语料链接:https://pan.baidu.com/s/1aDIp3Hxw-Xuxcx-lQ_0w9A
提取码:hpg7
trains.txt pos/neg各500条,一共1000条(用于训练模型)
dev.txt pos/neg各100条,一共200条(用于调参数)
tests.txt pos/neg各150条,一共300条(用于测试)
例如:下面是一个正面样本的例子。
<Polarity>1</Polarity>
<text>sit back in one of those comfortable chairs.</text>
1.数据预处理
加载数据、创建vocabulary、创建iterator,前面博客里写过类似的就不重复了,直接放代码。
1 import numpy as np 2 import torch 3 from torch import nn, optim 4 import torch.nn.functional as F 5 from torchtext import data 6 7 import math 8 import time 9 10 11 SEED = 123 12 BATCH_SIZE = 128 13 LEARNING_RATE = 1e-3 #学习率 14 EMBEDDING_DIM = 100 #词向量维度 15 16 #为CPU设置随机种子 17 torch.manual_seed(SEED) 18 19 TEXT = data.Field(tokenize=lambda x: x.split(), lower=True) 20 LABEL = data.LabelField(dtype=torch.float) 21 22 #get_dataset返回Dataset所需的examples和fields 23 def get_dataset(corpur_path, text_field, label_field): 24 fields = [('text', text_field), ('label', label_field)] #torchtext文件配对关系 25 examples = [] 26 27 with open(corpur_path) as f: 28 li = [] 29 while True: 30 content = f.readline().replace(' ', '') 31 if not content: #为空行,表示取完一次数据(一次的数据保存在li中) 32 if not li: #如果列表也为空,则表示数据读完,结束循环 33 break 34 label = li[0][10] 35 text = li[1][6:-7] 36 examples.append(data.Example.fromlist([text, label], fields)) 37 li = [] 38 else: 39 li.append(content) #["<Polarity>标签</Polarity>", "<text>句子内容</text>"] 40 41 return examples, fields 42 43 #得到构建Dataset所需的examples和fields 44 train_examples, train_fields = get_dataset("corpurs/trains.txt", TEXT, LABEL) 45 dev_examples, dev_fields = get_dataset("corpurs/dev.txt", TEXT, LABEL) 46 test_examples, test_fields = get_dataset("corpurs/tests.txt", TEXT, LABEL) 47 48 49 #构建Dataset数据集 50 train_data = data.Dataset(train_examples, train_fields) 51 dev_data = data.Dataset(dev_examples, dev_fields) 52 test_data = data.Dataset(test_examples, test_fields) 53 54 print('len of train data:', len(train_data)) #1000 55 print('len of dev data:', len(dev_data)) #200 56 print('len of test data:', len(test_data)) #300 57 58 print(train_data.examples[15].text) 59 print(train_data.examples[15].label) 60 61 62 #创建vocabulary 63 TEXT.build_vocab(train_data, max_size=5000, vectors='glove.6B.100d') 