报警处理流程如下:
1. Prometheus Server监控目标主机上暴露的http接口(这里假设接口A),通过Promethes配置的'scrape_interval'定义的时间间隔,定期采集目标主机上监控数据。
2. 当接口A不可用的时候,Server端会持续的尝试从接口中取数据,直到"scrape_timeout"时间后停止尝试。这时候把接口的状态变为“DOWN”。
3. Prometheus同时根据配置的"evaluation_interval"的时间间隔,定期(默认1min)的对Alert Rule进行评估;当到达评估周期的时候,发现接口A为DOWN,即UP=0为真,激活Alert,进入“PENDING”状态,并记录当前active的时间;
4. 当下一个alert rule的评估周期到来的时候,发现UP=0继续为真,然后判断警报Active的时间是否已经超出rule里的‘for’ 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则alert的状态变为“FIRING”;同时调用Alertmanager接口,发送相关报警数据。
5. AlertManager收到报警数据后,会将警报信息进行分组,然后根据alertmanager配置的“group_wait”时间先进行等待。等wait时间过后再发送报警信息。
6. 属于同一个Alert Group的警报,在等待的过程中可能进入新的alert,如果之前的报警已经成功发出,那么间隔“group_interval”的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个group的报警信息会汇总在一个邮件里进行发送。
7. 如果Alert Group里的警报一直没发生变化并且已经成功发送,等待‘repeat_interval’时间间隔之后再重复发送相同的报警邮件;如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待group_interval时间间隔后重复发送。
同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里有alertmanager的route路由规则进行配置。
alertmanager配置文件
kind: ConfigMap apiVersion: v1 metadata: name: alertmanager namespace: monitor-sa data: alertmanager.yml: |- global: resolve_timeout: 1m #解析超时时间 smtp_smarthost: 'smtp.163.com:25' smtp_from: '*****@163.com' smtp_auth_username: '138****' smtp_auth_password: '****GRMBHNBOY' #登录授权码 smtp_require_tls: false route: #告警分发策略 group_by: [alertname] #分组标签依据 group_wait: 10s #告警等待时间 在等待时间内组中产生新的告警 一起进行发送 group_interval: 10s #不同组告警 间隔时间 repeat_interval: 10m #重复告警间隔时间 receiver: default-receiver #设置默认告警接收人 receivers: #告警接收 - name: 'default-receiver' email_configs: - to: '******@qq.com' send_resolved: true - to: '******@qq.com' send_resolved: true
alertmanager配置文件解释说明: smtp_smarthost: 'smtp.163.com:25' #163邮箱的SMTP服务器地址+端口 smtp_from: '15011572657@163.com' #这是指定从哪个邮箱发送报警 smtp_auth_username: '15011572657' #这是发送邮箱的认证用户,不是邮箱名 smtp_auth_password: ' BGWHYUOSOOHWEUJM' #这是发送邮箱的授权码而不是登录密码,你们需要用自己的,不要用我的,用我的你会发不出来报警 email_configs: - to: '1980570647@qq.com' #to后面指定发送到哪个邮箱,我发送到我的qq邮箱,大家需要写自己的邮箱地址,不应该跟smtp_from的邮箱名字重复 route: #用于设置告警的分发策略 group_by: [alertname] #alertmanager会根据group_by配置将Alert分组 group_wait: 10s # 分组等待时间。也就是告警产生后等待10s,如果有同组告警一起发出 group_interval: 10s # 上下两组发送告警的间隔时间 repeat_interval: 10m # 重复发送告警的时间,减少相同邮件的发送频率,默认是1h receiver: default-receiver #定义谁来收告警
安装prometheus+alertmanager
prometheus+alertmanager配置文件


kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sa data: prometheus.yml: | rule_files: - /etc/prometheus/rules.yml alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::d+)?;(d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: 'kubernetes-pods' kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: true source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_scrape - action: replace regex: (.+) source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::d+)?;(d+) replacement: $1:$2 source_labels: - __address__ - __meta_kubernetes_pod_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: kubernetes_pod_name - job_name: 'kubernetes-schedule' scrape_interval: 5s static_configs: - targets: ['172.17.166.217:10251','172.17.166.218:10251','172.17.166.219:10251'] - job_name: 'kubernetes-controller-manager' scrape_interval: 5s static_configs: - targets: ['172.17.166.217:10252','172.17.166.218:10252','172.17.166.219:10252'] - job_name: 'kubernetes-kube-proxy' scrape_interval: 5s static_configs: - targets: ['172.17.166.219:10249','172.17.27.255:10249','172.17.27.248:10249','172.17.4.79:10249'] - job_name: 'pushgateway' scrape_interval: 5s static_configs: - targets: ['172.17.166.217:9091'] honor_labels: true - job_name: 'kubernetes-etcd' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.pem cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/kubernetes.pem key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/kubernetes-key.pem scrape_interval: 5s static_configs: - targets: ['172.17.166.219:2379','172.17.4.79:2379','172.17.27.255:2379','172.17.27.248:2379'] rules.yml: | groups: - name: example rules: - alert: kube-proxy的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: kube-proxy的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: scheduler的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: scheduler的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: controller-manager的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: controller-manager的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: apiserver的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: apiserver的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: etcd的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: etcd的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: kube-state-metrics的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: coredns的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: coredns的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: kube-proxy打开句柄数>600 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kube-proxy打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>600 expr: process_open_fds{job=~"kubernetes-schedule"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-schedule"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>600 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>600 expr: process_open_fds{job=~"kubernetes-apiserver"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>600 expr: process_open_fds{job=~"kubernetes-etcd"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-etcd"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 600 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 1000 for: 2s labels: severity: critical annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000" value: "{{ $value }}" - alert: kube-proxy expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 6000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: scheduler expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 6000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-controller-manager expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 6000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-apiserver expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 6000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过6G" value: "{{ $value }}" - alert: kubernetes-etcd expr: (process_virtual_memory_bytes{job=~"kubernetes-etcd"}) / 10 > 6000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过6G" value: "{{ $value }}" - alert: kube-dns expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 6000000000 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过6G" value: "{{ $value }}" - alert: HttpRequestsAvg expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000" value: "{{ $value }}" threshold: "1000" - alert: Pod_restarts expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0 for: 2s labels: severity: warnning annotations: description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的" value: "{{ $value }}" threshold: "0" - alert: Pod_waiting expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中" value: "{{ $value }}" threshold: "1" - alert: Pod_terminated expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除" value: "{{ $value }}" threshold: "1" - alert: Etcd_leader expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader" value: "{{ $value }}" threshold: "0" - alert: Etcd_leader_changes expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变" value: "{{ $value }}" threshold: "0" - alert: Etcd_failed expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败" value: "{{ $value }}" threshold: "0" - alert: Etcd_db_total_size expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G" value: "{{ $value }}" threshold: "10G" - alert: Endpoint_ready expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用" value: "{{ $value }}" threshold: "1" - name: 物理节点状态-监控告警 rules: - alert: 物理节点cpu使用率 expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90 for: 2s labels: severity: ccritical annotations: summary: "{{ $labels.instance }}cpu使用率过高" description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率 expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}内存使用率过高" description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: InstanceDown expr: up == 0 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}: 服务器宕机" description: "{{ $labels.instance }}: 服务器延时超过2分钟" - alert: 物理节点磁盘的IO性能 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) > 6000000 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})" - alert: 入网流量带宽 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: 出网流量带宽 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流出网络带宽过高!" description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)" - alert: 磁盘容量 expr: 100 - ( node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100 ) > 80 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!" description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
常用报警参数指标:
- process_cpu_seconds_total 各targets cpu总数(cpu默认采集数据类型counter 使用rate提取一定时间内 数率变化)
- process_open_fds 各targets 文件打开句柄数 (通常每个链接会占用一个句柄数 也就是一个连接数)
- process_virtual_memory_bytes 各targets 虚拟内存使用
- rest_client_requests_total 各targets TPS (TPS指一定的时间内请求的数量~吞吐量)
- kube_pod_container_status_restarts_total (pod重启状态)
- kube_pod_container_status_waiting_reason (pod启动异常 指的是pod 容器启动状态在等待中)
- kube_pod_container_status_terminated_reason (pod删除状态)
- etcd_server_leader_changes_seen_total (etcd的leader 也就是主是否重新选举 leader发生变化)
- etcd_server_proposals_failed_total (etcd服务失败总数)
- etcd_debugging_mvcc_db_total_size_in_bytes (etcd磁盘的使用,etcd metric默认采集的单位是E prometheus采集单位转换存在问题)
- kube_endpoint_address_not_ready (etcd状态错误 没有leader 代表当前集群宕机数量超过一半)
- node_cpu_seconds_total (采集物理节点cpu)
- node_memory_MemTotal_bytes (采集物理节点内存)
- up == 0 (代表有服务处于down状态)
- node_disk_io_time_seconds_total (物理节点I/O使用率)
- node_network_receive_bytes_total (入网流量)
- node_network_transmit_bytes_total (出网流量)
- node_netstat_Tcp_CurrEstab (物理节点tcp会话数)
- node_filesystem_free_bytes (物理节点磁盘使用)
- node_filesystem_size_bytes (磁盘总大小) 使用除以总的 *100既得出当前使用率
安装prometheus+alertmanager
--- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: monitor-sa labels: app: prometheus spec: replicas: 1 selector: matchLabels: app: prometheus component: server #matchExpressions: #- {key: app, operator: In, values: [prometheus]} #- {key: component, operator: In, values: [server]} template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: #nodeName: node1 serviceAccountName: monitor containers: - name: prometheus image: 172.17.166.217/kubenetes/prometheus:v2.2.1 #imagePullPolicy: IfNotPresent command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-lifecycle" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus name: prometheus-config - mountPath: /prometheus/ name: prometheus-storage-volume - name: k8s-certs mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ - name: alertmanager image: 172.17.166.217/kubenetes/alertmanager:v0.14.0 #imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/alertmanager.yml" - "--log.level=debug" ports: - containerPort: 9093 protocol: TCP name: alertmanager volumeMounts: - name: alertmanager-config mountPath: /etc/alertmanager - name: alertmanager-storage mountPath: /alertmanager - name: localtime mountPath: /etc/localtime volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /data type: Directory - name: k8s-certs secret: secretName: etcd-certs - name: alertmanager-config configMap: name: alertmanager - name: alertmanager-storage hostPath: path: /data/alertmanager type: DirectoryOrCreate - name: localtime hostPath: path: /usr/share/zoneinfo/Asia/Shanghai
--- apiVersion: v1 kind: Service metadata: labels: name: prometheuss kubernetes.io/cluster-service: 'true' name: prometheuss namespace: monitor-sa spec: ports: - name: prometheus #nodePort: 30066 port: 9090 protocol: TCP targetPort: 9090 selector: app: prometheus sessionAffinity: None #type: NodePort
是因为kube-proxy默认端口10249是监听在127.0.0.1上的,需要改成监听到物理节点上,按如下方法修改,线上建议在安装k8s的时候就做修改,这样风险小一些:
kubectl edit configmap kube-proxy -n kube-system
把metricsBindAddress这段修改成metricsBindAddress: 0.0.0.0:10249
然后重新启动kube-proxy这个pod
[root@xianchaomaster1]# kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
[root@xianchaomaster1]# ss -antulp |grep :10249
可显示如下
tcp LISTEN 0 128 [::]:10249 [::]:*
点击status->targets,可看到如下
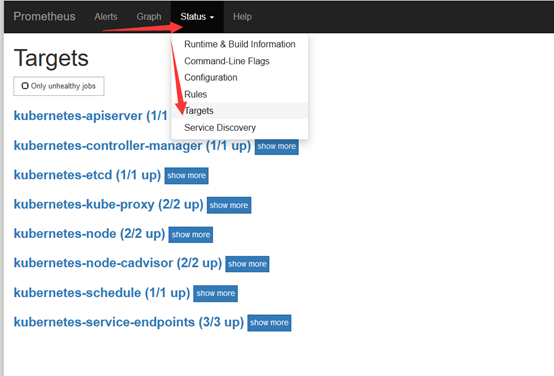
点击Alerts,可看到如下

把controller-manager的cpu使用率大于90%展开,可看到如下

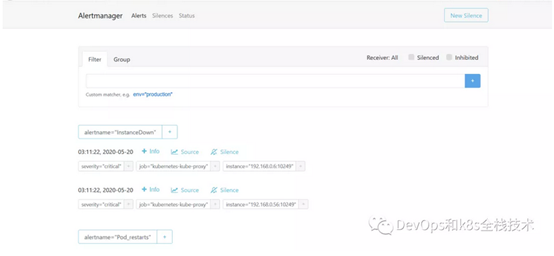
FIRING表示prometheus已经将告警发给alertmanager,在Alertmanager 中可以看到有一个 alert。
登录到alertmanager web界面
浏览器输入192.168.40.180:30066,显示如下
配置alertmanager-发送报警到钉钉
1.创建钉钉机器人 打开电脑版钉钉,创建一个群,创建自定义机器人,按如下步骤创建 https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq https://developers.dingtalk.com/document/app/custom-robot-access 我创建的机器人如下: 群设置-->智能群助手-->添加机器人-->自定义-->添加 机器人名称:test 接收群组:钉钉报警测试 安全设置: 自定义关键词:cluster1 上面配置好之后点击完成即可,这样就会创建一个test的报警机器人,创建机器人成功之后怎么查看webhook,按如下: 点击智能群助手,可以看到刚才创建的test这个机器人,点击test,就会进入到test机器人的设置界面 出现如下内容: 机器人名称:test 接受群组:钉钉报警测试 消息推送:开启 webhook: https://oapi.dingtalk.com/robot/send?access_token=8a53475677339a11cec453c608543c3d85ea73b330ea70c4b2de96a0839cbb90 安全设置: 自定义关键词:cluster1 2.安装钉钉的webhook插件,在k8s的控制节点xianchaomaster1操作 tar zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz压缩包所在的百度网盘地址如下: 链接:https://pan.baidu.com/s/1_HtVZsItq2KsYvOlkIP9DQ 提取码:d59o cd prometheus-webhook-dingtalk-0.3.0.linux-amd64 启动钉钉报警插件 nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --ding.profile="cluster1=https://oapi.dingtalk.com/robot/send?access_token=8a53475677339a11cec453c608543c3d85ea73b330ea70c4b2de96a0839cbb90" & 对原来的alertmanager-cm.yaml文件做备份 cp alertmanager-cm.yaml alertmanager-cm.yaml.bak 重新生成一个新的alertmanager-cm.yaml文件
