1.什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”?
1、是么是平台
Java是可以跨平台的编程语言,那我们首先得知道什么是平台,我们把CPU处理器与操作系统的整体叫平台。
CPU大家都知道,如果计算机是人,那CPU就是人的大脑,它既负责思维运算,又负责身体各部件的命令控制。CPU的种类很多,除去我们熟知的Intel与AMD外,还有比如上面说到的SUN的Sparc,比如IBM的PowerPC等等,这些各个公司生产的CPU使用或相同或不同的指令集。指令集就是cpu中用来计算和控制计算机系统的一套指令的集合。指令集又分为精简指令集(RISC)与复杂指令集(CISC),每种cpu都有其特定的指令集。开发程序,首先要知道该程序在什么CPU上运行,也就是要知道CPU所使用的指令集。
下面说操作系统,操作系统是充当用户和计算机之间交互的界面软件,不同的操作系统支持不同的CPU,严格意义上说是不同的操作系统支持不同CPU的指令集。例如 windows和liunx都支持Intel和AMD的复杂指令集,但并不支持PowerPC所使用的精简指令集,而早期的MAC电脑使用的是PowerPC处理器,所以也就无法在MAC下直接安装windows,直到05年MAC改用了Intel的CPU,才使在MAC下安装windows成为可能。但问题来了,原来的MAC 操作系统也只支持PowerPC,在Intel上也不能安装,怎么办?所以苹果公司也得重写自己的MAC操作系统以支持这种变化。最后总结下,我们要知道,不同的操作系统支持不同的CPU指令集,现在的windows,liunx,mac,solaris都支持Intel与AMD的CPU指令集。
有了上面的铺垫,旺旺老师就要告诉大家,如果您要开发程序,首先应该确定:1,CPU类型,也就是指令集类型;2,操作系统;我们把这种软硬件的结合叫平台。也可以说“平台= CPU+OS”。又因为现在主流的操作系统都支持主流的CPU,所以有时也把操作系统称为平台。
知道什么是平台,我们看Java跨平台原理。
2、Java跨平台原理
首先看一张与C语言有关的图:

如果您有过C的开发经历,这张图看起来将非常轻松。我们知道,只要是用标准C开发的程序,使用不同的编译器编译后的可执行文件是可以在对应平台运行的,比如windows可以使用VC编译,那编译后的exe文件就可以在windows下运行;liunx下可以使用GCC编译,生成的可执行文件就可以在Liunx上运行。
到这里请大家思考一个问题:“VC编译的exe能在Liunx上运行吗?”
答案肯定是否定的。使用特定编译器编译的程序只能在对应的平台运行,这里也可以说编译器是与平台相关的,编译后的文件也是与平台相关的。我们说的语言跨平台是编译后的文件跨平台,而不是源程序跨平台,如果是源程序,任何一门语言都是跨平台的语言了。这个如果您不明白,看下面一个案例:
比 如火星真的有外星人(并且毋庸置疑,火星是韩国人的,火星文也一定是韩国人发明的),就像我们观察蚂蚁一样,火星人默默的观察着我们,有一天,当人类做的 什么事情让火星人实在是看不下去了(比如旺旺老师的书出版了你不买,哈哈,呕吐中,没关系,吐啊吐啊就吐习惯了),所以决定来地球教育我们,但有一个问 题,火星人只会说火星文,地球人理解不了,怎么办啊?找翻译呗(也许非主流可以帮忙,玩笑)!由中文翻译把火星文翻译为中文,英文翻译把火星文翻译为英文 等等等等,但这样问题来了,中文翻译翻译的东西只有中国人能听懂,美国人法国人根本不明白,英文翻译翻译的文章中国人也不明白,也就是语言不能跨平台。
那上例中,火星文就是C语言,各个国家是平台,中文翻译英文翻译就是对应平台的编译器,编译后的文章就是可执行文件。虽然源文章火星文是与平台无关的,但翻译器是与特定国家相关的,翻译后的文章也是与特定国家相关的。
接下来思考另一个问题“怎么让火星文跨平台呢?”
火星人想到了地球上有世界语,于是首先把自己的文章翻译为世界语;世界语各国人当然看不懂,没关系,火星人又给每个国家配备了一个世界语到本地语的翻译,这 样火星文只要翻译一次(翻译为世界语),就可以到各个国家运行了。还要记住,这个过程火星人要提供两个组件,第一是火星文到世界语的翻译,第二是世界语到 对应本地语言的翻译。如下图:

有了上面案例的积累,我们也知道了语言跨平台原理:“不能编译成机器语言,因为那样就与平台相关了,编译为中间语言,再由解释器二次编译,解释执行。”如下是Java跨平台原理表示图:

上图中的.java就是源程序,类似于c语言的.c,生成的中间码是.class,这个既是我们上文中说的中间语,各个平台解释器就是各种国家翻译。
接下来我们再比较下两种方式的差异:第一,C语言是编译执行的,编译器与平台相关,编译生成的可执行文件与平台相关;第二,Java是解释执行的,编译为中间码的编译器与平台无关,编译生成的中间码也与平台无关(一次编译,到处运行),中间码再由解释器解释执行,解释器是与平台相关的,也就是不同的平台需要不同的解释器.
这里再说下语言根据执行方式的不同分类:第一是编译执行,如上文中说到的C,它把源程序由特定平台的编译器一次性编译为平台相关的机器码,它的优点是执行速度快,缺点是无法跨平台;第二是解释执行,如HTML,JavaScript,它使用特定的解释器,把代码一行行解释为机器码,类似于同声翻译,它的优点是可以跨平台,缺点是执行速度慢,暴露源程序;第三种是从Java开始引入的“中间码+虚拟机”的方式,它既整合了编译语言与解释语言的优点,同时如虚拟机又可以解决如垃圾回收,安全性检查等这些传统语言头疼的问题,所以其后微软的.NET平台也使用的这种方式。
Java先编译后解释
同一个.class文件在不同的虚拟机会得到不同的机器指令(Windows和Linux的机器指令不同),但是最终执行的结果却是相同的
最后再请大家思考一个问题:“开发Java程序需要什么?运行Java程序需要什么?”
答案:开发Java需要由源文件到中间文件的解释器;运行Java需要对应平台的解释器。与火星人要提供两个组件一样,SUN也得提供两个组件:第一,把源程序翻译为中间码的编译器;第二,相应平台的解释器。SUN把这两个组件包含在一个工具包中,我们把它叫做JDK(Java Developent ToolKit),接下来我们学习JDK的安装与使用。
2.JDK、JRE、JVM关系是什么?
JDK(Java Development Kit)
JRE(Java Runtime Environment)
JVM(Java Virtual Machines)
JDK是 Java 语言的软件开发工具包(SDK)。在JDK的安装目录下有一个jre目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib合起来就称为jre。
一、JDK
JDK(Java Development Kit) 是整个JAVA的核心,包括了Java运行环境(Java Runtime Envirnment),一堆Java工具(javac/java/jdb等)和Java基础的类库(即Java API 包括rt.jar)。
JDK是java开发工具包,基本上每个学java的人都会先在机器 上装一个JDK,那他都包含哪几部分呢?在目录下面有 六个文件夹、一个src类库源码压缩包、和其他几个声明文件。其中,真正在运行java时起作用的 是以下四个文件夹:bin、include、lib、 jre。有这样一个关系,JDK包含JRE,而JRE包 含JVM。
bin:最主要的是编译器(javac.exe)
include:java和JVM交互用的头文件
lib:类库
jre:java运行环境
1234
(注意:这里的bin、lib文件夹和jre里的bin、lib是 不同的)
总的来说JDK是用于java程序的开发,而jre则是只能运行class而没有编译的功能。
二、JRE
JRE(Java Runtime Environment,Java运行环境),包含JVM标准实现及Java核心类库。JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器)
JRE是指java运行环境。光有JVM还不能成class的 执行,因为在解释class的时候JVM需要调用解释所需要的类库lib。 (jre里有运行.class的java.exe)
JRE ( Java Runtime Environment ),是运行 Java 程序必不可少的(除非用其他一些编译环境编译成.exe可执行文件……),JRE的 地位就象一台PC机一样,我们写好的Win64应用程序需要操作系统帮 我们运行,同样的,我们编写的Java程序也必须要JRE才能运行。
三、JVM
JVM(Java Virtual Machine),即java虚拟机, java运行时的环境,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。针对java用户,也就是拥有可运行的.class文件包(jar或者war)的用户。里面主要包含了jvm和java运行时基本类库(rt.jar)。rt.jar可以简单粗暴地理解为:它就是java源码编译成的jar包。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。这就是Java的能够“一次编译,到处运行”的原因。
四、JDK、JRE、JVM三者的联系与区别
1.三者联系:
JVM不能单独搞定class的执行,解释class的时候JVM需要调用解释所需要的类库lib。在JDK下面的的jre目录里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。JVM+Lib=JRE。总体来说就是,我们利用JDK(调用JAVA API)开发了属于我们自己的JAVA程序后,通过JDK中的编译程序(javac)将我们的文本java文件编译成JAVA字节码,在JRE上运行这些JAVA字节码,JVM解析这些字节码,映射到CPU指令集或OS的系统调用。
2.三者区别:
a.JDK和JRE区别:在bin文件夹下会发现,JDK有javac.exe而JRE里面没有,javac指令是用来将java文件编译成class文件的,这是开发者需要的,而用户(只需要运行的人)是不需要的。JDK还有jar.exe, javadoc.exe等等用于开发的可执行指令文件。这也证实了一个是开发环境,一个是运行环境。
b.JRE和JVM区别:JVM并不代表就可以执行class了,JVM执行.class还需要JRE下的lib类库的支持,尤其是rt.jar。
参考文献:http://playkid.blog.163.com/blog/static/56287260201372113842153/
https://baike.baidu.com/item/JVM/2902369?fr=aladdin
---------------------
版权声明:本文为CSDN博主「Ancientear」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ancientear/article/details/79483592
3.Java支持的数据类型有哪些?什么是自动拆装箱?
基本数据类型:
整数值型:
字符型:
浮点类型:
布尔型:
Java有8种基本数据类型:
整数型:byte(8)、short(16)、int(32)、long(64)
浮点类型:float(32)、double(64)
字符型:char(16位的Unicode字符)
布尔型:boolean
jdk1.5之后支持自动拆装箱
自动装箱就是Java编译器在基本数据类型和对应的对象包装类型之间做的一个转化。自动拆箱反之。
4.面向对象是什么?
