1.list-watch是什么
List-watch 是 K8S 统一的异步消息处理机制,保证了消息的实时性,可靠性,顺序性,性能等等,为声明式风格的API 奠定了良好的基础,它是优雅的通信方式,是 K8S 架构的精髓。
2. List-Watch 机制具体是什么样的
Etcd存储集群的数据信息,apiserver作为统一入口,任何对数据的操作都必须经过 apiserver。客户端(kubelet/scheduler/controller-manager)通过 list-watch 监听 apiserver 中资源(pod/rs/rc等等)的 create, update 和 delete 事件,并针对事件类型调用相应的事件处理函数。
那么list-watch 具体是什么呢,顾名思义,list-watch有两部分组成,分别是list和 watch。list 非常好理解,就是调用资源的list API罗列资源,基于HTTP短链接实现;watch则是调用资源的watch API监听资源变更事件,基于HTTP 长链接实现,也是本文重点分析的对象。以 pod 资源为例,它的 list 和watch API 分别为: [List API](https://v1-10.docs.kubernetes.io/docs/reference/generated/kubernetes-api/v1.10/#list-all-namespaces-63),返回值为 [PodList](https://v1-10.docs.kubernetes.io/docs/reference/generated/kubernetes-api/v1.10/#podlist-v1-core),即一组 pod`。
GET /api/v1/pods
Watch API,往往带上 watch=true,表示采用 HTTP 长连接持续监听 pod 相关事件,每当有事件来临,返回一个 WatchEvent。
GET /api/v1/watch/pods
K8S 的informer 模块封装 list-watch API,用户只需要指定资源,编写事件处理函数,AddFunc, UpdateFunc和 DeleteFunc等。如下图所示,informer首先通过list API 罗列资源,然后调用 watch API监听资源的变更事件,并将结果放入到一个 FIFO 队列,队列的另一头有协程从中取出事件,并调用对应的注册函数处理事件。Informer还维护了一个只读的Map Store 缓存,主要为了提升查询的效率,降低apiserver 的负载。
3.Watch 是如何实现的
List的实现容易理解,那么 Watch 是如何实现的呢?Watch是如何通过 HTTP 长链接接收apiserver发来的资源变更事件呢?
秘诀就是 Chunked transfer encoding(分块传输编码),它首次出现在HTTP/1.1。正如维基百科所说:
HTTP 分块传输编码允许服务器为动态生成的内容维持 HTTP 持久链接。通常,持久链接需要服务器在开始发送消息体前发送Content-Length消息头字段,但是对于动态生成的内容来说,在内容创建完之前是不可知的。使用分块传输编码,数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。
当客户端调用 watch API 时,apiserver 在response 的 HTTP Header 中设置 Transfer-Encoding的值为chunked,表示采用分块传输编码,客户端收到该信息后,便和服务端该链接,并等待下一个数据块,即资源的事件信息。例如:
1 $ curl -i http://{kube-api-server-ip}:8080/api/v1/watch/pods?watch=yes 2 HTTP/1.1 200 OK 3 Content-Type: application/json 4 Transfer-Encoding: chunked 5 Date: Thu, 02 Jan 2019 20:22:59 GMT 6 Transfer-Encoding: chunked 7 8 {"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}} 9 {"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}} 10 {"type":"MODIFIED", "object":{"kind":"Pod","apiVersion":"v1",...}}
