCli.sh –server ip 进入命令行工具。输入 help,输出 zk shell 提示:

2.2. shell 基本操作
创建节点
create [-s] [-e] path data acl
其中,-s 或-e 分别指定节点特性,顺序或临时节点,若不指定,则表示持久节点;acl 用来进行权限控制。
创建顺序节点:

创建临时节点:

创建永久节点:

读取节点
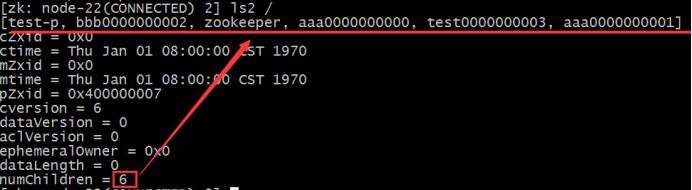
与读取相关的命令有 ls 命令和 get 命令,ls 命令可以列出 Zookeeper 指定节点下的所有子节点,只能查看指定节点下的第一级的所有子节点;get 命令可以获取 Zookeeper 指定节点的数据内容和属性信息。
ls path [watch]
get path [watch]
ls2 path [watch]
更新节点
set path data [version]
data 就是要更新的新内容,version 表示数据版本。
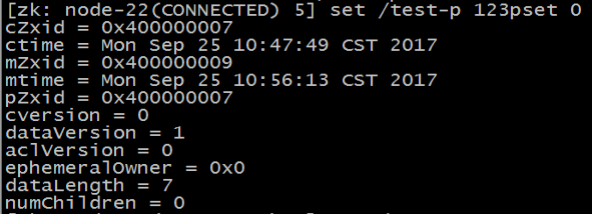
现在 dataVersion 已经变为 1 了,表示进行了更新。
删除节点
delete path [version]
若删除节点存在子节点,那么无法删除该节点,必须先删除子节点,再删除
父节点。
Rmr path
可以递归删除节点。
quota
setquota -n|-b val path 对节点增加限制。n:表示子节点的最大个数 b:表示数据值的最大长度
val:子节点最大个数或数据值的最大长度path:节点路径
listquota path 列出指定节点的 quota

子节点个数为 2,数据长度-1 表示没限制delquota [-n|-b] path 删除 quota

其他命令
history : 列出命令历史
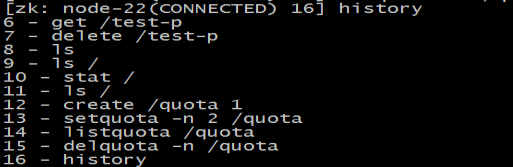
redo:该命令可以重新执行指定命令编号的历史命令,命令编号可以通过
history 查看
3. zookeeper 数据模型
ZooKeeper 的数据模型,在结构上和标准文件系统的非常相似,拥有一个层次的命名空间,都是采用树形层次结构,ZooKeeper 树中的每个节点被称为—
Znode。和文件系统的目录树一样,ZooKeeper 树中的每个节点可以拥有子节点。但也有不同之处:
- Znode 兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分,并可以具有子 Znode。用户对 Znode 具有增、删、改、查等操作(权限允许的情况下)。
- Znode 具有原子性操作,读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的 ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
- Znode 存储数据大小有限制。ZooKeeper 虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据, 比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以 KB 为大小单位。ZooKeeper 的服务器和客户端都被设计为严格检查并限制每个 Znode 的数据大小至多 1M,当时常规使用中应该远小于此值。
- Znode 通过路径引用,如同 Unix 中的文件路径。路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。在 ZooKeeper 中,路径由
Unicode 字符串组成,并且有一些限制。字符串"/zookeeper"用以保存管理信息,比如关键配额信息。
3.1. 数据结构图
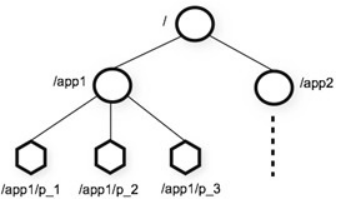
图中的每个节点称为一个 Znode。 每个 Znode 由 3 部分组成:
① stat:此为状态信息, 描述该 Znode 的版本, 权限等信息
② data:与该 Znode 关联的数据
③ children:该 Znode 下的子节点
3.2. 节点类型
Znode 有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,当然可以也可以手动删除。临时节点不允许拥有子节点。
永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
Znode 还有一个序列化的特性,如果创建的时候指定的话,该 Znode 的名字后面会自动追加一个不断增加的序列号。序列号对于此节点的父节点来说是唯一的,这样便会记录每个子节点创建的先后顺序。它的格式为“%10d”(10 位数字, 没有数值的数位用 0 补充,例如“0000000001”)。

这样便会存在四种类型的 Znode 节点,分别对应: PERSISTENT: 永 久 节 点 EPHEMERAL:临时节点
PERSISTENT_SEQUENTIAL:永久节点、序列化EPHEMERAL_SEQUENTIAL:临时节点、序列化
3.3. 节点属性
每个 znode 都包含了一系列的属性,通过命令 get,可以获得节点的属性。
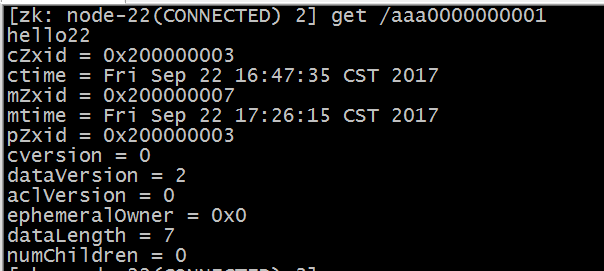
dataVersion:数据版本号,每次对节点进行 set 操作,dataVersion 的值都会增加 1(即使设置的是相同的数据),可有效避免了数据更新时出现的先后顺序问题。
cversion :子节点的版本号。当 znode 的子节点有变化时,cversion 的值就会增加 1。
aclVersion :ACL 的版本号。cZxid :Znode 创建的事务 id。
mZxid :Znode 被修改的事务 id,即每次对 znode 的修改都会更新 mZxid。对于 zk 来说,每次的变化都会产生一个唯一的事务 id,zxid(ZooKeeper
Transaction Id)。通过 zxid,可以确定更新操作的先后顺序。例如,如果 zxid1小于 zxid2,说明 zxid1 操作先于 zxid2 发生,zxid 对于整个 zk 都是唯一的, 即使操作的是不同的 znode。
ctime:节点创建时的时间戳.
mtime:节点最新一次更新发生时的时间戳.
ephemeralOwner:如果该节点为临时节点, ephemeralOwner 值表示与该节点绑定的 session id. 如果不是, ephemeralOwner 值为 0.
在 client 和 server 通信之前,首先需要建立连接,该连接称为 session。连接建立后,如果发生连接超时、授权失败,或者显式关闭连接,连接便处于 CLOSED 状态, 此时 session 结束。
4. Zookeeper Watch
Watch 说的是 Zookeeper 的监听机制。一个 Watch 事件是一个一次性的触发器,当被设置了 Watch 的数据发生了改变的时候,则服务器将这个改变发送给设置了 Watch 的客户端,以便通知它们。
改变有很多种方式,如:节点创建,节点删除,节点改变,子节点改变等。
4.1. Watch 机制特点
一次性触发
数据发生改变时,一个 watcher event 会被发送到 client,但是 client 只会收到一次这样的信息。
Watcher event 异步发送
watcher 的通知事件从 server 发送到 client 是异步的。数 据 监 视 Zookeeper 有数据监视和子数据监视
getdata() 、 exists() 设置数据监视getchildren()设置了子节点监视
注册 watcher
getData、exists、getChildren 触发 watcher create、delete、setData
4.2. Watch 的事件类型
Zookeeper 的 watch 实际上要处理两类事件
l 连接状态事件(type=None, path=null)
这类事件不需要注册,也不需要我们连续触发,我们只要处理就行了。None 在客户端与 Zookeeper 集群中的服务器断开连接的时候,客户端会收到这个事件。
l 节点事件
节点的建立,删除,数据的修改。
NodeCreated Znode 创建事件NodeDeleted Znode 删除事件
NodeDataChanged Znode 数据内容更新事件。其实本质上该事件只关注
dataVersion 版本号,但是只要调用了更新接口 dataVersion 就会有变更。NodeChildrenChanged Znode 子节点改变事件,只关注子节点的个数变更,子节点内容有变更是不会通知的。
4.3. Shell 客户端设置 watch
设置节点数据变动监听:

通过另一个客户端更改节点数据:

此时设置监听的节点收到通知:

