1.余弦相似度
加载需要的包和词向量(选择加载训练好的词嵌入数据)
1 import numpy as np 2 from w2v_utils import * 3 4 #words:单词集合 5 #word_to_vec:字典类型,{word:该word的50维度的嵌入向量} 6 words, word_to_vec_map = read_glove_vecs('datasets/glove.6B.50d.txt')
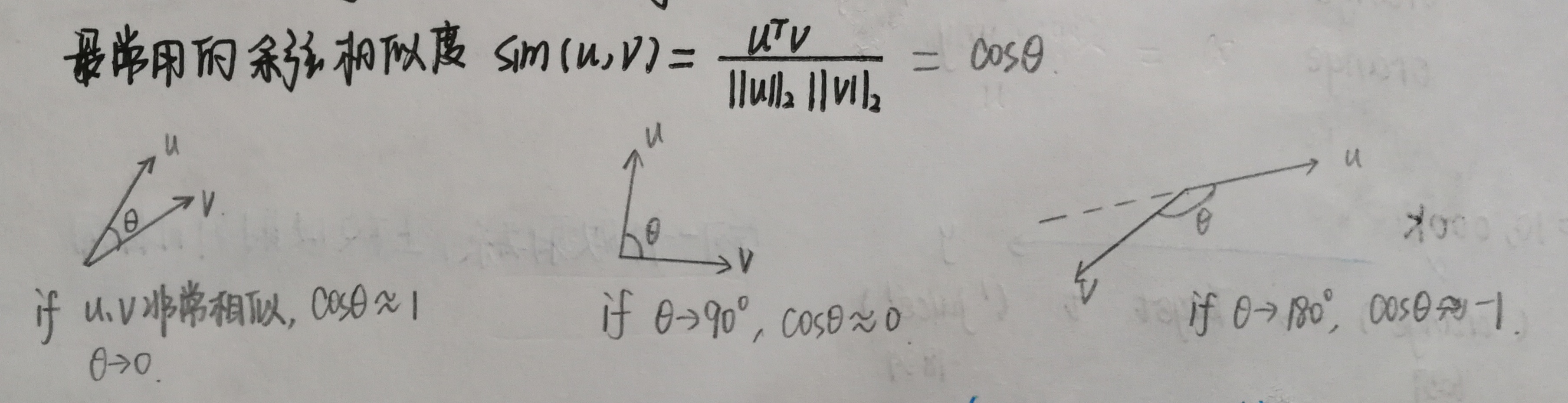
1 def cosine_similarity(u, v): 2 """ 3 Cosine similarity reflects the degree of similariy between u and v 4 5 Arguments: 6 u -- a word vector of shape (n,) 7 v -- a word vector of shape (n,) 8 9 Returns: 10 cosine_similarity -- the cosine similarity between u and v defined by the formula above. 11 """ 12 distance = 0.0 13 14 ### START CODE HERE ### 15 # Compute the dot product between u and v (≈1 line) 16 numerator = np.dot(u,v) 17 # Compute the L2 norm of u (≈1 line) 18 norm_u = np.linalg.norm(u) 19 # Compute the L2 norm of v (≈1 line) 20 norm_v = np.linalg.norm(v) 21 # Compute the cosine similarity defined by formula (1) (≈1 line) 22 cosine_similarity = numerator/(norm_u*norm_v) 23 ### END CODE HERE ### 24 25 return cosine_similarity
测试一下:
1 father = word_to_vec_map["father"] 2 mother = word_to_vec_map["mother"] 3 ball = word_to_vec_map["ball"] 4 crocodile = word_to_vec_map["crocodile"] 5 france = word_to_vec_map["france"] 6 italy = word_to_vec_map["italy"] 7 paris = word_to_vec_map["paris"] 8 rome = word_to_vec_map["rome"] 9 10 print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother)) 11 print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile)) 12 print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))
cosine_similarity(father, mother) = 0.890903844289
cosine_similarity(ball, crocodile) = 0.274392462614
cosine_similarity(france - paris, rome - italy) = -0.675147930817
2.词类类比
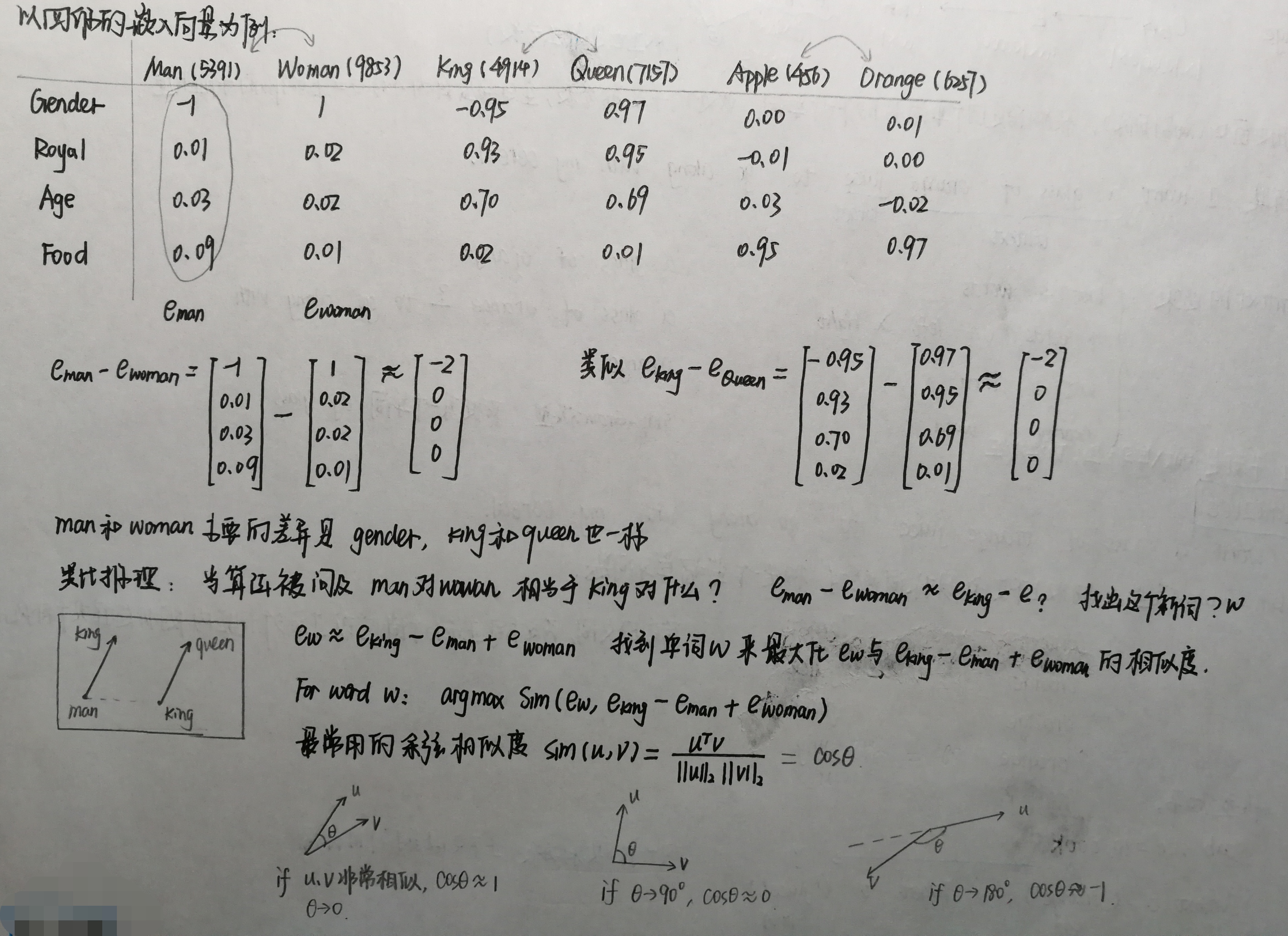
1 def complete_analogy(word_a, word_b, word_c, word_to_vec_map): 2 """ 3 Performs the word analogy task as explained above: a is to b as c is to ____. 4 5 Arguments: 6 word_a -- a word, string 7 word_b -- a word, string 8 word_c -- a word, string 9 word_to_vec_map -- dictionary that maps words to their corresponding vectors. 