粒度:
交换机(二层):目的MAC地址
路由器(三层):目的IP地址
防火墙和负载均衡器(四层):会话
会话的标记为:从同一个域到域的数据流,以第一个SYN数据包的源和目的IP地址及其源和目的端口为标识
防火墙特性:
- 将所有会话做监控管理,默认限制所有会话,再逐一放行会话。
注意:如上会话标记的定义,如果限定了从192.13.2.1:23发送数据到182.12.12.1:12,是无法同时限定从182.12.12.1:12发送数据到192.13.2.1:23,记住会话是双向的。
2.NAT
用途
a.解决地址紧张的问题
b.更安全,由于用户端IP地址未暴露在互联网,用户侧更安全,运营商也可以防止用户上挂恶意内容在互联网
问题:
多通道协议受阻,alg解决问题。比如ftp控制和数据分离。
注意:如上条注意,会话是双向的,NAT基于会话的,也同样是双向的。基于源IP或者IP:PORT,是源NAT;基于目的IP或者IP:PORT,是目的NAT。

3.VPN
主要用途:a.认证,双方身份确认;b.鉴权,授权可以使用的服务和数据流;c.加密,对数据流进行加密处理;d.网络扩展,实现远端网络本地化
分类:基于不同的套接层,分为——二层L2TP,三层MPLS/GRE/IPSEC,七层SSL(SSL_VPN/SSH)
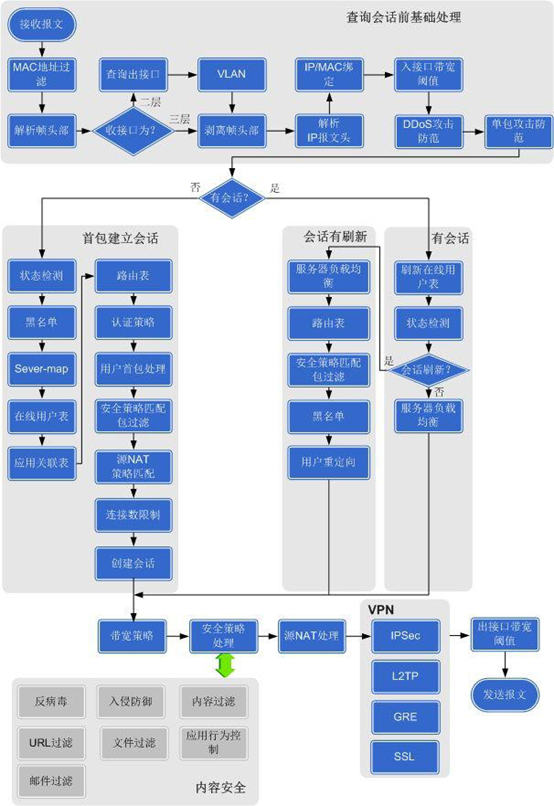
以下为华为防火墙数据流处理过程:
负载均衡(F5/Citrix)
不管是交换机,路由器,还是防火墙,对数据包的处理,总得来说都是两个过程。
- 首先是按照粒度识别数据流,然后进行匹配归类
这个归类交换机查询的是MAC地址表,路由器查询的是IP路由表,防火墙查询的是会话列表等
- 然后是再处理的过程,一般是转发处理。
一般有两种可能,一是多出口;二是基于不同的Qos考虑是否缓存延迟发送,还是丢弃。
负载均衡器处理方式是什么呢?
