目录:
1、安装Centos7
2、安装JDK1.7
3、安装Hadoop2.9.2
该配置过程摘抄于本人讲师,并非原创
1、安装Centos7
Centos7安装过程略,配置静态IP,关闭防火墙。
配置静态IP:
vi /etc/sysconfig/network-scripts/ifcfg-ens3
关闭防火墙:



TYPE=Ethernet PROXY_METHOD=none #BROWSER_ONLY=no BOOTPROTO=dhcp DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no #IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=c512d18c-000d-4bd8-bb3d-1a7eab3ee246 DEVICE=ens33 #ONBOOT=yes BOOTPROTO=static ONBOOT=yes IPADDR=192.168.19.16 NETMASK=255.255.255.0 GATEWAY=192.168.19.2 DNS1=8.8.8.8 DNS2=144.144.144.144 ZONE=public
2、安装JDK1.7
地址https://pan.baidu.com/s/1HlkngnG5H8JAdm0zYezEyg 提取码3z6s
下载后上传到centos中,然后cp到/usr/local下,然后解压:
tar -zxvf jdk-7u45-linux-x64.tar.gz
然后配置环境变量:
vim /etc/profile 然后在文件末尾加上: ############################### JAVA_HOME=/usr/local/jdk1.7.0_45 export JAVA_HOME export PATH=$JAVA_HOME/bin:$PATH ###############################
然后刷新环境变量:source /etc/profile,测试JDK安装成功:java -version,出现版本则成功。
3、安装Hadoop2.9.2
将Hadoop2.9.2下载后,传到linux的/usr/local中去。
地址http://mirrors.hust.edu.cn/apache/hadoop/common/
解压: tar -zxvf hadoop-2.9.2.tar.gz
(1):配置hadoop环境变量 vi /etc/profile 添加如下配置
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$PATH
然后刷新配置:source /etc/profile
完成后命令:hadoop version,出现版本号则成功。
然后切换到配置文件目录:cd /usr/local/hadoop-2.9.2/etc/hadoop/
(2):vim core-site.xml 添加如下配置
<property>
<name>fs.defaultFS</name>
<!-- 这里填的是你自己的ip,端口默认-->
<value>hdfs://192.168.124.144:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 这里填的是你自定义的hadoop工作的目录,端口默认-->
<value>/usr/local/hadoop-2.9.2/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>Should native hadoop libraries, if present, be used.
</description>
</property>
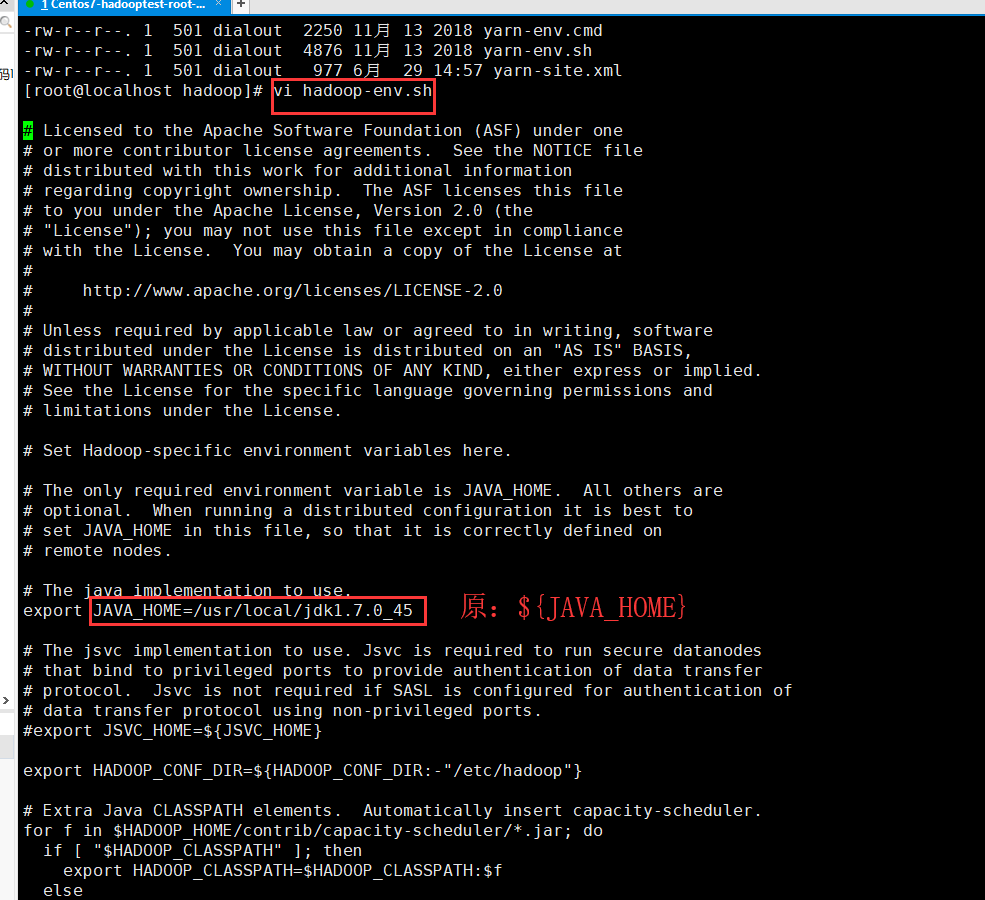
(3):vi hadoop-env.sh 配置成你自己的jdk安装路径
(4):vi hdfs-site.xml 添加如下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<!--这里是你自己的ip,端口默认-->
<value>192.168.124.144:50090</value>
</property>
(5):复制默认的模板配置文件,输入命令:cp mapred-site.xml.template ./mapred-site.xml 配置命名为mapred-site.xml
(6):vim mapred-site.xml 添加如下配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(7):配置yarn-site.xml ,vim yarn-site.xml 添加如下配置
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 自己的ip端口默认 -->
<value>192.168.124.144</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(8):配置好之后切换到sbin目录下
/usr/local/hadoop-2.9.2/sbin
(9):格式化hadoop文件格式,执行命令 hadoop namenode -format,注意不用 “./”
(10): 执行启动命令:./start-all.sh
注意:启动过程中启动每一个进程都会让你确认或输入密码,可以通过配置ssh来解决,就不需要输入了,暂时配置使用jps查看进程,能看到这些进程证明启动成功了,也可以在浏览器输入localhost:50070看是否出现网页,或者在物理机输入IP地址:50070,出现以下界面:

完成!
该配置过程摘抄于本人讲师,并非原创