glove和word2vec是目前最常用的两个训练词向量的模型,两者训练出来的文件都以文本格式呈现,区别在于word2vec包含向量的数量及其维度。
1.gensim加载glove训练的词向量
1 import numpy as np 2 3 import matplotlib.pyplot as plt 4 plt.style.use('ggplot') 5 6 from sklearn.decomposition import PCA 7 #加载Glove向量 8 from gensim.test.utils import datapath, get_tmpfile 9 from gensim.models import KeyedVectors 10 #加载word2vec向量 11 from gensim.scripts.glove2word2vec import glove2word2vec 12 13 14 glove_file = datapath('F:/python_DemoCode/PytorchEx/.vector_cache/glove.6B.100d.txt') #输入文件 15 word2vec_glove_file = get_tmpfile("F:/python_DemoCode/PytorchEx/.vector_cache/glove.6B.100d.word2vec.txt") #输出文件 16 glove2word2vec(glove_file, word2vec_glove_file) #转换 17 18 model = KeyedVectors.load_word2vec_format(word2vec_glove_file) #加载转化后的文件
测试一下:
1 print(model['banana'].shape) #(100,) 2 3 print(model.most_similar('banana')) 4 print(model.most_similar(negative='banana')) 5 6 #计算词语相似度 7 result = model.most_similar(positive=['woman', 'king'], negative=['man']) 8 print("{}: {:.4f}".format(*result[0])) #queen: 0.7699 9 10 11 def analogy(x1, x2, y1): 12 result = model.most_similar(positive=[y1, x2], negative=[x1]) 13 return result[0][0] 14 15 print(analogy('man', 'king', 'woman')) #queen 16 print(analogy('japan', 'japanese', 'australia')) #australian 17 print(analogy('tall', 'tallest', 'long')) #longest 18 print(analogy('good', 'fantastic', 'bad')) #terrible 19 20 print(model.doesnt_match("breakfast cereal dinner lunch".split())) #cereal
散点图演示一下:
1 def display_pca_scatterplot(model, words=None, sample=0): 2 if words == None: 3 if sample > 0: 4 words = np.random.choice(list(model.vocab.keys()), sample) 5 else: 6 words = [ word for word in model.vocab ] #words里面存储了单词集,len(model.vocab))=400000 7 8 word_vectors = np.array([model[w] for w in words]) #word_vectors里面存储了单词集对应的嵌入向量 9 10 twodim = PCA().fit_transform(word_vectors)[:,:2] #降维,取前两个维度 11 12 plt.figure(figsize=(6,6)) 13 plt.scatter(twodim[:,0], twodim[:,1], edgecolors='k', c='r') 14 for word, (x,y) in zip(words, twodim): 15 plt.text(x+0.05, y+0.05, word) 16 17 18 display_pca_scatterplot(model, 19 ['coffee', 'tea', 'beer', 'wine', 'brandy', 'rum', 'champagne', 'water', 20 'spaghetti', 'borscht', 'hamburger', 'pizza', 'falafel', 'sushi', 'meatballs', 21 'dog', 'horse', 'cat', 'monkey', 'parrot', 'koala', 'lizard', 22 'frog', 'toad', 'monkey', 'ape', 'kangaroo', 'wombat', 'wolf', 23 'france', 'germany', 'hungary', 'luxembourg', 'australia', 'fiji', 'china', 24 'homework', 'assignment', 'problem', 'exam', 'test', 'class', 25 'school', 'college', 'university', 'institute'])
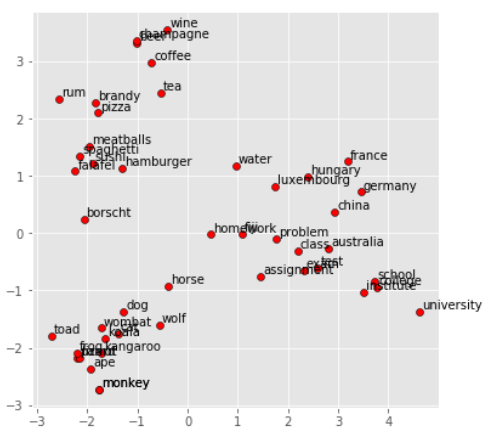
由图可知,相关性较大的词语会靠的近一些。