10 11 Returns: 12 best_word -- the word such that v_b - v_a is close to v_best_word - v_c, as measured by cosine similarity 13 """ 14 # convert words to lower case 15 word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower() 16 17 ### START CODE HERE ### 18 # Get the word embeddings v_a, v_b and v_c (≈1-3 lines) 19 e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c] 20 ### END CODE HERE ### 21 22 words = word_to_vec_map.keys() 23 max_cosine_sim = -100 # Initialize max_cosine_sim to a large negative number 24 best_word = None # Initialize best_word with None, it will help keep track of the word to output 25 26 # loop over the whole word vector set 27 for w in words: 28 # to avoid best_word being one of the input words, pass on them. 29 if w in [word_a, word_b, word_c] : 30 continue 31 32 ### START CODE HERE ### 33 # Compute cosine similarity between the vector (e_b - e_a) and the vector ((w's vector representation) - e_c) (≈1 line) 34 cosine_sim = cosine_similarity((e_b-e_a), (word_to_vec_map[w]-e_c)) 35 # If the cosine_sim is more than the max_cosine_sim seen so far, 36 # then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word (≈3 lines) 37 if cosine_sim > max_cosine_sim: 38 max_cosine_sim = cosine_sim 39 best_word = w 40 ### END CODE HERE ### 41 42 return best_word
测试一下:
1 triads_to_try = [('italy', 'italian', 'spain'), ('india', 'delhi', 'japan'), ('man', 'woman', 'boy'), ('small', 'smaller', 'large')] 2 for triad in triads_to_try: 3 print ('{} -> {} :: {} -> {}'.format( *triad, complete_analogy(*triad,word_to_vec_map)))
italy -> italian :: spain -> spanish
india -> delhi :: japan -> tokyo
man -> woman :: boy -> girl
small -> smaller :: large -> larger
3.去除词向量中的偏见
首先看一下 GloVe词嵌入如何关联性别的,你将计算一个向量 g=ewoman−eman,ewoman代表woman的词向量,eman代表man的词向量,得到的结果 g 粗略的包含性别这一概念。
1 g = word_to_vec_map['woman'] - word_to_vec_map['man'] 2 print(g)
结果:
