作业12-流与文件
1.本周学习总结
1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容。
在Java中的java.io包中定义了许多类专门负责处理各种方式的输入与输出。其中,所有输入流类都是抽象类InputStream(字节输入流)或抽象类Reader(字符输入流)的子类,而所有输出流类都是抽象类OutputStream(字节输出流)或抽象类Writer(字符输出流)的子类。
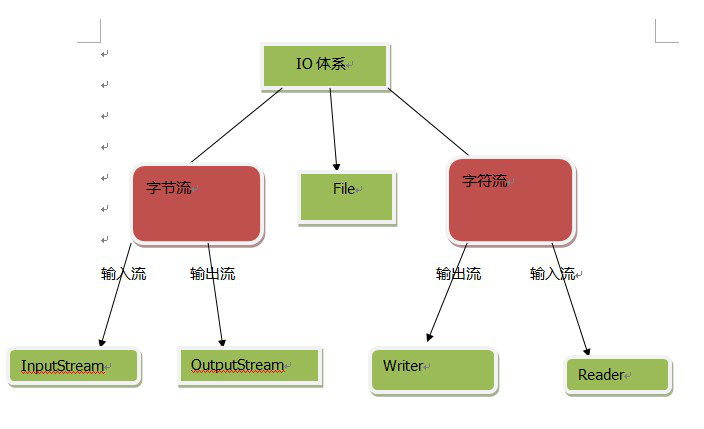
1.输入流
InputStream类的层次结构

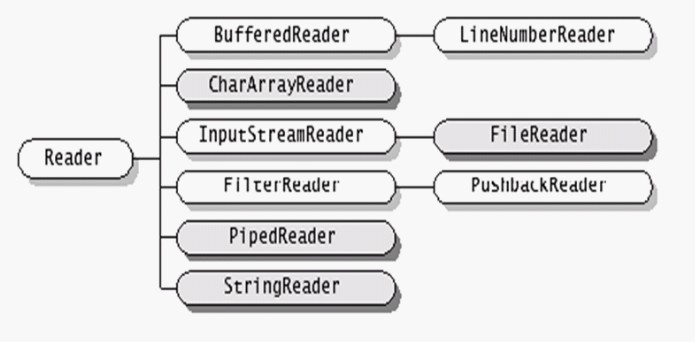
Reader类的层次结构
2.输出流
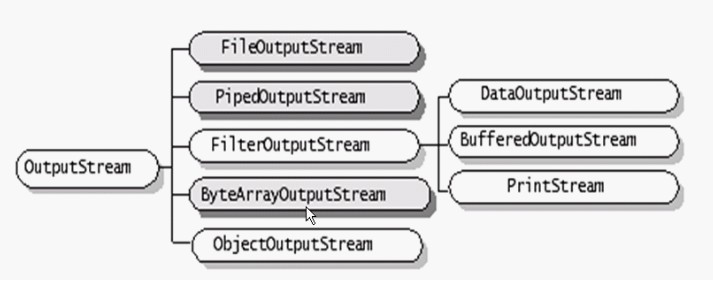
OutputStream类的层次结构
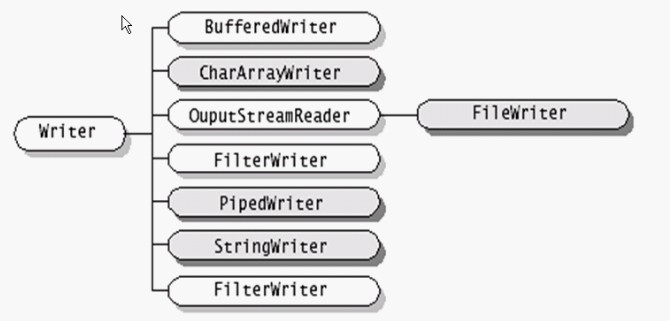
Writer类的层次结构
3.File类
File类是
java.io包中唯一代表磁盘文件本身的对象。File类定义了一些与平台无关的方法来操作文件,可以通过调用File类中的方法,实现创建、删除、重命名文件等操作。File类的对象主要用来获取文件本身的一些信息,如文件所在的目录、文件的长度、文件读写权限等。数据流可以将数据写入到文件中,文件也是数据流最常用的的数据媒体。
1.文件的创建
(1).New File(String pathname)
该构造方法通过将给定路径名字符串转换为抽象路径名来创建一个新的File实例
(2).new File(String parent,String child)
该构造方法根据定义的父路径和子路径字符串创建一个新的File对象
(3).new File(File f,String child)
该构造方法根据parent抽象路径名和child路径字符串创建一个新的File实例
