MeayunDB(www.meayun.com)是一款分布式的NoSQL列式内存数据库,由C#编写,主要为高性能,高并发,高可伸缩及大数据系统提供技术解决方案。基于MeayunDB,可以简单,快速的构建应用,并可根据访问量和数据存储需要的增长轻松扩展。
- 列式存储
- 分布式,弹性扩展
- Map/Reduce并行计算
- 嵌入式开发(C#,Python)
- 移动计算
- JSON数据交互
- 无缝集成RDBMS
- 网站数据―社交网站,电子商务,生活服务,旅游订票等
- 缓存系统―由于性能很高,MeayunDB也适合作为信息基础设施的缓存层。
- 高可伸缩,高并发系统―交易软件,电信计费,铁路购票等
- 高性能,低延迟系统―实时行情,报表系统等
- 大数据实时分析统计―高频交易,日志分析,数据挖掘等
MeayunDB架构

MeayunDB部署
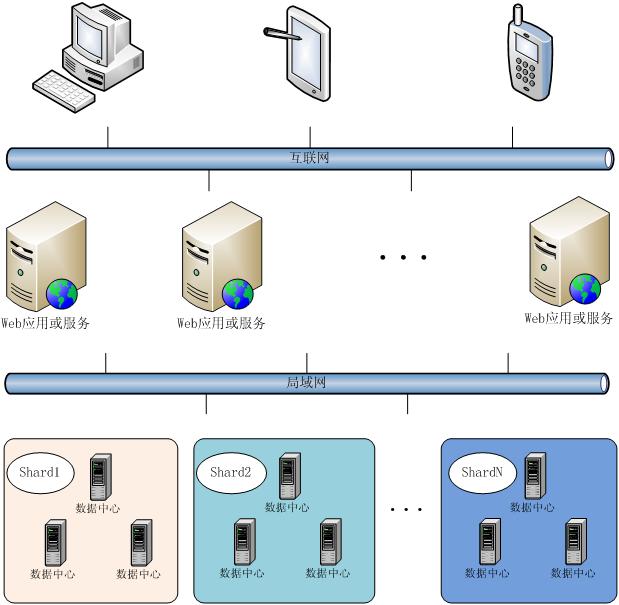
MeayunDB分布式集群由N>=1个MeayunDB子集群构成,每个子集群上的应用是完全相同的,唯一不相同的是每个MeayunDB子集群存储的数据是不相同的。您的所有数据是分布存储到每个子集群中的,每个子集群仅存储了您的数据的一部分。
MeayunDB子集群中MeayunDB实例数需要>=1(具体实例数由用户确定),同一个子集群中的MeayunDB实例数据是完全相同的,对外提供相同的业务应用,同一个子集群中的MeayunDB实例是互为对方的数据备份,可以以增加MeayunDB实例的方式,增加数据备份数。
MeayunDB没有采用主从架构,不存在单点故障问题,随着业务的扩展,可以线性增加子集群数,提高吞吐量,轻松应对上亿行级数据的存储和实时分析处理。
MapReduce流程

用户向MeayunDB集群提交任务后,集群会分解用户任务,并调度集群内MeayunDB实例,并行处理用户任务,最终合并任务结果,合并后的结果可作为下一轮并行计算的输入。
MeayunDB移动计算,而不移动数据,减少客户端/服务器进程间通信开销,并且在内存中进行数据计算,尽可能地提高了系统性能。
MeayunDB性能
本次测试使用的软硬件环境:
硬件配置:Intel(R) Xeon(R) CPUE5-2609 @ 2.40GHz,8核8线程,内存32GB
操作系统:Windows Server 2008 R2 Enterprise
数据表结构:

1. 查询测试:
|
MeayunDB实例 |
记录数(行) |
耗时(毫秒) |
|
单线程查询实例1 |
10000000 |
1641 |
|
单线程查询实例2 |
10000000 |
1590 |
|
单线程查询实例3 |
10000000 |
1246 |
|
单线程查询实例4 |
10000000 |
1593 |
|
单线程查询实例5 |
10000000 |
1484 |
|
单线程查询实例6 |
10000000 |
1694 |
|
单线程查询实例7 |
10000000 |
1376 |
|
单线程查询实例8 |
10000000 |
1581 |
|
8000万数据对double数据列F5求和的耗时 |
2307 |
|
|
查询每条记录的耗时 |
0.0288375微秒 |
|
|
每秒吞吐率(行/s) |
34677070行 |
|
2. 插入测试:
|
MeayunDB实例 |
记录数(行) |
耗时(毫秒) |
|
单线程插入实例1 |
10000000 |
59814 |
|
插入每条记录的耗时 |
5.9814微秒 |
|
|
每秒吞吐率(行/s) |
167184.93行 |
|
MeayunDB价值分析
- 开发简单,快捷,技术要求低,对开发人员友好
- 高可伸缩性,按需弹性扩展
- 降低人的因素影响,降低项目风险,易于项目管理
- 低延迟,高并发,微秒级数据存取效率。
- 大数据存储和实时并行计算
- 管理,开发,维护成本降低50-80%
- 工作效率2-4倍的提升
- 性能10-100倍的提升
QQ交流群:301165454