1.K近邻算法基础实例
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 raw_data_X=[[3.9,2.3], 5 [3.1,1.7], 6 [1.3,3.3], 7 [3.5,4.6], 8 [2.2,2.8], 9 [7.4,4.6], 10 [5.7,3.5], 11 [9.1,2.5], 12 [7.7,3.4], 13 [7.9,0.7]] 14 raw_data_y=[0,0,0,0,0,1,1,1,1,1] 15 16 X_train=np.array(raw_data_X) 17 y_train=np.array(raw_data_y) 18 19 x=np.array([8,3]) 20 21 plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g') 22 plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r') 23 plt.scatter(x[0],x[1],color='b') 24 plt.show() 25 26 #KNN过程 27 from math import sqrt 28 distances=[sqrt(np.sum((x_train-x)**2)) for x_train in X_train] 29 nearest=np.argsort(distances) #nearest得到与x从近到远的点的序号 30 k=6 31 topK_y=[y_train[i] for i in nearest[:k]] #topK_y得到最近的k个点所属的类别 32 33 from collections import Counter 34 votes=Counter(topK_y) #Counter({0:1,1:5}) 35 36 predict_y=votes.most_common(1)[0][0] #votes.most_common(1)=[(1,5)] 37 print(predict_y)
2.scikit-learn中的机器学习算法封装
机器学习算法一般过程:
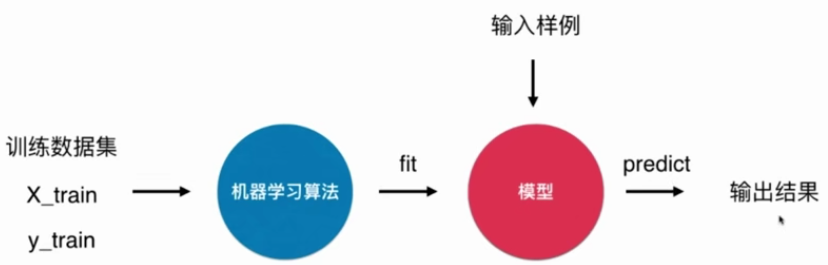
k近邻算法非常特殊,可以被认为是没有模型的算法,为了和其他算法统一,可以认为训练数据集就是算法本身。
1 import numpy as np 2 3 raw_data_X=[[3.9,2.3], 4 [3.1,1.7], 5 [1.3,3.3], 6 [3.5,4.6], 7 [2.2,2.8], 8 [7.4,4.6], 9 [5.7,3.5], 10 [9.1,2.5], 11 [7.7,3.4], 12 [7.9,0.7]] 13 raw_data_y=[0,0,0,0,0,1,1,1,1,1] 14 15 X_train=np.array(raw_data_X) 16 y_train=np.array(raw_data_y) 17 18 x=np.array([8,3]) 19 20 from sklearn.neighbors import KNeighborsClassifier 21 kNN_classifier=KNeighborsClassifier(n_neighbors=6) 22 kNN_classifier.fit(X_train,y_train) 23 X_predit=x.reshape(1,-1) #待预测的样本转化成矩阵形式 24 y_predit=kNN_classifier.predict(x) 25 print(y_predit[0])
3.训练数据集和测试数据集的拆分
利用鸢尾花数据集,将原本的数据集(150,4),拆分成训练集(120,4)和测试集(30,4)
且因为数据和标签是一一对应的,使用shuffle函数时要一起打乱。
1 import numpy as np 2 from sklearn import datasets 3 4 iris=datasets.load_iris() 5 X=iris.data #(150,4) 6 y=iris.target #(150,) 7 8 shuffle_indexes=np.random.permutation(len(X)) 9 test_ratio=0.2 10 test_size=int(len(X)*test_ratio) #规定测试集个数 11 12 test_indexes=shuffle_indexes[:test_size] #测试集索引 13 train_indexes=shuffle_indexes[test_size:] #训练集索引 14 15 16 X_train=X[train_indexes] #(120,4) 17 y_train=y[train_indexes] #(120,) 18 X_test=X[test_indexes] #(30,4) 19 y_test=y[test_indexes] #(30,)
或者直接调用sklearn中的train_test_split函数
1 from sklearn import datasets 2 iris=datasets.load_iris() 3 X=iris.data #(150,4) 4 y=iris.target #(150,) 5 6 #sklearn中调用拆分数据集 7 from sklearn.model_selection import train_test_split 8 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2) #random_state=666)随机种子,可以复现之前的额结果 9 10 from sklearn.neighbors import KNeighborsClassifier 11 kNN_classifier=KNeighborsClassifier(n_neighbors=3) 12 kNN_classifier.fit(X_train,y_train) 13 14 y_predit=kNN_classifier.predict(X_test) 15 print(sum(y_predit==y_test)/len(y_test)) #预测准确率
4.分类准确度
利用手写数字识别数据集,不同方法计算分类的准确率
