在讲解字符集和校对规则之前,我们先来简单了解一下字符、字符集和字符编码。
字符(Character)是计算机中字母、数字、符号的统称,一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号等。
计算机是以二进制的形式来存储数据的。平时我们在显示器上看到的数字、英文、标点符号、汉字等字符都是二进制数转换之后的结果。
字符集(Character set)定义了字符和二进制的对应关系,为字符分配了唯一的编号。常见的字符集有 ASCII、GBK、IOS-8859-1 等。
字符编码(Character encoding)也可以称为字集码,规定了如何将字符的编号存储到计算机中。
大部分字符集都只对应一种字符编码,例如:ASCII、IOS-8859-1、GB2312、GBK,都是既表示了字符集又表示了对应的字符编码。
所以一般情况下,可以将两者视为同义词。Unicode 字符集除外,Unicode 有三种编码方案,即 UTF-8、UTF-16 和 UTF-32。最为常用的是 UTF-8 编码。
校对规则(Collation)也可以称为排序规则,是指在同一个字符集内字符之间的比较规则。字符集和校对规则是一对多的关系,每个字符集都有一个默认的校对规则。字符集和校对规则相辅相成,相互依赖关联。
简单来说,字符集用来定义 MySQL 存储字符串的方式,校对规则用来定义 MySQL 比较字符串的方式。
有些数据库并没有清晰的区分开字符集和校对规则。例如,在 SQL Server 中创建数据库时,选择字符集就相当于选定了字符集和校对规则。
而在 MySQL 中,字符集和校对规则是区分开的,必须设置字符集和校对规则。一般情况下,没有特殊需求,只设置其一即可。只设置字符集时,MySQL 会将校对规则设置为字符集中对应的默认校对规则。
可以通过SHOW VARIABLES LIKE 'character%';命令查看当前 MySQL 使用的字符集,命令和运行结果如下:
mysql> SHOW VARIABLES LIKE 'character%'; +--------------------------+---------------------------------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------------------------------+ | character_set_client | gbk | | character_set_connection | gbk | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | gbk | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | C:Program FilesMySQLMySQL Server 5.7sharecharsets | +--------------------------+---------------------------------------------------------+ 8 rows in set, 1 warning (0.01 sec)
上述运行结果说明如下表所示:
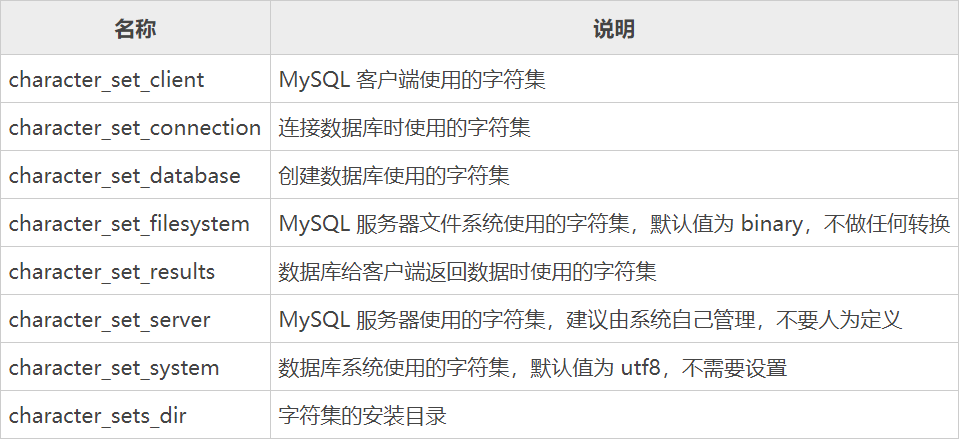
乱码时,不需要关心 character_set_filesystem、character_set_system 和 character_sets_dir 这 3 个系统变量,它们不会影响乱码 。
可以通过SHOW VARIABLES LIKE 'collation\_%';命令查看当前 MySQL 使用的校对规则,命令和运行结果如下
mysql> SHOW VARIABLES LIKE 'collation\_%'; +----------------------+-------------------+ | Variable_name | Value | +----------------------+-------------------+ | collation_connection | gbk_chinese_ci | | collation_database | latin1_swedish_ci | | collation_server | latin1_swedish_ci | +----------------------+-------------------+ 3 rows in set, 1 warning (0.01 sec)
对上述运行结果说明如下:
- collation_connection:连接数据库时使用的校对规则
- collation_database:创建数据库时使用的校对规则
- collation_server:MySQL 服务器使用的校对规则
校对规则命令约定如下:
- 以校对规则所对应的字符集名开头
- 以国家名居中(或以 general 居中)
- 以 ci、cs 或 bin 结尾,ci 表示大小写不敏感,cs 表示大小写敏感,bin 表示按二进制编码值比较。
MySQL字符集的转换过程
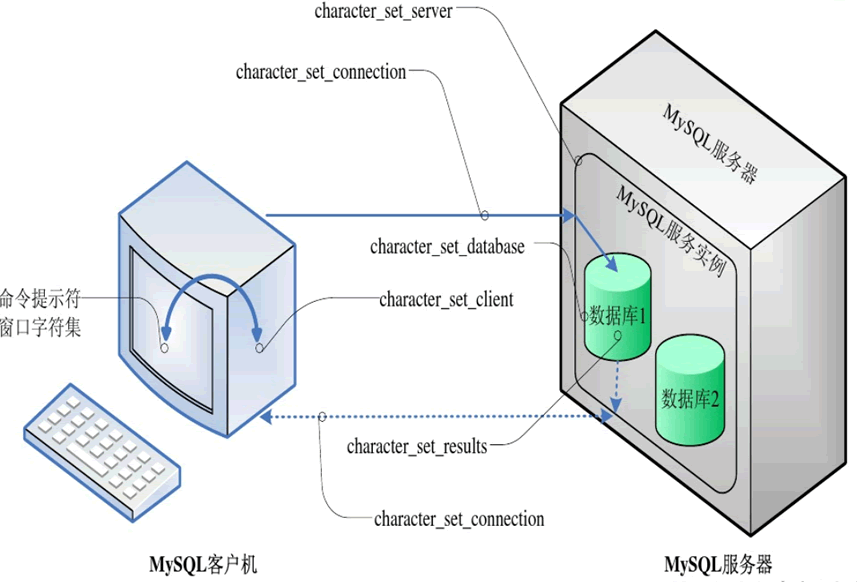