面向对象是一种编程风格,Python一切皆对象,把一切东西看成是一个个对象,比如人、耳机、鼠标、水杯等,他们各自都有属性,比如:耳机是白色的,鼠标是黑色的,水杯是圆柱形的等等,把这些对象拥有的属性变量和操作这些属性变量的函数打包成一个类来表示
面向对象有三大特性:封装,继承,多态。
封装:
将一类事物的属性和行为抽象成一个类,使其属性私有化,行为公开化,提高了数据的隐秘性的同时,使代码模块化。这样做使得代码的复用性更高。
意义:
将属性和方法放到一起做为一个整体,然后通过实例化对象来处理;
隐藏内部实现细节,只需要和对象及其属性和方法交互就可以了;
对类的属性和方法增加 访问权限控制。
继承:
在程序中,继承描述的是多个类之间的所属关系,如果一个类A里面的属性和方法可以复用,则可以通过继承的方式,传递到类B里,那么类A就是基类,也叫做父类;类B就是派生类,也叫做子类。继承进一步提高了代码的复用性。
多态:
所谓多态:定义时的类型和运行时的类型不一样,此时就成为多态 ,多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚“鸭子类型”。
鸭子类型:虽然我想要一只"鸭子",但是你给了我一只鸟。 但是只要这只鸟走路像鸭子,叫起来像鸭子,游泳也像鸭子,我就认为这是鸭子。
Python的多态,就是弱化类型,重点在于对象参数是否有指定的属性和方法,如果有就认定合适,而不关心对象的类型是否正确。
面向过程:根据业务逻辑从上到下写代码
面向对象:将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程
举个例子:吃鸭子
第一种方式(面向过程):
1)养鸭子
2)鸭子长成
3)杀
4)作料
5)烹饪
6)吃
7)卒
第二种方式(面向对象):
1)找个卖啤酒鸭的人
2)给钱 交易
3)吃
4)胖6斤
---------------------
版权声明:本文为CSDN博主「爱吃萝卜的喵」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zzd864582451/article/details/85335748
5.什么是值传递和引用传递?
一、基本类型和引用类型的理解Java中的数据类型分为两种为基本类型和引用类型。
1、基本类型的变量保存原始值,所以变量就是数据本身。
常见的基本类型:byte,short,int,long,char,float,double,Boolean,returnAddress。
2、引用类型的变量保存引用值,所谓的引用值就是对象所在内存空间的“首地址值”,通过对这个引用值来操作对象。
常见的引用类型:类类型,接口类型和数组。
二、值传递和引用传递的理解
1、值传递 在方法的调用过程中,实参把它的实际值传递给形参,此传递过程就是将实参的值复制一份传递到函数中,这样如果在函数中对该值(形参的值)进行了操作将不会影响实参的值。因为是直接复制,所以这种方式在传递大量数据时,运行效率会特别低下。
2、引用传递 引用传递弥补了值传递的不足,如果传递的数据量很大,直接复过去的话,会占用大量的内存空间,而引用传递就是将对象的地址值传递过去,函数接收的是原始值的首地址值。在方法的执行过程中,形参和实参的内容相同,指向同一块内存地址,也就是说操作的其实都是源数据,所以方法的执行将会影响到实际对象。
举例说明:public class Example {
String str = new String("hello"); char[] ch = {'a', 'b'};
public static void main(String[] args) {
Example ex = new Example();
ex.change(ex.str, ex.ch);
System.out.println(ex.str + " and");
System.out.println(ex.ch); }
public void change(String str, char[] ch) {
str = "ok";
ch[0] = 'c';
}}
输出是:hello andcb
过程分析:
1、为对象分配空间
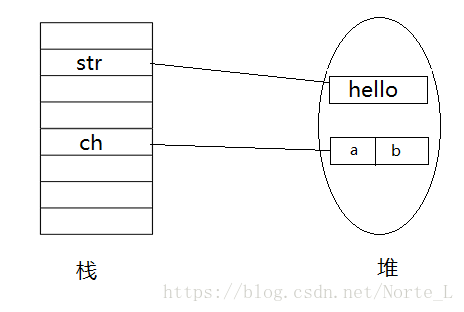
2、执行change()方法执行前实参(黑色)和形参(红色)的指向如下:

因为String是不可变类且为值传递,而ch[]是引用传递,所以方法中的str = "ok",相当于重新创建一个对象并没有改变实参str的值,数组是引用传递,直接改变,所以执行完方法后,指向关系如下:
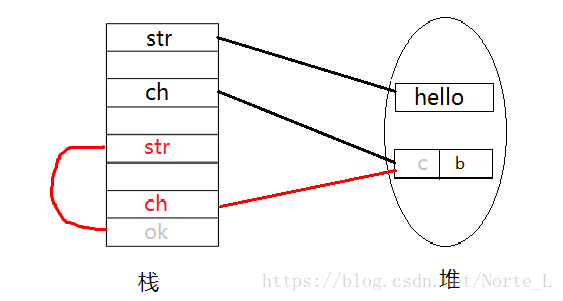
3.结论通过上面的分析我们可以得出以下结论:基本数据类型传值,对形参的修改不会影响实参;引用类型传引用,形参和实参指向同一个内存地址(同一个对象),所以对参数的修改会影响到实际的对象。
String, Integer, Double等immutable的类型特殊处理,可以理解为传值,最后的操作不会修改实参对象。
---------------------
版权声明:本文为CSDN博主「Norte_L」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Norte_L/article/details/80250057
6.Java中的方法覆盖(Overriding)和方法重载(Overloading)是什么意思?
java中的方法重载发生在同一个类里面两个或者多个方法的方法名相同但是参数不同的情况。与此相对,方法覆盖是说子类重新定义了父类的方法。方法覆盖必须有相同的方法名,参数列表和返回类型。
覆盖者可能不会限制它所覆盖的方法的访问。
重载(Overloading)
(1)方法重载是让类以统一的方法处理不同类型数据的一种手段。多个同名函数同时存在,具有不同的参数个数(类型)。重载Override是一个类中多态性的一种表现。
(2)java的方法重载,就是在类中可以创建多个方法,他们具有相同的名字,但具有不同参数和不同的定义。调用方法时通过传递给他们不同的参数个数和参数类型来决定具体使用那个方法,这就是多态性。
(3)重载的时候,方法名要一样,但是参数类型和个数不一样,返回值类型可以相同也可以不同。无法以返回类型来作为重载函数的区分标准。
重写(Overriding)
(1)父类与子类的多态性,对父类的函数进行重新定义。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写。在java中,子类可继承父类的方法,则不需要重新编写相同的方法。但有时子类并不想原封不动继承父类的方法,而是想做一定的修改,这就采用方法重写。方法重写又称方法覆盖。
(2)若子类中的方法与父类的中的某一方法具有相同的方法名、返回类型和参数表,则新方法覆盖原有的方法。如需要父类的原有方法,可以使用super关键字,该关键字引用房钱类的父类。
(3)子类函数访问权限大于父类。
7.Java中,什么是构造方法?什么是构造方法重载?什么是复制构造方法?
当新对象被创建的时候,构造方法会被调用。每一个类都有构造方法。在程序员没有给类提供构造方法的情况下,Java编译器会为这个类创建一个默认的构造方法。
Java中构造方法重载和方法重载很相似。可以为一个类创建多个构造方法。每一个构造方法必须有它自己唯一的参数列表。
Java不支持像C++中那样的复制构造方法,这个不同点是因为如果你不自己写构造方法的情况下,Java不会创建默认的复制构造方法。
---------------------
版权声明:本文为CSDN博主「never疯」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40574571/article/details/90600081
8.Java支持多继承么?
不支持,Java中每个类都只能继承一个类,但可以实现多个接口。。。
9.String和StringBuilder、StringBuffer的区别?
