上次回归:
上次我们主要说了,我们的注册中心nacos的使用,如我们的命名空间、分组、集群、版本等是如何使用的,如果是这样呢?我们现在有三个用户服务和三个订单服务,我们应该如何分发这些请求呢?都请求到一个服务?轮询?权重?这次我们就来看一下我们的如何解决这些问题的。
本次主要内容:
本次我们主要来说ribbon的使用,还有ribbon是如何配置各个分发策略的,再就是我们怎么能自己实现我们的自己的分发策略。
客户端负载均衡:
nginx大家都很熟悉了,提到负载均衡,我们第一个想到的一定是nginx,他的反向代理很强大,内部可以实现轮询、权重、IP哈希、URL哈希几种算法来分发我们的请求,这个就是我们熟悉的负载均衡,也叫做服务端负载均衡。那么什么又是客户端的负载均衡呢?举个小栗子。我们去***高级会所,叫了一个按摩的,其实这个是由一个主管给你安排一个技师给你的,不是你自己来选择的,由主管安排的,我们可以理解为服务端负载均衡。
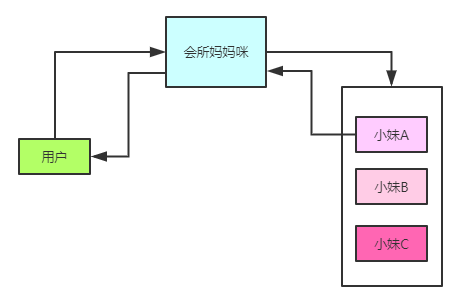
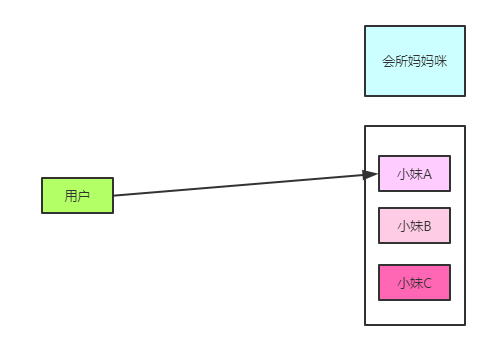
那么如果我们又去了***高级会所(由于常去,都熟悉哪个技师给力),又叫了一个按摩的,感觉上次的89号按的不错,手法娴熟,我们直接选取了我们的89号技师,并不是由主管安排的,是我们的一个自主选择,是我们在我们的心中选择了合适的人选给予按摩,这样的操作,我们可以理解为客户端负载均衡。
ribbon的使用:
ribbon在中间给给予我们一个选择的作用了,而且省去了很多的代码(相比上次博客的代码来说),我们先来看一个最简单的示例代码。
一、最简单的实现
①.加入我们的ribbon依赖包,我这直接放在的父工程下了。
<!-- 加入ribbon依赖包 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-ribbon</artifactId> </dependency>
②.改用户服务的config配置(调用方)。@LoadBalanced
package com.user.config; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.client.RestTemplate; @Configuration public class ClientConfig { @LoadBalanced @Bean public RestTemplate restTemplate() { return new RestTemplate(); } }
③.改用户服务(调用方)的调用方式,刚才我都提到了会简单很多代码,看一下到底简单了多少代码
package com.user.clintOrder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; @RestController public class UserController { @Autowired private RestTemplate restTemplate; @GetMapping("/getOrder") public String getOrderData(){ String forObject = restTemplate.getForObject("http://ribbon-order/getOrderData", String.class); System.out.println("forObject = " + forObject); return forObject; } }
④.启动订单服务(被调用方),启动用户服务(调用方)
OK,最简单的示例完成了。
二、内部算法
刚才我说到了ribbon可以做到客户端的负载均衡,现在我们只有一个服务体现不出来的啊,我们在多弄几个被调用端。很多小伙伴可能还不会IDEA同时启动多个服务,我这里顺便说一句,会的请无视。我们先启动一个订单服务,然后点击左上角的下拉选项,就是你运行程序,Debug程序,结束程序那里,然后点击Edit Configurations...,点开以后,勾选Allow parenel run就可以了,记得自己该程序的端口,要不会端口冲突。有的IDEA版本是勾选share即可。
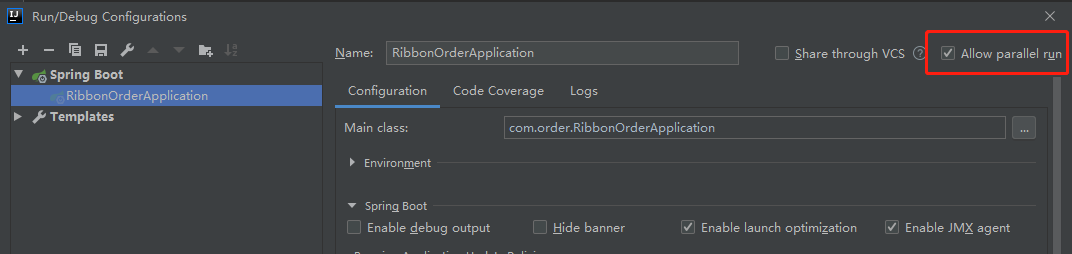
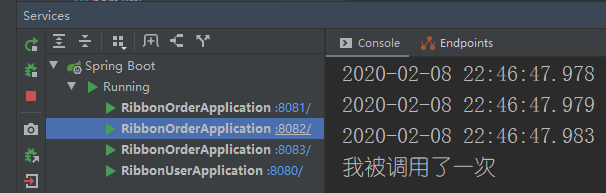
这次我们启动三个订单服务,然后看一下访问情况。第一次访问,调用了我们的8082端口的订单服务服务,第二次是我们的8083,第三次是我们的8081......可以看出来这个是一个轮询的规则来调用的。
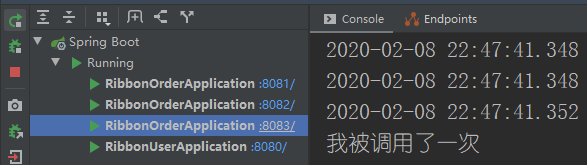
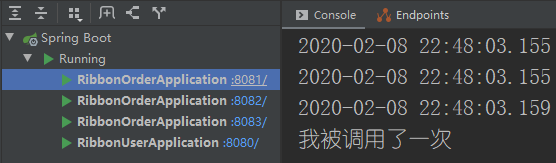
严格意义来说也不算是轮询的,如果你是亚马逊的服务器,你就不会体验的轮询了,我们接下来看一下都有什么算法。