5. Zookeeper 客户端 API
org.apache.zookeeper.Zookeeper 是客户端入口主类,负责建立与 server 的会话,它提供以下几类主要方法:
create 在本地目录树中创建一个节点delete 删除一个节点
exists 测试本地是否存在目标节点
get/set data 从目标节点上读取 / 写数据get children 检索一个子节点上的列表
5.1. 基本使用
建立 java maven 项目,引入 maven pom 坐标。
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.9</version>
</dependency>
5.2. 操作示例
public static void main(String[] args) throws Exception { // 初始化 ZooKeeper 实例(zk 地址、会话超时时间,与系统默认一致、watcher) ZooKeeper zk = new ZooKeeper("node-21:2181,node-22:2181", 30000, new Watcher() { @Override public void process(WatchedEvent event) { System.out.println("已经触发了" + event.getType() + "事件!"); } }); // 创建一个目录节点 zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); // 创建一个子目录节点 zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT); System.out.println(new String(zk.getData("/testRootPath",false,null))); // 取出子目录节点列表 System.out.println(zk.getChildren("/testRootPath",true)); // 修改子目录节点数据 zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1); System.out.println("目录节点状态:["+zk.exists("/testRootPath",true)+"]"); // 创建另外一个子目录节点 zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT); System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo",true,null))); // 删除子目录节点 zk.delete("/testRootPath/testChildPathTwo",-1); zk.delete("/testRootPath/testChildPathOne",-1); // 删除父目录节点 zk.delete("/testRootPath",-1); zk.close(); }
- Zookeeper 选举机制
zookeeper 默认的算法是 FastLeaderElection,采用投票数大于半数则胜出的逻辑。
6.1. 概念
服务器 ID
比如有三台服务器,编号分别是 1,2,3。编号越大在选择算法中的权重越大。
选举状态
LOOKING,竞选状态。
FOLLOWING,随从状态,同步 leader 状态,参与投票。OBSERVING,观察状态,同步 leader 状态,不参与投票。LEADING,领导者状态。
数据 ID
服务器中存放的最新数据 version。
值越大说明数据越新,在选举算法中数据越新权重越大。逻辑时钟
也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比, 根据不同的值做出不同的判断。
6.2. 全新集群选举
假设目前有 5 台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
l 服务器 1 启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器 1 的状态一直属于 Looking。
l 服务器 2 启动,给自己投票,同时与之前启动的服务器 1 交换结果,由于服务器 2 的编号大所以服务器 2 胜出,但此时投票数没有大于半数, 所以两个服务器的状态依然是 LOOKING。
l 服务器 3 启动,给自己投票,同时与之前启动的服务器 1,2 交换信息, 由于服务器 3 的编号最大所以服务器 3 胜出,此时投票数正好大于半数, 所以服务器 3 成为领导者,服务器 1,2 成为小弟。
l 服务器 4 启动,给自己投票,同时与之前启动的服务器 1,2,3 交换信息, 尽管服务器 4 的编号大,但之前服务器 3 已经胜出,所以服务器 4 只能成为小弟。
l 服务器 5 启动,后面的逻辑同服务器 4 成为小弟。
6.3. 非全新集群选举
对于运行正常的 zookeeper 集群,中途有机器 down 掉,需要重新选举时, 选举过程就需要加入数据 ID、服务器 ID 和逻辑时钟。
数据 ID:数据新的 version 就大,数据每次更新都会更新 version。服务器 ID:就是我们配置的 myid 中的值,每个机器一个。
逻辑时钟:这个值从 0 开始递增,每次选举对应一个值。 如果在同一次选举中,这个值是一致的。
这样选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票;
2、统一逻辑时钟后,数据 id 大的胜出;
3、数据 id 相同的情况下,服务器 id 大的胜出; 根据这个规则选出 leader。
- Zookeeper 典型应用
7.1. 数据发布与订阅(配置中心)
发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到 ZK 节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。
应用在启动的时候会主动来获取一次配置,同时,在节点上注册一个 Watcher, 这样一来,以后每次配置有更新的时候,都会实时通知到订阅的客户端,从来达 到获取最新配置信息的目的。比如:
分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在 ZK 的一些指定节点,供各个客户端订阅使用。
注意:适合数据量很小的场景,这样数据更新可能会比较快。
7.2. 命名服务(Naming Service)
在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用 ZK 提供的创建节点的 API,能够很容易创建一个全局唯一的 path,这个 path 就可以作为一个名称。
阿里巴巴集团开源的分布式服务框架 Dubbo 中使用 ZooKeeper 来作为其命名服务,维护全局的服务地址列表。
7.3. 分布式锁
分布式锁,这个主要得益于 ZooKeeper 保证了数据的强一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把 zk 上的一个 znode 看作是一把锁,通过 create
znode 的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
控制时序,就是所有试图来获取这个锁的客户端,最终都是会被安排执行, 只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:
CreateMode.EPHEMERAL_SEQUENTIAL 来指定)。Zk 的父节点(/distribute_lock) 维持一份 sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。