一、Java String 类——String字符串常量
字符串广泛应用 在Java 编程中,在 Java 中字符串属于对象,Java 提供了String 类来创建和操作字符串。
需要注意的是,String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,这样不仅效率低下,而且大量浪费有限的内存空间。我们来看一下这张对String操作时内存变化的图:
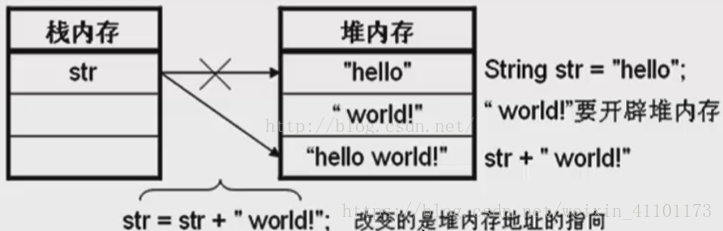
我们可以看到,初始String值为“hello”,然后在这个字符串后面加上新的字符串“world”,这个过程是需要重新在栈堆内存中开辟内存空间的,最终得到了“hello world”字符串也相应的需要开辟内存空间,这样短短的两个字符串,却需要开辟三次内存空间,不得不说这是对内存空间的极大浪费。为了应对经常性的字符串相关的操作,谷歌引入了两个新的类——StringBuffer类和StringBuild类来对此种变化字符串进行处理。
二、Java StringBuffer 和 StringBuilder 类——StringBuffer字符串变量、StringBuilder字符串变量

当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类。
和 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
三者的继承结构
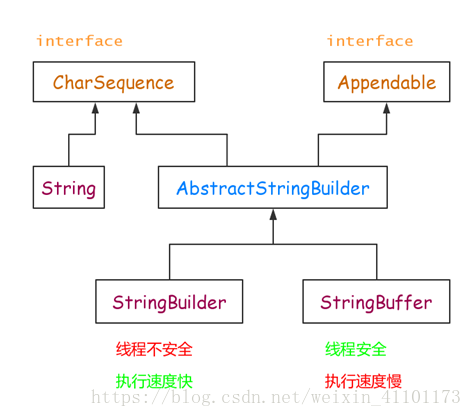
三者的区别:

(1)字符修改上的区别(主要,见上面分析)
(2)初始化上的区别,String可以空赋值,后者不行,报错
①String
String s = null;
String s = “abc”;
②StringBuffer
StringBuffer s = null; //结果警告:Null pointer access: The variable result can only be null at this location
StringBuffer s = new StringBuffer();//StringBuffer对象是一个空的对象
StringBuffer s = new StringBuffer(“abc”);//创建带有内容的StringBuffer对象,对象的内容就是字符串”
小结:(1)如果要操作少量的数据用 String;
(2)多线程操作字符串缓冲区下操作大量数据 StringBuffer;
(3)单线程操作字符串缓冲区下操作大量数据 StringBuilder。
10、内部类与外部类的调用
部类:
①静态内部类中可以有非静态的方法
②当内部类中有静态方法或者静态成员变量时,一定是静态内部类
一般内部类在外部类的成员变量位置,像这样:
1 1 public class Outer { 2 class Inner{ 3 4 } 5 } 2 3 1、外部类访问内部类: 4 5 内部类被static修饰:可以直接new 6 7 Inner in = new Inner(); 8 9 内部类没有被static修饰:得先new出来外部类的实例,再new内部类的 10 11 Inner in = new Outer().new Inner(); 12 13 2、内部类访问外部类:(外部类.this.变量) 14

1 2 3 1 public class Outer {
2 int x = 9;3 class Inner{4 int x = 8;5 public void test(){
6 int x = 7;7 System.out.println(x);
8 System.out.println(this.x);9 System.out.println(Outer.this.x); 10 test1();
11 }
12 }
13
14 private void test1(){
15 System.out.println("test"); 16 }
17 public static void main(String[] args) {
18 Inner in = new Outer().new Inner();
19 in.test();
20 }
21 } 4 5 复制代码 6
输出为:7,8,9,test
分析:第七行第八行相信大家都没有什么问题,第九行输出的是9,说明访问到了外部类的变量,而输出的test说明内部类访问到了外部类的test1方法
总结:
输出是9的原因:因为内部类持有一个外部类的引用,格式:外部类名.this
可以调用private方法原因是:因为他们在一个类Outer中所以可以调用
3、外部类和内部类中的方法相互访问:
①外部类的静态方法test和非静态内部类的非静态方法voice的相互访问:
! test----->voice 先new外类再new内类,再调方法
1 1 public class Outerclass { 2 3 2 class Inner{ 4 5 3 public void voice(){ 6 7 4 System.out.println("voice()"); 8 9 5 } 10 11 6 } 12 13 7 public static void test(){ 14 15 8 new Outerclass().new Inner().voice(); 16 17 9 } 18 19 10 public static void main(String[] args) { 20 //主函数调用test方法 11 test(); 21 22 13 } 23 24 14 } 25
输出:voice();
!! voice----->test 外类.this.方法(持有的外部类的引用)
1 1 public class Outerclass {
2 class Inner{ 3 public void voice(){
4 Outerclass.this.test(); 5 }
6 }
7 public static void test(){
8 System.out.println("test()"); 9 }
10 public static void main(String[] args) { 2 //主函数调用voice()
11 Inner in = new Outerclass().new Inner(); 12 in.voice(); 13 } 14 } 3 4 复制代码 5
输出:test();
②外部类的非静态方法test和静态内部类中的非静态方法voice之间的相互调用
! voice------>test
1 1 public class Outerclass { 2 2 static class Inner{ 3 3 public void voice(){ 4 4 new Outerclass().test(); 5 5 } 6 6 } 7 7 public void test(){ 8 8 System.out.println("test()"); 9 9 } 10 10 public static void main(String[] args) { 11 //主函数调用voice()方法 11 new Outerclass.Inner().voice(); 12 12 } 13 13 }
输出:test();
!! test----->voice
1 public class Outerclass { 2 static class Inner{ 3 public void voice(){ 4 System.out.println("voice()"); 5 } 6 } 7 public void test(){ //1、其他类访问外部类中的静态内部类的非静态方法 8 // new Outerclass.Inner().voice(); //2、此处的Outerclass中的test方法访问静态内部类中的非静态方法 new Inner().voice(); 9 } 10 public static void main(String[] args) { //主函数调用test方法 11 new Outerclass().test(); 12 } 13 } 复制代码
输出:voice();
4、总结:
外部类访问内部类:必须建立内部类的对象
内部类访问外部类:内部类可以直接访问外部类的成员包括私有成员,因为外部类持有内部类的引用
特例:内部类写在外部类的方法中(即局部变量的位置)
1、内部来外部类均可定义变量/常量
2、只能被final/abstract修饰
3、只能访问被final/abstract修饰的变量
4、可以直接访问外部类中的成员,因为还持有外部类的引用
11、多线程
a)线程与进程的区别,举例说明
进程是资源分配和管理的基本单位,进程中包含的一个或多个执行单元叫做线程。一个程序至少有一个进程,一个进程至少有一个线程
理解线程与进程
如果把CPU比喻成工厂,单核CPU就是指工厂的电力有限,一次只能给一个车间供应电力,当CPU给某个车间供电的时候,其他车间都要暂时停工。
如果是多核CPU,就相当于这个工厂的电力可以一次供应多个车间
这时车间就相当于进程
一个车间里,可以有很多个机器人,他们一起完成这个车间的任务
机器人就相当于线程
一个车间可以有多个机器人,一个进程可以有多个线程
但是机器人需要供电才能运作,单核CPU就相当于一次只能给一个机器人供电
所以在实际生产中,工厂一次只能给一个车间的一个机器人供电,下一次给另外一个机器人供电(可以是相同车间或者不同车间),就这样交替供电来完成工厂中所有的任务
在系统中也一样,单核CPU一次只能给一个进程的一个线程调度,然后不同的线程交替执行,来完成系统中所有的任务
车间的空间是这个车间的机器人们共享的,相应地,一个进程中的内存空间可以给这个进程中的所有线程共享
但不同车间的空间不能共享,所以不同进程不能共享内存空间
---------------------
版权声明:本文为CSDN博主「sun_ljz」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhao18933/article/details/46699629
b)为什么要使用多线程
1、避免阻塞(异步调用)
单个线程中的程序,是顺序执行的。如果前面的操作发生了阻塞,那么就会影响到后面的操作。这时候可以采用多线程,我感觉就等于是异步调用。这样的例子有很多:
ajax调用,就是浏览器会启一个新的线程,不阻塞当前页面的正常操作;
流程在某个环节调用web service,如果是同步调用,则需要等待web service调用结果,可以启动新线程来调用,不影响主流程;
android里,不要在ui thread里执行耗时操作,否则容易引发ANR;
创建工单时,需要级联往其他表中插入数据,可以将级联插入的动作放到新线程中,先返回工单创建的结果……
2、避免CPU空转
以http server为例,如果只用单线程响应HTTP请求,即处理完一条请求,再处理下一条请求的话,CPU会存在大量的闲置时间
因为处理一条请求,经常涉及到RPC、数据库访问、磁盘IO等操作,这些操作的速度比CPU慢很多,而在等待这些响应的时候,CPU却不能去处理新的请求,因此http server的性能就很差
所以很多web容器,都采用对每个请求创建新线程来响应的方式实现,这样在等待请求A的IO操作的等待时间里,就可以去继续处理请求B,对并发的响应性就好了很多
当然,这种设计方式并不是绝对的,现在像node.js、Nginx等新一代http server,采用了事件驱动的实现方式,用单线程来响应多个请求也是没问题的。甚至实现了更高的性能,因为多线程是一把双刃剑,在提升了响应性的同时,创建销毁线程都是需要开销的,另外CPU在线程之间切换,也会带来额外的开销。避免了这些额外开销,可能是node.js等http server性能优秀的原因之一吧
3、提升性能
在满足条件的前提下,多线程确实能提升性能
打一个比方,多线程就相当于,把要炒的菜放到了不同的锅里,然后用不同的炉来炒,当然速度会比较快。本来需要先炒西红柿,10分钟;再炒白菜10分钟;加起来就需要20分钟。用了多线程以后,分别放在2个锅里炒,10分钟就都炒好了
基本上,需要满足3个条件:
第1,任务具有并发性,也就是可以拆分成多个子任务。并不是什么任务都能拆分的,条件还比较苛刻
子任务之间不能有先后顺序的依赖,必须是允许并行的
比如
Java代码 ![]()
- a = b + c
- d = e + f
这个是可以并行的;
Java代码 ![]()
- a = b + c
- d = a + e
这个就无法并行了,第2步计算需要依赖第1步的计算结果,即使分成2个线程,也不会带来任何性能提升
另外,还不能有资源竞争。比如2个线程都需要写一个文件,第1个线程将文件锁定了,第2个线程只能等着,这样的2个子任务,也不具备并发性;执行sychronized代码,也是同样的情况
第2,只有在CPU是性能瓶颈的情况下,多线程才能实现提升性能的目的。比如一段程序,瓶颈在于IO操作,那么把这个程序拆分到2个线程中执行,也是无法提升性能的
第3,有点像废话,就是需要有多核CPU才行。否则的话,虽然拆分成了多个可并行的子任务,但是没有足够的CPU,还是只有一个CPU在多个线程中切换来切换去,不但达不到提升性能的效果,反而由于增加了额外的开销,而降低了性能。类似于虽然把菜放到了2个锅里,但是只有1个炉子一样
如果上述条件都满足,有一个经验公式可以计算性能提升的比例,叫阿姆达尔定律:
速度提升比例 = 1/[(1-P)+(P/N)],其中P是可并行任务的比例,N是CPU核心数量
假设CPU核心是无限的,则公式简化为1/(1-P)
假设P达到了80%(已经非常高了),那么速度提升比例也只能达到5倍而已
c)用户线程和守护线程(系统线程),举例
在Java中有两类线程:User Thread(用户线程)、Daemon Thread(守护线程)
Java平台把操作系统的底层进行了屏蔽,在JVM虚拟平台里面构造出对自己有利的机制,这就是守护线程的由来。Daemon的作用是为其他线程的运行提供服务,比如说GC线程。
User Thread线程和Daemon Thread唯一的区别之处就在虚拟机的离开,如果User Thread全部撤离,那么Daemon Thread也就没啥线程好服务的了,所以虚拟机也就退出了。
守护线程用户也可以自行设定,方法:public final void setDaemon(boolean flag)
注意点:
正在运行的常规线程不能设置为守护线程。
thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个IllegalThreadStateException异常。
在Daemon线程中产生的新线程也是Daemon的(这里要和linux的区分,linux中守护进程fork()出来的子进程不再是守护进程)
根据自己的场景使用(在应用中,有可能你的Daemon Thread还没来的及进行操作时,虚拟机可能已经退出了)
非守护线程案例: 1
2
3 复制代码
4
5 public class DaemonTest {
6 public static void main(String[] args) {
7 Thread thread = new Thread(new Runnable() {
8 @Overridepublic void run() {
9 try {Thread.sleep(2000);}
10 catch (InterruptedException e) {
11 e.printStackTrace();}
12 System.out.println("thread 线程结束....");}});
13 thread.start();
14 System.out.println("main线程 结束....");
15 }
16 }
17
18 复制代码
19
结果输出:
main线程 结束....
thread 线程结束....