64 LABEL.build_vocab(train_data) 65 print(len(TEXT.vocab)) #3287 66 print(TEXT.vocab.itos[:12]) #['<unk>', '<pad>', 'the', 'and', 'a', 'to', 'is', 'was', 'i', 'of', 'for', 'in'] 67 print(TEXT.vocab.stoi['like']) #43 68 print(LABEL.vocab.stoi) #defaultdict(None, {'0': 0, '1': 1}) 69 70 71 #创建iterators,每个itartion都会返回一个batch的examples 72 train_iterator, dev_iterator, test_iterator = data.BucketIterator.splits( 73 (train_data, dev_data, test_data), 74 batch_size=BATCH_SIZE, 75 sort = False)
2.定义模型
2.1形式一:根据注意力机制的定义求解
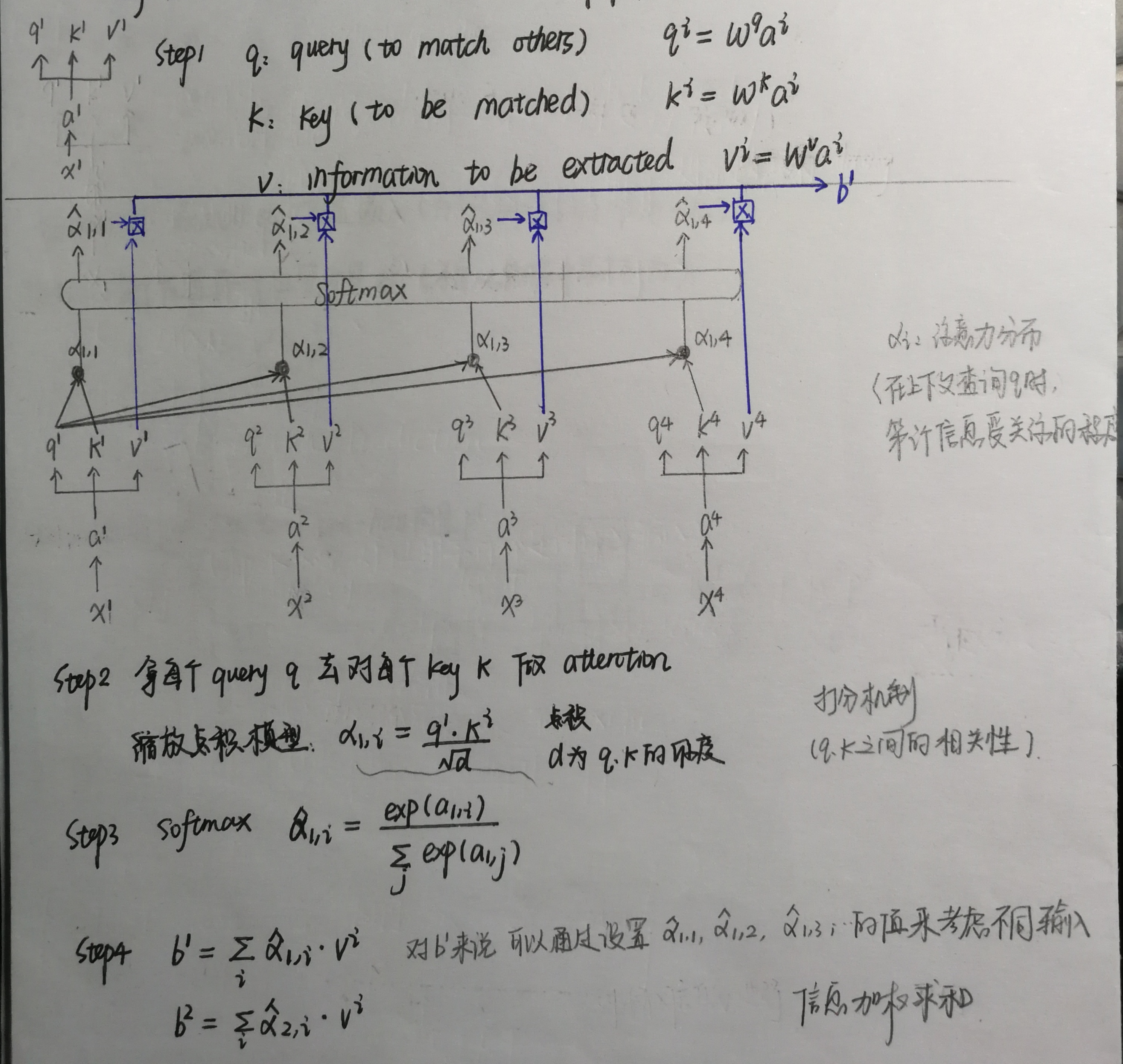
1 class BiLSTM_Attention(nn.Module): 2 3 def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers): 4 5 super(BiLSTM_Attention, self).__init__() 6 7 self.hidden_dim = hidden_dim 8 self.n_layers = n_layers 9 self.embedding = nn.Embedding(vocab_size, embedding_dim) 10 self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=True, dropout=0.5) 11 self.fc = nn.Linear(hidden_dim * 2, 1) 12 self.dropout = nn.Dropout(0.5) 13 14 #x,query:[batch, seq_len, hidden_dim*2] 15 def attention_net(self, x, query, mask=None): #软性注意力机制(key=value=x) 16 17 d_k = query.size(-1) #d_k为query的维度 18 scores = torch.matmul(query, x.transpose(1, 2)) / math.sqrt(d_k) #打分机制 scores:[batch, seq_len, seq_len] 19 20 p_attn = F.softmax(scores, dim = -1) #对最后一个维度归一化得分 21 context = torch.matmul(p_attn, x).sum(1) #对权重化的x求和,[batch, seq_len, hidden_dim*2]->[batch, hidden_dim*2] 22 return context, p_attn 23 24 25 def forward(self, x): 26 embedding = self.dropout(self.embedding(x)) #[seq_len, batch, embedding_dim] 27 28 # output: [seq_len, batch, hidden_dim*2] hidden/cell: [n_layers*2, batch, hidden_dim] 29 output, (final_hidden_state, final_cell_state) = self.rnn(embedding) 30 output = output.permute(1, 0, 2) #[batch, seq_len, hidden_dim*2] 31 32 query = self.dropout(output) 33 attn_output, attention = self.attention_net(output, query) #和LSTM的不同就在于这一句 34 logit = self.fc(attn_output) 35 return logit
2.2形式二:参考:https://blog.csdn.net/qsmx666/article/details/107118550
Attention公式:
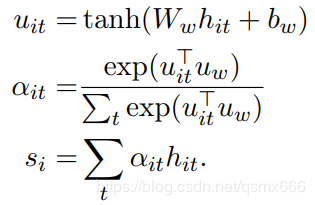
图中的Ww和uw对应了下面代码中的w_omega和u_omega,随机初始化而来,hit对应x。