4. 谈谈 List-Watch 的设计理念
当设计优秀的一个异步消息的系统时,对消息机制有至少如下四点要求:
- 消息可靠性
- 消息实时性
- 消息顺序性
- 高性能
首先消息必须是可靠的,list 和 watch 一起保证了消息的可靠性,避免因消息丢失而造成状态不一致场景。具体而言,list API可以查询当前的资源及其对应的状态(即期望的状态),客户端通过拿期望的状态和实际的状态进行对比,纠正状态不一致的资源。Watch API 和 apiserver保持一个长链接,接收资源的状态变更事件并做相应处理。如果仅调用 watch API,若某个时间点连接中断,就有可能导致消息丢失,所以需要通过list API解决消息丢失的问题。从另一个角度出发,我们可以认为list API获取全量数据,watch API获取增量数据。虽然仅仅通过轮询 list API,也能达到同步资源状态的效果,但是存在开销大,实时性不足的问题。
消息必须是实时的,list-watch 机制下,每当apiserver 的资源产生状态变更事件,都会将事件及时的推送给客户端,从而保证了消息的实时性。
消息的顺序性也是非常重要的,在并发的场景下,客户端在短时间内可能会收到同一个资源的多个事件,对于关注最终一致性的 K8S 来说,它需要知道哪个是最近发生的事件,并保证资源的最终状态如同最近事件所表述的状态一样。K8S 在每个资源的事件中都带一个 resourceVersion的标签,这个标签是递增的数字,所以当客户端并发处理同一个资源的事件时,它就可以对比 resourceVersion来保证最终的状态和最新的事件所期望的状态保持一致。
List-watch 还具有高性能的特点,虽然仅通过周期性调用list API也能达到资源最终一致性的效果,但是周期性频繁的轮询大大的增大了开销,增加apiserver的压力。而watch 作为异步消息通知机制,复用一条长链接,保证实时性的同时也保证了性能。
5. Informer介绍
Informer 是 Client-go 中的一个核心工具包。在Kubernetes源码中,如果 Kubernetes 的某个组件,需要 List/Get Kubernetes 中的 Object,在绝大多 数情况下,会直接使用Informer实例中的Lister()方法(该方法包含 了 Get 和 List 方法),而很少直接请求Kubernetes API。Informer 最基本 的功能就是List/Get Kubernetes中的 Object。
6. Informer 设计思路
6.1 Informer 设计中的关键点
为了让Client-go 更快地返回List/Get请求的结果、减少对 Kubenetes API的直接调用,Informer 被设计实现为一个依赖Kubernetes List/Watch API、可监听事件并触发回调函数的二级缓存工具包。
6.2 更快地返回 List/Get 请求,减少对 Kubenetes API 的直接调用
使用Informer实例的Lister()方法,List/Get Kubernetes 中的 Object时,Informer不会去请求Kubernetes API,而是直接查找缓存在本地内存中的数据(这份数据由Informer自己维护)。通过这种方式,Informer既可以更快地返回结果,又能减少对 Kubernetes API 的直接调用。
6.3 依赖 Kubernetes List/Watch API
Informer 只会调用Kubernetes List 和 Watch两种类型的 API。Informer在初始化的时,先调用Kubernetes List API 获得某种 resource的全部Object,缓存在内存中; 然后,调用 Watch API 去watch这种resource,去维护这份缓存; 最后,Informer就不再调用Kubernetes的任何 API。
用List/Watch去维护缓存、保持一致性是非常典型的做法,但令人费解的是,Informer 只在初始化时调用一次List API,之后完全依赖 Watch API去维护缓存,没有任何resync机制。
笔者在阅读Informer代码时候,对这种做法十分不解。按照多数人思路,通过 resync机制,重新List一遍 resource下的所有Object,可以更好的保证 Informer 缓存和 Kubernetes 中数据的一致性。
咨询过Google 内部 Kubernetes开发人员之后,得到的回复是:
在 Informer 设计之初,确实存在一个relist无法去执 resync操作, 但后来被取消了。原因是现有的这种 List/Watch 机制,完全能够保证永远不会漏掉任何事件,因此完全没有必要再添加relist方法去resync informer的缓存。这种做法也说明了Kubernetes完全信任etcd。
6.4 可监听事件并触发回调函数
Informer通过Kubernetes Watch API监听某种 resource下的所有事件。而且,Informer可以添加自定义的回调函数,这个回调函数实例(即 ResourceEventHandler 实例)只需实现 OnAdd(obj interface{}) OnUpdate(oldObj, newObj interface{}) 和OnDelete(obj interface{}) 三个方法,这三个方法分别对应informer监听到创建、更新和删除这三种事件类型。
在Controller的设计实现中,会经常用到 informer的这个功能。
6.5 二级缓存
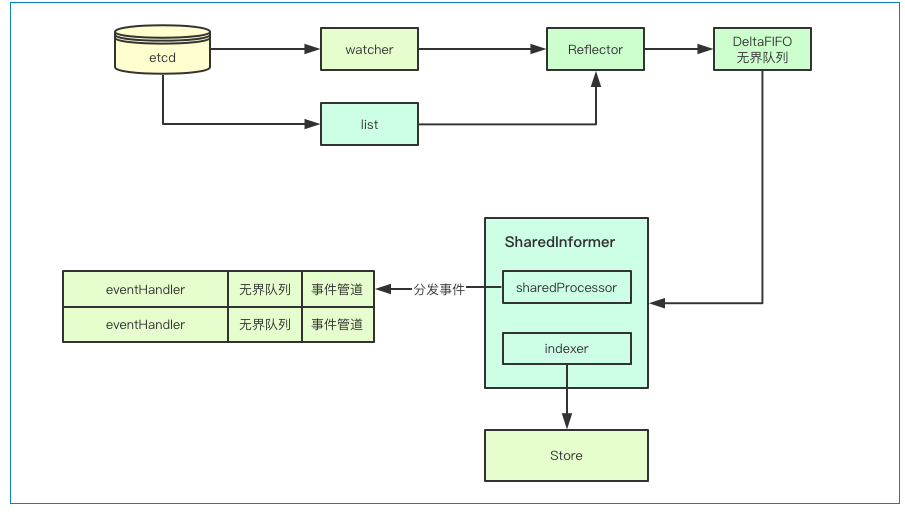
二级缓存属于 Informer的底层缓存机制,这两级缓存分别是DeltaFIFO和 LocalStore。
这两级缓存的用途各不相同。DeltaFIFO用来存储Watch API返回的各种事件 ,LocalStore 只会被Lister的List/Get方法访问 。
虽然Informer和 Kubernetes 之间没有resync机制,但Informer内部的这两级缓存之间存在resync 机制。
6.6 关键逻辑介绍
1.Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod
2.Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中
3.如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
4.Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件;如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件
5.Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO
6.DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1
7.DeltaFIFO 再 Pop 这个事件到 Controller 中
8.Controller 收到这个事件,会触发 Processor 的回调函数
9.LocalStore 会周期性地把所有的 Pod 信息重新放到 DeltaFIFO 中
关键设计
Informer依赖Kubernetes的List/Watch API。 通过Lister()对象来List/Get对象时,Informer不会去请求Kubernetes API,而是直接查询本地缓存,减少对Kubernetes API的直接调用。
Informer 只会调用 Kubernetes List 和 Watch 两种类型的 API。Informer 在初始化的时,先调用 Kubernetes List API 获得某种 resource 的全部 Object,缓存在内存中; 然后,调用 Watch API 去 watch 这种 resource,去维护这份缓存; 最后,Informer 就不再调用 Kubernetes 的任何 API。
Informer组件:
- Controller
- Reflector:通过Kubernetes Watch API监听resource下的所有事件
- Lister:用来被调用List/Get方法
- Processor:记录并触发回调函数
- DeltaFIFO
- LocalStore
DeltaFIFO和LocalStore是Informer的两级缓存。 DeltaFIFO:用来存储Watch API返回的各种事件。 LocalStore:Lister的List/Get方法访问。
我们以 Pod 为例,详细说明一下 Informer 的关键逻辑:
- Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod
- Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中
- 如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
- Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件;如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件
- Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO
- DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1
- DeltaFIFO 再 Pop 这个事件到 Controller 中
- Controller 收到这个事件,会触发 Processor 的回调函数

之前说到kubernetes里面的apiserver的只负责数据的CRUD接口实现,并不负责业务逻辑的处理,所以k8s中就通过外挂controller通过对应资源的控制器来负责事件的处理,controller如何感知事件呢?答案就是informer
基于chunk的消息通知

watcher的设计在之前的文章中已经介绍,服务端是如何将watcher感知到的事件发送给informer呢?我们提到过apiserver本质上就是一个http的rest接口实现,watch机制则也是基于http协议,不过不同于一般的get其通过chunk机制,来实现消息的通知
本地缓存
通过listwatch接口主要分为两部分,list接口我们可以获取到对应资源当前版本的全量资源,watch接口可以获取到后续变更的资源,通过全量加增量的数据,就构成了在client端一份完整的数据(基于当前版本的),那后续如果要获取对应的数据,就直接可以通过本地的缓存来进行获取,为此informer抽象了cache这个组件,并且实现了store接口,如果后续要获取资源,则就可以通过本地的缓存来进行获取
无界队列
为了协调数据生产与消费的不一致状态,在cleint-go中通过实现了一个无界队列来进行数据的缓冲,当reflector获取到数据之后,只需要将数据写入到无界队列中,则就可以继续watch后续事件,从而减少阻塞时间, 下面的事件去重也是在该队列中实现的
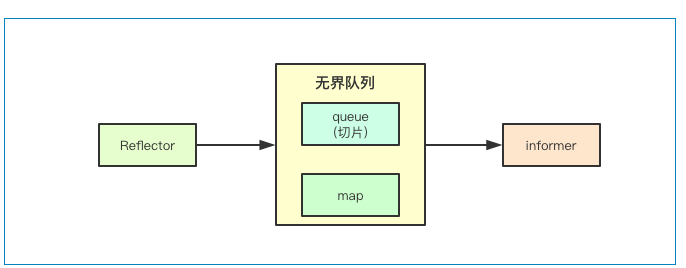
为了协调数据生产与消费的不一致状态,在cleint-go中通过实现了一个无界队列来进行数据的缓冲,当reflector获取到数据之后,只需要将数据写入到无界队列中,则就可以继续watch后续事件,从而减少阻塞时间, 下面的事件去重也是在该队列中实现的
事件去重
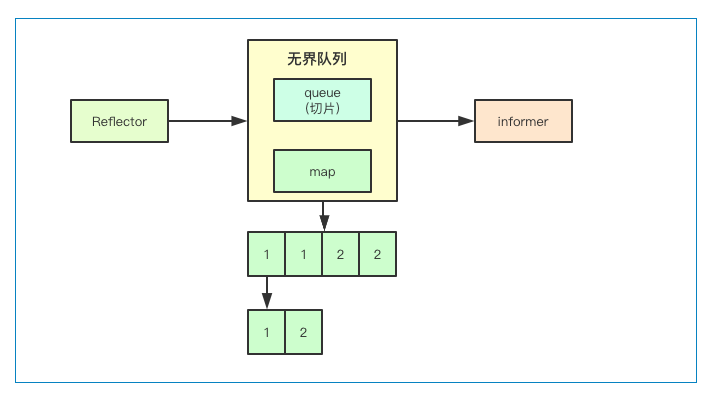
事件去重是指的,在上面的无界队列中,如果针对某个资源的事件重复被触发,则就只会保留相同事件最后一个事件作为后续处理
到此对于事件接收和数据缓存相关优化就结束了,接下就是处理层的优化
复用连接
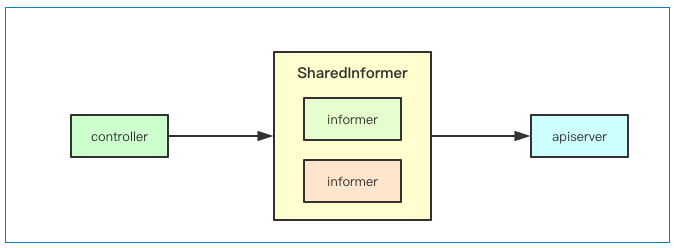
在k8s中一些控制器可能会关注多种资源,比如Deployment可能会关注Pod和replicaset,replicaSet可能还会关注Pod,为了避免每个控制器都独立的去与apiserver建立链接,k8s中抽象了sharedInformer的概念,即共享的informer, 针对同一资源只建立一个链接
基于观察者模式的注册
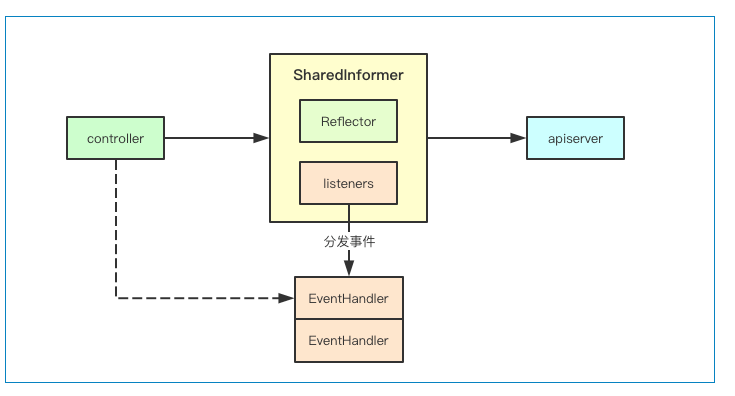
因为彼此共用informer,但是每个组件的处理逻辑可能各部相同,在informer中通过观察者模式,各个组件可以注册一个EventHandler来实现业务逻辑的注入
设计总结
————————————————
原文链接:https://blog.csdn.net/weixin_43116910/article/details/88653263