2.获取文件信息
File类的常用方法
| 方法 | 返回值 | 说明 |
|---|---|---|
| getName() | String | 获取文件的名称 |
| canRead() | boolean | 判断文件是否是可读的 |
| canWrite() | boolean | 判断文件是否可被写入 |
| exits() | boolean | 判断文件是否存在 |
| length() | long | 获取文件长度 |
| getAbsoultePath() | String | 获取文件的绝对路径 |
| getParent() | String | 获取文件的父路径 |
| isFile() | boolean | 判断文件是否存在 |
| isDirectory() | boolean | 判断文件是否是一个目录 |
| isHidden() | boolean | 判断文件是否是隐藏文件 |
| lastModified() | long | 获取文件最后修改时间 |
2.面向系统综合设计-图书馆管理系统或购物车
使用流与文件改造你的图书馆管理系统或购物车。
2.1 简述如何使用流与文件改造你的系统。文件中数据的格式如何?
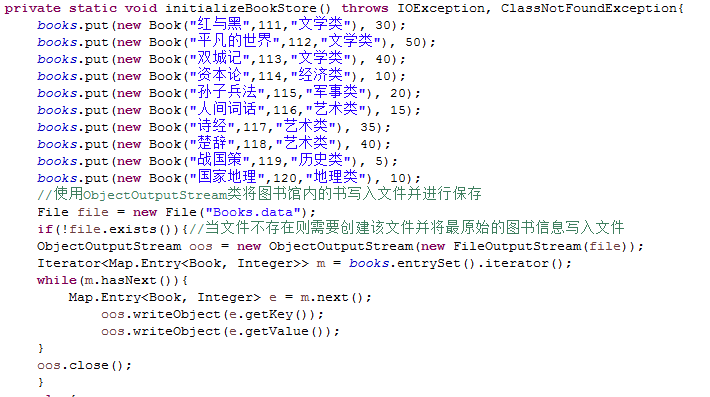
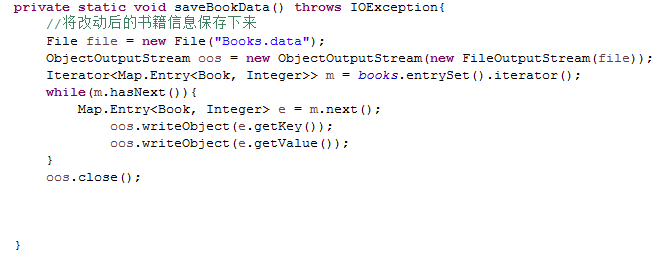
答:我在刚开始的时候先通过静态初始化块初始图书馆的数据然后将初始化后的图书数据使用对象流ObjectOutputStream写入文件Book.data进行保存,用户模块类似,然后在两个模块中各写一个保存修改后文件数据的方法用于存储操作过程中数据变化后的文件。用对象流写入文件是以十六进制保存的,因为对象流本来就是适合于网络之间的传输。
2.2 简述系统中文件读写部分使用了流与文件相关的什么接口与类?为什么要用这些接口与类?