1 import numpy as np 2 import matplotlib 3 import matplotlib.pyplot as plt 4 from sklearn import datasets 5 6 digits=datasets.load_digits() 7 X=digits.data #(1797,64) 8 y=digits.target #(1797,) 9 10 some_digit=X[666] #显示某个数字 11 some_digit_image=some_digit.reshape(8,8) 12 plt.imshow(some_digit_image,cmap=matplotlib.cm.binary) 13 plt.show() 14 15 #拆分数据集 16 from sklearn.model_selection import train_test_split 17 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) 18 19 #训练数据集 20 from sklearn.neighbors import KNeighborsClassifier 21 knn_clf=KNeighborsClassifier(n_neighbors=3) 22 knn_clf.fit(X_train,y_train) 23 24 #方法一:手动计算准确率 25 y_predict=knn_clf.predict(X_test) 26 print(sum(y_predict==y_test)/len(y_test)) 27 28 #方法二:调用sklearn(需要计算预测值) 29 y_predict=knn_clf.predict(X_test) 30 from sklearn.metrics import accuracy_score 31 print(accuracy_score(y_test, y_predict)) 32 33 #方法三:调用sklearn(不用计算预测值) 34 print(knn_clf.score(X_test, y_test))
5.超参数
超参数:运行之前需要确定的参数。(egKNN中的参数k)
模型参数:算法过程中学习的参数。
超参数1:k
利用手写数字识别数据集,进行调参,找出最好的k。
1 from sklearn import datasets 2 3 digits=datasets.load_digits() 4 X=digits.data #(1797,64) 5 y=digits.target #(1797,) 6 7 #拆分数据集 8 from sklearn.model_selection import train_test_split 9 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) 10 11 from sklearn.neighbors import KNeighborsClassifier 12 best_score=0.0 13 best_k=-1 14 for k in range(1,11): 15 knn_clf=KNeighborsClassifier(n_neighbors=k) 16 knn_clf.fit(X_train,y_train) 17 score=knn_clf.score(X_test, y_test) 18 if score>best_score: 19 best_k=k 20 best_score=score 21 print('best_k=',best_k) 22 print('best_score=',best_score)
如果上面的搜索结果best_k=10,作为边界值,需要扩大范围,继续搜索两边。
超参数2:权重
考虑距离权重(以距离的倒数作为权重,距离越近的权重越大,距离越远的权重越小)可以解决平票问题。

KNeighborsClassifier中的参数weights='uniform'时,不考虑权重,distance时要考虑权重。
1 from sklearn import datasets 2 3 digits=datasets.load_digits() 4 X=digits.data #(1797,64) 5 y=digits.target #(1797,) 6 7 #拆分数据集 8 from sklearn.model_selection import train_test_split 9 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) 10 11 #确定最好的k和method 12 from sklearn.neighbors import KNeighborsClassifier 13 best_method='' 14 best_score=0.0 15 best_k=-1 16 for method in ['uniform','distance']: 17 for k in range(1,11): 18 knn_clf=KNeighborsClassifier(n_neighbors=k,weights=method) 19 knn_clf.fit(X_train,y_train) 20 score=knn_clf.score(X_test, y_test) 21 if score>best_score: 22 best_k=k 23 best_score=score 24 best_method=method 25 print('best_method=',best_method) 26 print('best_k=',best_k) 27 print('best_score=',best_score)
超参数3:距离
距离包括欧拉距离(默认)、曼哈顿距离
明可夫斯基距离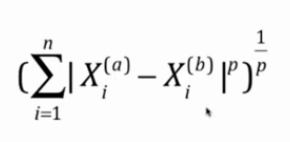
p=1时为曼哈顿距离;p=2时为欧拉距离。
KNeighborsClassifier中的参数p,p就是明可夫斯基中的p。p只有在weights='distance'才有意义。