守护线程案例:
1 package cn.kafka.t; 2 public class DaemonTest { 3 public static void main(String[] args) { 4 Thread thread = new Thread(new Runnable() { 5 @Overridepublic void run() {t 6 ry { 7 Thread.sleep(2000);} 8 catch (InterruptedException e) { 9 e.printStackTrace();} 10 System.out.println("thread 线程结束...."); 11 } 12 } 13 ); 14 //设置为守护线程 thread.setDaemon(true);thread.start(); 15 System.out.println("main线程 结束....") 16 ;} 17 } 18 19 复制代码 20
结果输出:
main线程 结束....
结论:主线程结束,JVM直接退出,守护线程不管是否运行结束都要伴随着JVM的退出而退出
d)线程的优先级别:
每个进程都有相应的优先级,优先级决定它何时运行和接收多少CPU时间。最终的优先级共32级,是从0到31的数值,称为基本优先级别(Base Priority LeveL)。系统按照不同的优先级调度进程的运行,0-15级是普通优先级,进程的优先级可以动态变化,高优先级进程优先运行,只有高优先级进程不运行时,才调度低优先级进程运行,优先级相同的进程按照时间片轮流运行。16-31级是实时优先级,实时优先级与普通优先级的最大区别在于相同优先级进程的运行不按照时间片轮转,而是先运行的进程就先控制CPU,如果它不主动放弃控制,同级或低优先级的进程就无法运行。这就是进(线)程的推进问题。
e)死锁:
死锁是指在俩个或多个并发的进程中,如果每个进程持有某种资源而又等待别的进程释放它们现保持着的资源,否则就不能向前推进。此时,每个进程都占用了一定的资源但是又不能向前推进,则称这一组进程产生了死锁。
简单的说:就是俩个或多个进程无止境的等候,永远不会成立的条件的一种系统状态。、
产生死锁的根本原因是系统能够提供的资源个数要求比该资源的进程数少,具体原因:系统资源不足,进程推进顺序非法。
死锁的四个必要条件:
互斥条件:一个资源每次只能被一个进程使用。
请求和保持条件:一个进程因请求而阻塞时,对以获得的资源保持不放
不可剥夺条件:进程以获得的资源,在没有使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源的关系
死锁的处理方式?
检测死锁并恢复。
仔细对资源进行动态分配,以避免死锁。
通过破坏死锁产生的四个必要条件之一,来防止死锁的产生。
鸵鸟算法忽略该问题。(鸵鸟算法,一种计算机操作系统算法,用于当死锁真正发生且影响系统正常运行时,手动干预—重新启动。)
---------------------
版权声明:本文为CSDN博主「zhaoxaun666」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhaoxaun666/article/details/81076790
F)线程的同步方法
一、同步方法
即有synchronized关键字修饰的方法。 由于java的每个对象都有一个内置锁,当用此关键字修饰方法时, 内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
注: synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类。
二、同步代码块
即有synchronized关键字修饰的语句块。 被该关键字修饰的语句块会自动被加上内置锁,从而实现同步
代码如:
synchronized(object){ }
三、wait与notify
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
notifyAll():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
五、使用重入锁实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。
ReenreantLock类的常用方法有:
ReentrantLock() : 创建一个ReentrantLock实例 lock() : 获得锁 unlock() : 释放锁
注:ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
六、使用局部变量实现线程同步
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
ThreadLocal 类的常用方法
ThreadLocal() : 创建一个线程本地变量 get() : 返回此线程局部变量的当前线程副本中的值 initialValue() : 返回此线程局部变量的当前线程的"初始值" set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
12、类加载的过程

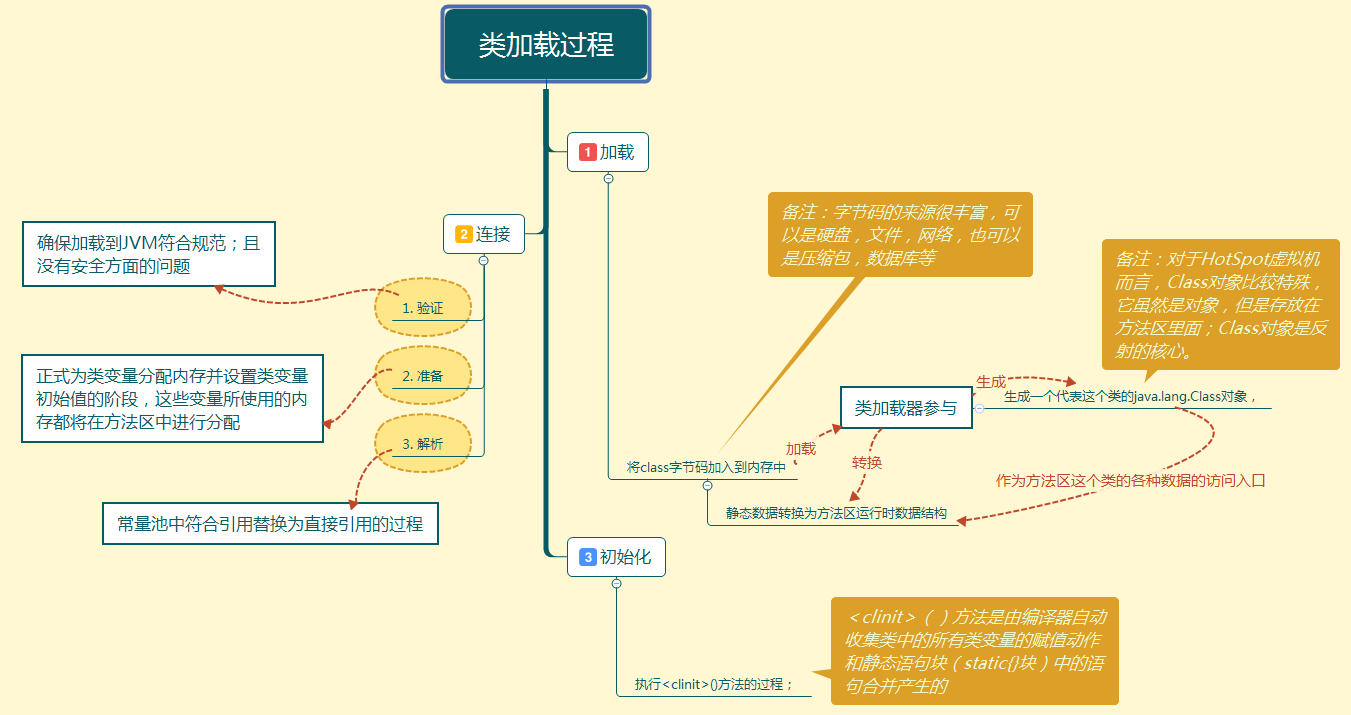
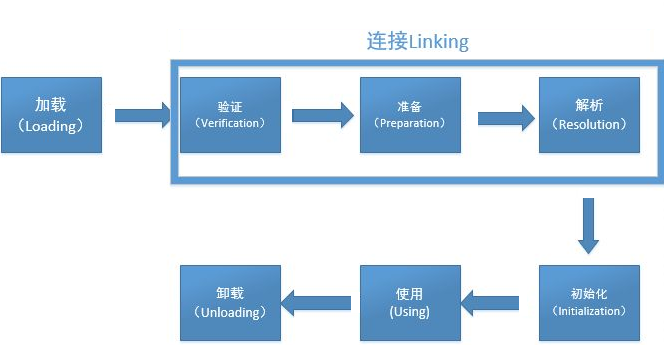
Java虚拟机中类加载的全过程,即 加载、验证、准备、解析和初始化
一个Java文件从编码完成到最终执行,一般主要包括两个过程
编译
运行
编译,即把我们写好的java文件,通过javac命令编译成字节码,也就是我们常说的.class文件。
运行,则是把编译声称的.class文件交给Java虚拟机(JVM)执行。
而我们所说的类加载过程即是指JVM虚拟机把.class文件中类信息加载进内存,并进行解析生成对应的class对象的过程。
举个通俗点的例子来说,JVM在执行某段代码时,遇到了class A, 然而此时内存中并没有class A的相关信息,于是JVM就会到相应的class文件中去寻找class A的类信息,并加载进内存中,这就是我们所说的类加载过程。
由此可见,JVM不是一开始就把所有的类都加载进内存中,而是只有第一次遇到某个需要运行的类时才会加载,且只加载一次。
类加载
类加载的过程主要分为三个部分:
加载
链接
初始化
而链接又可以细分为三个小部分:
验证
准备
解析
加载
简单来说,加载指的是把class字节码文件从各个来源通过类加载器装载入内存中。
这里有两个重点:
字节码来源。一般的加载来源包括从本地路径下编译生成的.class文件,从jar包中的.class文件,从远程网络,以及动态代理实时编译
类加载器。一般包括启动类加载器,扩展类加载器,应用类加载器,以及用户的自定义类加载器。
注:为什么会有自定义类加载器?
一方面是由于java代码很容易被反编译,如果需要对自己的代码加密的话,可以对编译后的代码进行加密,然后再通过实现自己的自定义类加载器进行解密,最后再加载。
另一方面也有可能从非标准的来源加载代码,比如从网络来源,那就需要自己实现一个类加载器,从指定源进行加载。
验证
主要是为了保证加载进来的字节流符合虚拟机规范,不会造成安全错误。
包括对于文件格式的验证,比如常量中是否有不被支持的常量?文件中是否有不规范的或者附加的其他信息?
对于元数据的验证,比如该类是否继承了被final修饰的类?类中的字段,方法是否与父类冲突?是否出现了不合理的重载?
对于字节码的验证,保证程序语义的合理性,比如要保证类型转换的合理性。
对于符号引用的验证,比如校验符号引用中通过全限定名是否能够找到对应的类?校验符号引用中的访问性(private,public等)是否可被当前类访问?