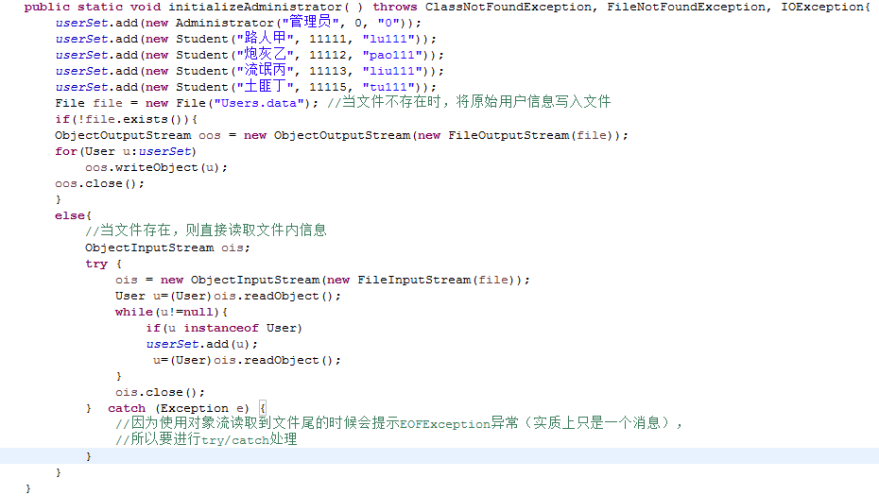
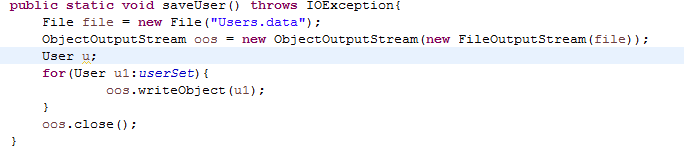
用到了InputStream、OutputStream接口下的ObjectInputStream和ObjectOutputStream子类,还有文件类File,在对对象进行序列化的时候还用到了Serializable接口,使用对象流是为了可以将一个对象的完整信息都存入文件,如果只是普通的字节字符流则没办法做到这点,然后使用对象流写入或读取对象时,要保证对象时序列化的,这是为了保证能把对象写入文件,并且从文件中正确读到程序中,这时候就要用到Serializable接口来实现对象的序列化。
2.3 截图读写文件相关代码。关键行需要加注释。
初始化Library:

保存修改后的Library文件:
初始化用户模块:
保存修改过后的用户信息保存到文件中:
选做:3. 尝试为计算机学院网站设计一个搜索引擎系统(组队完成)
一开始可以只用控制台,不一定要用Web。
3.1 系统大概分为几部分,每个部分要完成什么功能?
3.2 系统的整个工作流程是什么。各个部分之间的关系是什么。可尝画图描述。
3.3 为了完成该系统需要什么方面的知识?
3.代码量统计
3.1 统计本周完成的代码量
需要将每周的代码统计情况融合到一张表中。
似乎达到了第一周设置的目标(◦˙▽˙◦)
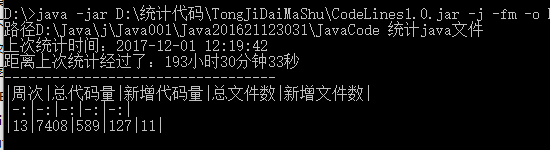
| 周次 | 总代码量 | 新增代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 2 | 607 | 607 | 15 | 15 |
| 3 | 1642 | 1035 | 33 | 18 |
| 5 | 2044 | 402 | 42 | 9 |
| 6 | 2874 | 830 | 57 | 15 |
| 7 | 3161 | 287 | 63 | 6 |
| 8 | 4299 | 1138 | 72 | 9 |
| 9 | 4831 | 532 | 81 | 9 |
| 10 | 5475 | 644 | 93 | 12 |
| 11 | 5958 | 483 | 102 | 9 |
| 12 | 6819 | 861 | 116 | 14 |
