1.服务器渲染:在服务器端直接把HTML骨架和数据整合在一起,统一发送给浏览器
在页面源代码当中能看到数据
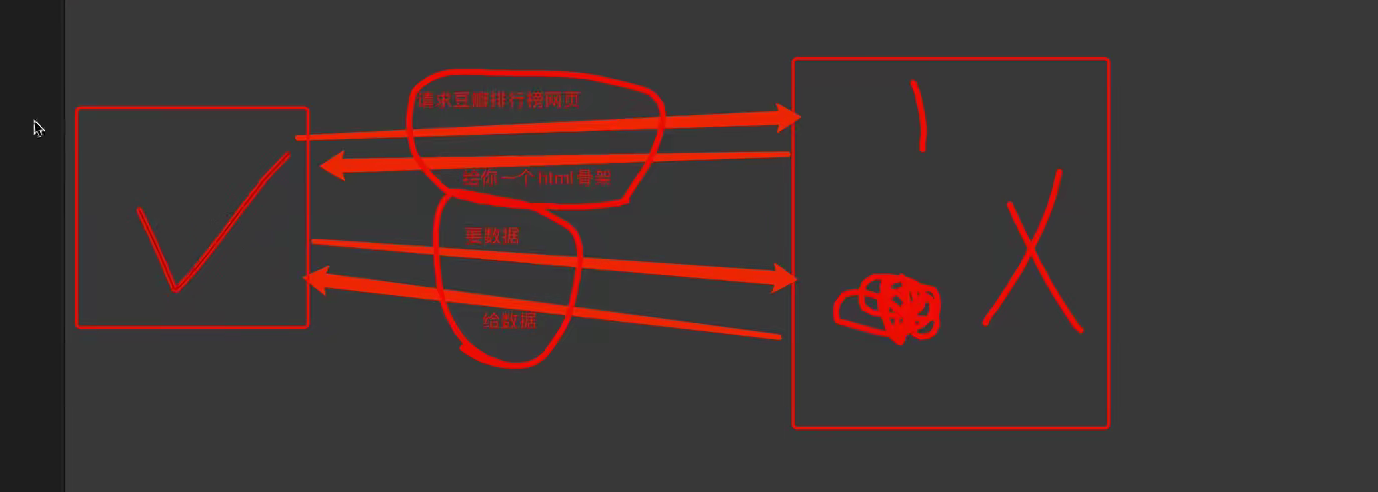
2.客户端渲染:
第一次请求只要求一个HTML骨架,第二次请求拿到数据,进行数据展示
在页面源代码中,看不到数据
第一次请求拿不到数据,只要找到第二次请求的url 就能拿到数据
使用浏览器的抓包工具
Http协议:传递网站代码
请求行-> 请求方式(get 一般是显示提交 请求数据一般会用到 获取 /post 上传数据 一般修改单个数据或少量数据会用到) 请求 url地址 协议
请求头--> 放一些服务求要使用的附加信息(一般反爬虫的关键位置)
{1.User-Agent:请求载体的身份标识 用什么发送的请求
2.Referer: 防盗链 一般记录这次请求从哪个页面来的?反爬取会用到
3.cookie: 本地字符串数据信息 (用户登录信息,反爬的token)}
请求体 --> 一般放一些请求参数
状态行 ->协议 状态码(404/500/200)
响应头 -> 放一些客户端要使用的一些附加信息(一般反爬虫的关键位置)
{1.cookie: 本地字符串数据信息 用户登录信息,反爬的token
2.各种神奇的莫名其妙的字符串 经验之谈 一般都是token 字样 ,防止各种攻击和反爬}
响应体 -> 服务器返回的真正客户端要使用的内容(html,json)等
python利用open打开文件的方式:
w:以写方式打开,
a:以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+:以读写模式打开
w+:以读写模式打开 (参见 w )
a+:以读写模式打开 (参见 a )
rb:以二进制读模式打开
wb:以二进制写模式打开 (参见 w )
ab:以二进制追加模式打开 (参见 a )
rb+:以二进制读写模式打开 (参见 r+ )
wb+:以二进制读写模式打开 (参见 w+ )
ab+:以二进制读写模式打开 (参见 a+ )