在本系列的Pulsar和Kafka比较文章中,我将引导您完成我认为重要的几个领域,并且对于人们选择强大,高可用性,高性能的流式消息传递平台至关重要。消息传递模型(Messaging model)是用户在选择流式消息传递系统时应首先考虑的事情。消息传递模型应涵盖以下3个方面:
- Message consumption(消息消费):如何发送和消费消息
- Message Acknowledgement(消息确认):如何确认消息
- Message Retention(消息保留):消息要保留多久、出发消息删除的原因以及删除方式
一、消息消费
在一个现代的实时流式架构中,消息用例可被分为两类:队列和流。
队列
队列是无序或共享的消息传递,通过队列进行消息传递,多个消费者可以被创建以从单个点对点消息传递通道接收消息。当通道传递消息时,任何消费者都可能接收消息。消息传递系统的实现决定哪个消费者实际接收的消息。队列用例通常与无状态的应用程序一起使用,无状态应用程序不关心排序,但它们需要能够进行消息确认(acknowledge)或消息删除(remove)、以及尽可能扩展消息消费并行性的能力。典型的基于排队的消息传递系统包括RabbitMQ和RocketMQ。
流
相比之下、流是严格排序或独占的消息传递。使用流式消息传递,始终只有一个消费者使用消息传递通道。消费者按照编写它们的确切顺序接收从通道发送的消息。流式用例通常与有状态应用程序相关联。有状态的应用程序关心顺序及其状态。消息的排序决定了有状态应用程序的状态。顺序将影响应用程序在发生无序消耗时需要应用的任何处理逻辑的正确性。
