之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍mapreduce计算模型能用于解决什么问题及有什么巧妙优化。
MapReduce到底解决什么问题?
MapReduce准确的说,它不是一个产品,而是一种解决问题的思路,能够用分治策略来解决问题。例如:网页抓取、日志处理、索引倒排、查询请求汇总等等问题。通过分治法,将一个大规模的问题,分解成多个小规模的问题(分),多个小规模问题解决,再统筹小问题的解(合),就能够解决大规模的问题。最早在单机的体系下计算,当输入数据量巨大的时候,处理很慢。如何能够在短时间内完成处理,很容易想到的思路是,将这些计算分布在成百上千的主机上,但此时,会遇到各种复杂的问题,例如:并发计算、数据分发、错误处理、数据分布、负载均衡、集群管理与通信等,将这些问题综合起来将是比较复杂的问题了,而Google为了方便用户使用系统,提供给了用户很少的接口,去解决复杂的问题。
(1) Map函数接口:处理一个基于key/value(后简称k/v)的数据对(pair)数据集合,同时也输出基于k/v的数据集合。
(2) Reduce函数接口:用来合并Map输出的k/v数据集合
假设我们要统计大量文档中单词出现的次数。
Map
输入K/V:pair(文档名称,文档内容)
输出K/V:pair(单词,1)
Reduce
输入K/V:pair(单词,1)
输出K/V:pair(单词,总计数)
Map伪代码:
Map(list<pair($docName, $docContent)>){//如果有多个Map进程,输入可以是一个pair,不是一个list
foreach(pair in list)
foreach($word in $docContent)
print pair($word, 1); // 输出list<k,v>
}
Reduce伪代码:
Reduce(list<pair($word, $count)>){//大量(word,1)(即使有多个Reduce进程,输入也是list<pair>,因为它的输入是Map的输出) map<string,int> result; foreach(pair in list) if result.isExist($word)
result[$word] += $count; else result[$word] = 1; foreach($keyin result) print pair($key, result[$key]); //输出list<k,v> }
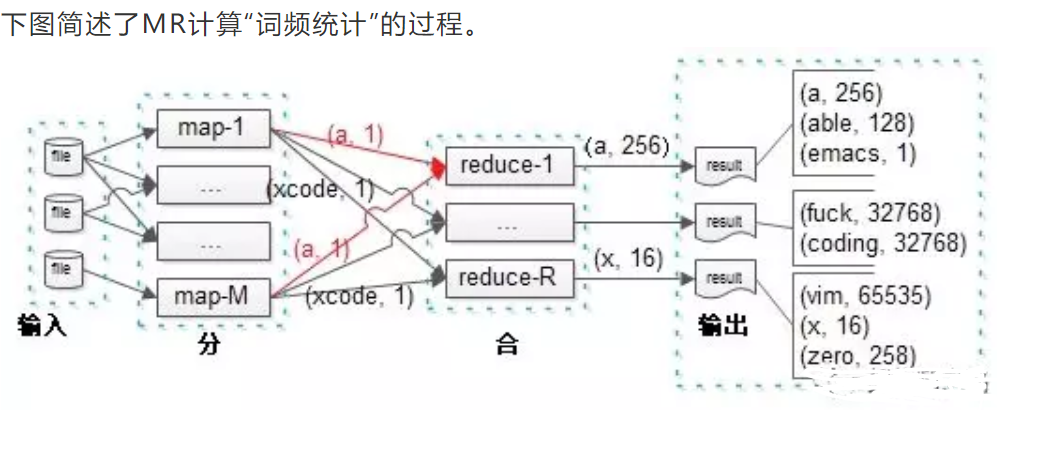
可以看到,R个reduce实例并发进行处理,直接输出最后的计数结果。需要理解的是,由于这是业务计算的最终结果,一个单词的计数不会出现在两个实例里。即:如果(a, 256)出现在了实例1的输出里,就一定不会出现在其他实例的输出里,否则的话,还需要合并,就不是最终结果。
再看中间步骤,map到reduce的过程,M个map实例的输出,会作为R个reduce实例的输入。
问题一:每个map都有可能输出(a, 1),而最终结果(a, 256)必须由一个reduce输出,那如何保证每个map输出的同一个key,落到同一个reduce上去呢?
这就是“分区函数”的作用。分区函数是使用MapReduce的用户按所需实现的,决定map输出的每一个key应当落到哪个reduce上的函数。如果用户没有实现,会使用默认分区函数。为了保证每一个reduce实例都能够差不多时间结束工作任务,分区函数的实现要点是:尽量负载均衡,即数据均匀分摊,防止数据倾斜造成部分reduce节点数据饥饿。如果数据不是负载均衡的,那么有些reduce实例处理的单词多,有些reduce处理的单词少,这样就可能出现所有reduce实例都处理结束,最后等待一个需要长时间处理的reduce情况。
问题二:每个map都有可能输出多个(a, 1),这样就增大了网络带宽资源以及reduce的计算资源,怎么办?
这就是“合并函数”的作用。有时,map产生的中间key的重复数据比重很大,可以提供给用户一个自定义函数,在一个map实例完成工作后,本地就做一次合并,这样将大大节约网络传输与reduce计算资源。合并函数在每个map任务结束前都会执行一次,一般来说,合并函数与reduce函数是一样的,区别是:合并函数是执行map实例本地数据合并,而reduce函数是执行最终的合并,会收集多个map实例的数据。对于词频统计应用,合并函数可以将:一个map实例的多个(a, 1)合并成一个(a, count)输出。
问题三:如何确定文件到map的输入呢?
随意即可,只要负载均衡,均匀切分输入文件大小就行,不用管分到哪个map实例都能正确处理。
问题四:map和reduce可能会产生很多磁盘io,将更适用于离线计算,完成离线作业。