| 13 | 7408 | 589 | 127 | 11 |
选做:4. 流与文件学习指导(底下的作业内容全部都是选做)
1. 字符流与文本文件:使用 PrintWriter(写),BufferedReader(读)
将Student对象(属性:int id, String name,int age,double grade)写入文件student.data、从文件读出显示。
1.1 生成的三个学生对象,使用PrintWriter的println方法写入student.txt,每行一个学生,学生的每个属性之间用|作为分隔。使用Scanner或者BufferedReader将student.txt的数据读出。(截图关键代码,出现学号)
三个Student对象:

writeStudent方法:

使用BufferedReader方法读取student.txt

控制台输出以及记事本内容:
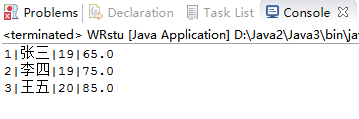
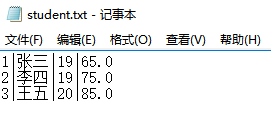
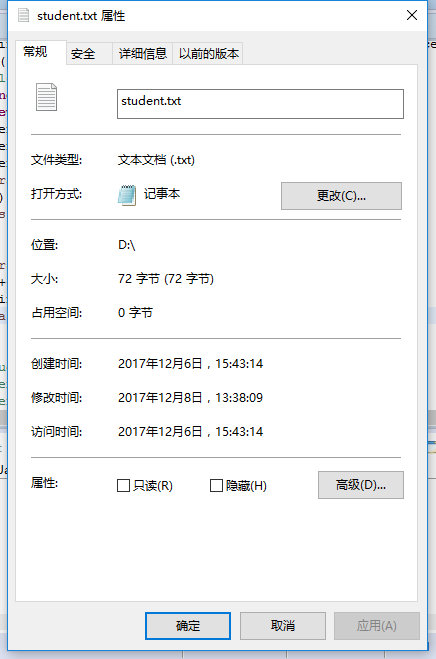
1.2 生成文件大小多少(使用右键文件属性查看)?分析该文件大小
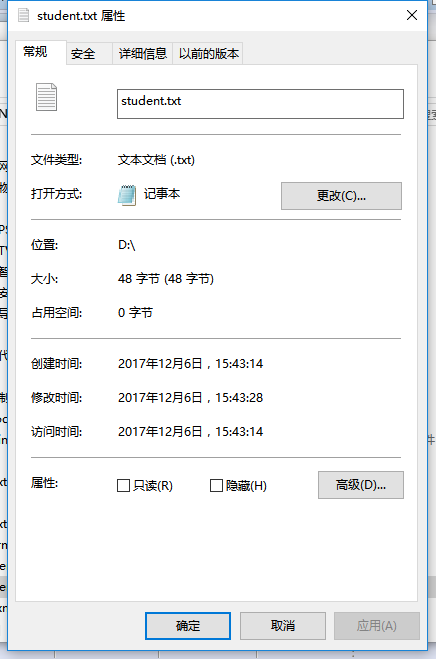
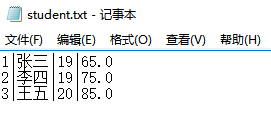
文件大小为48个字节,其中每个英文字符以及”|”占一个字节,每个中文字符占两个字节,换行符占两个字节,因此每一行为16个字节,三行总共48个字节。
1.3 如果调用PrintWriter的println方法,但在后面不close。文件大小是多少?为什么?
大小为0字节。
因为printWrite会将数据写到缓冲区内,在最后使用close进行关闭时,它会将缓冲区的内容送出来,所以当没有使用close进行关闭的时候,数据就会在缓冲区内丢失,因此如果在关闭前使用了flush方法将缓冲区的内容先送出来,还是可以将数据写入文件的。
2. 缓冲流
2.1 使用PrintWriter往文件里写入1千万行(随便什么内容都行),然后对比使用BufferedReader与使用Scanner从该文件中读取数据的速度(只读取,不输出),使用哪种方法快?截取测试源代码,出现学号。请详细分析原因?提示:可以使用junit4对比运行时间