1 [-0.087144 0.2182 -0.40986 -0.03922 -0.1032 0.94165 2 -0.06042 0.32988 0.46144 -0.35962 0.31102 -0.86824 3 0.96006 0.01073 0.24337 0.08193 -1.02722 -0.21122 4 0.695044 -0.00222 0.29106 0.5053 -0.099454 0.40445 5 0.30181 0.1355 -0.0606 -0.07131 -0.19245 -0.06115 6 -0.3204 0.07165 -0.13337 -0.25068714 -0.14293 -0.224957 7 -0.149 0.048882 0.12191 -0.27362 -0.165476 -0.20426 8 0.54376 -0.271425 -0.10245 -0.32108 0.2516 -0.33455 9 -0.04371 0.01258 ]
现在考虑不同单词与g的余弦相似度,考虑相似度的正值与相似度的负值之间的关系。
1 # girls and boys name 2 name_list = ['john', 'marie', 'sophie', 'ronaldo', 'priya', 'rahul', 'danielle', 'reza', 'katy', 'yasmin'] 3 4 for w in name_list: 5 print (w, cosine_similarity(word_to_vec_map[w], g))
结果女生名字和g的余弦相似度为正,而男生为负:
1 john -0.23163356146 2 marie 0.315597935396 3 sophie 0.318687898594 4 ronaldo -0.312447968503 5 priya 0.17632041839 6 rahul -0.169154710392 7 danielle 0.243932992163 8 reza -0.079304296722 9 katy 0.283106865957 10 yasmin 0.233138577679
看看其他词:
1 word_list = ['lipstick', 'guns', 'science', 'arts', 'literature', 'warrior','doctor', 'tree', 'receptionist', 2 'technology', 'fashion', 'teacher', 'engineer', 'pilot', 'computer', 'singer'] 3 for w in word_list: 4 print (w, cosine_similarity(word_to_vec_map[w], g))
结果:
1 lipstick 0.276919162564 2 guns -0.18884855679 3 science -0.0608290654093 4 arts 0.00818931238588 5 literature 0.0647250443346 6 warrior -0.209201646411 7 doctor 0.118952894109 8 tree -0.0708939917548 9 receptionist 0.330779417506 10 technology -0.131937324476 11 fashion 0.0356389462577 12 teacher 0.179209234318 13 engineer -0.0803928049452 14 pilot 0.00107644989919 15 computer -0.103303588739 16 singer 0.185005181365
“computer”接近“man”,“literature ”接近“woman”,这些都是不对的观念,应该减少这些偏差。
而对于grandfather与grandmother,actor与actress这些词本身具有性别偏差,应该均衡性别词。
整体步骤:

3.1中和与性别无关的词汇偏差

1 def neutralize(word, g, word_to_vec_map): 2 """ 3 Removes the bias of "word" by projecting it on the space orthogonal to the bias axis. 4 This function ensures that gender neutral words are zero in the gender subspace. 5 6 Arguments: 7 word -- string indicating the word to debias 8 g -- numpy-array of shape (50,), corresponding to the bias axis (such as gender) 9 word_to_vec_map -- dictionary mapping words to their corresponding vectors. 