from sklearn import datasets digits=datasets.load_digits() X=digits.data #(1797,64) y=digits.target #(1797,) #拆分数据集 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) #确定最好的p from sklearn.neighbors import KNeighborsClassifier best_p=-1 best_score=0.0 best_k=-1 for k in range(1,11): for p in range(1,6): knn_clf=KNeighborsClassifier(n_neighbors=k,weights='distance',p=p) knn_clf.fit(X_train,y_train) score=knn_clf.score(X_test, y_test) if score>best_score: best_k=k best_score=score best_p=p print('best_p=',best_p) print('best_k=',best_k) print('best_score=',best_score)
6.网格搜索Grid Search
cv即交叉验证。
1 from sklearn import datasets 2 3 digits=datasets.load_digits() 4 X=digits.data #(1797,64) 5 y=digits.target #(1797,) 6 7 #拆分数据集 8 from sklearn.model_selection import train_test_split 9 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) 10 11 #网格搜索 12 param_grid=[ 13 { 14 'weights':['uniform'], 15 'n_neighbors':[i for i in range(1,11)] 16 }, 17 { 18 'weights':['distance'], 19 'n_neighbors':[i for i in range(1,11)], 20 'p':[i for i in range(1,6)] 21 } 22 ] 23 from sklearn.neighbors import KNeighborsClassifier 24 knn_clf=KNeighborsClassifier() 25 26 from sklearn.model_selection import GridSearchCV 27 grid_search=GridSearchCV(knn_clf, param_grid) 28 29 grid_search.fit(X_train,y_train) 30 print(grid_search.best_estimator_) #显示全部最佳参数组合 31 print(grid_search.best_score_) #准确度 32 print(grid_search.best_params_) #显示我们给定的参数的最佳组合 33 knn_clf=grid_search.best_estimator_ 34 knn_clf.score(X_test,y_test)
GridSearchCV更多参数
- n_jobs:默认为1,单核;等于-1时,全部核用来网格搜索
- verbose:不同的值相应的搜索输出不一样,通常为2
更多距离定义:向量空间余弦相似度、调整余弦相似度、皮尔森相关系数、Jaccard系数
7.数据归一化(Feature Scaling)
将所有的数据映射到同一尺度
- 最值归一化(normalization):把所有数据映射到0-1之间,适用于数据分布有明显边界的情况,受outliner影响较大。

- 均值方差归一化(standardization):把所有数据归一到均值为0,方差为1的分布中。适用于数据分布没有明显边界,有可能存在极端数据值。
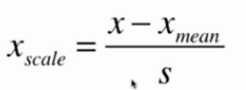
1 #最值归一化(一维) 2 import numpy as np 3 x=np.random.randint(0,100,size=100) 4 print((x-np.min(x))/(np.max(x)-np.min(x))) 5 6 #最值归一化(二维) 7 X=np.random.randint(0,100,(50,2)) 8 X=np.array(X,dtype=float) 9 #如果有n列,使用for循环实现 10 X[:,0]=(X[:,0]-np.min(X[:,0]))/(np.max(X[:,0])-np.min(X[:,0])) 11 X[:,1]=(X[:,1]-np.min(X[:,1]))/(np.max(X[:,1])-np.min(X[:,1])) 12 13 #均值方差归一化 14 X2=np.random.randint(0,100,(50,2)) 15 X2=np.array(X,dtype=float) 16 X2[:,0]=(X2[:,0]-np.mean(X2[:,0]))/np.std(X2[:,0]) 17 X2[:,1]=(X2[:,1]-np.mean(X2[:,1]))/np.std(X2[:,1])
8.scikit-learn中的Scaler
对测试数据集如何归一化?
使用训练数据集得出的mean_train和std_train进行计算
原因:测试数据集是模拟真实环境的,但真实环境可能无法得到所有测试数据的均值和方差
1 from sklearn import datasets 2 3 iris=datasets.load_iris() 4 X=iris.data 5 y=iris.target 6 7 from sklearn.model_selection import train_test_split 8 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) 9 10 from sklearn.preprocessing import StandardScaler 11 standardScaler=StandardScaler() 12 standardScaler.fit(X_train) 13 14 X_train=standardScaler.transform(X_train) #训练集归一化 15 X_test_standard=standardScaler.transform(X_test) #测试集归一化 16 17 from sklearn.neighbors import KNeighborsClassifier 18 knn_clf=KNeighborsClassifier(n_neighbors=3) 19 knn_clf.fit(X_train, y_train) 20 print(knn_clf.score(X_test_standard,y_test)) #如果训练集进行了归一化,那测试集也需要归一化,同步的