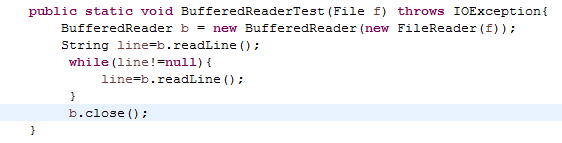
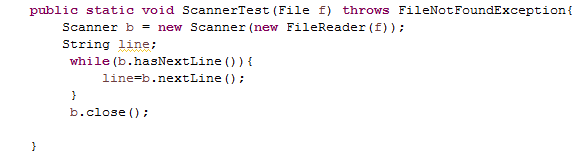
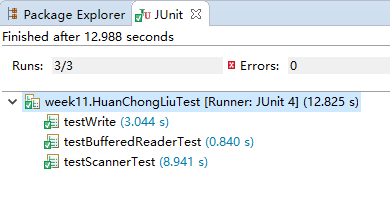
可以看出使用BufferedReader读取文件更快,这是因为Scanner会对输入数据进行类解析,而BufferedReader只是简单地读取字符序列。并且BufferedReader相对于Scanner有更大的缓冲区,可以进行更少的输入输出操作,因此会更快一些。
2.2 将PrintWriter换成BufferedWriter,观察写入文件的速度是否有提升。记录两者的运行时间。试分析原因。
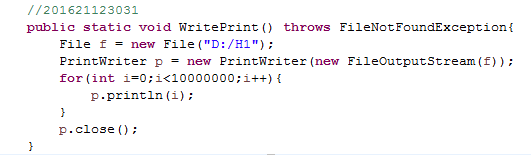
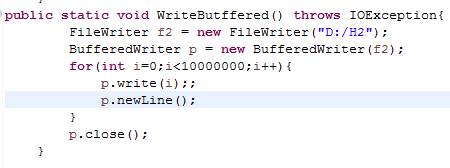
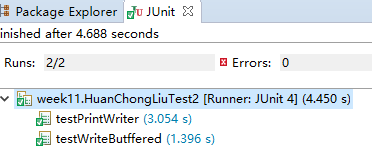
由上图可以看出,速度会有提升,这是因为BufferedWriter具有更大缓冲区的关系。
3. 字符编码
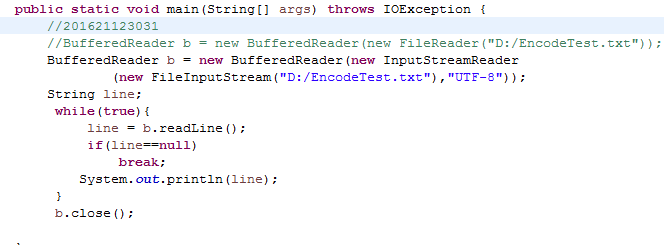
3.1 现有EncodeTest.txt 文件,包含一些中文,该文件使用UTF-8编码。使用FileReader与BufferedReader将EncodeTest.txt的文本读入并输出。是否有乱码?为什么会有乱码?如何解决?(截图关键代码,出现学号)
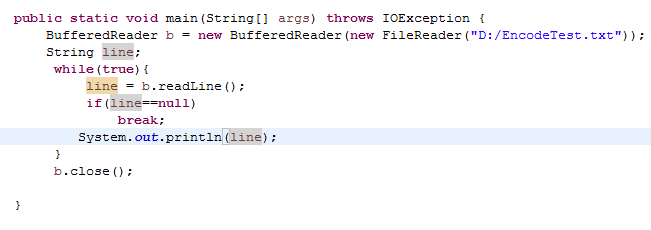
运行结果:
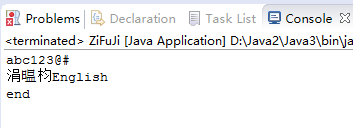
可以看出会产生乱码,这是因为FileReader继承自InputStreamReader,并利用它完成字节流到字符流的转换,而且在转换时采取的字符集为系统的默认字符集,即GBK。于是在UTF-8 -> GBK -> UTF-8的过程中编码出现损失,导致其出现了乱码。解决方法如下:
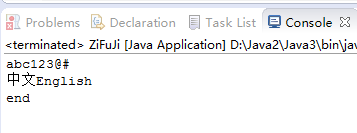
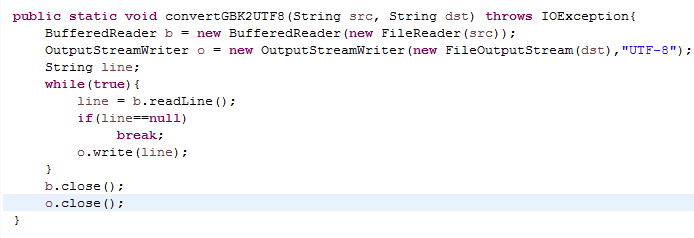
