1、问题描述
每一个作业Ji都有两项任务分别在2台机器上完成。每个作业必须先有机器1处理,然后再由机器2处理。作业Ji需要机器j的处理时间为tji。对于一个确定的作业调度,设Fji是作业i在机器j上完成处理时间。则所有作业在机器2上完成处理时间和f是指把F2i将i从1-n求和,称为该作业调度的完成时间和。
2、简单描述
对于给定的n个作业,指定最佳作业调度方案,使其完成时间和达到最小。
区别于流水线调度问题:批处理作业调度旨在求出使其完成时间和达到最小的最佳调度序列;
流水线调度问题旨在求出使其最后一个作业的完成时间最小的最佳调度序列;
例:设n=3,考虑以下实例:

这3个作业的6种可能的调度方案是1,2,3;1,3,2;2,1,3;2,3,1;3,1,2;3,2,1;它们所相应的完成时间和分别是19,18,20,21,19,19。易见,最佳调度方案是1,3,2,其完成时间和为18。那么具体的完成时间和是怎么计算的呢?将在第3部分举例说明中详细描述。
3、举例说明


4、算法设计
批处理作业调度问题要从n个作业的所有排列中找出有最小完成时间和的作业调度,所以批处理作业调度问题的解空间是一颗排列树。
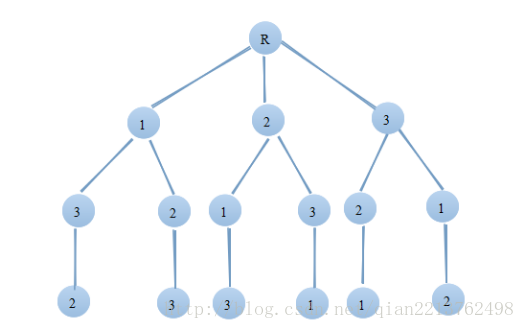
按照回溯法搜索排列树的算法框架,设开始时x=[1,2, ... , n]是所给的n个作业,则相应的排列树由x[1:n]的所有排列(所有的调度序列)构成。
二维数组M是输入作业的处理时间,bestf记录当前最小完成时间和,bestx记录相应的当前最佳作业调度。
在递归函数Backtrack中,
当i>n时,算法搜索至叶子结点,得到一个新的作业调度方案。此时算法适时更新当前最优值和相应的当前最佳调度。
当i<n时,当前扩展结点位于排列树的第(i-1)层,此时算法选择下一个要安排的作业,以深度优先方式递归的对相应的子树进行搜索,对不满足上界约束的结点,则剪去相应的子树。
5、算法分析
【前期准备】
1、区分作业i和当前第i个正在执行的作业
给x赋初值,即其中一种排列,如x=[1,3,2];M[x[j]][i]代表当前作业调度x排列中的第j个作业在第i台机器上的处理时间;如M[x[2]][1]就意味着作业3在机器1上的处理时间。
2、bestf的初值
此问题是得到最佳作业调度方案以便使其完成时间和达到最小,所以当前最优值bestf应该初始化赋值为较大的一个值。
3、f1、f2的定义与计算
假定当前作业调度排列为:x=[1,2,3];f1[i]即第i个作业在机器1上的处理时间,f2[j]即第j个作业在机器2上的处理时间;则:
f1[1]=M[1][1] , f2[1]=f1[1]+M[1][2]
f1[2]=f1[1]+M[2][1] , f2[2]=MAX(f2[1],f1[2])+M[2][2] //f2[2]不光要等作业2自己在机器1上的处理时间,还要等作业1在机器2上的处理时间,选其大者。
f1[3]=f1[2]+M[3][1] , f2[3]=MAX(f2[2],f1[3])+M[3][2]
1只有当前值有用,可以覆盖赋值,所以定义为int型变量即可,减少空间消耗;f2需要记录每个作业的处理时间,所以定义为int *型,以便计算得完成时间和。
4、f2[0]的初值
f2[i]的计算都是基于上一个作业f2[i-1]进行的,所以要记得给f2[0]赋值为0。
6.代码实现


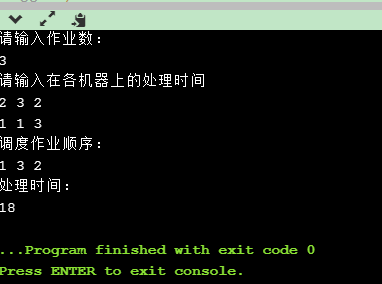
#include<iostream> using namespace std; int x[100]; //当前作业调度————其中一种排列顺序 int bestx[100]; //当前最优作业调度 int m[100][100];//各作业所需的处理时间 //M[j][i]代表第j个作业在第i台机器上的处理时间 int f1=0;//机器1完成处理时间 int f2=0;//机器2完成处理时间 int cf=0;//完成时间和 int bestf=10000;//当前最优值,即最优的处理时间和 int n;//作业数 void swap(int &a,int &b) { int temp=a; a=b; b=temp; } void Backtrack(int t) { //t用来指示到达的层数(第几步,从0开始),同时也指示当前执行完第几个任务/作业 int tempf,j; if(t>n) //到达叶子结点,搜索到最底部 { if(cf<bestf) { for(int i=1; i<=n; i++) bestx[i]=x[i];//更新最优调度序列 bestf=cf;//更新最优目标值 } } else //非叶子结点 { for(j=t; j<=n; j++) //j用来指示选择了哪个任务/作业(也就是执行顺序) { f1+=m[x[j]][1];//选择第x[j]个任务在机器1上执行,作为当前的任务 tempf=f2;//保存上一个作业在机器2的完成时间 f2=(f1>f2?f1:f2)+m[x[j]][2];//保存当前作业在机器2的完成时间 cf+=f2; //在机器2上的完成时间和 //如果该作业处理完之后,总时间已经超过最优时间,就直接回溯。 //剪枝函数 if(cf<bestf) //总时间小于最优时间 { swap(x[t],x[j]); //交换两个作业的位置,把选择出的原来在x[j]位置上的任务调到当前执行的位置x[t] Backtrack(t+1); //深度搜索解空间树,进入下一层 swap(x[t],x[j]); //进行回溯,还原,执行该层的下一个任务 //如果是叶子节点返回上一层 } //回溯需要还原各个值 f1-=m[x[j]][1]; cf-=f2; f2=tempf; } } } int main() { int i,j; cout<<"请输入作业数:"<<endl; cin>>n; cout<<"请输入在各机器上的处理时间"<<endl; for(i=1; i<=2; i++) //i从1开始 for(j=1; j<=n; j++) cin>>m[j][i];//第j个作业,第i台机器的时间值 for(i=1; i<=n; i++) x[i]=i;//初始化当前作业调度的一种排列顺序 Backtrack(1); cout<<"调度作业顺序:"<<endl; for(i=1; i<=n; i++) cout<<bestx[i]<<' '; cout<<endl; cout<<"处理时间:"<<endl; cout<<bestf; return 0; } /* 测试数据: 3 2 3 2 1 1 3 3 2 5 4 3 2 1 */
7.实现结果

参考文献:王晓东《算法设计与分析》
https://blog.csdn.net/qian2213762498/article/details/79420060