把网站装进爬虫里,分为几步:
- 新建项目 (Project):新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
1.新建项目(Project)
在空目录下按住Shift键右击,选择“在此处打开命令窗口”,输入一下命令:
>scrapy startproject douban
创建project完成后,生成如下目录:
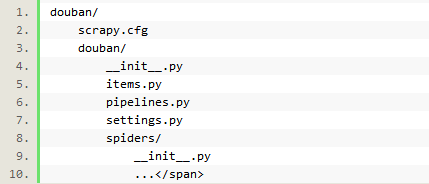
用pycharm打开该项目,具体看一下:
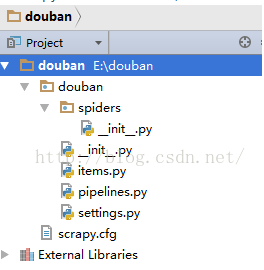
各个文件的作用:
- scrapy.cfg:项目的配置文件
- douban/:项目的Python模块,将会从这里引用代码
- douban/items.py:项目的items文件(items是用来加载抓取内容的容器)
- douban/pipelines.py:项目的pipelines文件
- douban/settings.py:项目的设置文件
- douban/spiders/:存储爬虫的目录
2.明确目标(Item)
item可以用scrapy.item.Item类来创建,并且用scrapy.item.Field对象来定义属性。
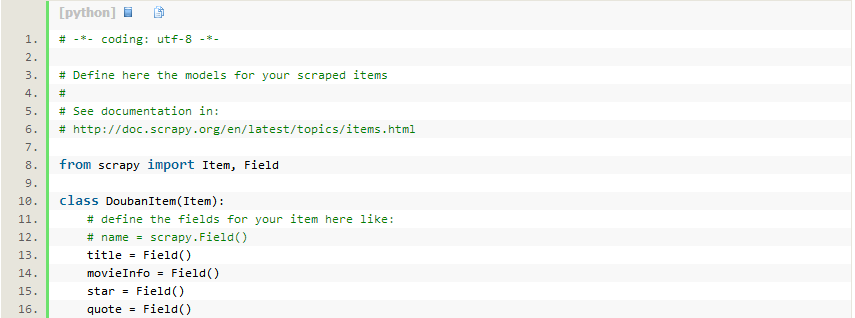
接下来,我们开始来构建item模型(model)。本例中,构建items.py如下:
首先,我们想要的内容有:
- 电影名称(name)
- 电影描述(movieInfo)
- 电影评分(star)
- 格言(quote)
- 对应地,修改douban目录下的items.py文件,在原本的class后面添加我们自己的class。因为要抓豆瓣网站的内容,所以我们可以将其命名为DoubanItem:
【attention】:
爬取元素并不是必须声明一个model,也可以直接在爬虫代码中,将爬取的元素直接通过这种方式来展现

根据官方文档介绍,Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便,Item提供了类字典的API,并且可以很方便的声明字段,很多Scrapy组件可以利用Item的其他信息。后面也可以方便pipelines对爬到的数据进行处理。
3.制作爬虫(Spider)
制作爬虫,总体分两步:爬——取
也就是说,首先你要获取整个网页的所有内容,然后再取出其中对你有用的部分。
3.1爬
Spider是用户自己编写的类,用来从一个域(或域组)中抓取信息。定义了用于下载的URL列表、跟踪链接的方案、解析网页内容的方式,以此来提取items。
要建立一个Spider,你必须用scrapy.spider.BaseSpider创建一个子类,并确定三个强制的属性:
- name:爬虫的识别名称,必须是唯一的,不同的爬虫中必须定义不同的名字
- start_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成
- parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL。
下面我们来写第一只爬虫,命名为doubanspider.py,保存在doubanspiders目录下。
在douban目录下按住shift右击,在此处打开命令窗口,输入:
>scrapy crawl douban
3.1.1 创建main.py,保存在douban目录下