识别过程:
基于MAC/IP/端口号(协议)/http头(host、url、文件格式、浏览器、操作系统等),进而归类;
转发过程(负载均衡的前提是多出口):
a.根据是否超过出口设定的阈值,分为以下两种情况:
阈值内:基于不同的负载均衡算法,将流量分摊到多出口
超过阈值:将不转发到超过阈值出口;所有出口都超过阈值,不能像路由交换设备采用丢弃策略,而是会配置默认出口(一般为默认网关),转发超过部分的流量。
b.过载保护,阈值设定
一般采用最大连接数、最大带宽、最大客户端数量等因子。
c.负载均衡算法
数据包在转发的时候,可以基于以下因子算法来负载均衡转发到不同的出口:
Least Connections
Round Robin
Least response time
Least bandwidth
Least packets URL hashing
Domain name hashing
Source IP address hashing
Destination IP address hashing
Source IP - Destination IP hashing
Token LRTM
d.会话保持
交换机/路由器上,基于TRUNK、多路由(包括策略路由、多静态路由、OSPF等的等价路由等)等二三层的负载均衡技术,可能会出现乱序包。负载均衡器后面如果带的是几个服务器的话,一般是不允许让同一个连接的数据包,发送到不同的服务器上的。所以才有了该特性会话保持,会话保持基于的因子有如下:
Source IP
Cookie insert
SSL session ID
URL passive
Custom Server ID
Rule
DESTIP
注:其实在trunk上发送的发射可以设定hash,来转发数据到特定的口,比如ethrunk。
e.上下行接口绑定技术
当做负载均衡的时候,只是考虑了请求流量出口的负载情况,但是却未考虑返回流量的出口情况。理想状况是,从线路1进来的请求,最后返回的结果也从线路1回去。
从F5和netscaler都只有类似的功能分别叫outbound和lld。
f.互联网出流量优化
在互联网对接口上,为了保证到对应运营商的流量能够指定转发。不仅仅是F5(outbound)和citrix(lld)支持,就是防火墙也提供该特性。
代理方式:
|
名称 |
目的IP地址 |
源IP地址 |
是否中断TCP链 |
位置 |
|
正向代理 |
代理IP——>源站IP |
客户端IP——>代理IP |
是 |
客户侧行为 |
|
反向代理 |
不一定 |
不一定 |
不一定 |
服务侧行为 |
|
透明代理 |
源站ip |
客户端IP |
是 |
中间商行为 |
同源同宿
同源同宿指属于同一个网络连接的双向数据报文必须从同一个输出接口输出。比如,网络流量分析(DPI)中,仅分析通信双方的单向流量是不够的,往往需要结合通信双方的双向流量才能全面分析流量包含的信息,因此需要将通信双方的报文分流到同一台流分析服务器,这就要求分流设备在特定的转发流程中支持同源同宿。
同源同宿的特性:
1.将某一个TCP链接流,转发到特定的出口;
2.上下行流量,都能得到相同的hash值,从而可以发送到指定接口。
同样在华为93上也支持同源同宿,分别有支持eth-trunk和多等价路由等。
例如当93作为负载均衡器的时候,服务于代理服务器,特别是透明模式的时候,可以采用多条缺省路由加同源同宿作为负载均衡的方案。
用户请求的流量和代理服务器回源的流量,经过同源同宿后准确的发送到特定的服务器上。而代理服务器发送的请求和返回客户的响应,一般在93上走的是策略路由。
为了满足同源同宿的特性,我处揣测如下两种算法:
设一端为A=IP1:PORT1,另一端为B=IP2:PORT2。
算法一:a.满足第一特性,MOD(hash(AB)),即先将A和B连接成为一个新的数据,并做hash,再对该hash值,对后端出口数求余,依次一一对应转发;
b.满足第二特性,先比较A和B的值,将较小者排在前面,不管A是源地址,还是B是源地址。
算法二:mod(hash(A xor B)),不管A是源地址还是目的地址,异或之后将得到一样的值,然后再hash,求余即可。这种靠谱,简单,实现有效。
HA或者容灾什么的,主要思想和VRRP差不多。一个心跳平面,一个业务平面。心跳告知双方健康否,业务平面传送业务。最后都是在一个局域网里面通过响应免费ARP来控制,转发到哪一台。一般建议心跳和业务在同一个局域网内,心跳失败,则业务失败,ARP也算失败。
关于负载均衡算法,不同算法各有优劣,简单说下:
a.最小连接负载均衡算法
当前我们使用的负载均衡算法为最小连接数负载均衡
最小连接数负载均衡算法是一种基于iso/osi参考模型传输层的算法。由于负载均衡器后端服务器的配置不尽相同,对于请求的处理有快有慢。该算法可以根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
对于基于TCP连接的HTTP、HTTPS和SSL_TCP等服务,在负载均衡器上一般有如下两种连接情况:
- 已建链连接,这些连接是从客户端发送到达负载均衡器,并且负载均衡器已经转发给了后台的服务器。
- 等待连接。任何来自于外端的连接,都会先保存在队列里面,等待负载均衡器转发给后端服务器。