我知道的有这7中算法。
①.RoundRobinRule 轮询选择, 轮询index,选择index对应位置的Server。轮询
②.ZoneAvoidanceRule(默认是这个),复合判断Server所在Zone的性能和Server的可用性选择Server,在没有Zone的情况下类是轮询。你在国内可以理解为轮询。轮询
③.RandomRule,随机选择一个Server)。随机
④.RetryRule,对选定的负载均衡策略机上重试机制,在一个配置时间段内当选择Server不成功, 则一直尝试使用subRule的方式选择一个可用的server.
⑤.AvailabilityFilteringRule,过滤掉一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的后端Server或者使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就就是检查status里记录的各个Server的运行状态
⑥.BestAvailableRule,选择一个最小的并发请求的Server,逐个考察Server,如果Server被tripped了,则跳过。并发
⑦.WeightedResponseTimeRule,根据响应时间加权,响应时间越长,权重越小,被选中的可能性越低。响应时间长短
那么这么多的算法,我们来如何配置呢?我们来改一下我们的config配置
package com.user.config; import com.netflix.loadbalancer.IRule; import com.netflix.loadbalancer.RandomRule; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.client.RestTemplate; @Configuration public class ClientConfig { @LoadBalanced @Bean public RestTemplate restTemplate() { return new RestTemplate(); } /** * 选择ribbon算法 * @return */ @Bean public IRule chooseAlgorithm(){ return new RandomRule(); } }
这样我们就更改了我们的默认算法,改为了随机选择的算法,我就不用上图给你们看测试结果了,我这测过了,好用~!我这是8081->8081->8081->8083->8082->8082,完全没有规律,是随机的。
三、细粒度配置
说到这还没完,我们来看一个需求,我们用户服务需要轮询调用积分服务,且需要随机调用订单服务,怎么来配置?我们下面来看一下如何细粒度的来配置。
首先我们在用户服务下面添加两个类,注意不要被spring扫描到。
package com.config; import com.netflix.loadbalancer.IRule; import com.netflix.loadbalancer.RoundRobinRule;public class IntegralConfig { /** * 选择积分服务算法 * @return */public IRule chooseAlgorithm(){ return new RoundRobinRule(); } }
package com.config; import com.netflix.loadbalancer.IRule; import com.netflix.loadbalancer.RandomRule; public class OrderConfig { /** * 选择订单服务算法 * @return */public IRule chooseAlgorithm(){ return new RandomRule(); } }
然后在我们的主配置类的加入注解,就是说我们的遇到ribbon-order服务调用OrderConfig类下面的算法,我们的遇到ribbon-logistics服务调用LogisticsConfig类下面的算法,
package com.user.config; import com.config.IntegralConfig; import com.config.OrderConfig; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.cloud.netflix.ribbon.RibbonClient; import org.springframework.cloud.netflix.ribbon.RibbonClients; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.client.RestTemplate; @Configuration @RibbonClients(value={ @RibbonClient(name="ribbon-order",configuration = OrderConfig.class), @RibbonClient(name="ribbon-integral",configuration = IntegralConfig.class) }) public class ClientConfig { @LoadBalanced @Bean public RestTemplate restTemplate() { return new RestTemplate(); } }
