一、序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,python中叫pickling
序列化之后就可以把序列化后的内容写入磁盘或通过网络传输到别的机器上
反序列化:unpickling,也就是loads的过程
二、json模块
功能:处理成字符串
可以让不同语言间进行数据交换
import json
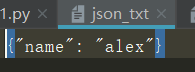
dic = {"name": "alex"}
data = json.dumps(dic)
print(data, type(data))

经json处理,就把别的数据类型变为json字符串
json规范的字符串必须使用双引号
处理过程:dic = {‘name’: 'alex'}----> {"name": "alex"} ----> '{"name": "alex"}' (先把所有单引号变为双引号,再在外面加上单引号)
i = 8 #----> '8'
s = 'hello' ----->"hello"----->' "hello" '
json方法: dumps和dump
推荐用dumps, dump只是简化了一步,只能用于文件处理
import json
dic = {"name": "alex"}
data = json.dumps(dic)
with open("json_txt", "w") as f:
f.write(data)
或:
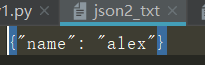
import json
dic = {"name": "alex"}
# data = json.dumps(dic)
with open("json2_txt", "w") as f:
json.dump(dic, f)
json方法:loads 和load
推荐用loads, load只是简化了一步,只能用于文件处理
import json
with open("json_txt","r")as f_read:
data = f_read.read()
data = json.loads(data)
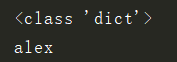
print(type(data))
print(data["name"])
或:
import json
with open("json_txt","r")as f_read:
# data = f_read.read()
data = json.load(f_read)
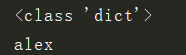
print(type(data))
print(data["name"])
三、pickle 模块
和 json 的功能、方法一样,
区别:pickle是把数据处理成字节, 且支持的数据类型更多,例如: 类,函数...
写入的文件,直接打开是看不懂的
dumps:
import pickle
dic = {"name": "alex", "age":18}
with open("pickle_test", "wb") as f:
dic_str = pickle.dumps(dic)
f.write(dic_str)

loads:
import pickle
with open("pickle_test", "rb") as f:
data = f.read()
data = pickle.loads(data)
print(data["age"])

load和dump方法的使用也相同,此处不在赘述
四、shelve模块
和json 、pickle一个系类,内部封装了dumps 和loads,
可以直接以字典形式写入磁盘内容,再以字典方法读取
import shelve
f = shelve.open("shelve_test")
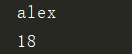
f["name"] = "alex" #将一个键值对写入文件
f["stu1"] = {"name":"alvin", "age":18} #将一个键值对写入文件
print(f.get("name"))
print(f.get("stu1")["age"])