准备
主要是为类变量(注意,不是实例变量)分配内存,并且赋予初值。
特别需要注意,初值,不是代码中具体写的初始化的值,而是Java虚拟机根据不同变量类型的默认初始值。
比如8种基本类型的初值,默认为0;引用类型的初值则为null;常量的初值即为代码中设置的值,final static tmp = 456, 那么该阶段tmp的初值就是456
解析
将常量池内的符号引用替换为直接引用的过程。
两个重点:
符号引用。即一个字符串,但是这个字符串给出了一些能够唯一性识别一个方法,一个变量,一个类的相关信息。
直接引用。可以理解为一个内存地址,或者一个偏移量。比如类方法,类变量的直接引用是指向方法区的指针;而实例方法,实例变量的直接引用则是从实例的头指针开始算起到这个实例变量位置的偏移量
举个例子来说,现在调用方法hello(),这个方法的地址是1234567,那么hello就是符号引用,1234567就是直接引用。
在解析阶段,虚拟机会把所有的类名,方法名,字段名这些符号引用替换为具体的内存地址或偏移量,也就是直接引用。
初始化
这个阶段主要是对类变量初始化,是执行类构造器的过程。
换句话说,只对static修饰的变量或语句进行初始化。
如果初始化一个类的时候,其父类尚未初始化,则优先初始化其父类。
如果同时包含多个静态变量和静态代码块,则按照自上而下的顺序依次执行。
总结
类加载过程只是一个类生命周期的一部分,在其前,有编译的过程,只有对源代码编译之后,才能获得能够被虚拟机加载的字节码文件;在其后还有具体的类使用过程,当使用完成之后,还会在方法区垃圾回收的过程中进行卸载。如果想要了解Java类整个生命周期的话,可以自行上网查阅相关资料,这里不再多做赘述。
---------------------
版权声明:本文为CSDN博主「公众号-IT程序猿进化史」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ln152315/article/details/79223441
13、对象的创建
使用new关键字
通过new关键字直接在堆内存上创建对象,这样很方便的调用对象的有参和无参的构造函数.
Student stu1 = new Student("lihua");
1
Class反射调用
使用Java中反射特性,来进行对象的创建。使用Class类的newInstance方法可以调用无参的构造器来创建对象,如果是有参构造器,则需要使用Class的forName方法和Constructor来进行对象的创建。
1 Class stuClass = Class.forName("Student"); 2 Constructor constructor = stuClass.getConstructor(String.class); 3 Student stu2 = (Student) constructor.newInstance("李四"); 4 123
使用Clone方法
使用Clone的方法:无论何时我们调用一个对象的clone方法,JVM就会创建一个新的对象,将前面的对象的内容全部拷贝进去,用clone方法创建对象并不会调用任何构造函数。要使用clone方法,我们必须先实现Cloneable接口并实现其定义的clone方法。
1 try 2 { 3 Student stu3 = (Student) stu1.clone(); 4 System.out.println(stu3); 5 } 6 catch (CloneNotSupportedException e) 7 { 8 e.printStackTrace(); 9 } 10 123456789 11 12 13
使用序列化
一个对象实现了Serializable接口,就可以把对象写入到文件中,并通过读取文件来创建对象。
1 String path = Test.class.getClassLoader().getResource("").getPath(); 2 String objectFilePath = path + "out.txt"; 3 4 ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFilePath)); 5 objectOutputStream.writeObject(stu2); 6 7 ObjectInput objectInput = new ObjectInputStream(new FileInputStream(objectFilePath)); 8 Student stu4 = (Student) objectInput.readObject(); 9 12345678 10
示例代码
Student对象,实现Cloneable和Serializable接口
1 import java.io.Serializable; 2 3 /** 4 * Created by wzj on 2017/11/3. 5 */ 6 public class Student implements Cloneable,Serializable 7 { 8 private String name; 9 10 public Student(String name) 11 { 12 this.name = name; 13 } 14 15 /** 16 * @return a clone of this instance. 17 * @throws CloneNotSupportedException if the object's class does not 18 * support the {@code Cloneable} interface. Subclasses 19 * that override the {@code clone} method can also 20 * throw this exception to indicate that an instance cannot 21 * be cloned. 22 * @see Cloneable 23 */ 24 @Override 25 protected Object clone() throws CloneNotSupportedException 26 { 27 return super.clone(); 28 } 29 } 30 1234567891011121314151617181920212223242526272829 31 32 测试类 33 34 import java.io.*; 35 import java.lang.reflect.Constructor; 36 import java.lang.reflect.InvocationTargetException; 37 38 /** 39 * Created by wzj on 2017/11/2. 40 */ 41 public class Test 42 { 43 public static void main(String[] args) throws Exception 44 { 45 //1、第一种方式是通过new 46 Student stu1 = new Student("lihua"); 47 System.out.println(stu1); 48 49 //2、通过java反射,静态方式 50 Class stuClass = Class.forName("Student"); 51 Constructor constructor = stuClass.getConstructor(String.class); 52 Student stu2 = (Student) constructor.newInstance("李四"); 53 54 System.out.println(stu2); 55 56 //3、通过clone实现,必须实现Cloneable接口 57 try 58 { 59 Student stu3 = (Student) stu1.clone(); 60 System.out.println(stu3); 61 } 62 catch (CloneNotSupportedException e) 63 { 64 e.printStackTrace(); 65 } 66 67 //4、通过对象流,必须实现Serializable 68 String path = Test.class.getClassLoader().getResource("").getPath(); 69 String objectFilePath = path + "out.txt"; 70 71 ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFilePath)); 72 objectOutputStream.writeObject(stu2); 73 74 ObjectInput objectInput = new ObjectInputStream(new FileInputStream(objectFilePath)); 75 Student stu4 = (Student) objectInput.readObject(); 76 System.out.println(stu4); 77 } 78 79 80 } 81
---------------------
版权声明:本文为CSDN博主「dmfrm」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010889616/article/details/78946580
14.Java集合框架的基础接口有哪些?
总共有两大接口:Collection 和Map ,一个元素集合,一个是键值对集合; 其中List和Set接口继承了Collection接口,一个是有序元素集合,一个是无序元素集合; 而ArrayList和 LinkedList 实现了List接口,HashSet实现了Set接口,这几个都比较常用; HashMap 和HashTable实现了Map接口,并且HashTable是线程安全的,但是HashMap性能更好
15.HashMap和Hashtable有什么区别?
一、HashMap简介
HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
HashMap存数据的过程是:
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上是一个单向链表。当准备添加一个key-value对时,首先通过hash(key)方法计算hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,计算方法是先用hash&0x7FFFFFFF后,再对length取模,这就保证每一个key-value对都能存入HashMap中,当计算出的位置相同时,由于存入位置是一个链表,则把这个key-value对插入链表头。
HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。
了解了数据的存储,那么数据的读取也就很容易就明白了。
HashMap的存储结构,如下图所示:

图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
HashMap内存储数据的Entry数组默认是16,如果没有对Entry扩容机制的话,当存储的数据一多,Entry内部的链表会很长,这就失去了HashMap的存储意义了。所以HasnMap内部有自己的扩容机制。HashMap内部有:
变量size,它记录HashMap的底层数组中已用槽的数量;
变量threshold,它是HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
变量DEFAULT_LOAD_FACTOR = 0.75f,默认加载因子为0.75
HashMap扩容的条件是:当size大于threshold时,对HashMap进行扩容
扩容是是新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。 很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(从构造函数中可以看出,如果不指明,则默认为16),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。
下面说下加载因子,如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。
另外,无论我们指定的容量为多少,构造方法都会将实际容量设为不小于指定容量的2的次方的一个数,且最大值不能超过2的30次方
对HashMap想进一步深入了解的朋友推荐看一下HashMap源码剖析:http://blog.csdn.net/ns_code/article/details/36034955
二、Hashtable简介
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
Hashtable和HashMap比较相似,感兴趣的朋友可以看“Hashtable源码剖析”这篇博客:http://blog.csdn.net/ns_code/article/details/36191279
下面主要介绍一下HashTable和HashMap区别
三、HashTable和HashMap区别
1、继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
2、线程安全性不同
javadoc中关于hashmap的一段描述如下:此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的非同步访问,如下所示:
Map m = Collections.synchronizedMap(new HashMap(...));
Hashtable 线程安全很好理解,因为它每个方法中都加入了Synchronize。这里我们分析一下HashMap为什么是线程不安全的:
HashMap底层是一个Entry数组,当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。
我们来分析一下多线程访问:
(1)在hashmap做put操作的时候会调用下面方法:
1 [java] view plaincopy 2 1.// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。 3 2.void addEntry(int hash, K key, V value, int bucketIndex) { 4 3. // 保存“bucketIndex”位置的值到“e”中 5 4. Entry<K,V> e = table[bucketIndex]; 6 5. // 设置“bucketIndex”位置的元素为“新Entry”, 7 6. // 设置“e”为“新Entry的下一个节点” 8 7. table[bucketIndex] = new Entry<K,V>(hash, key, value, e); 9 8. // 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小 10 9.if (size++ >= threshold) 11 10. resize(2 * table.length); 12 11. } 13
在hashmap做put操作的时候会调用到以上的方法。现在假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失
( 2)删除键值对的代码
1 [java] view plaincopy 2 1.<span style="font-size: 18px;"> </span>// 删除“键为key”的元素 3 2.final Entry<K,V> removeEntryForKey(Object key) { 4 3. // 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算 5 4.int hash = (key == null) ? 0 : hash(key.hashCode()); 6 5. int i = indexFor(hash, table.length); 7 6. Entry<K,V> prev = table[i]; 8 7. Entry<K,V> e = prev; 9 8. // 删除链表中“键为key”的元素 10 9. // 本质是“删除单向链表中的节点” 11 10.while (e != null) { 12 11. Entry<K,V> next = e.next; 13 12. Object k; 14 13. if (e.hash == hash && 15 14. ((k = e.key) == key || (key != null && key.equals(k)))) { 16 15. modCount++; 17 16. size--; 18 17. if (prev == e) 19 18. table[i] = next; 20 19. else 21 20. prev.next = next; 22 21. e.recordRemoval(this); 23 22. return e; 24 23. } 25 24. prev = e; 26 25. e = next; 27 26. } 28 27. return e; 29 28. } 30