在面向微服务或事件驱动的体系结构中,流和队列都是必需的。
二、Pulsal Model
Apache Pulsar将队列和流统一为消息传递模型:producer-topic-subscription-consumer。主题(分区)是用于发送消息的命名通道。每个主题分区都由存储在Apache BookKeeper中的分布式日志支持。发布者发布的每条消息仅存储在主题分区上一次,复制以存储在多个bookies(BookKeeper服务器)上,并且可以根据消费者的需要多次消费使用。主题是消费真相的来源,尽管消息仅在主题分区上存储一次,但是可以有不同的方式来消费这些消息。消费者被组合在一起以消费消息。每组消费者都是对主题的订阅,每个消费者群体都可以拥有自己的消费方式 - 独占,共享或故障转移 - 这些消费群体可能会有所不同。这在一个模型和API中结合了队列和流,它的设计和实现目标是不影响性能和引入成本开销,同时还为用户提供了很多灵活性,以最适合当前用例的方式使用消息。
独占订阅(流):顾名思义,在任何给定时间内,订阅(消费者组)中只有一个消费者消费主题分区。下面的图1说明了独占订阅的示例。有一个有订阅A的活动消费者A-0消息m0到m4按顺序传送并由A-0消费。如果另一个消费者A-1想要附加到订阅A,则不允许这样做。
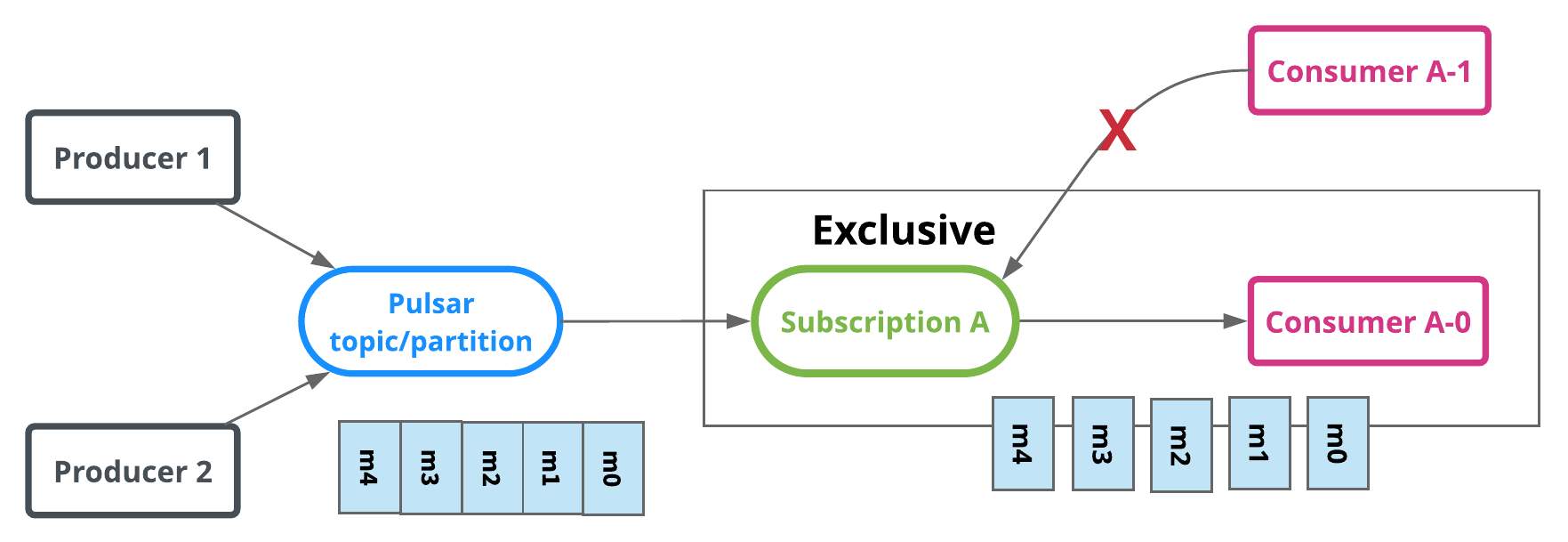