连接等待的情况,任何时候都可能发生,一般有以下几方面原因:
A. 负载均衡器上针对每台服务器都配置了最小连接数限制,并且当前所有的服务器服务器的连接数都超过了阈值;
B. 负载均衡器配置了针对后端服务器的过载保护,比如带宽等,当超过了配置阈值,将不再转发请求给后端服务器;
C. 后端服务器达到了连接数上限,因此将不再新增服务连接。
最小连接算法能够很好的均衡连接数到后端服务器。如果后端服务器的性能相当是特别适用的,否则会不尽合理。例如,考虑如下情况:后端服务器有两台A和B。服务器A处理连接数上线是100,已经有95条活跃连接。服务器B处理连接数上线是500,当前活跃连接数为96。当前情况下,如果使用最小连接数算法选择服务器,由于A服务器的活跃连接数较小,即使链接数情况已经接近其能力上线,接下来的请求连接,负载均衡器还是会转发给A服务器而不是B服务器。
由于负载均衡器只能感知当前活跃连接数情况,而未知后端服务器实际处理能力情况。采用最小链接算法,将无法完美的服务于差异性的负载均衡,那么基于权重的最小连接数负载均衡算法应运而生。
基于权重的最小连接负载均衡算法,选择通过以下表达式的值(Nw)决定将服务转发给后端的服务器。负载均衡器始终将新的请求转发给各台服务器计算情况得到的Nw最小值
Nw = (当前活跃连接数) * (10000 / 权重)
备注:权重是我们加以设定的值。
b.最小连接数算法缺陷
如果web缓存系统采用最小连接数负载均衡的话,将有很大可能遇到如下这种情况:
前提:假定有三台web缓存服务器在负载均衡器后面,分别为服务器A、服务器B和服务器C,并且web缓存服务器假定被访问一次就会被缓存。
当有一个用户U1访问大小为100MB的资源S,LBS将该资源的请求转发给了服务器A,服务器A随及从源站回源,并经过查询能够提供缓存服务,就将该资源S存储在了本机磁盘上,并将源站响应的资源S吐出给用户U1。由此当前资源S占用磁盘资源100M。
当有另一个用户U2再次访问同一个资源S,如果将他的请求转发给服务器A,服务器A就可以直接将资源S吐出给用户U2。但是很不幸,经过负载均衡器,将请求转发给了服务器B。由此服务器B从源站回源,并经过查询能够提供缓存服务,也将该资源S存储在了本机磁盘上,并将源站响应的资源S吐出给用户U2。首先占用了额外回源一次S的带宽,破坏了WEB缓存系统的初衷,节省带宽;再就是再次在磁盘上存储了一次,由此加上服务器A上的,总共占用磁盘200M。
同理如果用户U3访问同一个资源,并且转发给了服务器C。又会再次造成带宽和磁盘的资源浪费。
很明显基于四层的负载均衡算法是无法满足web缓存系统要求的。必须提供一种能够对资源进行唯一识别的算法,将资源有效的负载均衡到后端服务器。这就是下面要提到的优化方案url_hash负载均衡算法。
c.url_hash负载均衡算法
URL(Uniform/Universal Resource Locator的缩写,统一资源定位符)是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址的。现在它已经被万维网联盟编制为因特网标准RFC1738了。一个完整的URL包括访问协议类型、主机地址、路径和文件名。例如:http://www.uestc.edu.cn/。
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
url_hash负载均衡算法基于url进行hash计算,然后通过hash结果找到对应的服务器。因为针对单一个url的hash结果是一样的,所以理论上这个url会被永久分配到固定的一台服务器上。另外因为经过了hash算法,所以分配url就很均匀,同时访问量也可以达到均衡。这类算法有多种,比如:
hash+求余的算法
首先将从用户端到负载均衡器的url中的前一部分(一般为80字节)做hash得到hash值P。再将该值使用后端服务器的数量N相除求余(记为MOD(P,N)),再进行一对一的业务分配。比如有3台设备,分别为A、B、C。hash值除以3,求余得0,就分配与A;求余得1,分配给B;求余得2,分配给C。
该算法简单,对负载均衡器性能消耗少,反应速度快。但是如果当后台服务器中有一台设备挂掉之后,所有资源都将经过重新计算,重新存储服务。
完全使用hash算法
对服务器的IP地址进行一次hash得到hash值P1,对从用户端到负载均衡器的url中的前一部分(一般为80字节)做hash得到hash值P2。再将这两个hash值P1和P2进行hash,得到hash值P3。最后将用户端请求转发到hash值P3最大的服务器上。比如有三台设备,分别为
A、B、C,分别计算后得到的P3值:P3(B)>P3(A)>P3(C)。那么负载均衡器将该用户端请求转发到服务器B上去。
该算法经过了三次hash,对设备性能相对前面一种算法有更大的消耗。但是即使其中一台挂掉了,也只是影响挂掉那台设备的资源重新计算而已,受影响的范围较小。
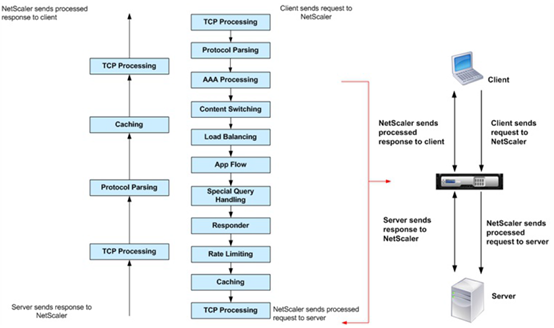
附,下图显示了 NetScaler 中的 L7 数据包流。
L7 数据包流图

下图显示了 NetScaler 中的 DataStream 数据包流
更多细节请查看F5/Netscaler/华为防火墙等相关产品文档,及其相关RFC。