1.最小二乘法
手工推导使损失函数最小的参数a和b:

2.简单线性回归的实现
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 x=np.array([1.,2.,3.,4.,5.]) 5 y=np.array([1.,3.,2.,3.,5.]) 6 7 #根据公式计算参数a和b 8 x_mean,y_mean=np.mean(x),np.mean(y) 9 num=0.0 10 d=0.0 11 for x_i,y_i in zip(x,y): 12 num+=(x_i-x_mean)*(y_i-y_mean) 13 d+=(x_i-x_mean)**2 14 a=num/d 15 b=y_mean-a*x_mean 16 print(a,b) 17 18 #根据a和b,画出直线 19 y_hat=a*x+b 20 plt.scatter(x,y) 21 plt.plot(x,y_hat,color='r') 22 plt.axis([0,6,0,6]) 23 plt.show() 24 25 x_predict=6 26 y_predict=a*x_predict+b 27 print(y_predict)

3.向量化
把上面用for循环求解a和b的过程转换成向量的相乘,速度会快得多。
1 x_mean,y_mean=np.mean(x),np.mean(y) 2 a=(x-x_mean).dot(y-y_mean)/(x-x_mean).dot(x-x_mean) 3 b=y_mean-a*x_mean
4.衡量线性回归的的性能
此衡量标准和m相关,通常需要除以m。
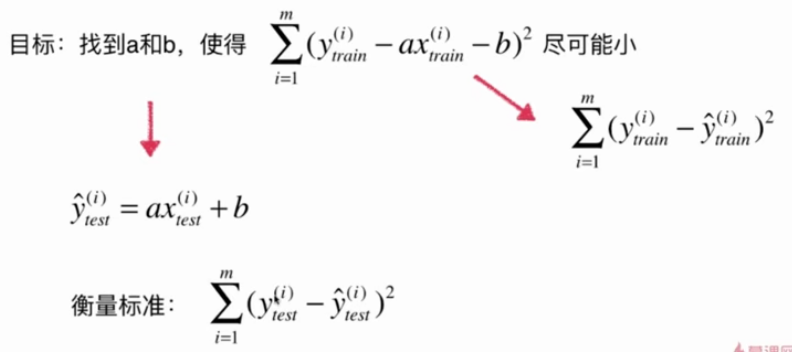
均方误差MSE:

均方根误差RMSE:(量纲和y的量纲一致)
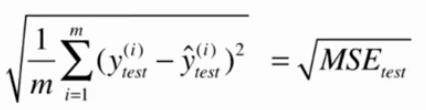
平均绝对误差MAE:
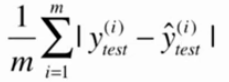
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import datasets 4 5 #波士顿房产数据 6 boston=datasets.load_boston() 7 print(boston.feature_names) 8 9 x=boston.data[:,5] #只使用房间数这一特征 (506,) 10 y=boston.target #(506,) 11 12 x=x[y<50.0] #去除掉采集样本拥有的上限点 13 y=y[y<50.0] 14 15 from sklearn.model_selection import train_test_split 16 x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666) #x_train(392,) x_test(98,) 17 18 #调用手动编写的简单线性回归算法(本质和上面一样) 19 from playML.SimpleLinearRegression import SimpleLinearRegression 20 reg=SimpleLinearRegression() 21 reg.fit(x_train,y_train) 22 23 plt.scatter(x_train,y_train) 24 plt.plot(x_train,reg.predict(x_train),color='r') 25 plt.show() 26 27 y_predict=reg.predict(x_test) 28 29 #手动计算MSE 30 mse_test=np.sum((y_predict-y_test)**2/len(y_test)) 31 print(mse_test) 32 #调用库计算MSE 33 from sklearn.metrics import mean_squared_error 34 print(mean_squared_error(y_test, y_predict)) 35 36 #计算RMSE 37 from math import sqrt 38 rmse_test=sqrt(mse_test) 39 print(rmse_test) 40 41 #手动计算MAE 42 mae_test=np.sum(np.absolute(y_predict-y_test)/len(y_test)) 43 print(mae_test) 44 #调用库计算MAE 45 from sklearn.metrics import mean_absolute_error 46 print(mean_absolute_error(y_test, y_predict))
相比分类问题(可以用准确度来衡量,且0最差,1最好),回归问题针对不同的问题,评估出的数据会相差很大,所以引出R方。
R方(R Squared)