图一:独占订阅
故障转移订阅(Failover sub streaming):使用故障转移订阅,多个使用者可以附加到同一订阅。但是,对于给定的主题分区,将选择一个使用者作为该主题分区的主使用者,其他消费者将被指定为故障转移消费者,当主消费者断开连接时,分区将被重新分配给其中一个故障转移消费者,而新分配的消费者将成为新的主消费者。发生这种情况时,所有未确认的消息都将传递给新的主消费者,这类似于Apache Kafka中的使用者分区重新平衡。图2显示了故障转移订阅,消费者B-0和B-1通过订阅B订阅消费消息.B-0是主消费者并接收所有消息,B-1是故障转移消费者,如果消费者B-0出现故障,将接管消费。

共享订阅(队列):使用共享订阅,可以将所需数量的消费者附加到同一订阅。消息以多个消费者的循环尝试分发形式传递,并且任何给定的消息仅传递给一个消费者。当消费者断开连接时,所有传递给它并且未被确认的消息将被重新安排,以便发送给该订阅上剩余的剩余消费者。图3说明了共享订阅。消费者C-1,C-2和C-3都在同一主题分区上消费消息。每个消费者接收大约1/3的消息。如果您想提高消费率,您可以在不增加分区数量的情况下为更多的消费者提供相同的订阅(尽可能多的消费者)。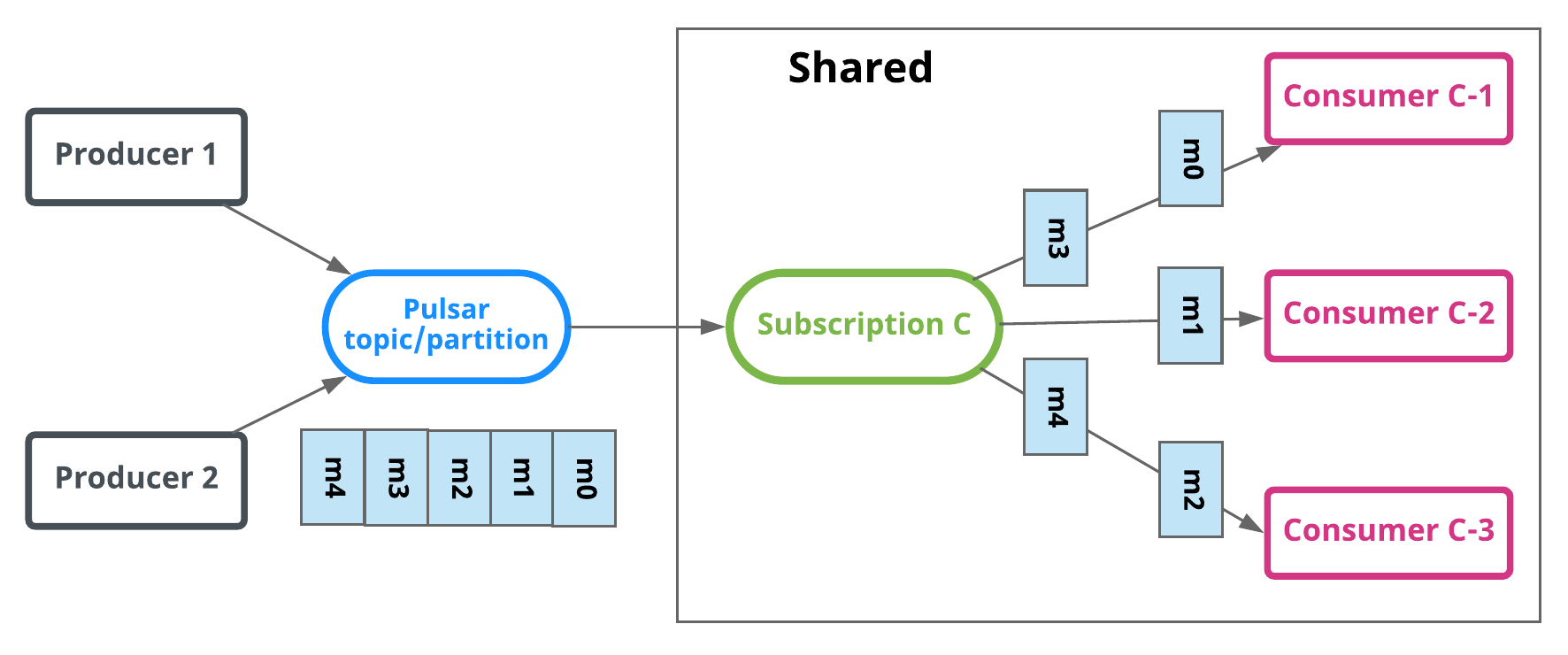
