redis主从复制
redis主从配置比较简单,基本就是在从节点配置文件加上:slaveof 192.168.33.130 6379
主要是通过master server持久化的rdb文件实现的。master server 先dump出内存快照文件,然后将rdb文件传给slave server,slave server 根据rdb文件重建内存表。
redis复制过程如下:
1、slave server启动连接到master server之后,salve server主动发送SYNC命令给master server
2、master server接受SYNC命令之后,判断,是否有正在进行内存快照的子进程,如果有,则等待其结束,否则,fork一个子进程,子进程把内存数据保存为文件,并发送给slave server
3、master server子进程进程做数据快照时,父进程可以继续接收client端请求写数据,此时,父进程把新写入的数据放到待发送缓存队列中
4、slave server 接收内存快照文件之后,清空内存数据,根据接收的快照文件,重建内存表数据结构
5、master server把快照文件发送完毕之后,发送缓存队列中保存的子进程快照期间改变的数据给slave server,slave server做相同处理,保存数据一致性
6、master server 后续接收的数据,都会通过步骤1建立的连接,把数据发送到slave server
需要注意:slave server如果因为网络或其他原因断与master server的连接,当slave server重新连接时,需要重新获取master server的内存快照文件,slave server的数据会自动全部清空,然后再重新建立内存表,这样会让slave server 启动恢复服务比较慢,同时也给master server带来较大压力,可以看出redis的复制没有增量复制的概念,这是redis主从复制的一个主要弊端,在实际环境中,尽量规避中途增加从库
redis2.8之前不支持增量,到2.8之后就支持增量了!
redis cluster(集群)
3.0之后的功能,至少需要3(Master)+3(Slave)才能建立集群,是无中心的分布式存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用、可扩展等问题。
redis集群提供了以下两个好处
1、将数据自动切分(split)到多个节点
2、当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
一个 redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个。集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。集群中的每一个节点负责处理一部分哈希槽。
集群中的主从复制
集群中的每个节点都有1个至N个复制品,其中一个为主节点,其余的为从节点,如果主节点下线了,集群就会把这个主节点的一个从节点设置为新的主节点,继续工作。这样集群就不会因为一个主节点的下线而无法正常工作
注意:
1、如果某一个主节点和他所有的从节点都下线的话,redis集群就会停止工作了。redis集群不保证数据的强一致性,在特定的情况下,redis集群会丢失已经被执行过的写命令
2、使用异步复制(asynchronous replication)是redis 集群可能会丢失写命令的其中一个原因,有时候由于网络原因,如果网络断开时间太长,redis集群就会启用新的主节点,之前发给主节点的数据就会丢失。
Redis集群
基本介绍
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施installation。
Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低Redis集群的性能, 并导致不可预测的行为。
Redis 集群通过分区partition来提供一定程度的可用性availability: 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis集群提供了以下两个好处:
- 将数据自动切分
split到多个节点的能力。 - 当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。
集群原理
redis-cluster架构图
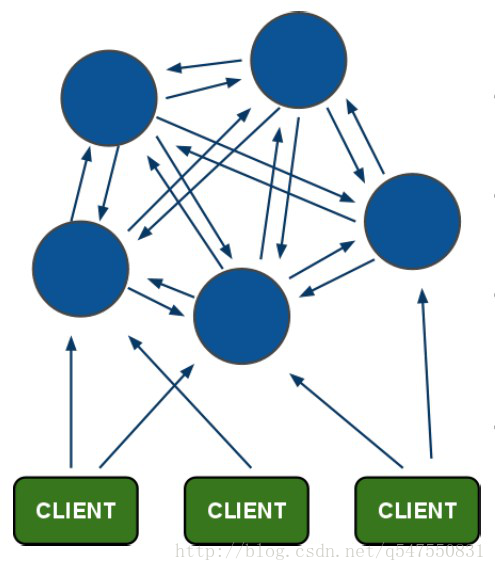
-
所有的
redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。 -
节点的
fail是通过集群中超过半数的节点检测失效时才生效。 -
客户端与
redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。 -
redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster负责维护node<->slot<->value
Redis集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
redis-cluster投票:容错
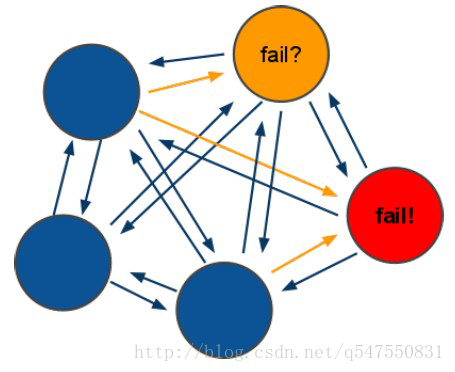
-
投票过程是集群中所有
master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),认为当前master节点挂掉. -
什么时候整个集群不可用(
cluster_state:fail)?- 如果集群任意
master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完整时进入fail状态.
redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
- 如果集群超过半数以上
master挂掉,无论是否有slave,集群进入fail状态.
- 如果集群任意
主从概念
- 一个master可以拥有多个slave,一个slave又可以拥有多个slave。如此下去,形成了强大的多级服务器集群架构。
- master用写数据,经统计:网站的读写比率是10:1
- 通过主从分离可以实现读写分离
- master和slave都是一个redis实例(redis服务)
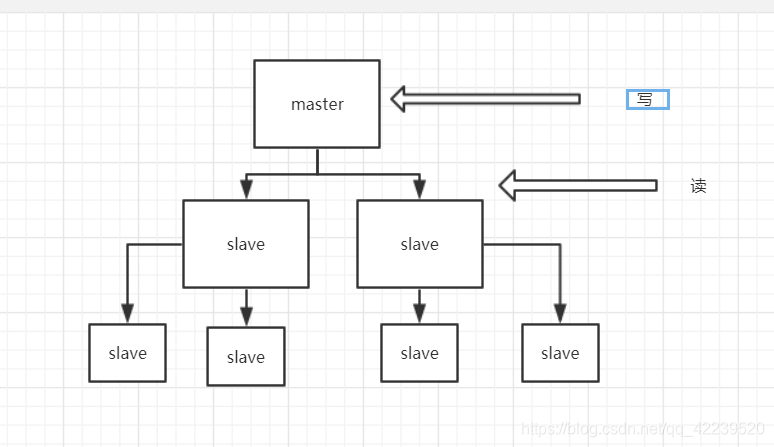
-
因此,主从模型可以提高读的能力,在一定程度上缓解了写的能力。因为能写仍然只有Master节点一个,可以将读的操作全部移交到从节点上,变相提高了写能力。
问题:我们已经部署好了redis,并且能启动一个redis,实现数据的读写,为什么还要学习redis集群?
答:(1)单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
(2)单个redis的读写能力是有限的。
redis集群是为了强化redis的读写能力。
总结:主从着眼于高可用,集群Cluster提高并发量