1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
答:
HDFS是hadoop的核心组件之一,分布式存储海量的数据;
MapReduce也是hadoop的核心组件之一,分布式计算数据,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
Yarn 是Hadoop 2.0 中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度。
Hbase是一种NoSQL数据库。HBase是非关系型数据库(Nosql),在某些业务场景下,数据存储查询在Hbase的使用效率更高。HBase中保存的数据可以使用MapReduce来处理
Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储系统,可融入Hadoop生态。是一种快速、通用、可扩展的大数据分析引擎,是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目。
针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN(Yet Another Resource Negotiator),它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。对应Hadoop版本为Hadoop 0.23.x和2.x。YARN是Hadoop的一个子项目(与MapReduce并列),它实际上是一个资源统一管理系统,可以在上面运行各种计算框架(包括MapReduce、Spark、Storm、MPI等)。
hadoop的MapReduce是分步对数据进行处理的,从磁盘中读取数据,进行一次处理,将结果写到磁盘,然后在从磁盘中读取更新后的数据,再次进行的处理,最后再将结果存入磁盘,这存取磁盘的过程会影响处理速度。而spark从磁盘中读取数据,把中间数据放到内存中,,完成所有必须的分析处理,将结果写回集群,所以spark更快,所以引入spark可提高数据的运算速度。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark 生态系统以Spark Core 为核心,能够读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源,利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。主要组件包括Spark Streaming、Spark SQL、 MLBase/MLlib、GraphX
2.1spark Core是整个生态系统地核心组件,是一个分布式大数据处理框架。Spark Core中提供了多种资源部调度管理,通过内存计算、有向无环图(DAG)等机制来保证分布式计算的快速,并引入了RDD的抽象保证数据的高容错性
2.2 Spark Streaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
由于使用DStreaming,Spark Streaming具有如下特性:
动态负载均衡:Spark Streaming将数据划分为小批量,通过这种方式可以实现对资源更加细粒度的分配。
快速故障恢复机制:在Spark中,计算将分成许多小的任务,保证能够在任何节点运行后能够正确进行合并。因此,在某个节点出现的故障的情况,这个节点的任务将均匀的分散在集群中的节点进行计算。
批处理、流处理与交互式的一体化:Spark Streaming是将流式计算分解成一系列短小的批处理作业,也就是SparkStreaming的输入数据按照批处理大小,分成一段一段的离散数据流(DStream),每一段数据都转换成Spark中的RDD。
2.3 Spark SQL
Spark SQL允许开发人员直接处理RDD,同时也可查询例如在 Apache Hive上存在的外部数据。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。
2.4 MLBase/MLlib
MLBase是Spark生态圈的一部分专注于机器学习,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLbase。MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。
MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,该算法可以进行可扩充;
MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台;
ML Optimizer会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果
2.5 GraphX
GraphX是Spark中用于图和图并行计算的API,可以认为是GraphLab和Pregel在Spark上的重写和优化。跟其他分布式图计算框架相比,GraphX最大的优势是:在Spark基础上提供了一栈式数据解决方案,可以高效地完成图计算的完整流水作业。
3. 用图文描述你所理解的Spark运行架构,运行流程。
1.程序的执行流程:
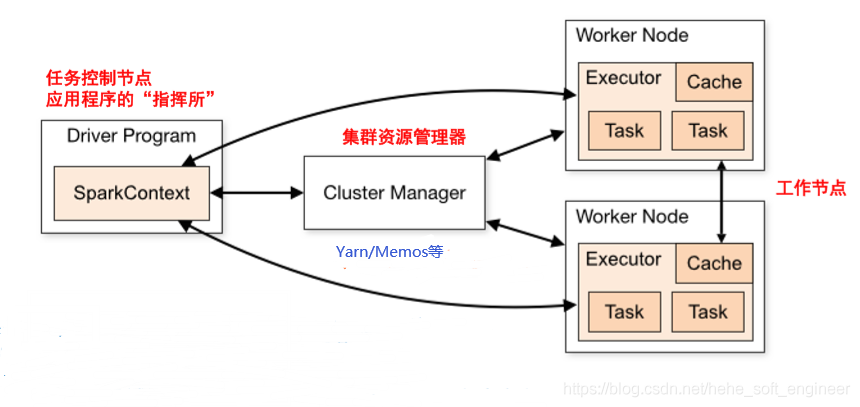
当执行一个应用时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用 程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
2.下面是Spark应用程序详细流程

①当一个Spark应用程序被提交时,首先要为这个应用程序的执行构建基本的运行环境(资源)。任务控制器(Driver)会创建一个SparkContext对象,由SparkContext和Custer Manager进行通信、资源申请(申请运行Executor的资源)、任务分配和监控等。SparkContext可以被看作应用程序连接集群的通道。
②Cluster Manager为Executor分配资源,并启动Executor进程,Executor上资源的使用情况将通过心跳的方式反馈到Cluster Manager上。
③SparkContext会根据RDD的依赖关系构建DAG,DAG会被提交到DAG调度器(DAG Scheduler)进行解析,将DAG分解为多个阶段(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,接着把一个个任务集交给任务调度器(Task Scheduler)。
④Executor进程启动后会向SparkContext申请任务,接着任务调度器(Task Scheduler)会将任务发送给Executor执行,同时SparkContext还会把代码发送给Executor。
⑤任务执行的结果会反馈给任务调度器,然后返回给DAG调度器,运行完成后将执行结果会返回给Driver,或者写到HDFS并释放掉资源。
3. 用图文描述你所理解的Spark运行架构,运行流程。