独占和故障转移订阅仅允许每个订阅每个主题分区仅有一个消费者。它们按分区顺序使用消息。它们最适用于需要严格排序的流用例。另一方面,共享订阅允许每个主题分区有多个消费者,同一订阅中的每个消费者仅接收发布到主题分区的一部分消息。共享订阅最适用于不需要排序的并且可以扩展超出分区数量的使用者数量的队列用例。
Pulsar中的subscription(订阅)实际上与Apache Kafka中的消费者群体相同。创建订阅具有高度可扩展性且非常低廉的。可以根据需要创建任意数量的订阅,对同一主题的不同订阅不必具有相同的订阅类型。这意味着可以在同一主题上有10个消费者的故障转移订阅或有20个消费者的共享订阅。如果共享订阅处理事件的速度很慢,则可以在不更改分区数的情况下向共享订阅添加更多消费者。图4描绘了一个包含3个订阅A,B和C的主题,并说明了消息如何从生产者流向消费者。 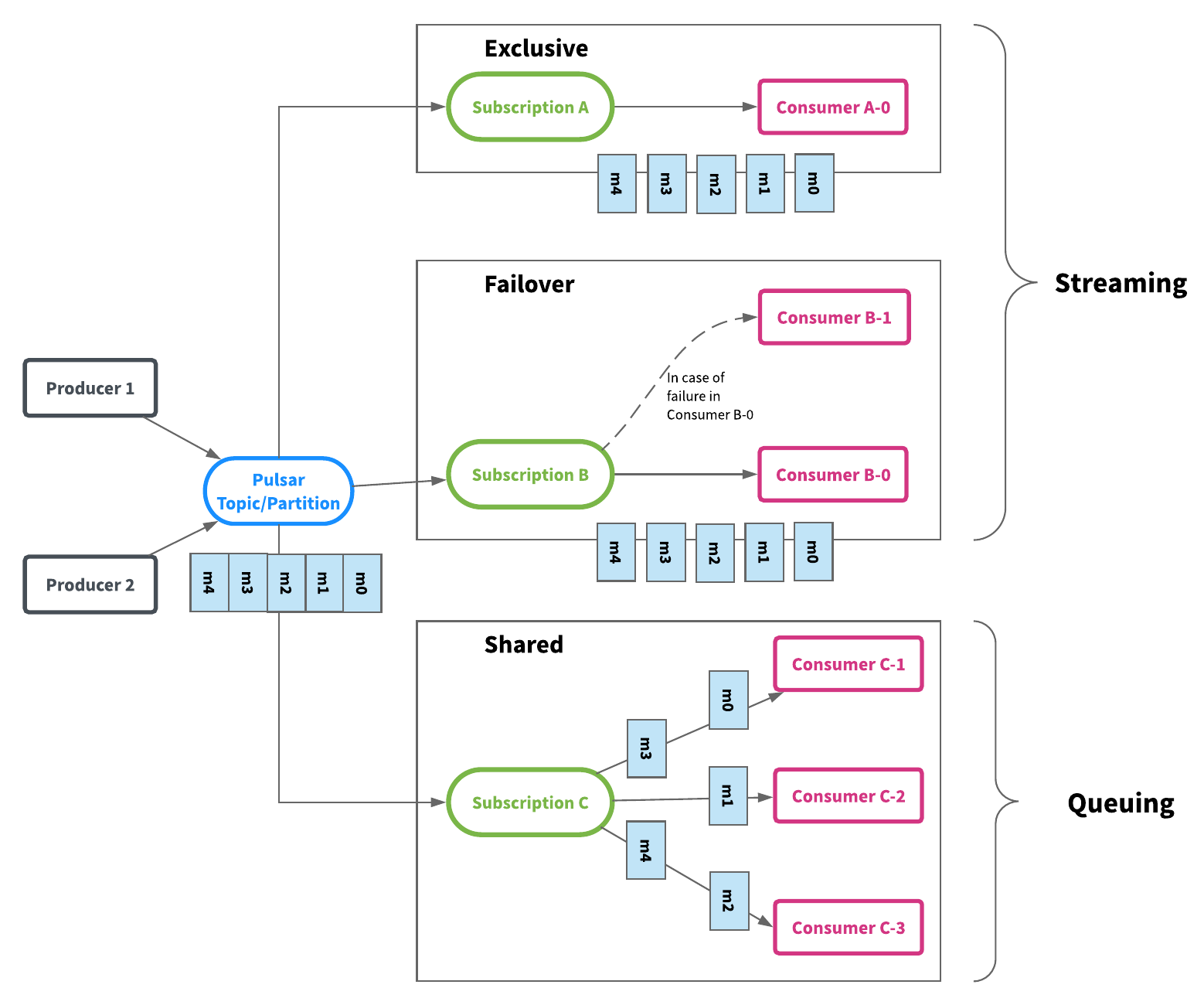
除了统一消息传递API之外,由于Pulsar主题分区实际上是存储在Apache BookKeeper中的分布式日志,它还提供了一个读取器(reader) API(类似于消费者(consumer) API但没有游标管理),以便用户完全控制如何使用消息本身。
消息确认(Message Ackmowledgment)
当使用跨机器分布的消息传递系统时,可能会发生故障。在消费者从消息传递系统中的主题消费消息的情况下,消费消息的消费者和服务于主题分区的消息代理都可能失败。当发生这样的故障时,能够从消费者停止的地方恢复消费,这样既不会错过消息,也不必处理已经确认的消息。