这是其中的一种配置,下面还有一种配置比较简单,在配置文件中加入算法就可以了,但是切记,不要两种同时使用,容易乱。
ribbon-order: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule ribbon-integral: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
我们先来实测一下我们的配置是否真的可用,先测试第一种注解+外部配置文件的,轮询积分服务,随机订单服务,我们先验证积分。第一次访问积分服务
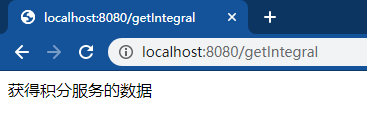

第二次访问积分服务
第三次访问积分服务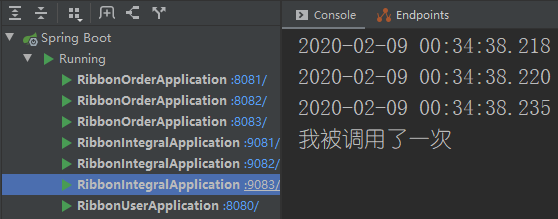
第四次访问积分服务
积分服务是轮询的,说明积分服务算法配置正确,我们再来看一下订单服务。第一访问订单服务

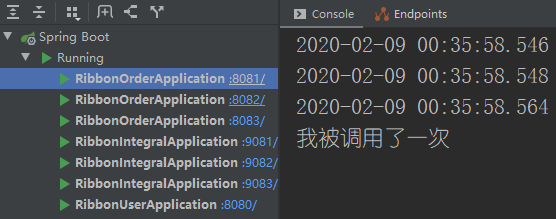
第二次访问订单服务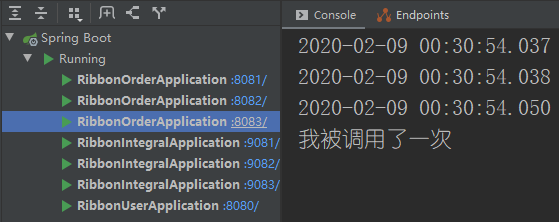
第三次访问订单服务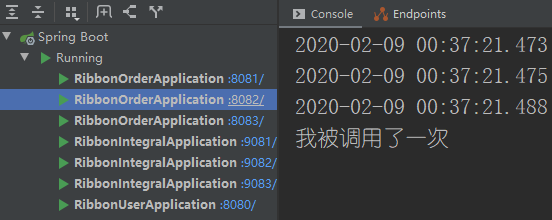
第四和第五次访问订单服务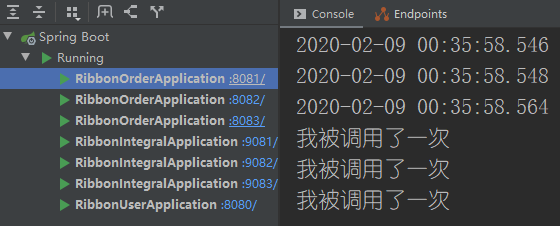
吓死我了,以为配置失败了呢,害得我第四次和第五次同时访问的,可以看出来12311这个顺序是一个随机的,我们再来验证一下我们的配置文件方式。
我们的订单服务的结果是:8083->8083->8083->8082->8082->8082->8082,可以看出来我们的订单是一个随机数。
我们的积分服务的结果是:9081->9082->9083->9081->9082->9083->9081,可以看出来我们的积分是一个轮询的算法。
这里我说到了两种配置,再次强调一次,强烈不建议两种配置同时使用,你会乱的,建议使用配置文件的方式(不需要考虑文件是否被spring扫描到的问题),其次使用外部配置文件,不让spring扫描到的方式。
四、ribbon参数解析
ribbon.MaxAutoRetries=1 #每一台服务器重试的次数,不包含首次调用的那一次
ribbon.MaxAutoRetriesNextServer=2 #重试的服务器的个数,不包含首次调用的那一台实例
ribbon.OkToRetryOnAllOperations=true #是否对所以的操作进行重试(True 的话,会对pos、 put操作进行重试,存在服务幂等问题) 没事别配置这个玩意,是个坑
ribbon.ConnectTimeout=3000 # 建立连接超时
ribbon.ReadTimeout=3000 # 读取数据超时
也可以为每个Ribbon客户端设置不同的超时时间, 通过服务名称进行指定:
ribbon-order.ribbon.ConnectTimeout=2000
ribbon-integral.ribbon.ReadTimeout=5000
详细地址http://c.biancheng.net/view/5356.html
开启饥饿加载,用来解决Ribbon第一次调用耗时高的配置
ribbon.eager-load.enabled=true #开启Ribbon的饥饿加载模式
ribbon.eager-load.clients=ribbon-order #指定需要饥饿加载的服务名
五、自定义规则策略(权重)
我们的ribbon并没有我们平时用的权重算法,所以我们还是需要自己来实现权重算法的,首先新建一个规则类,然后集成我们的AbstractLoadBalancerRule,重写我们的choose方法。
