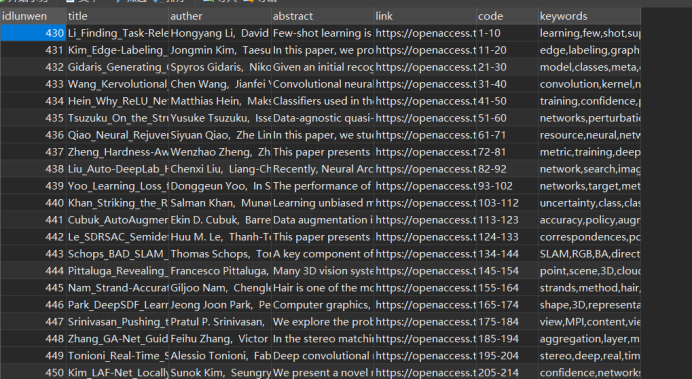
import requests import jieba import pymysql from bs4 import BeautifulSoup #链接到本地数据库 from jieba.analyse import extract_tags db = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='1224',database='cvpr',charset='utf8') cursor = db.cursor() #定义头文件 headers={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36" } #get方法抓取数据 # url="http://openaccess.thecvf.com/CVPR2019.py" url="https://openaccess.thecvf.com/CVPR2019?day=2019-06-18" html=requests.get(url) #使用 Beautiful Soup 解析网页 soup=BeautifulSoup(html.content,'html.parser') pdfs=soup.findAll("a",text="pdf") print(len(pdfs)) lis = [] jianjie="" for i,pdf in enumerate(pdfs): pdf_name=pdf["href"].split('/')[-1] name=pdf_name.split('.')[0].replace("_CVPR_2019_paper","") link="http://openaccess.thecvf.com/content_CVPR_2019/html/"+name+"_CVPR_2019_paper.html" url1=link print(url1) print(i) html1 = requests.get(url1) if html1: soup1 = BeautifulSoup(html1.content, 'html.parser') weizhi = soup1.find('div', attrs={'id':'abstract'}) if weizhi: jianjie =weizhi.get_text() authers = soup1.find_all(id="authors") # 论文编号 a = authers[0].contents[3] a_split = a.split('.')#以点分割为数组 code=a_split[1].strip()#去掉空格前后 # 作者 auther = soup1.find("i") myauther=auther.string keywordlist=[] for keyword, weight in extract_tags(jianjie.strip(), topK=5, withWeight=True): keywordlist.append(keyword) keywordliststr = ','.join(keywordlist) info = {'title': name, 'author': myauther, 'abstract': jianjie, 'link': link, 'code': code, 'keywords': keywordliststr} print(info.values()) lis.append(info) print(lis) cursor = db.cursor() for i in range(len(lis)): cols = ", ".join('`{}`'.format(k) for k in lis[i].keys()) print(cols) # '`name`, `age`' val_cols = ', '.join('%({})s'.format(k) for k in lis[i].keys()) print(val_cols) # '%(name)s, %(age)s' sql = "insert into lunwen(%s) values(%s)" res_sql = sql % (cols, val_cols) print(res_sql) cursor.execute(res_sql, lis[i]) # 将字典a传入 db.commit() print("ok")