10 11 Returns: 12 e_debiased -- neutralized word vector representation of the input "word" 13 """ 14 ### START CODE HERE ### 15 # Select word vector representation of "word". Use word_to_vec_map. (≈ 1 line) 16 e = word_to_vec_map[word] 17 18 # Compute e_biascomponent using the formula give above. (≈ 1 line) 19 e_biascomponent = np.divide(np.dot(e,g), np.square(np.linalg.norm(g))) * g 20 21 # Neutralize e by substracting e_biascomponent from it 22 # e_debiased should be equal to its orthogonal projection. (≈ 1 line) 23 e_debiased = e - e_biascomponent 24 ### END CODE HERE ### 25 26 return e_debiased
测试一下:
1 e = "receptionist" 2 print("cosine similarity between " + e + " and g, before neutralizing: ", cosine_similarity(word_to_vec_map[e], g)) 3 4 e_debiased = neutralize("receptionist", g, word_to_vec_map) 5 print("cosine similarity between " + e + " and g, after neutralizing: ", cosine_similarity(e_debiased, g))
cosine similarity between receptionist and g, before neutralizing: 0.330779417506
cosine similarity between receptionist and g, after neutralizing: 1.16820646645e-17
中和之后,g和e的余弦相似度接近于0,
3.2性别词的均衡算法
将grandmother和grandfather这种性别对立的词移至与中间轴线等距的一对点上。
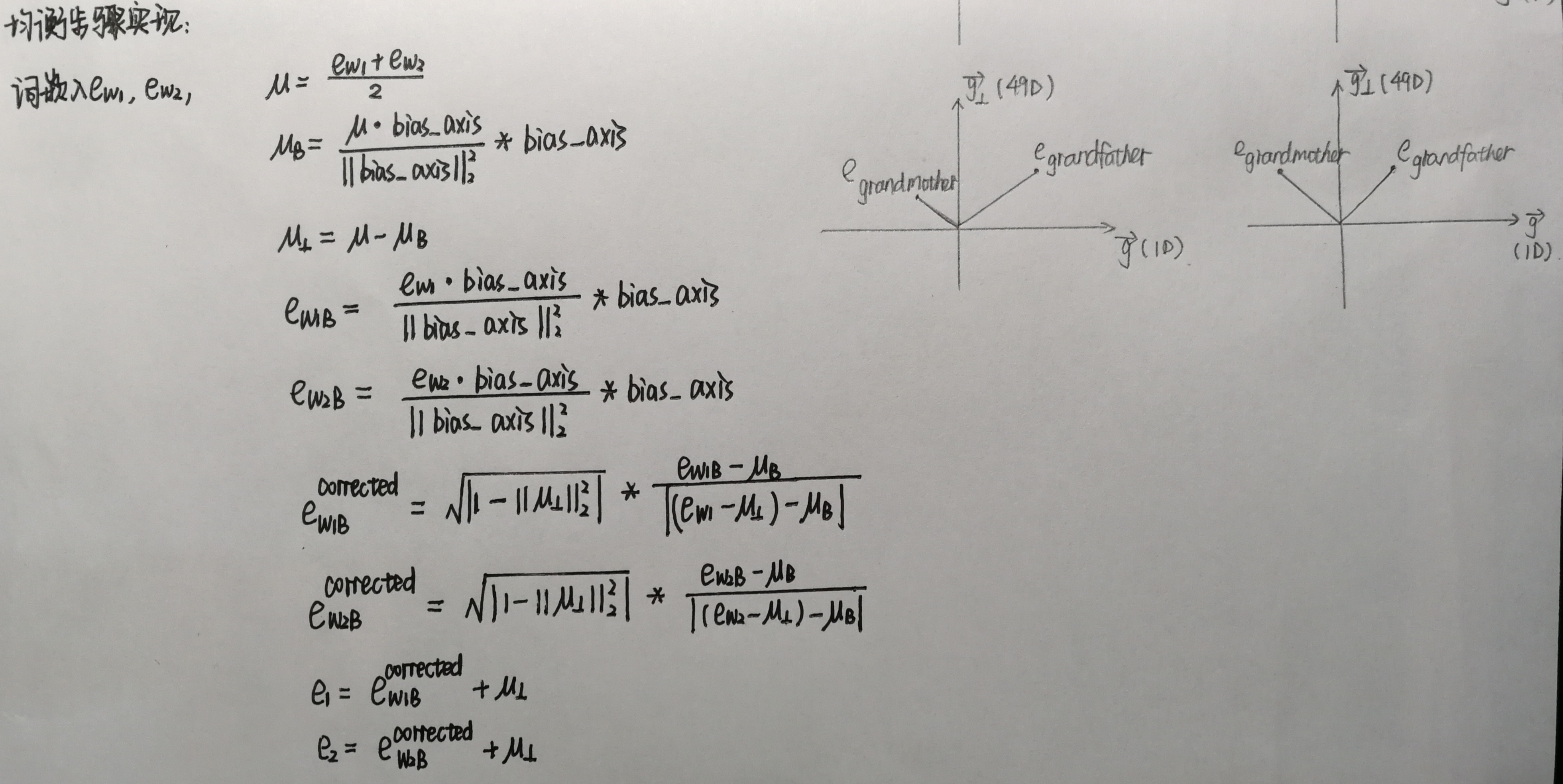
1 def equalize(pair, bias_axis, word_to_vec_map): 2 """ 3 Debias gender specific words by following the equalize method described in the figure above. 4 5 Arguments: 6 pair -- pair of strings of gender specific words to debias, e.g. ("actress", "actor") 7 bias_axis -- numpy-array of shape (50,), vector corresponding to the bias axis, e.g. gender 8 word_to_vec_map -- dictionary mapping words to their corresponding vectors 9 10 Returns 11 e_1 -- word vector corresponding to the first word 12 e_2 -- word vector corresponding to the second word 13 """ 14 ### START CODE HERE ### 15 # Step 1: Select word vector representation of "word". Use word_to_vec_map. (≈ 2 lines) 16 w1, w2 = pair[0], pair[1] 17 e_w1, e_w2 = word_to_vec_map[w1], word_to_vec_map[w2] 18 19 # Step 2: Compute the mean of e_w1 and e_w2 (≈ 1 line) 20 mu = (e_w1 + e_w2)/2 21 22 # Step 3: Compute the projections of mu over the bias axis and the orthogonal axis (≈ 2 lines) 23 mu_B = np.divide(np.dot(mu,bias_axis), np.square(np.linalg.norm(bias_axis))) * bias_axis 24 mu_orth = mu-mu_B 25 26 # Step 4: Use equations (7) and (8) to compute e_w1B and e_w2B (≈2 lines) 27 e_w1B = np.divide(np.dot(e_w1,bias_axis), np.square(np.linalg.norm(bias_axis))) * bias_axis 28 e_w2B = np.divide(np.dot(e_w2,bias_axis), np.square(np.linalg.norm(bias_axis))) * bias_axis 29 30 # Step 5: Adjust the Bias part of e_w1B and e_w2B using the formulas (9) and (10) given above (≈2 lines) 31 corrected_e_w1B = np.sqrt(np.abs(1-np.square(np.linalg.norm(mu_orth)))) * np.divide((e_w1B-mu_B),np.abs(e_w1-mu_orth-mu_B)) 32 corrected_e_w2B = np.sqrt(np.abs(1-np.square(np.linalg.norm(mu_orth)))) * np.divide((e_w2B-mu_B),np.abs(e_w2-mu_orth-mu_B)) 33 # Step 6: Debias by equalizing e1 and e2 to the sum of their corrected projections (≈2 lines) 34 e1 = corrected_e_w1B + mu_orth 35 e2 = corrected_e_w2B + mu_orth 36 ### END CODE HERE ### 37 38 return e1, e2
测试一下:
1 print("cosine similarities before equalizing:") 2 print("cosine_similarity(word_to_vec_map["man"], gender) = ", cosine_similarity(word_to_vec_map["man"], g)) 3 print("cosine_similarity(word_to_vec_map["woman"], gender) = ", cosine_similarity(word_to_vec_map["woman"], g)) 4 print() 5 e1, e2 = equalize(("man", "woman"), g, word_to_vec_map) 6 print("cosine similarities after equalizing:") 7 print("cosine_similarity(e1, gender) = ", cosine_similarity(e1, g)) 8 print("cosine_similarity(e2, gender) = ", cosine_similarity(e2, g))
cosine similarities before equalizing:
cosine_similarity(word_to_vec_map["man"], gender) = -0.117110957653
cosine_similarity(word_to_vec_map["woman"], gender) = 0.356666188463
cosine similarities after equalizing:
cosine_similarity(e1, gender) = -0.716572752584
cosine_similarity(e2, gender) = 0.739659647493