当多个线程同时操作同一个数组位置的时候,也都会先取得现在状态下该位置存储的头结点,然后各自去进行计算操作,之后再把结果写会到该数组位置去,其实写回的时候可能其他的线程已经就把这个位置给修改过了,就会覆盖其他线程的修改
(3)addEntry中当加入新的键值对后键值对总数量超过门限值的时候会调用一个resize操作,代码如下:
[java] view plaincopy 1.// 重新调整HashMap的大小,newCapacity是调整后的容量 2.void resize(int newCapacity) { 3. Entry[] oldTable = table; 4. int oldCapacity = oldTable.length; 5. //如果就容量已经达到了最大值,则不能再扩容,直接返回 6.if (oldCapacity == MAXIMUM_CAPACITY) { 7. threshold = Integer.MAX_VALUE; 8. return; 9. } 10. // 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中, 11. // 然后,将“新HashMap”赋值给“旧HashMap”。 12. Entry[] newTable = new Entry[newCapacity]; 13. transfer(newTable); 14. table = newTable; 15. threshold = (int)(newCapacity * loadFactor); 16. }
这个操作会新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。
当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
3、是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
我们看一下Hashtable的ContainsKey方法和ContainsValue的源码:
[java] view plaincopy 1.public boolean containsValue(Object value) { 2. return contains(value); 3. } [java] view plaincopy 1.// 判断Hashtable是否包含“值(value)” 2.public synchronized boolean contains(Object value) { 3. //注意,Hashtable中的value不能是null, 4. // 若是null的话,抛出异常! 5.if (value == null) { 6. throw new NullPointerException(); 7. } 8. // 从后向前遍历table数组中的元素(Entry) 9. // 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value 10. Entry tab[] = table; 11. for (int i = tab.length ; i-- > 0 ;) { 12. for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) { 13. if (e.value.equals(value)) { 14. return true; 15. } 16. } 17. } 18. return false; 19. }
[java] view plaincopy 1.// 判断Hashtable是否包含key 2. public synchronized boolean containsKey(Object key) { 3. Entry tab[] = table; 4./计算hash值,直接用key的hashCode代替 5.int hash = key.hashCode(); 6. // 计算在数组中的索引值 7.int index = (hash & 0x7FFFFFFF) % tab.length; 8. // 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素 9.for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { 10. if ((e.hash == hash) && e.key.equals(key)) { 11. return true; 12. } 13. } 14. return false; 15. }
下面我们看一下HashMap的ContainsKey方法和ContainsValue的源码:
[java] view plaincopy 1.// HashMap是否包含key 2. public boolean containsKey(Object key) { 3. return getEntry(key) != null; 4. }
[java] view plaincopy
// 返回“键为key”的键值对 2.final Entry<K,V> getEntry(Object key) { 3. // 获取哈希值 4. // HashMap将“key为null”的元素存储在table[0]位置,“key不为null”的则调用hash()计算哈希值 5.int hash = (key == null) ? 0 : hash(key.hashCode()); 6. // 在“该hash值对应的链表”上查找“键值等于key”的元素 7.for (Entry<K,V> e = table[indexFor(hash, table.length)]; 8. e != null; 9. e = e.next) { 10. Object k; 11. if (e.hash == hash && 12. ((k = e.key) == key || (key != null && key.equals(k)))) 13. return e; 14. } 15. return null; 16. }
[java] view plaincopy
// 是否包含“值为value”的元素 2.public boolean containsValue(Object value) { 3. // 若“value为null”,则调用containsNullValue()查找 4.if (value == null) 5. return containsNullValue(); 6. // 若“value不为null”,则查找HashMap中是否有值为value的节点。 7. Entry[] tab = table; 8. for (int i = 0; i < tab.length ; i++) 9. for (Entry e = tab[i] ; e != null ; e = e.next) 10. if (value.equals(e.value)) 11. return true; 12. return false; 13. }
通过上面源码的比较,我们可以得到第四个不同的地方
4、key和value是否允许null值
其中key和value都是对象,并且不能包含重复key,但可以包含重复的value。
通过上面的ContainsKey方法和ContainsValue的源码我们可以很明显的看出:
Hashtable中,key和value都不允许出现null值。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
5、两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
6、hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值。
Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
7、内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
16.String能被继承吗?为什么?
不能被继承,因为String类有final修饰符,而final修饰的类是不能被继承的。
Java对String类的定义:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { // 省略... }
final修饰符的用法:
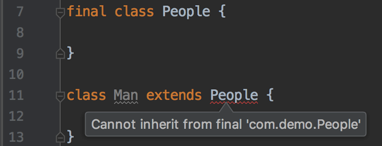
1.修饰类
当用final修饰一个类时,表明这个类不能被继承。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。
2.修饰方法
使用final修饰方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。
因此,只有在想明确禁止该方法在子类中被覆盖的情况下才将方法设置为final。
注:一个类中的private方法会隐式地被指定为final方法。
3.修饰变量
对于被final修饰的变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。虽然不能再指向其他对象,但是它指向的对象的内容是可变的。
final和static的区别:
很多时候会容易把static和final关键字混淆,static作用于成员变量用来表示只保存一份副本,而final的作用是用来保证变量不可变。看下面这个例子:
1 public class Demo1 { 2 public static void main(String[] args) { 3 MyClass myClass1 = new MyClass(); 4 MyClass myClass2 = new MyClass(); 5 System.out.println(myClass1.i); 6 System.out.println(myClass2.i); 7 System.out.println(myClass1.j); 8 System.out.println(myClass2.j); 9 10 } 11 } 12 13 class MyClass { 14 public final double i = Math.random(); 15 public static double j = Math.random(); 16 }
运行结果:
0.3222977275463088 0.2565532218939688 0.36856868882926397 0.36856868882926397
每次打印的两个j值都是一样的,而i的值却是不同的。从这里就可以知道final和static变量的区别了。
17.ArrayList 和 LinkedList 有什么区别。
ArrayList和LinkedList都实现了List接口,他们有以下的不同点:
ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
也可以参考ArrayList vs. LinkedList。
1) 因为 Array 是基于索引 (index) 的数据结构,它使用索引在数组中搜索和读取数据是很快的。 Array 获取数据的时间复杂度是 O(1), 但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。
2) 相对于 ArrayList , LinkedList 插入是更快的。因为 LinkedList 不像 ArrayList 一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是 ArrayList 最坏的一种情况,时间复杂度是 O(n) ,而 LinkedList 中插入或删除的时间复杂度仅为 O(1) 。 ArrayList 在插入数据时还需要更新索引(除了插入数组的尾部)。
3) 类似于插入数据,删除数据时, LinkedList 也优于 ArrayList 。
4) LinkedList 需要更多的内存,因为 ArrayList 的每个索引的位置是实际的数据,而 LinkedList 中的每个节点中存储的是实际的数据和前后节点的位置 ( 一个 LinkedList 实例存储了两个值: Node<E> first 和 Node<E> last 分别表示链表的其实节点和尾节点,每个 Node 实例存储了三个值: E item,Node next,Node pre) 。
什么场景下更适宜使用 LinkedList,而不用ArrayList
1) 你的应用不会随机访问数据 。因为如果你需要LinkedList中的第n个元素的时候,你需要从第一个元素顺序数到第n个数据,然后读取数据。
2) 你的应用更多的插入和删除元素,更少的读取数据 。因为插入和删除元素不涉及重排数据,所以它要比ArrayList要快。
换句话说,ArrayList的实现用的是数组,LinkedList是基于链表,ArrayList适合查找,LinkedList适合增删
以上就是关于 ArrayList和LinkedList的差别。你需要一个不同步的基于索引的数据访问时,请尽量使用ArrayList。ArrayList很快,也很容易使用。但是要记得要给定一个合适的初始大小,尽可能的减少更改数组的大小。
18.抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。
类可以继承多个类吗
类不能继承多个类
接口可以继承多个接口吗
接口可以继承多个接口
类可以实现多个接口吗
类可以实现多个接口
抽象类
1.抽象类中可以构造方法
2.抽象类中可以存在普通属性,方法,静态属性和方法。
3.抽象类中可以存在抽象方法。
4.如果一个类中有一个抽象方法,那么当前类一定是抽象类;抽象类中不一定有抽象方法。
5.抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
接口
1.在接口中只有方法的声明,没有方法体。 (Java8 接口可以有实例方法)
2.在接口中只有常量,因为定义的变量,在编译的时候都会默认加上 public static final (必须被初始化,不能改变)
3.在接口中的方法,永远都被public来修饰(只能)。
4.接口中没有构造方法,也不能实例化接口的对象。
5.接口可以实现多继承
6.接口中定义的方法都需要有实现类来实现,如果实现类不能实现接口中的所有方法则实现类定义为抽象类。
PS.
1、静态方法不能被重写,不能被抽象
本地方法是本地代码实现的方法,不能是抽象
synchronize与方法的实现细节有关,抽象方法不能被synchronize修饰
2、抽象类中可以定义一些子类的公共方法,子类只需要增加新的功能,不需要重复写已经存在的方法;
而接口中只是对方法的申明和常量的定义。
区别总结:
类可以实现很多个接口,但是只能继承一个抽象类
接口中所有的方法隐含的都是抽象的。而抽象类则可以同时包含抽象和非抽象的方法。(Java8 接口可以有实例方法 需要关键字default)
Java接口中声明的变量默认是public static final(必须赋初始值)。抽象类可以包含非final的变量。
Java接口中的成员函数默认是public abstract的。抽象类的成员函数可以是private,protected或者是public。
接口可继承接口,不能继承类(抽象类和普通类) 抽象类可继承接口也可继承具体类(继承接口时可只实现部分方法)
非抽象类如果要实现一个接口,它必须要实现接口声明的所有方法。类可以不实现抽象类或接口声明的所有方法,当然,在这种情况下,类也必须得声明成是抽象的。
接口是绝对抽象的,不可以被实例化。抽象类也不可以被实例化,但是,如果它包含main方法的话是可以被调用的。
从设计角度来看抽象类和接口:
1、抽象类就是is a,是实例必须要有的,比如Door 必须有开和关。
而接口就是has a,可以有也可以没有,比如Door可以有报警器,但是报警器不是门必须有的,是可扩展的行为。
2、抽象类强调的是同类事物的抽象,接口强调的是同类方法的抽象。
类可以继承多个类么?
不能。
一个类不能直接继承多个类,java是单继承语言。
比如说这样:class A extends B,C 不能这样写,因为java不支持多继承。
但是可以像下面这样实现继承多个类:class A extends B,class C extends A,这样C就同时继承了B和A两个类了。
19.String类的常用方法有那些?
charAt:返回指定索引处的字符
indexOf():返回指定字符的索引
replace():字符串替换
trim():去除字符串两端空白
split():分割字符串,返回一个分割后的字符串数组
getBytes():返回字符串的byte类型数组
length():返回字符串长度
toLowerCase():将字符串转成小写字母
toUpperCase():将字符串转成大写字符
substring():截取字符串
format():格式化字符串
equals():字符串比较
20.String str=”aaa”,与String str=new String(“aaa”)一样吗?