cat >alertmanager-cm.yaml <<EOF kind: ConfigMap apiVersion: v1 metadata: name: alertmanager namespace: monitor-sa data: alertmanager.yml: |- global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' smtp_from: '15011572657@163.com' smtp_auth_username: '1501157****' smtp_auth_password: ‘BGWHYUOSOOHWEUJM' smtp_require_tls: false route: group_by: [alertname] group_wait: 10s group_interval: 10s repeat_interval: 10m receiver: cluster1 receivers: - name: cluster1 webhook_configs: - url: 'http://192.168.40.180:8060/dingtalk/cluster1/send' send_resolved: true EOF
配置alertmanager-发送报警到微信
1注册企业微信 登陆网址: https://work.weixin.qq.com/ 找到应用管理,创建应用 应用名字wechat 创建成功之后显示如下:
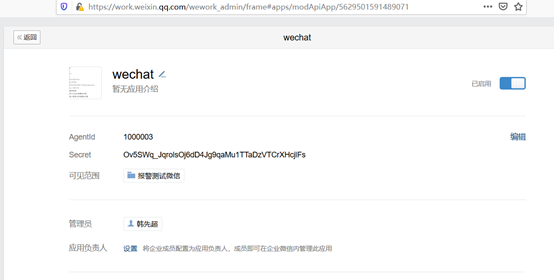
AgentId:1000003
Secret:Ov5SWq_JqrolsOj6dD4Jg9qaMu1TTaDzVTCrXHcjlFs
2.修改alertmanager-cm.yaml global: smtp_smarthost: 'smtp.163.com:25' smtp_from: '15011572657@163.com' smtp_auth_username: '15011572657' smtp_auth_password: 'BGWHYUOSOOHWEUJM' smtp_require_tls: false route: group_by: [alertname] group_wait: 10s group_interval: 10s repeat_interval: 3m receiver: "prometheus" receivers: - name: 'prometheus' wechat_configs: - corp_id: wwa82df90a693abb15 to_user: '@all' agent_id: 1000003 api_secret: Ov5SWq_JqrolsOj6dD4Jg9qaMu1TTaDzVTCrXHcjlFs 参数说明: secret: 企业微信("企业应用"-->"自定应用"[Prometheus]--> "Secret") wechat是本人自创建应用名称 corp_id: 企业信息("我的企业"--->"CorpID"[在底部]) agent_id: 企业微信("企业应用"-->"自定应用"[Prometheus]--> "AgentId") wechat是自创建应用名称 #在这创建的应用名字是wechat,那么在配置route时,receiver也应该是Prometheus to_user: '@all' :发送报警到所有人
配置自定义告警模板
cat template_wechat.tmpl {{ define "wechat.default.message" }} {{ range .Alerts }} ========start========== 告警程序:node_exporter 告警名称:{{ .Labels.alertname }} 故障主机: {{ .Labels.instance }} 告警主题: {{ .Annotations.summary }} 告警信息: {{ .Annotations.description }} ========end========== {{ end }} {{ end }}
不同告警分组
routes: - match_re: service: ^(foo1|foo2|baz)$ receiver: team-X-mails routes: - match: severity: critical receiver: team-X-pager - match: service: files receiver: team-Y-mails routes: - match: severity: critical receiver: team-Y-pager - match: service: database receiver: team-DB-pager # Also group alerts by affected database. group_by: [alertname, cluster, database] routes: - match: owner: team-X receiver: team-X-pager continue: true - match: owner: team-Y receiver: team-Y-pager
global:#配置邮箱、url、微信等 route: #配置路由树 - receiver: #从接受组(与route同级别)中选择接受 - group_by:[]#填写标签的key,通过相同的key不同的value来判断 ===研究rules中的标签值 - continue: false #告警是否去继续路由子节点 - match: [labelname:labelvalue,labelname1,labelvalue1] #通过标签去匹配这次告警是否符合这个路由节点,???必须全部匹配才可以告警???待测试。 - match_re: [labelname:regex] #通过正则表达是匹配标签,意义同上 - group_wait: 30s #组内等待时间,同一分组内收到第一个告警等待多久开始发送,目标是为了同组消息同时发送,不占用告警信息,默认30s - group_interval: 5m #当组内已经发送过一个告警,组内若有新增告警需要等待的时间,默认为5m,这条要确定组内信息是影响同一业务才能设置,若分组不合理,可能导致告警延迟,造成影响 - repeat_inteval: 4h #告警已经发送,且无新增告警,若重复告警需要间隔多久 默认4h 属于重复告警,时间间隔应根据告警的严重程度来设置 routes: - route:#路由子节点 配置信息跟主节点的路由信息一致
例如:
route: receiver: 'default-receiver' group_wait: 30s group_interval: 5m repeat_interval: 4h group_by: [cluster, alertname] routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend