前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移。因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3.6.0 ,PanGu分词也是对应Lucene3.6.0版本的。不过好在Lucene.net 已经有了Core 2.0版本(4.8.0 bate版),而PanGu分词,目前有人正在做,貌似已经做完,只是还没有测试~,Lucene升级的改变我都会加粗表示。
Lucene.net 4.8.0
https://github.com/apache/lucenenet
PanGu分词
https://github.com/LonghronShen/Lucene.Net.Analysis.PanGu/tree/netcore2.0
不过现在我已经抛弃了PanGu分词,取而代之的是JIEba分词,
https://github.com/SilentCC/JIEba-netcore2.0
现在已经支持直接在nuget中下载,包名:Lucene.JIEba.net
https://www.nuget.org/packages/Lucene.JIEba.net/1.0.4
详情可以参照上一篇。
这篇博文主要是想介绍Lucene的搜索过程在源码中怎样的。决定探究源码的原因是因为我在使用Lucene的过程中遇到性能瓶颈的问题,根本不知道在搜索过程中哪里消耗的资源多,导致并发的时候服务器不堪重负。最后找到了原因,虽然和这篇博文没什么大的关系,但还是想把自己学习的过程记录下来。
一,搜索引擎的索引系统简介
在介绍Lucene的search之前,有必要对搜索引擎的索引系统做一个简单的了解。
索引通俗的说就是用来查找信息的信息,比如书的目录也是索引,可以帮助我们快速的查找内容在哪一页。那么在搜索引擎中我们需要储存的是文档和网页内容,就像是书中的一个一个章节一样。那么搜索引擎的索引其实就是查询的关键词,通过关键词,搜索引擎帮助你快速查找到文档在哪里。文档的量是十分巨大的,然而关键词在任何语言中都是固定的那么多,都是有限的。因此书本的目录可以是很少的几页。那么如何去建这个索引呢?这就是索引系统简历的关键。
我们知道现在的全文检索的索引系统大都是基于倒排索引的,倒排索引可以快速通过关键词(索引)找到相应的文档,Lucene的索引系统自然也是基于倒排索引。
1.正排索引
介绍倒排索引之前先介绍正排索引,因为正排索引是倒排索引创建的基础,二者结合起来就很好理解搜索引擎的索引系统。全文检索系统无法就是在大量的索引库中寻找命中搜索关键词的文档。于是在任何一个索引系统中应该有这么两个概念:关键词(索引),文档 (信息)。正排索引的储存很简单就是一个文档到关键词的映射,根据文档id 可以映射到这篇文档里面关键词信息:
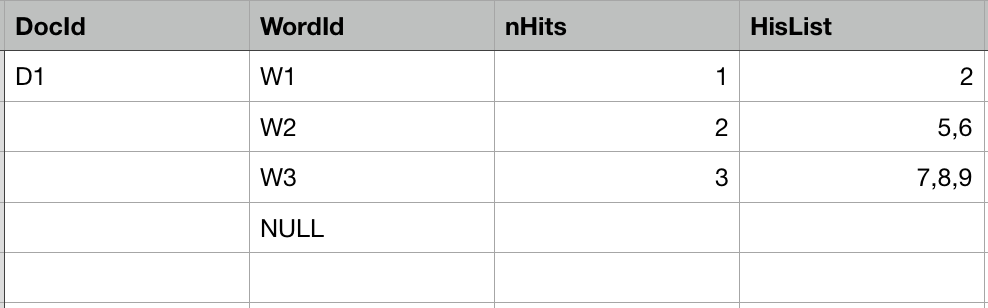
上面就是正排表,它表示DocId 为D1 的文档 由三个词组成 W1, W2 和W3 。W1 在文档中出现了1次,起始位置为2。W2在文档中出现了2次,起始位置分别为5 和6。
这样可以通过文档快速的找到文档中的索引词的信息。它是站在文档的角度,以文档编号为索引结构。
正排索引是无法满足全文检索的需要,于是在正排索引的基础上创造了倒排索引。
2.倒排索引
倒排索引其实是以关键词为索引结构,构造了从关键词到文档的一个映射。倒排索引由两部分组成,第一部分是关键词组成的字典,也就是索引结构。第二部分是文档集合。
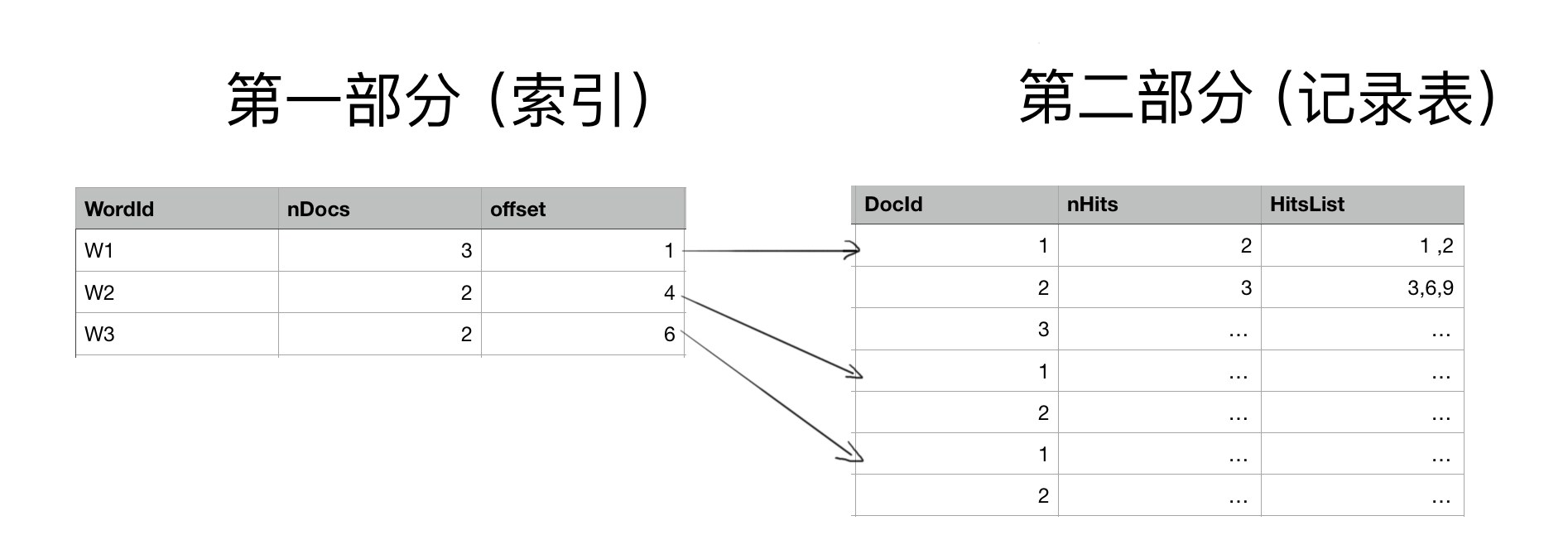
上图就是一个倒排表,它表示的意思是:首先在第一部分(字典构成的索引)中,有个三个关键词W1,W2,W3. 其中包含W1的文档(nDocs)有3个,偏移位置(offset)为1 ,这个偏移位置就表示W1 映射在第二部分中的起始位置,所以可以看到,W1 命中了三篇文档(1,2,3)在第一篇文档中W1出现了2次,起始位置分别是1,2。以此类推第二篇和第三篇。 W2 命中了两篇文档(1 和 2),W3也是如此。
可以看到在倒排索引中,它是一个关键词映射到文档的集合。可以通过关键词,快速查找该关键词出现在哪里文档,并且在该文档中出现的次数和位置(这是建立在正排索引的基础上)
实际上这样一个简单的倒排索引结构还是十分简陋的,没有考虑到记录表中的何种文档排序方式更有利于检索,以及这样一个倒排索引结构采用什么方式压缩更省空间。这些都不去细究了。接下来看Lucene的索引系统。
3.Lucene的索引结构
在 Lucene.net(4.8.0) 学习问题记录三: 索引的创建 IndexWriter 和索引速度的优化 中介绍了Lucene 索引结构的正向信息,所谓正向信息就是从文档的角度出发储存文档的域,词等信息:
- .fnm保存了此段包含了多少个域,每个域的名称及索引方式。
- .fdx,.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
- .tvx,.tvd,.tvf保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
那么Lucene索引结构中的反向信息也就是我们所说的倒排索引:
- .tip .tim 就是上文中说的倒排索引中第一部分也即词典索引。
- .doc 是倒排索引的第二部分(记录表),储存文档和文档中的词频信息。
Lucene的索引(这里就是指倒排索引第一部分也即词典索引)用的是FST数据结构,Lucene的记录表采用Frame of reference结构都不做细述。
- 在Lucene中.tip 储存的叫做Term Directory 它列举了每个Field ( 域 ) 的Terms ( 词 ) 并且把它们储存在Block(块)中,每个Block有25-48个Term
- 而.tim 中储存的叫做Term Index 它储存了每个Field的 FST ,FST 中储存的是Term(词)的前缀, 对应.tip 中的Block。Block中的每个Term都是相同的前缀,这个前缀就储存在FST中。可是每个Block最多存48个Term, 如果相同前缀的Term很多的话,Block会分出一个子Block,很显然父Block的公共前缀是子Block公共前缀的前缀。
二,Lucene的搜索源码分析
1.概览
从索引文件上来说,Lucene的搜索过程:在IndexSearch 初始化的时候先就将.tip .tim文件的内容加载到内存中,在Search的过程中,会从.tip .tim文件中查找到关键词(Terms),然后顺着这些Terms 去.doc文件中查找命中的文档,最后取出文档ID。这只是很笼统的一个大概的过程。实际上Lucene在Search的过程中还有一个很重要同时也是很消耗时间的操作:评分。 接下来就看看Lucene的具体源码是怎么实现的,在这个过程中只介绍重要的类和方法,因为整个搜索过程是很复杂的,并且在这个过程中可以看看Lucene的搜索操作时间都消耗在了哪里?。PS:我这里的Lucene都是指Lucene.Net版本。
2.实际操作
Lucene检索的时序图,大概如下所示,可以直观的看下整个流程:

2.1 第一步 IndexSearch的初始化
我们都知道Lucene的搜索是通过IndexSearch来完成的。IndexSearch的初始化分为三步,前两步是:
FSDriectory dir = FSDirectory.Open(storage.IndexDir);
IndexReader indexReader = DirectoryReader.Open(dir);
前面说到过Lucene需要加载词典索引到内存中,这步操作就是在 DirectoryReader.Open()的函数中完成的。而完成加载的类叫做 BlockTreeTermsReader ,还有一个与之对应的类叫做BlockTreeTermsWriter 很显然前者是从来读取索引,后者是用来写索引的,这两个类是操作词典索引的类。它们在Lucene.Net.Codecs包中
具体一点的加载方式:BlockTreeTermsReader 的内部类 FieldReader 它是前面的Term Directory 和Term Index的代码实现,只贴出一部分。
public sealed class FieldReader : Terms { private readonly BlockTreeTermsReader outerInstance; internal readonly long numTerms; internal readonly FieldInfo fieldInfo; internal readonly long sumTotalTermFreq; internal readonly long sumDocFreq; internal readonly int docCount; internal readonly long indexStartFP; internal readonly long rootBlockFP; internal readonly BytesRef rootCode; internal readonly int longsSize; internal readonly FST<BytesRef> index; //private boolean DEBUG; ..... }
可以看到FST<BytesRef> index 对应.tim中的FST 。FST.cs在Lucene.Net.Util包中 。
每次初始化IndexSearch,都会将.tim 和.tip中的内容加载到内存中,这些操作都是很耗时的。所以这就是为什么用Lucene的人都说IndexSearch应该使用单例模式,或者把它缓存起来。
在初始化IndexSearch之后,便开始执行IndexSearch.Search 函数
public virtual TopDocs Search(Query query, Filter filter, int n) { Query q = WrapFilter(query, filter); Weight w = CreateNormalizedWeight(q); return Search(w, null, n); }
2.2 第二步 组合Query
将Query 和Filter 组合成过滤查询FilteredQuery 就是上面代码块中的Query q = WrapFilter(query,filter);
IndexSearchr : WrapFilter
protected virtual Query WrapFilter(Query query, Filter filter) { Console.WriteLine("第二步:根据查询query,和过滤条件filter 组合成过滤查询FilteredQuery,执行函数WrapFilter"); return (filter == null) ? query : new FilteredQuery(query, filter); }
2.3 第三步 由第二步得到的Query 生成Weight
Weight 类简单的概念:
- Weight 类是Search过程中很重要的类,它负责生成Scorer (一个命中Query的文档集合的迭代器,文档打分调用Similarity 类就是Lucene自己的TF/IDF打分机制) 。
- Weight类实际上是包装Query 它先通过Query生成,之后IndexSearch所需要提供的Query便都由Weight提供。
- Weight 生成Scorer 是通过AtomicReaderContext (由IndexReaderContext而来)构造而得。所以搜索过程的AtomicReader(提供对索引进行读取操作的类) 驻留在Scorer中。说白了Weight 生成Scorer的操作 便是 检索的主要操作:是从索引中查找命中文档的过程。
Lucene中生成Weight的源码:
public virtual Weight CreateNormalizedWeight(Query query) {
query = Rewrite(query);//重写查询 Weight weight = query.CreateWeight(this);//生成Weight float v = weight.GetValueForNormalization(); float norm = Similarity.QueryNorm(v); if (float.IsInfinity(norm) || float.IsNaN(norm)) { norm = 1.0f; } weight.Normalize(norm, 1.0f); return weight; }
首先是重写查询
Lucene 将Query 重写成一个个TermQuery组成的原始查询 ,调用的是Query的Rewrite 方法,比如一个PrefixQuery 则会被重写成由TermQuerys 组成的BooleanQuery 。所有继承Query的 比如BooleanQuery ,PhraseQuery,CustomQuery都会覆写这个方法以实现重写Query。
public virtual Query Rewrite(IndexReader reader) { return this; }
然后计算查询权重
计算查询权重,实际上这么一个操作:在得到重写查询之后的原始查询TermQuery ,先通过上文所说的 BlogTreeTermsReader 读取词典索引中符合TermQuery的Term ,然后通过Lucene自己TF/IDF 打分机制,算出Term的IDF值,以及QueryNorm的值(打分操作都是调用 Similarity 类),最后返回Weight。
计算Term IDF的源码,它位于 TFIDFSimilarity : Similarity 中
public override sealed SimWeight ComputeWeight(float queryBoost, CollectionStatistics collectionStats, params TermStatistics[] termStats) { Explanation idf = termStats.Length == 1 ? IdfExplain(collectionStats, termStats[0]) : IdfExplain(collectionStats, termStats); return new IDFStats(collectionStats.Field, idf, queryBoost); }
IDFStats 是包装Term IDF值的类,可以看到打分的过程还要考虑我们在应用层设置的Query的Boost .
上面只是计算一个文档的分数的一小部分,实际上还是比较复杂的,我们可以简单了解介绍Lucene 的TFIDFSimilarity 的打分机制
TFIDFSimilarity的简单介绍:
TFIDFSimilarity 是Lucene中的评分类。这是官方文档的介绍:https://lucene.apache.org/core/4_8_0/core/org/apache/lucene/search/similarities/TFIDFSimilarity.html
它并不仅仅是TFIDF那么简单的算法。实际上它是很大部分搜索引擎都在使用的打分机制,叫做空间向量模型。
做过自然语言处理的人都知道,对于文本都需要它们处理成向量,这样我们就可以利用数学,统计学中的知识对文本进行分析了。这些向量叫做文本向量。向量的维度是文档中词的个数,向量中的值是文档中词的权重。算余弦值
| cosine-similarity(q,d) = |
|
通过这些文本向量,我们可以做一些很有意思的事情,比如计算两个文本的文本向量的余弦值,就可以知道两篇文本的相似程度。而搜索引擎就是利用了这样的性质,将查询关键词和待查询的文档都转成空间向量,计算二者的余弦值,这样就可以知道哪些文档和查询关键词十分相似了。这些相似的文档得分就越高。这样的打分方式高效而且准确。
在Lucene中空间向量的值其实就是TF/IDF的值。Lucene的计算空间余弦值经过变换已经变成这样的形式

至于过程是怎么样的,有兴趣可以详细阅读上面的官方文档。(一定要注意颜色,这个很重要)
PS: 在这里我要提醒一点,因为Lucene提供了自定义打分机制(CustomSocre),和给Query设置Boost ,最终的得分是score(q,d)*customScore 我就吃过自己设置的自定义打分机制和Boost不当的亏,导致排序结果是那些IDF值很低(也即无关紧要的词,例如“我”,“在”,“找不到”...)的词排名靠前,而明明有命中所有查询词的文档却排在后面。
可以猜到到这里Lucene只计算了 queryNorm(q) *idf(t in q) *t.getBoost() 值,最后的文档的分数 还要再正真的Search过程中去完成剩余的部分。
2.4 第四步 生成TopSorceDocCollector
生成Weight 之后,Lucene执行的源码如下:
protected virtual TopDocs Search(IList<AtomicReaderContext> leaves, Weight weight, ScoreDoc after, int nDocs) { // single thread int limit = reader.MaxDoc; if (limit == 0) { limit = 1; } nDocs = Math.Min(nDocs, limit); TopScoreDocCollector collector = TopScoreDocCollector.Create(nDocs, after, !weight.ScoresDocsOutOfOrder); Search(leaves, weight, collector); return collector.GetTopDocs(); }
TopSorceDocCollector 实际上一个文档收集器,它是装在查询结果文档的容器,collector.GetTopDocs() 得到就是大家都知道的TopDocs.
TopSorceDocCollector 生成函数
opScoreDocCollector collector = TopScoreDocCollector.Create(nDocs, after, !weight.ScoresDocsOutOfOrder);
2.5 第五步 由Weight 生成Scorer
Scorer 前面已经介绍过,它就是一个由TermQuery从索引库中查询出来的文档集合的迭代器,可以说生成Scorer的过程就是查找文档的过程。那么生成Scorer之后可以通过它的next 函数遍历我们的结果文档集合,对它们一一打分结合前面计算的queryWeight
先来看源码:
protected virtual void Search(IList<AtomicReaderContext> leaves, Weight weight, ICollector collector) { // TODO: should we make this // threaded...? the Collector could be sync'd? // always use single thread: foreach (AtomicReaderContext ctx in leaves) // search each subreader { try { collector.SetNextReader(ctx); } catch (CollectionTerminatedException) { // there is no doc of interest in this reader context // continue with the following leaf continue; } BulkScorer scorer = weight.GetBulkScorer(ctx, !collector.AcceptsDocsOutOfOrder, ctx.AtomicReader.LiveDocs); if (scorer != null) { try { scorer.Score(collector); } catch (CollectionTerminatedException) { // collection was terminated prematurely // continue with the following leaf } } } }
通过Weight 生成scorer 的操作是:
BulkScorer scorer = weight.GetBulkScorer(ctx, !collector.AcceptsDocsOutOfOrder, ctx.AtomicReader.LiveDocs);
这应该是整个搜索过程中最耗时的操作。它是如果获取Scorer的呢?上文说到Weight的一个作用是提供Search需要的Query, 其实生成Scorer的最终步骤是通过TermQuery(原始型查询) 的GetScorer函数,GetScorer函数:
public override Scorer GetScorer(AtomicReaderContext context, IBits acceptDocs) { Debug.Assert(termStates.TopReaderContext == ReaderUtil.GetTopLevelContext(context), "The top-reader used to create Weight (" + termStates.TopReaderContext + ") is not the same as the current reader's top-reader (" + ReaderUtil.GetTopLevelContext(context)); TermsEnum termsEnum = GetTermsEnum(context); if (termsEnum == null) { return null; } DocsEnum docs = termsEnum.Docs(acceptDocs, null); Debug.Assert(docs != null); return new TermScorer(this, docs, similarity.GetSimScorer(stats, context)); }
在这个函数里,已经体现了Lucene是怎么根据查找文档的,首先GetTermsEnum(context)函数 获取 TermsEnum , TermsEnum 是用来获取包含当前 Term 的 DocsEnum ,而DocsEnum 包含文档docs 和词频term frequency .
于是查询文档的过程就清晰了:
对于当前的TermQuery ,查找符合TermQuery的文档的步骤是 利用AtomicReader (通过AtomicReaderContext获取) 生成TermsEnum (TermsEnum中的当前Term 就是TermQuery我们需要查询的那个Term)
TermsEnum termsEnum = context.AtomicReader.GetTerms(outerInstance.term.Field).GetIterator(null);
再通过TermsEnum 获取DocsEnum
DocsEnum docs = termsEnum.Docs(acceptDocs, null);
最后合成Scorer
return new TermScorer(this, docs, similarity.GetSimScorer(stats, context));
2.6 第六步 给每个搜出来的文档打分并且添加到TopSorceDocCollector中
这一步直接体现在源码中就是:
scorer.Score(collector);
当然不可能是这一行代码就能完成的。它最终调用的Weight类的ScoreAll()函数.
internal static void ScoreAll(ICollector collector, Scorer scorer) { System.Console.WriteLine("Weight类,ScoreAll ,将Scorer中的doc传给Collertor"); int doc; while ((doc = scorer.NextDoc()) != DocIdSetIterator.NO_MORE_DOCS) { collector.Collect(doc);//收集评分后的文档 } }
然而正真打分的函数也不是ScoreAll函数,它是scorer.NextDoc()函数,
scorer执行NextDoc函数会调用 TFIDFSimScorer 类,它是TFIDFSimilarity的内部类,计算分数的函数为:
public override float Score(int doc, float freq) { System.Console.WriteLine("开始计算文档的算分,根据TF/IDF方法"); float raw = outerInstance.Tf(freq) * weightValue; // compute tf(f)*weight return norms == null ? raw : raw * outerInstance.DecodeNormValue(norms.Get(doc)); // normalize for field }
这是Lucene评分公式中的部分得分,最终得分应该再乘以上文的查询得分queryWeight再乘以自定义的得分CustomScore.
2.7 第七步 返回结果
没什么好说的了。
三,结语
行文至此,终于将Lucene 的索引,搜索,打分机制说完了。实际上完整的过程不是一篇博文就能涵盖的,源码也远远不止我贴出来的那些。我只是大概了解这个过程,并且介绍了几个关键的类:IndexSearcher,Weight , Scorer , Similarity, TopScoreDocCollector,AtomicReader 等。Lucene之所以是搜索引擎开源框架的不二选择,是因为它的搜索效果和速度是真的不错。如果你的程序搜索效果很差,那么一定是你没有善用Lucene。
此外我想说一个问题,读懂Lucene的源码对于使用Lucene有没有帮助呢?你不懂Lucene的内部机制和底层原理,照样也可以用的很滑溜,还有Solr ElasticSearch 等现成的工具可以使用。其实读懂源码对你的知识和代码认知能力提升不说,对于lucene,你可以在知道它内部原理的情况下自己修改它的源码已适应你的程序,比如 1. 你完全可以将打分机制屏蔽,那么Lucene搜索的效率将成倍提高 2. 你也可以直接使用Lucene最底层的接口,比如AtomicReader 类,这个直接操作索引的类,从而达到更深层次的二次开发。这岂不是很酷炫?3. 可以直接修改lucene不合理的代码。
最后说一句勉励自己的话,其实写博客是一个很好的方式,因为你抱着写给别人看的态度,所以你要格外严谨,并且保证自己充分理解的情况下才能写博客。这个过程已经足够你对某个问题入木三分了。
最最后,我补充一下,我遇到的Lucene的性能问题,源于高亮。上述过程Lucene做的十分出色,而由于高亮的限制(实际上是自动摘要)搜索引擎的并发性能很低,而如何解决这个问题也是很值得深究的问题。