在Apache Kafka中,恢复点通常称为偏移,更新恢复点的过程称为消息确认或提交偏移。在Apache Pulsar中,游标(cursors)用于跟踪每个订阅(subscription)的消息确认(message acknowledgment)。每当消费者在主题分区上确认消息时,游标都会更新,更新游标可确保消费者不会再次收到消息,但是游标并不像Apache Kafka那样简单。Apache Pulsar有两种方法可以确认消息,个体确认ack或累积确认消息。通过累积确认,消费者只需要确认它收到的最后一条消息,主题分区中的所有消息(包括)提供消息ID将被标记为已确认,并且不会再次传递给消费者,累积确认与Apache Kafka中的偏移更新实际上相同。Apache Pulsar的区别特征是能够个体单独进行ack,也就是选择性acking。消费者可以单体确认消息。 Acked消息将不会被重新传递。图5说明了ack个体和ack累积之间的差异(灰色框中的消息被确认并且不会被重新传递)。在图的顶部,它显示了ack累积的一个例子,M12之前的消息被标记为acked。在图的底部,它显示了单独进行acking的示例。仅确认消息M7和M12 - 在消费者失败的情况下,除了M7和M12之外,将重新传送所有消息。
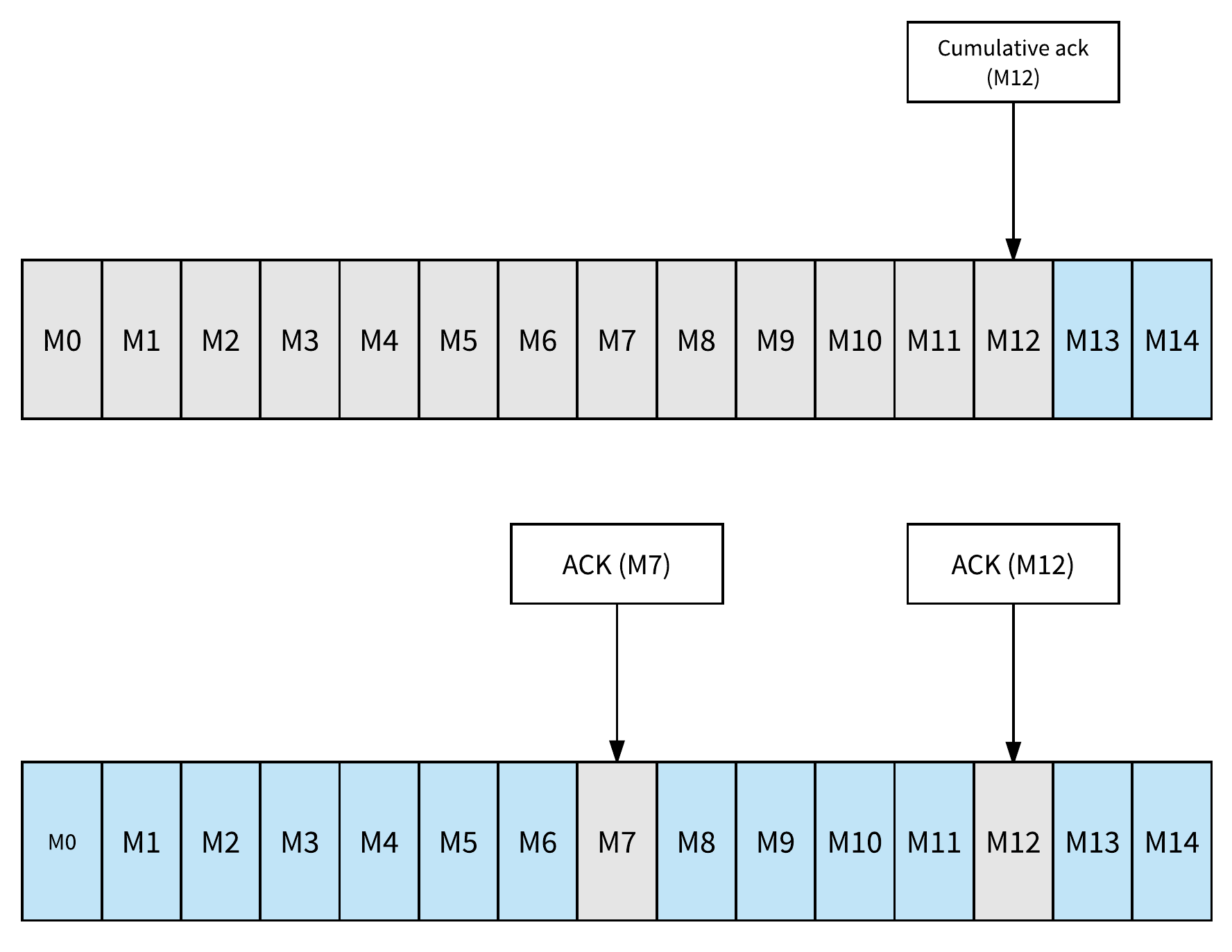