3.1.2 为免于被封,需要伪装一下,在settings.py里加上USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
3.2取
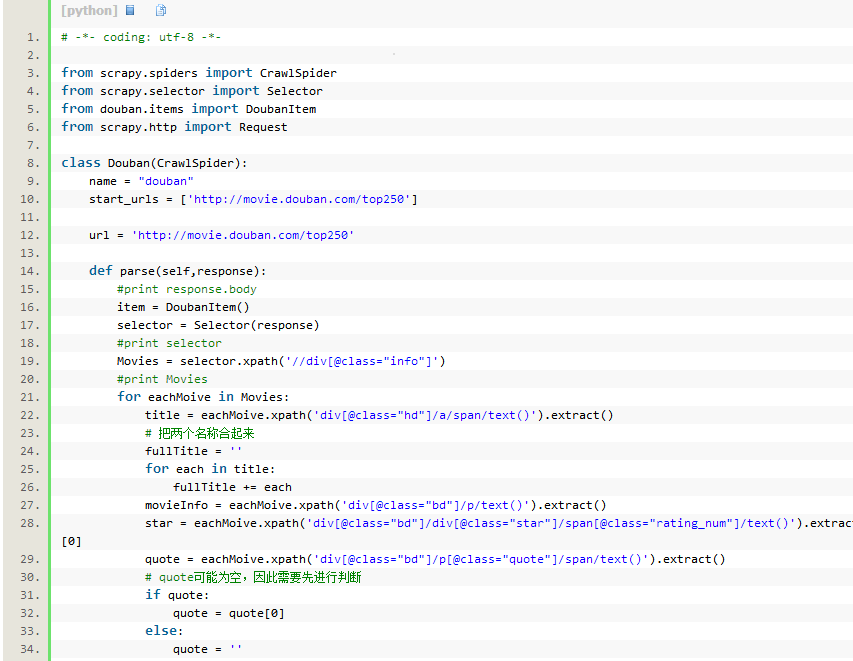
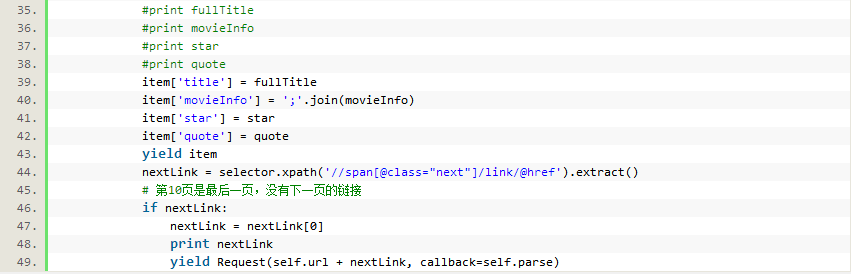
- # -*- coding: utf-8 -*-
- from scrapy.spiders import CrawlSpider
- from scrapy.selector import Selector
- from douban.items import DoubanItem
- from scrapy.http import Request
- class Douban(CrawlSpider):
- name = "douban"
- start_urls = ['http://movie.douban.com/top250']
- url = 'http://movie.douban.com/top250'
- def parse(self,response):
- #print response.body
- item = DoubanItem()
- selector = Selector(response)
- #print selector
- Movies = selector.xpath('//div[@class="info"]')
- #print Movies
- for eachMoive in Movies:
- title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
- # 把两个名称合起来
- fullTitle = ''
- for each in title:
- fullTitle += each
- movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
- star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
- quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
- # quote可能为空,因此需要先进行判断
- if quote:
- quote = quote[0]
- else:
- quote = ''
- #print fullTitle
- #print movieInfo
- #print star
- #print quote
- item['title'] = fullTitle
- item['movieInfo'] = ';'.join(movieInfo)
- item['star'] = star
- item['quote'] = quote
- yield item
- nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
- # 第10页是最后一页,没有下一页的链接
- if nextLink:
- nextLink = nextLink[0]
- print nextLink
- yield Request(self.url + nextLink, callback=self.parse) ## 递归将下一页的地址传给这个函数自己,在进行爬取注意寒老师提供的栗子中对此处二次解析的解读 callback=self.parse
4.存储内容(Pipeline)
保存信息的最简单的方法是通过Feed exports,主要有四种:JSON,JSON lines,CSV,XML。将结果用最常用的JSON导出,命令如下:
>scrapy crawl douban -o items.json -t json #-o 后面是导出文件名,-t 后面是导出类型。导出的结果,用文本编辑器打开json文件即可
尝试导出csv格式:
>scrapy crawl douban -o items.csv -t csv
4.1 设置默认存储
可以直接在settings.py文件中设置输出的位置和文件类型,如下:
- FEED_URI = u'file:///E:/douban/douban.csv'
- FEED_FORMAT = 'CSV'

5.运行爬虫(main.py)
不同于简单单线程爬虫程序直接运行,这里我们还需要通过一个main.py来运行,需要自己手动生成,main.py代码如下:

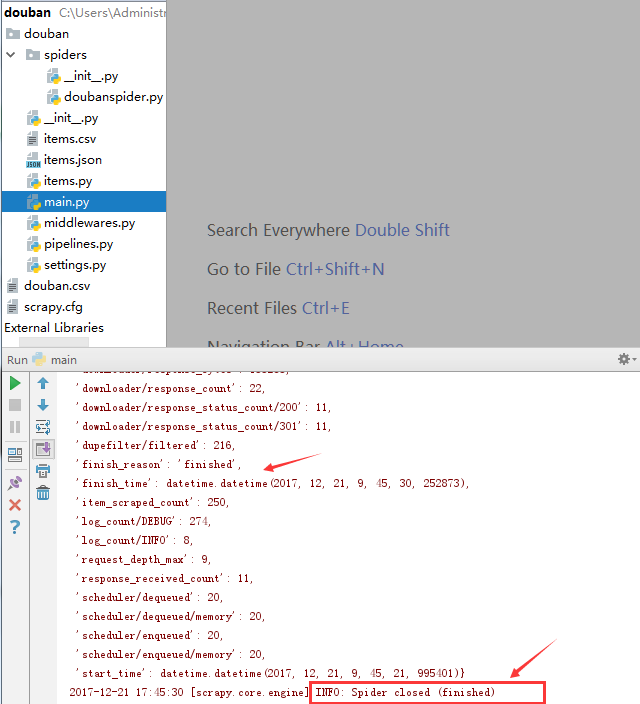
运行结果:
如果你想用抓取的items做更复杂的事情,你可以写一个 Item Pipeline(条目管道)。