不一样的。因为内存分配的方式不一样。
第一种,创建的”aaa”是常量,jvm都将其分配在常量池中。
第二种创建的是一个对象,jvm将其值分配在堆内存中。
21.Final在java中的作用
Final可以修饰类,修饰方法,修饰变量。
修饰的类叫最终类。该类不能被继承。
修饰的方法不能被重写。
修饰的变量叫常量,常量必须初始化,一旦初始化后,常量的值不能发生改变。
22.Static关键字有什么作用?
Static可以修饰内部类、方法、变量、代码块
Static修饰的类是静态内部类
Static修饰的方法是静态方法,表示该方法属于当前类的,而不属于某个对象的,静态方法也不能被重写,可以直接使用类名来调用。在static方法中不能使用this或者super关键字。
Static修饰变量是静态变量或者叫类变量,静态变量被所有实例所共享,不会依赖于对象。静态变量在内存中只有一份拷贝,在JVM加载类的时候,只为静态分配一次内存。
Static修饰的代码块叫静态代码块,通常用来做程序优化的。静态代码块中的代码在整个类加载的时候只会执行一次。静态代码块可以有多个,如果有多个,按照先后顺序依次执行。
23.内部类与静态内部类的区别?
静态内部类相对与外部类是独立存在的,在静态内部类中无法直接访问外部类中变量、方法。如果要访问的话,必须要new一个外部类的对象,使用new出来的对象来访问。但是可以直接访问静态的变量、调用静态的方法;
普通内部类作为外部类一个成员而存在,在普通内部类中可以直接访问外部类属性,调用外部类的方法。
如果外部类要访问内部类的属性或者调用内部类的方法,必须要创建一个内部类的对象,使用该对象访问属性或者调用方法。
如果其他的类要访问普通内部类的属性或者调用普通内部类的方法,必须要在外部类中创建一个普通内部类的对象作为一个属性,外同类可以通过该属性调用普通内部类的方法或者访问普通内部类的属性
如果其他的类要访问静态内部类的属性或者调用静态内部类的方法,直接创建一个静态内部类对象即可。
24.Java常用包有那些?
Java.lang
Java.io
Java.sql
Java.util
Java.awt
Java.math
25.Object类常用方法有那些?
Equals
Hashcode
toString
wait
notify
clone
getClass
26.一个java类中包含那些内容?
属性、方法、内部类、构造方法、代码块。
27.什么是JVM?java虚拟机包括什么?
JVM:java虚拟机,运用硬件或软件手段实现的虚拟的计算机,Java虚拟机包括:寄存器,堆栈,处理器
28.Java的数据结构有那些?
线性表(ArrayList)
链表(LinkedList)
栈(Stack)
队列(Queue)
图(Map)
树(Tree)
29.Char类型能不能转成int类型?能不能转化成string类型,能不能转成double类型
Char在java中也是比较特殊的类型,它的int值从1开始,一共有2的16次方个数据;Char<int<long<float<double;Char类型可以隐式转成int,double类型,但是不能隐式转换成string;如果char类型转成byte,short类型的时候,需要强转。
30.什么是拆装箱?
拆箱:把包装类型转成基本数据类型?????
装箱:把基本数据类型转成包装类型?????
31、"=="和 equals 方法究竟有什么区别?
==操作符专门用来比较两个变量的值是否相等,也就是用于比较变量所对应的内存中所存 储的数值是否相同,要比较两个基本类型的数据或两个引用变量是否相等,只能用==操作符。
equals 方法是用于比较两个独立对象的内容是否相同
32、静态变量和实例变量的区别?
在语法定义上的区别:静态变量前要加 static 关键字,而实例变量前则不加。
在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量。
静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以被使用了。总之,实例变量必须创建对象后才可以通过这个对象 来使用,静态变量则可以直接使用类名来引用。
33、是否可以从一个 static 方法内部发出对非 static方法的调用?
不可以。因为非 static 方法是要与对象关联在一起的,必须创建一个对象后,才可以在该对 象上进行方法调用,而 static 方法调用时不需要创建对象,可以直接调用。也就是说,当一 个 static 方法被调用时,可能还没有创建任何实例对象,如果从一个 static 方法中发出对非 static 方法的调用,那个非 static 方法是关联到哪个对象上的呢?这个逻辑无法成立,所以, 一个 static 方法内部发出对非 static 方法的调用。
34、Integer 与 int 的区别
int是java提供的8种原始数据类型之一。Java为每个原始类型提供了封装类,Integer是java 为 int 提供的封装类。int 的默认值为0,而 Integer的默认值为 null,即 Integer 可以区分出 未赋值和值为0的区别,int 则无法表达出未赋值的情况
35、请说出作用域 public,private,protected,以及不写时的区别
作用域 当前类 同一包(package) 子孙类 其他包(package
(
19、构造器 Constructor 是否可被 override?
构造器 Constructor
不能被继承,因此不能重写 Override ,但可以被重载 Overload 。)
36、接口是否可继承接口?抽象类是否可实现(implements)接口?抽象类是否可 继承具体类(concrete class)?抽象类中是否可以有静态的 main方法?
接口可以继承接口。抽象类可以实现(implements)接口,抽象类可以继承具体类。抽象类中 可以有静态的 main 方法。
37、java 中实现多态的机制是什么?
靠的是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象,而程序调用的方
法在运行期才动态绑定,就是引用变量所指向的具体实例对象的方法,也就是内存里正在运 行的那个对象的方法,而不是引用变量的类型中定义的方法。
38、abstract class和 interface 有什么区别?
含有 abstract 修饰符的 class 即为抽象类,abstract 类不能创建的实例对象。含有 abstract 方法的类必须定义为abstract class,abstract class类中的方法不必是抽象的。
abstract class类中定义抽象方法必须在具体(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静 态方法。如果的子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义为 abstract 类型。 接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口 中的方法定义默认为 public abstract类型,接口中的成员变量类型默认为 public static final。
下面比较一下两者的语法区别:
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象 的普通方法。
4. 抽象类中的抽象方法的访问类型可以是 public,protected 和(默认类型,虽然 eclipse 下不报错,但应该也不行),但接口中的抽象方法只能是 public 类型的,并且默认即 为 public abstract 类型。
5. 抽象类中可以包含静态方法,接口中不能包含静态方法
6. 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任 意,但接口中定义的变量只能是 public static final 类型,并且默认即为 public static final 类 型。
7. 一个类可以实现多个接口,但只能继承一个抽象类。
39、数组有没有 length()这个方法? String有没有 length()这个方法?
数组没有 length()这个方法,有 length 的属性。String 有有 length()这个方法。
40、请写出你最常见到的 几个 runtime exception。
NullPointerException、ArrayIndexOutOfBoundsException、 ClassCastException。
41、JAVA 语言如何进行异常处理,关键字:throws,throw,try,catch,finally分 别代表什么意义?在 try块中可以抛出异常吗?
throws 捕获并向外抛出异常 throw抛出异常 try catch 是内部捕获异常并做自定义处理 finally 是无论是否有异常都会被处理的语句,除非在 finally 前存在被执行的 System.exit(int i)时除外
42、多线程有几种实现方法?用什么关键字修饰同步方法?
有两种实现方法,分别是继承 Thread 类与实现 Runnable 接口
43、List 和 Map 区别?
一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List 中存储的数 据是有顺序,并且允许重复;Map 中存储的数据是没有顺序的,其键是不能重复的,它的 值是可以有重复的。
44、说出一些常用的类,包,接口,请各举 5 个
常用的类:BufferedReader BufferedWriter FileReader FileWirter String Integer java.util.Date,System,Class,List,HashMap
常用的包:java.lang java.io java.util java.sql,javax.servlet,org.apache.strtuts.action,org.hibernate
常用的接口:Remote List Map Document NodeList,Servlet,HttpServletRequest,HttpServletResponse,Transaction(Hibernate)、 Session(Hibernate),HttpSession
45、java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承, 请说出他们分别是哪些类?
字节流,字符流。字节流继承于 InputStream OutputStream,字符流继承于 InputStreamReaderOutputStreamWriter。在 java.io 包中还有许多其他的流,主要是为了提 高性能和使用方便。
46、描述一下 JVM加载 class文件的原理机制?
JVM中类的装载是由 ClassLoader 和它的子类来实现的,Java ClassLoader是一个重要的 Java 运行时系统组件。它负责在运行时查找和装入类文件的类。
47、说一说 Servlet的生命周期?
servlet 有良好的生存期的定义,包括加载和实例化、初始化、处理请求以及服务结束。 这个生存期由 javax.servlet.Servlet 接口的 init,service 和 destroy 方法表达。 Servlet 被服务器实例化后,容器运行其 init 方法,请求到达时运行其 service 方法,service 方法自动派遣运行与请求对应的 doXXX 方法(doGet,doPost)等,当服务器决定将实例 销毁的时候调用其 destroy 方法。 web 容器加载 servlet,生命周期开始。通过调用 servlet 的 init()方法进行 servlet 的初始化。 通过调用 service()方法实现,根据请求的不同调用不同的 do***()方法。结束服务,web 容 器调用 servlet的 destroy()方法。
48、什么情况下调用 doGet()和 doPost()?
Jsp页面中的FORM标签里的method属性为get时调用doGet(),为 post时调用doPost()。
49、forward 和 redirect的区别
forward 是服务器请求资源,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读 取过来,然后把这些内容再发给浏览器,浏览器根本不知道服务器发送的内容是从哪儿来的, 所以它的地址栏中还是原来的地址。
redirect 就是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,一般来 说浏览器会用刚才请求的所有参数重新请求,所以 session,request参数都可以获取。
50、页面间对象传递的方法
request,session,application,cookie 等
51、MVC的各个部分都有那些技术来实现?如何实现?
MVC 是 Model-View-Controller的简写。Model 代表的是应用的业务逻辑(通过 JavaBean,EJB 组件实现),View 是应用的表示面(由 JSP 页面产生),Controller是提供 应用的处理过程控制(一般是一个 Servlet),通过这种设计模型把应用逻辑,处理过程和显 示逻辑分成不同的组件实现。这些组件可以进行交互和重用。
52、数据库三范式是什么?