package com.user.myRule; import com.alibaba.cloud.nacos.NacosDiscoveryProperties; import com.alibaba.cloud.nacos.ribbon.NacosServer; import com.alibaba.nacos.api.exception.NacosException; import com.alibaba.nacos.api.naming.NamingService; import com.alibaba.nacos.api.naming.pojo.Instance; import com.netflix.client.config.IClientConfig; import com.netflix.loadbalancer.AbstractLoadBalancerRule; import com.netflix.loadbalancer.BaseLoadBalancer; import com.netflix.loadbalancer.Server; import org.springframework.beans.factory.annotation.Autowired; public class WeightedRule extends AbstractLoadBalancerRule { @Autowired private NacosDiscoveryProperties discoveryProperties; @Override public void initWithNiwsConfig(IClientConfig iClientConfig) { //读取配置文件并且初始化,ribbon内部的 几乎用不上 } @Override public Server choose(Object key) { try { BaseLoadBalancer baseLoadBalancer = (BaseLoadBalancer) this.getLoadBalancer(); //获取微服务的名称 String serviceName = baseLoadBalancer.getName(); //获取Nocas服务发现的相关组件API NamingService namingService = discoveryProperties.namingServiceInstance(); //获取 一个基于nacos client 实现权重的负载均衡算法 Instance instance = namingService.selectOneHealthyInstance(serviceName); //返回一个server return new NacosServer(instance); } catch (NacosException e) { System.out.println("自定义负载均衡算法错误"); e.printStackTrace(); } return null; } }
然后按照我们配置算法的方式来配置一下我们的自定义算法,首先写一个不会被spring扫描的类,在我们的配置中加入我们的注解,这次我们设置所有的服务都用我们的自定义算法
package com.config; import com.netflix.loadbalancer.IRule; import com.user.myRule.WeightedRule; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; public class WeightedConfig { /** * 选择权重算法 * @return */public IRule chooseAlgorithm(){ return new WeightedRule(); } }
@RibbonClients(defaultConfiguration = WeightedConfig.class)
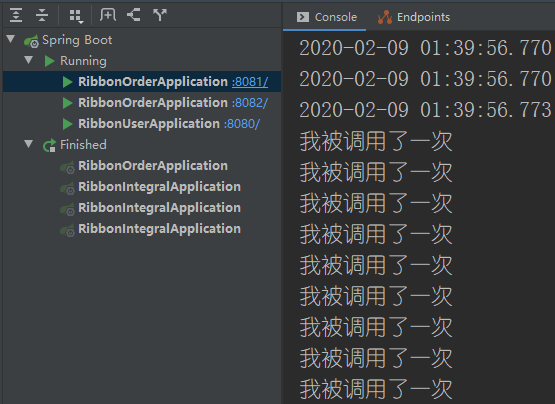
启动我们的订单服务,这次我启动了两个订单服务,打开我们的nacos页面,设置权重

从这个配置来看我们是几乎都是访问的8081这个服务的,我们来测试一下。我获取了10次,实际上也是有9次落到我们的8081的服务上
六、自定义算法,同集群优先
上次nacos我们留下了一个小问题,就是同一个集群的优先调用,需要我们自己来实现,上次没有说,今天说了ribbon,可以去说如何同集群优先调用了
package com.user.myRule; import com.alibaba.cloud.nacos.NacosDiscoveryProperties; import com.alibaba.cloud.nacos.ribbon.NacosServer; import com.alibaba.nacos.api.exception.NacosException; import com.alibaba.nacos.api.naming.NamingService; import com.alibaba.nacos.api.naming.pojo.Instance; import com.netflix.client.config.IClientConfig; import com.netflix.loadbalancer.AbstractLoadBalancerRule; import com.netflix.loadbalancer.BaseLoadBalancer; import