独占(exclusive)或故障转移(failover)订阅的消费者能够单个或累积地发送消息(ack message);而共享订阅中的消费者只允许单独发送消息(ack messages)。单独确认消息的能力为处理消费者故障提供了更好的体验。对于某些应用来说,处理那些已经确认过的消息可能是非常耗时的,防止重新传送已经确认的消息是非常重要。
Message Retention
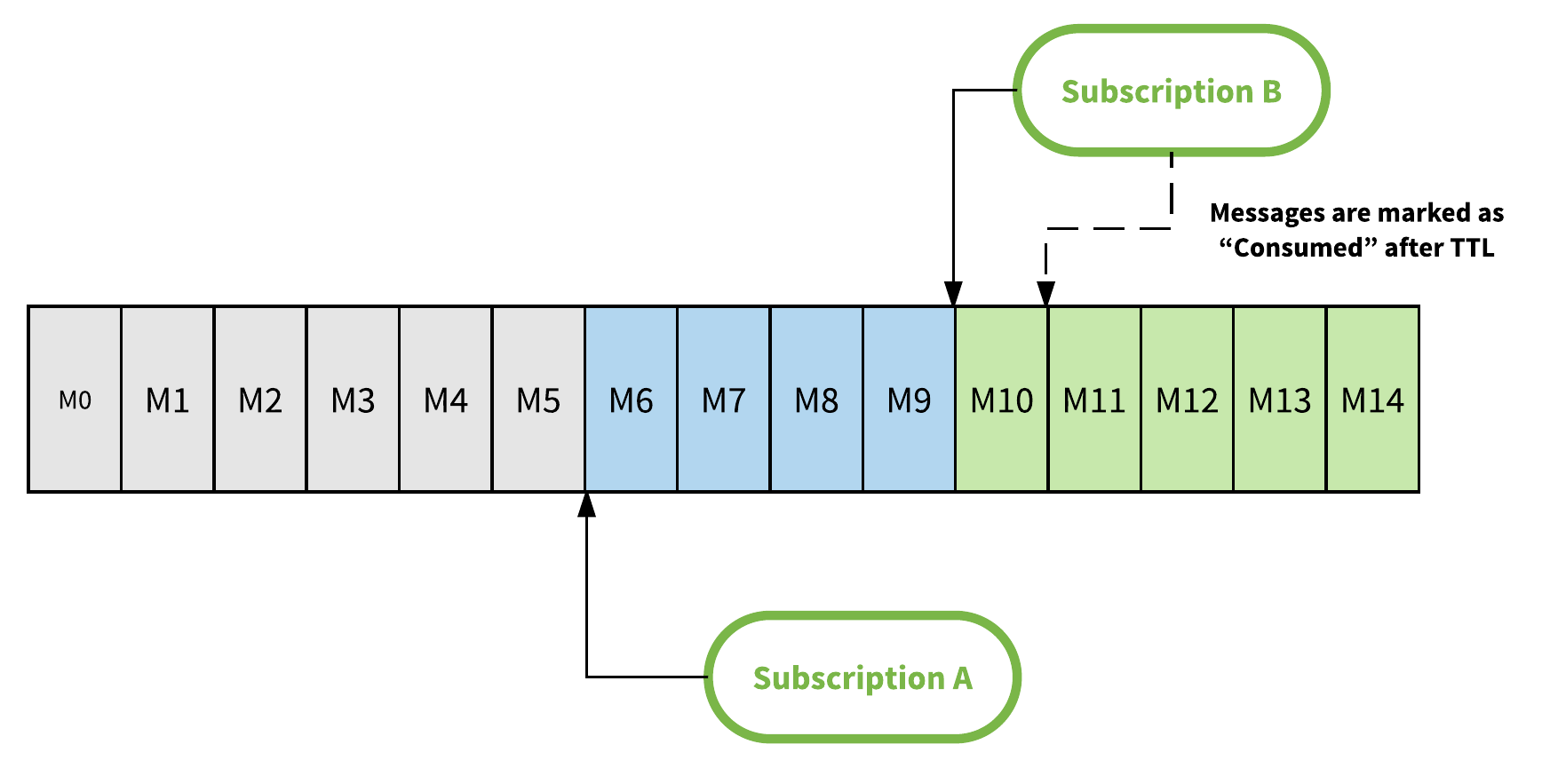
与传统的消息传递系统相比,消息在被确认后不会立即被删除。Pulsar代理在接收消息确认时仅更新cursor,只有在所有订阅已经使用它之后才能删除消息(消息在其sorcor中标记为已确认)。Pulsar还允许将消息保留更长时间,即使所有订阅已经消费了它们,这是通过配置消息保留期来完成的。图6说明了如何在具有2个订阅的主题分区中保留消息,订阅A已经消费了M6之前的所有消息,订阅B已经消费M10之前的所有消息。这意味着M6之前的所有消息(灰色框中)都可以安全删除,订阅A仍未使用M6和M9之间的消息,无法删除它们。如果主题分区配置了消息保留期,则即使A和B已经消耗它们,消息M0到M5也将在配置的时间段内保持不变。
Time-to-Live(TTL)
除了消息保留(message retention),Pulsar还支持消息生存时间(TTL)。如果消息在配置的TTL时间段内没有被消费者使用,则消息将自动标记为已确认。消息保留和消息TTL之间的区别在于消息保留适用于标记为已确认并将其设置为已删除的消息,保留是对主题应用的时间限制,而TTL适用于未使用的消息。