第一范式(1NF):字段具有原子性,不可再分。
第二范式(2NF):要求实体的属性完全依赖于主关键字。
第三范式(3NF):属性值不可传递
53、Java 中的23种设计模式:
Factory(工厂模式), Builder(建造模式), Factory Method(工厂方法模式),
Prototype(原始模型模式),Singleton(单例模式), Facade(门面模式), Adapter(适配器模式), Bridge(桥梁模式), Composite(合成模式),
Decorator(装饰模式), Flyweight(享元模式), Proxy(代理模式), Command(命令模式), Interpreter(解释器模式), Visitor(访问者模式), Iterator(迭代子模式), Mediator(调停者模式), Memento(备忘录模式), Observer(观察者模式), State(状态模式), Strategy(策略模式), Template Method(模板方法模式), Chain Of Responsibleity(责任链模式)
54、页面之间传递参数的几种方法
1:通过URL链接地址传递
2:通过post方式
3:通过session
4: 通过Application
5:通过Servlet.Transfer
55、Java集合类框架的基本接口有哪些?
Java集合类提供了一套设计良好的支持对一组对象进行操作的接口和类。Java集合类里面最基本的接口有:
Collection:代表一组对象,每一个对象都是它的子元素。
Set:不包含重复元素的Collection。
List:有顺序的collection,并且可以包含重复元素。
Map:可以把键(key)映射到值(value)的对象,键不能重复
56、spring注入方法:
属性注入(set方法) 构造注入(无参构造) P标签注入
57、主要学习的框架是什么?并说下spring有哪几种注入方式。
1、学习框架有struts、hibernate、Mybatis、spring
补充:
1.什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”?
Java虚拟机是一个可以执行Java字节码的虚拟机进程。Java源文件被编译成能被Java虚拟机执行的字节码文件。
Java被设计成允许应用程序可以运行在任意的平台,而不需要程序员为每一个平台单独重写或者是重新编译。Java虚拟机让这个变为可能,因为它知道底层硬件平台的指令长度和其他特性。
2.JDK、JRE、JVM关系是什么?
JDK(Java Development Kit)即为Java开发工具包,包含编写Java程序所必须的编译、运行等开发工具以及JRE。开发工具如:用于编译java程序的javac命令、用于启动JVM运行java程序的java命令、用于生成文档的javadoc命令以及用于打包的jar命令等等。
JRE(Java Runtime Environment)即为Java运行环境,提供了运行Java应用程序所必须的软件环境,包含有Java虚拟机(JVM)和丰富的系统类库。系统类库即为java提前封装好的功能类,只需拿来直接使用即可,可以大大的提高开发效率。
JVM(Java Virtual Machines)即为Java虚拟机,提供了字节码文件(.class)的运行环境支持。
简单说,就是JDK包含JRE包含JVM。
3.Java支持的数据类型有哪些?什么是自动拆装箱?
基本数据类型:
整数值型:byte,short,int,long,
字符型:char
浮点类型:float,double
布尔型:boolean
整数默认int型,小数默认是double型。Float和long类型的必须加后缀。
首先知道String是引用类型不是基本类型,引用类型声明的变量是指该变量在内存中实际存储的是一个引用地址,实体在堆中。引用类型包括类、接口、数组等。String类还是final修饰的。
而包装类就属于引用类型,自动装箱和拆箱就是基本类型和引用类型之间的转换,至于为什么要转换,因为基本类型转换为引用类型后,就可以new对象,从而调用包装类中封装好的方法进行基本类型之间的转换或者toString(当然用类名直接调用也可以,便于一眼看出该方法是静态的),还有就是如果集合中想存放基本类型,泛型的限定类型只能是对应的包装类型。
5.面向对象是什么?
面向对象是一种思想,世间万物都可以看做一个对象,这里只讨论面向对象编程(OOP),Java是一个支持并发、基于类和面向对象的计算机编程语言,面向对象软件开发的优点:
代码开发模块化,更易维护和修改;
代码复用性强;
增强代码的可靠性和灵活性;
增加代码的可读性。
面向对象的四大基本特性:
抽象:提取现实世界中某事物的关键特性,为该事物构建模型的过程。对同一事物在不同的需求下,需要提取的特性可能不一样。得到的抽象模型中一般包含:属性(数据)和操作(行为)。这个抽象模型我们称之为类。对类进行实例化得到对象。
封装:封装可以使类具有独立性和隔离性;保证类的高内聚。只暴露给类外部或者子类必须的属性和操作。类封装的实现依赖类的修饰符(public、protected和private等)
继承:对现有类的一种复用机制。一个类如果继承现有的类,则这个类将拥有被继承类的所有非私有特性(属性和操作)。这里指的继承包含:类的继承和接口的实现。
多态:多态是在继承的基础上实现的。多态的三个要素:继承、重写和父类引用指向子类对象。父类引用指向不同的子类对象时,调用相同的方法,呈现出不同的行为;就是类多态特性。多态可以分成编译时多态和运行时多态。
8.什么是值传递和引用传递?
值传递是对基本型变量而言的,传递的是该变量的一个副本,改变副本不影响原变量.
引用传递一般是对于对象型变量而言的,传递的是该对象地址的一个副本, 并不是原对象本身 。
一般认为,java内的传递都是值传递. java中实例对象的传递是引用传递 。
10.Java中的方法覆盖(Overriding)和方法重载(Overloading)是什么意思?
Java中的方法重载发生在同一个类里面两个或者是多个方法的方法名相同但是参数不同的情况。与此相对,方法覆盖是说子类重新定义了父类的方法。方法覆盖必须有相同的方法名,参数列表和返回类型。覆盖者可能不会限制它所覆盖的方法的访问。
11.Java中,什么是构造方法?什么是构造方法重载?什么是复制构造方法?
当新对象被创建的时候,构造方法会被调用。每一个类都有构造方法。在程序员没有给类提供构造方法的情况下,Java编译器会为这个类创建一个默认的构造方法。
Java中构造方法重载和方法重载很相似。可以为一个类创建多个构造方法。每一个构造方法必须有它自己唯一的参数列表。
12.Java支持多继承么?
Java中类不支持多继承,只支持单继承(即一个类只有一个父类)。 但是java中的接口支持多继承,,即一个子接口可以有多个父接口。(接口的作用是用来扩展对象的功能,一个子接口继承多个父接口,说明子接口扩展了多个功能,当类实现接口时,类就扩展了相应的功能)。
17.String和StringBuilder、StringBuffer的区别?
Java平台提供了两种类型的字符串:String和StringBuffer/StringBuilder,它们可以储存和操作字符串。其中String是只读字符串,也就意味着String引用的字符串内容是不能被改变的。而StringBuffer/StringBuilder类表示的字符串对象可以直接进行修改。StringBuilder是Java 5中引入的,它和StringBuffer的方法完全相同,区别在于它是在单线程环境下使用的,因为它的所有方面都没有被synchronized修饰,因此它的效率也比StringBuffer要高。
10、内部类与外部类的调用
a) 内部类可以直接调用外部类包括private的成员变量,使用外部类引用的this.关键字调用即可
b) 而外部类调用内部类需要建立内部类对象
11、多线程
a)一个进程是一个独立的运行环境,可以看做是一个程序,而线程可以看做是进程的一个任务,比如QQ是一个进程,而一个QQ窗口是一个线程。
b)在多线程程序中,多线程并发可以提高程序的效率,cpu不会因为某个线程等待资源而进入空闲状态,它会把资源让给其他的线程。
c)用户线程就是我们开发程序是创建的线程,而守护线程为系统线程,如JVM虚拟中的GC
d)线程的优先级别:每一个线程都有优先级别,有限级别高的可以先获取CPU资源使该线程从就绪状态转为运行状态。也可以自定义线程的有限级别
e)死锁:至少两个以上线程争取两个以上cpu资源,避免死锁就避免使用嵌套锁,只需要在他们需要同步的地方加锁和避免无限等待
23、类加载的过程
a) 遇到一个新的类时,首先会到方法区去找class文件,如果没有找到就会去硬盘中找class文件,找到后会返回,将class文件加载到方法区中,在类加载的时候,静态成员变量会被分配到方法区的静态区域,非静态成员变量分配到非静态区域,然后开始给静态成员变量初始化,赋默认值,赋完默认值后,会根据静态成员变量书写的位置赋显示值,然后执行静态代码。当所有的静态代码执行完,类加载才算完成。
24、对象的创建
a) 遇到一个新类时,会进行类的加载,定位到class文件
b) 对所有静态成员变量初始化,静态代码块也会执行,而且只在类加载的时候执行一次
c) New 对象时,jvm会在堆中分配一个足够大的存储空间
d) 存储空间清空,为所有的变量赋默认值,所有的对象引用赋值为null
e) 根据书写的位置给字段一些初始化操作
f) 调用构造器方法(没有继承)
20.Java集合框架的基础接口有哪些?
Collection为集合层级的根接口。一个集合代表一组对象,这些对象即为它的元素。Java平台不提供这个接口任何直接的实现。## 标题 ##
Set是一个不能包含重复元素的集合。这个接口对数学集合抽象进行建模,被用来代表集合,就如一副牌。
List是一个有序集合,可以包含重复元素。你可以通过它的索引来访问任何元素。List更像长度动态变换的数组。
Map是一个将key映射到value的对象.一个Map不能包含重复的key:每个key最多只能映射一个value。
一些其它的接口有Queue、Dequeue、SortedSet、SortedMap和ListIterator。
30.HashMap和Hashtable有什么区别?
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高。
4、Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
一般现在不建议用HashTable, ①是HashTable是遗留类,内部实现很多没优化和冗余。②即使在多线程环境下,现在也有同步的ConcurrentHashMap替代,没有必要因为是多线程而用HashTable。
2.String能被继承吗?为什么?
不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,
3.ArrayList 和 LinkedList 有什么区别。
ArrayList和LinkedList都实现了List接口,有以下的不同点:
>1、ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
>2、相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
>3、LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
11.抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。
1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
2、抽象类要被子类继承,接口要被类实现。
3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
6、抽象方法只能申明,不能实现。abstract void abc();不能写成abstract void abc(){}。
7、抽象类里可以没有抽象方法
8、如果一个类里有抽象方法,那么这个类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的。
10、接口可继承接口,并可多继承接口,但类只能单根继承。
50.什么是重写?什么是重载?
重载和重写都是java多态的表现。
重载叫override,在同一个类中多态的表现。当一个类中出现了多个相同名称的方法,但参数个数和参数类型不同,方法重载与返回值无关
重写叫overwrite,是字符类中多态的表现。当子类出现与父类相同的方法,那么这就是方法重写。方法重写时,子类的返回值必须与父类的一致。如果父类方法抛出一个异常,子类重写的方法抛出的异常类型不能小于父类抛出的异常类型