1 class BiLSTM_Attention(nn.Module): 2 3 def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers): 4 5 super(BiLSTM_Attention, self).__init__() 6 7 self.hidden_dim = hidden_dim 8 self.n_layers = n_layers 9 self.embedding = nn.Embedding(vocab_size, embedding_dim) #单词数,嵌入向量维度 10 self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=True, dropout=0.5) 11 self.fc = nn.Linear(hidden_dim * 2, 1) 12 self.dropout = nn.Dropout(0.5) 13 14 # 初始时间步和最终时间步的隐藏状态作为全连接层输入 15 self.w_omega = nn.Parameter(torch.Tensor(hidden_dim * 2, hidden_dim * 2)) 16 self.u_omega = nn.Parameter(torch.Tensor(hidden_dim * 2, 1)) 17 18 nn.init.uniform_(self.w_omega, -0.1, 0.1) 19 nn.init.uniform_(self.u_omega, -0.1, 0.1) 20 21 22 def attention_net(self, x): #x:[batch, seq_len, hidden_dim*2] 23 24 u = torch.tanh(torch.matmul(x, self.w_omega)) #[batch, seq_len, hidden_dim*2] 25 att = torch.matmul(u, self.u_omega) #[batch, seq_len, 1] 26 att_score = F.softmax(att, dim=1) 27 28 scored_x = x * att_score #[batch, seq_len, hidden_dim*2] 29 30 context = torch.sum(scored_x, dim=1) #[batch, hidden_dim*2] 31 return context 32 33 34 def forward(self, x): 35 embedding = self.dropout(self.embedding(x)) #[seq_len, batch, embedding_dim] 36 37 # output: [seq_len, batch, hidden_dim*2] hidden/cell: [n_layers*2, batch, hidden_dim] 38 output, (final_hidden_state, final_cell_state) = self.rnn(embedding) 39 output = output.permute(1, 0, 2) #[batch, seq_len, hidden_dim*2] 40 41 attn_output = self.attention_net(output) 42 logit = self.fc(attn_output) 43 return logit
使用模型,使用预训练过的embedding来替换随机初始化,定义优化器、损失函数。
1 rnn = BiLSTM_Attention(len(TEXT.vocab), EMBEDDING_DIM, hidden_dim=64, n_layers=2) 2 3 pretrained_embedding = TEXT.vocab.vectors 4 print('pretrained_embedding:', pretrained_embedding.shape) #torch.Size([3287, 100]) 5 rnn.embedding.weight.data.copy_(pretrained_embedding) 6 print('embedding layer inited.') 7 8 optimizer = optim.Adam(rnn.parameters(), lr=LEARNING_RATE) 9 criteon = nn.BCEWithLogitsLoss()
3.训练、评估模型
常规套路:计算准确率、训练函数、评估函数、打印模型表现、用保存的模型参数预测测试数据。