因此,TTL是订阅消费的时间限制。上面的图6说明了Pulsar中的TTL。例如,如果订阅B没有活动消费者,则在配置的TTL时间段过后,消息M10将自动标记为已确认,即使没有消费者实际读取该消息。
Kafka与Pulsar异同:
| Kafka | Pulsar | |
|---|---|---|
| 概念 | 生产者 - 主题 - 消费者群体 - 消费者 | 生产者 - 主题 - 订阅 - 消费者 |
| 消费 | 更专注于分区上的流式传输、独占消息传递,没有共享消费。 | 统一消息传递模型和API。
|
| Acking | 简单的偏移offset管理
|
统一消息传递模型和API。
|
| Retention | 根据保留删除消息,如果消费者在保留期之前未读取消息,则会丢失数据。 | 消息仅在所有订阅消耗后删除,即使订阅的消费者长时间down,也没有数据丢失。 即使所有订阅都使用消息,也允许消息保留一段配置的保留期。 |
| TTL | 没有TTL支持 | 支持消息TTL |
Apache Pulsar将高性能流式处理(Apache Kafka所追求的)和灵活的传统队列(RabbitMQ所追求的)结合到一个统一的消息传递模型和API中,Pulsar使用统一的API提供一个流式处理和队列系统,具有相同的高性能。
本博客是学习记录,原文参照:https://streaml.io/blog/pulsar-streaming-queuing