MySQL 中字符集的转换过程如下:
1)在命令提示符窗口(cmd 命令行)中执行 MySQL 命令或 sql 语句时,这些命令或语句从“命令提示符窗口字符集”转换为“character_set_client”定义的字符集。
2)使用命令提示符窗口成功连接 MySQL 服务器后,就建立了一条“数据通信链路”,MySQL 命令或 sql 语句沿着“数据链路”传向 MySQL 服务器,由 character_set_client 定义的字符集转换为 character_set_connection 定义的字符集。
3)MySQL 服务实例收到数据通信链路中的 MySQL 命令或 sql 语句后,将 MySQL 命令或 sql 语句从 character_set_connection 定义的字符集转换为 character_set_server 定义的字符集。
4)若 MySQL 命令或 sql 语句针对于某个数据库进行操作,此时将 MySQL 命令或 sql 语句从 character_set_server 定义的字符集转换为 character_set_database 定义的字符集。
5)MySQL 命令或 sql 语句执行结束后,将执行结果设置为 character_set_results 定义的字符集。
6)执行结果沿着打开的数据通信链路原路返回,将执行结果从 character_set_results 定义的字符集转换为 character_set_client 定义的字符集,最终转换为命令提示符窗口字符集,显示到命令提示符窗口中。
下面介绍主要介绍查看字符集和校对规则的几种方法。
在 MySQL 中,查看可用字符集的命令和执行过程如下:
mysql> SHOW CHARACTER set; +----------+---------------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+---------------------------------+---------------------+--------+ | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | tis620 | TIS620 Thai | tis620_thai_ci | 1 | | euckr | EUC-KR Korean | euckr_korean_ci | 2 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | utf16 | UTF-16 Unicode | utf16_general_ci | 4 | | utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | utf32 | UTF-32 Unicode | utf32_general_ci | 4 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | | gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 | +----------+---------------------------------+---------------------+--------+ 41 rows in set (0.02 sec)
其中:
- 第一列(Charset)为字符集名称;
- 第二列(Description)为字符集描述;
- 第三列(Default collation)为字符集的默认校对规则;
- 第四列(Maxlen)表示字符集中一个字符占用的最大字节数。
常用的字符集如下:
- latin1 支持西欧字符、希腊字符等。
- gbk 支持中文简体字符。
- big5 支持中文繁体字符。
- utf8 几乎支持所有国家的字符。
也可以通过查询 information_schema.character_set 表中的记录,来查看 MySQL 支持的字符集。SQL 语句和执行过程如下:
mysql> SELECT * FROM information_schema.character_sets; +--------------------+----------------------+---------------------------------+--------+ | CHARACTER_SET_NAME | DEFAULT_COLLATE_NAME | DESCRIPTION | MAXLEN | +--------------------+----------------------+---------------------------------+--------+ | big5 | big5_chinese_ci | Big5 Traditional Chinese | 2 | | dec8 | dec8_swedish_ci | DEC West European | 1 | | cp850 | cp850_general_ci | DOS West European | 1 | | hp8 | hp8_english_ci | HP West European | 1 | ......
可以使用 SHOW COLLATION LIKE '***';命令来查看相关字符集的校对规则。
mysql> SHOW COLLATION LIKE 'gbk%'; +----------------+---------+----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +----------------+---------+----+---------+----------+---------+ | gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 | | gbk_bin | gbk | 87 | | Yes | 1 | +----------------+---------+----+---------+----------+---------+ 2 rows in set (0.00 sec)
上面运行结果为 GBK 字符集所对应的校对规则,其中 gbk_chinese_ci 是默认的校对规则,对大小写不敏感。而 gbk_bin 按照二进制编码的值进行比较,对大小写敏感。
也可以通过查询 information_schema.COLLATIONS 表中的记录,来查看 MySQL 中可用的校对规则。SQL 语句和执行过程如下:
mysql> SELECT * FROM information_schema.COLLATIONS; +--------------------------+--------------------+-----+------------+-------------+---------+ | COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLEN | +--------------------------+--------------------+-----+------------+-------------+---------+ | big5_chinese_ci | big5 | 1 | Yes | Yes | 1 | | big5_bin | big5 | 84 | | Yes | 1 | | dec8_swedish_ci | dec8 | 3 | Yes | Yes | 1 | | dec8_bin | dec8 | 69 | | Yes | 1 | | cp850_general_ci | cp850 | 4 | Yes | Yes | 1 | | cp850_bin | cp850 | 80 | | Yes | 1 | ......
例 1
分别指定“A”和“a”按照 gbk_chinese_ci 和 gbk_bin 校对规则进行比较。SQL 语句和运行结果如下:
mysql> SELECT CASE WHEN 'A' COLLATE gbk_chinese_ci = 'a' COLLATE gbk_chinese_ci then 1 -> else 0 end; +-------------------------------------------------------------------------------------+ | CASE WHEN 'A' COLLATE gbk_chinese_ci = 'a' COLLATE gbk_chinese_ci then 1 else 0 end | +-------------------------------------------------------------------------------------+ | 1 | +-------------------------------------------------------------------------------------+ 1 row in set (0.02 sec) mysql> SELECT CASE WHEN 'A' COLLATE gbk_bin = 'a' COLLATE gbk_bin then 1 -> else 0 end; +-----------------------------------------------------------------------+ | CASE WHEN 'A' COLLATE gbk_bin = 'a' COLLATE gbk_bin then 1 else 0 end | +-----------------------------------------------------------------------+ | 0 | +-----------------------------------------------------------------------+ 1 row in set (0.00 sec)
由于 gbk_chinese_ci 校对规则忽略大小写,所以认为两个“A“和“a”是相同的。 gbk_bin 校对规则不忽略大小写,则认为两个字符是不同的。
在实际应用中,我们应事先确认应用需要按照什么样方式排序,是否区分大小写,然后选择相应的校对规则。