===============
1 准备数据
1.1 建立 Employee 表
DROP TABLE IF EXISTS employee; CREATE TABLE IF NOT EXISTS employee( id INT PRIMARY KEY auto_increment, name VARCHAR(40), dept_id INT ); INSERT INTO employee(name, dept_id) VALUES('Alice', 1); INSERT INTO employee(name, dept_id) VALUES('BOb', 2); INSERT INTO employee(name, dept_id) VALUES('Chris', 3333); INSERT INTO employee(name, dept_id) VALUES('David', 4444);
1.2 建立 Department 表
DROP TABLE IF EXISTS department; CREATE TABLE IF NOT EXISTS department( id INT PRIMARY KEY auto_increment, name VARCHAR(40) ); INSERT INTO department(name) VALUES('RD'); INSERT INTO department(name) VALUES('HR'); INSERT INTO department(name) VALUES('test01'); INSERT INTO department(name) VALUES('test02');
2 再回顾一下数据
2.1 Employee表
SELECT * FROM employee;
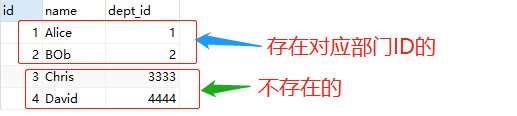
2.2 Department表
SELECT * FROM department;
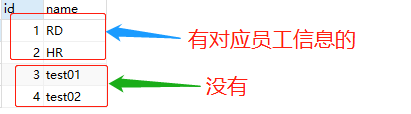
3 测试
3.1 AB共有
图示说明:
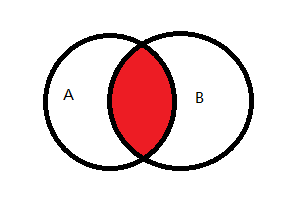
Sql查询:
SELECT * FROM employee e INNER JOIN department d WHERE e.dept_id = d.id;
结果:
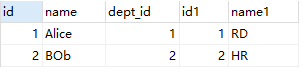
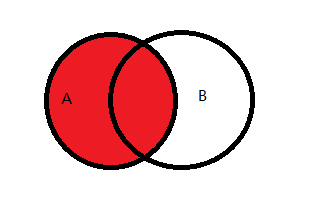
3.2 左外连接
图示说明:
Sql查询:
SELECT * FROM employee e LEFT JOIN department d ON e.dept_id = d.id;
结果:
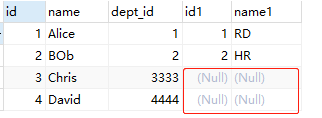
左外连接:左边一定有,如果右边没有则为Null
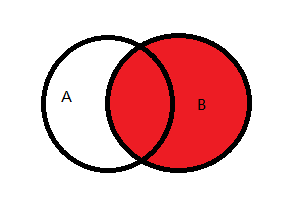
3.3 右外连接
图示说明:
Sql查询:
SELECT * FROM employee e RIGHT JOIN department d ON e.dept_id = d.id;
结果:
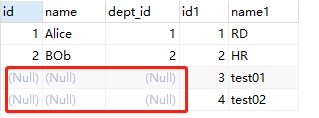
右外连接:右边一定有,如果左边没有则为Null
3.4 A独有
图示说明:
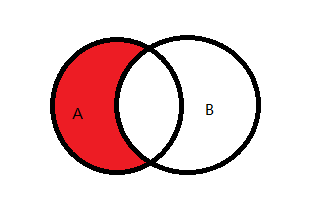
Sql查询:
SELECT * FROM employee e LEFT JOIN department d ON e.dept_id = d.id WHERE d.id IS NULL;
结果:
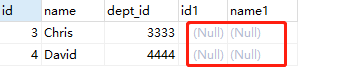
左边独有,说明右边为空,于是对右边加上 IS NULL 的条件即可
3.5 B独有
图示说明:

Sql查询:
SELECT * FROM employee e RIGHT JOIN department d ON e.dept_id = d.id WHERE e.id IS NULL;
结果:
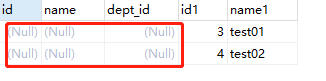
右边独有,说明左边为空,于是对左边加上 IS NULL 的条件即可
3.6 AB并集
图示说明:

Sql查询:
SELECT * FROM employee e LEFT JOIN department d ON e.dept_id = d.id UNION SELECT * FROM employee e RIGHT JOIN department d ON e.dept_id = d.id;
结果:
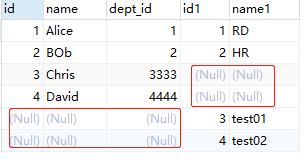
其实就是 3.2(左外连接) 与 3.3(右外连接) 两者的并集
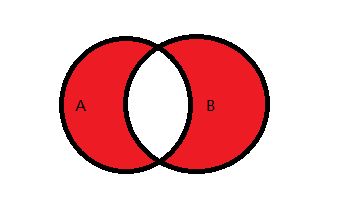
3.7 AB分别独有的并集
图示说明:
Sql查询:
SELECT * FROM employee e LEFT JOIN department d ON e.dept_id = d.id WHERE d.id IS NULL UNION SELECT * FROM employee e RIGHT JOIN department d ON e.dept_id = d.id WHERE e.id IS NULL;
结果:
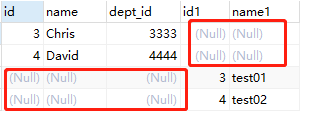
其实就是 3.4(A独有) 与 3.5(B独有) 两者的并集
======下一篇======