com.netflix.loadbalancer.Server; import lombok.extern.slf4j.Slf4j; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.util.StringUtils; import java.util.ArrayList; import java.util.List; @Slf4j public class TheSameClusterPriorityRule extends AbstractLoadBalancerRule { public static final Logger log = LoggerFactory.getLogger(TheSameClusterPriorityRule.class); @Autowired private NacosDiscoveryProperties discoveryProperties; @Override public void initWithNiwsConfig(IClientConfig clientConfig) { } @Override public Server choose(Object key) { try { //第一步:获取当前服务所在的集群 String currentClusterName = discoveryProperties.getClusterName(); //第二步:获取一个负载均衡对象 BaseLoadBalancer baseLoadBalancer = (BaseLoadBalancer) getLoadBalancer(); //第三步:获取当前调用的微服务的名称 String invokedSerivceName = baseLoadBalancer.getName(); //第四步:获取nacos clinet的服务注册发现组件的api NamingService namingService = discoveryProperties.namingServiceInstance(); //第五步:获取所有的服务实例 List<Instance> allInstance = namingService.getAllInstances(invokedSerivceName); List<Instance> theSameClusterNameInstList = new ArrayList<>(); //第六步:过滤筛选同集群下的所有实例 for(Instance instance : allInstance) { if(StringUtils.endsWithIgnoreCase(instance.getClusterName(),currentClusterName)) { theSameClusterNameInstList.add(instance); } } Instance toBeChooseInstance ; //第七步:选择合适的一个实例调用 if(theSameClusterNameInstList.isEmpty()) { toBeChooseInstance = WeightedBalancer.chooseInstanceByRandomWeight(allInstance); System.out.println("发生跨集群调用"); log.info("发生跨集群调用--->当前微服务所在集群:{},被调用微服务所在集群:{},Host:{},Port:{}", currentClusterName,toBeChooseInstance.getClusterName(),toBeChooseInstance.getIp(),toBeChooseInstance.getPort()); }else { toBeChooseInstance = WeightedBalancer.chooseInstanceByRandomWeight(theSameClusterNameInstList); System.out.println("同集群调用"); log.info("同集群调用--->当前微服务所在集群:{},被调用微服务所在集群:{},Host:{},Port:{}", currentClusterName,toBeChooseInstance.getClusterName(),toBeChooseInstance.getIp(),toBeChooseInstance.getPort()); } return new NacosServer(toBeChooseInstance); } catch (NacosException e) { log.error("同集群优先权重负载均衡算法选择异常:{}",e); } return null; } }
总结:
本次博客主要说了我们的ribbon的使用,以及我们的内部算法也简单说了一遍,后面的源码博客会具体去说内部的实现,我们还定义了我们自己的算法。


最进弄了一个公众号,小菜技术,欢迎大家的加入