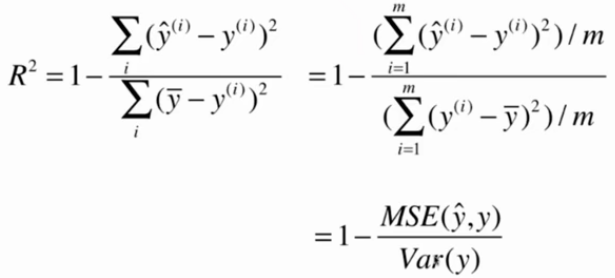
分子描述的是使用我们的模型预测产生的错误
分母描述的是使用y=y的平均值预测产生的错误(Baseline Model)

1 #接着上面的代码 2 #手动计算R方 3 print(1-mean_squared_error(y_test, y_predict)/np.var(y_test)) 4 #调用库计算R方 5 from sklearn.metrics import r2_score 6 print(r2_score(y_test, y_predict))
5.多元线性回归
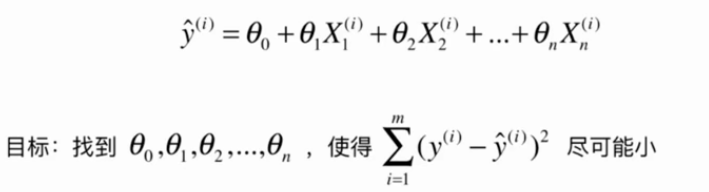
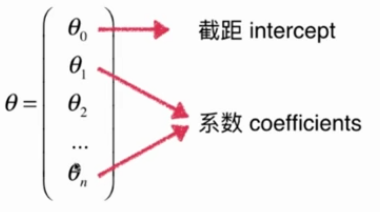
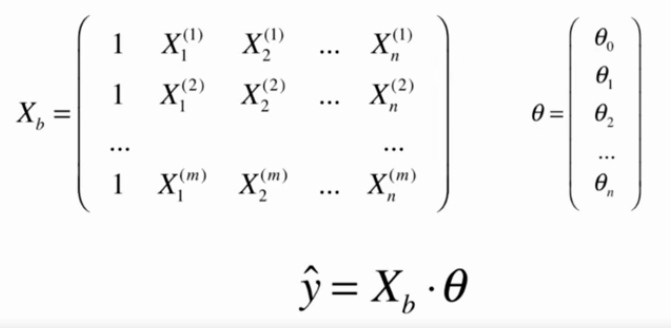
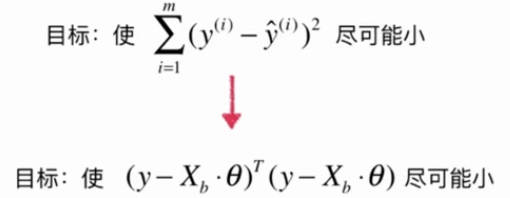
多元线性回归的正规方程解:![]()
6.使用scikit-learn解决回归问题
1 import numpy as np 2 from sklearn import datasets 3 4 #波士顿房产数据 5 boston=datasets.load_boston() 6 7 X=boston.data 8 y=boston.target 9 10 X=X[y<50.0] #去除掉采集样本拥有的上限点 11 y=y[y<50.0] 12 13 from sklearn.model_selection import train_test_split 14 X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666) 15 16 from sklearn.linear_model import LinearRegression 17 lin_reg=LinearRegression() 18 lin_reg.fit(X_train,y_train) 19 print(lin_reg.coef_) #系数 20 print(lin_reg.intercept_) #截距 21 print(lin_reg.score(X_test, y_test))
7.使用KNN解决回归问题
import numpy as np from sklearn import datasets #波士顿房产数据 boston=datasets.load_boston() X=boston.data y=boston.target X=X[y<50.0] #去除掉采集样本拥有的上限点 y=y[y<50.0] from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666) from sklearn.neighbors import KNeighborsRegressor knn_reg=KNeighborsRegressor() knn_reg.fit(X_train,y_train) print(knn_reg.score(X_test,y_test)) from sklearn.model_selection import GridSearchCV param_grid=[ { 'weights':['uniform'], 'n_neighbors':[i for i in range(1,11)] }, { 'weights':['distance'], 'n_neighbors':[i for i in range(1,11)], 'p':[i for i in range(1,6)] } ] knn_reg=KNeighborsRegressor() grid_search=GridSearchCV(knn_reg, param_grid,n_jobs=-1,verbose=1) grid_search.fit(X_train,y_train) print(grid_search.best_params_) #查看最好的参数 print(grid_search.best_score_) #使用CV标准下的得分 print(grid_search.best_estimator_.score(X_test,y_test))