1 #计算准确率 2 def binary_acc(preds, y): 3 preds = torch.round(torch.sigmoid(preds)) 4 correct = torch.eq(preds, y).float() 5 acc = correct.sum() / len(correct) 6 return acc 7 8 9 #训练函数 10 def train(rnn, iterator, optimizer, criteon): 11 12 avg_loss = [] 13 avg_acc = [] 14 rnn.train() #表示进入训练模式 15 16 for i, batch in enumerate(iterator): 17 18 pred = rnn(batch.text).squeeze() #[batch, 1] -> [batch] 19 20 loss = criteon(pred, batch.label) 21 acc = binary_acc(pred, batch.label).item() #计算每个batch的准确率 22 23 avg_loss.append(loss.item()) 24 avg_acc.append(acc) 25 26 optimizer.zero_grad() 27 loss.backward() 28 optimizer.step() 29 30 avg_acc = np.array(avg_acc).mean() 31 avg_loss = np.array(avg_loss).mean() 32 return avg_loss, avg_acc 33 34 35 #评估函数 36 def evaluate(rnn, iterator, criteon): 37 38 avg_loss = [] 39 avg_acc = [] 40 rnn.eval() #表示进入测试模式 41 42 with torch.no_grad(): 43 for batch in iterator: 44 45 pred = rnn(batch.text).squeeze() #[batch, 1] -> [batch] 46 47 loss = criteon(pred, batch.label) 48 acc = binary_acc(pred, batch.label).item() 49 50 avg_loss.append(loss.item()) 51 avg_acc.append(acc) 52 53 avg_loss = np.array(avg_loss).mean() 54 avg_acc = np.array(avg_acc).mean() 55 return avg_loss, avg_acc 56 57 58 #训练模型,并打印模型的表现 59 best_valid_acc = float('-inf') 60 61 for epoch in range(30): 62 63 start_time = time.time() 64 65 train_loss, train_acc = train(rnn, train_iterator, optimizer, criteon) 66 dev_loss, dev_acc = evaluate(rnn, dev_iterator, criteon) 67 68 end_time = time.time() 69 70 epoch_mins, epoch_secs = divmod(end_time - start_time, 60) 71 72 if dev_acc > best_valid_acc: #只要模型效果变好,就保存 73 best_valid_acc = dev_acc 74 torch.save(rnn.state_dict(), 'wordavg-model.pt') 75 76 print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs:.2f}s') 77 print(f' Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%') 78 print(f' Val. Loss: {dev_loss:.3f} | Val. Acc: {dev_acc*100:.2f}%') 79 80 81 #用保存的模型参数预测数据 82 rnn.load_state_dict(torch.load("wordavg-model.pt")) 83 test_loss, test_acc = evaluate(rnn, test_iterator, criteon) 84 print(f'Test. Loss: {test_loss:.3f} | Test. Acc: {test_acc*100:.2f}%') 85
hidden_dim=64, n_layers=2的条件下:
当定义的模型部分只有LSTM时,准确率:78.08%
当使用2.1的Attention公式,准确率:82.46%
当使用2.2的Attention公式,准确率:81.49%
加入Attention机制,性能略有提升。