3.2 编写方法convertGBK2UTF8(String src, String dst),可以将以GBK编码的源文件src转换成以UTF8编码的目的文件dst。
方法如下:
4. 字节流、二进制文件:DataInputStream, DataOutputStream、ObjectInputStream
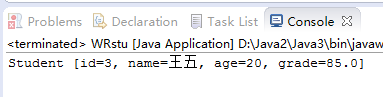
4.1 参考DataStream目录相关代码,尝试将三个学生对象的数据写入文件,然后从文件读出并显示。(截图关键代码,出现学号)
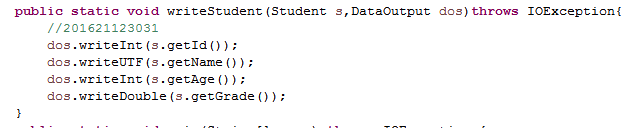


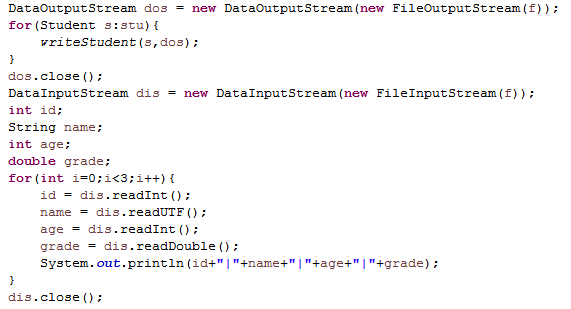
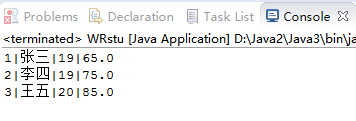
4.2 这里生成的文件和题目1生成的文件有何不一样?生成的文件有多大?分析该文件大小?将该文件大小和题目1生成的文件对比是大了还是小了,为什么?存储数据的时候,到底是二进制文件比较节省空间还是文本文件比较节省空间?使用二进制存储文件有何好处?
这里生成的文件是以.data为后缀名的数据文件,在这具体是指一个二进制文件。
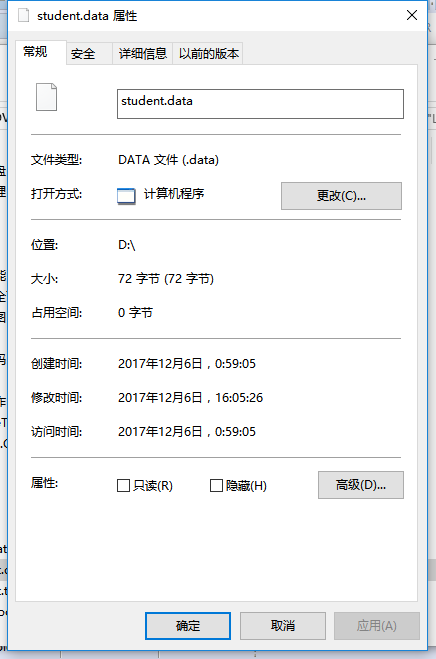
可以看到生成的文件为72个字节,其中一个int为4个字节,一个汉字为3个字节,表明字符串所占的字节数为2个字节,一个double为8个字节,因此一行的字节数为4+3+3+4+8+2=24,三行的字节数为24*3=72.
和题目一的文件相比变大了,有上面的分析可以看出,存储一个int,double和中文字符所需的字节数都变多了,因此文件比第一题的大。
虽然从上面的分析来看似乎是文本文件更能节省空间,但是这个还是要看具体情况,当存储的数值很小的时候,文本文件所占用的空间可能会更小,但是如果要存储大量的数据,还是二进制文件更能节省空间。
使用二进制存储文件的好处如下:
- 二进制文件更能节省存储空间
- 对于某些比较精确的数据,二进制不会造成有效位数的丢失
- 计算机中使用的语言是二进制语言,因此用二进制存储就可以省去语言的转换过程
4.3 使用wxMEdit的16进制模式(或者其他文本编辑器的16进制模式)打开student.data,分析数据在文件中是如何存储的。
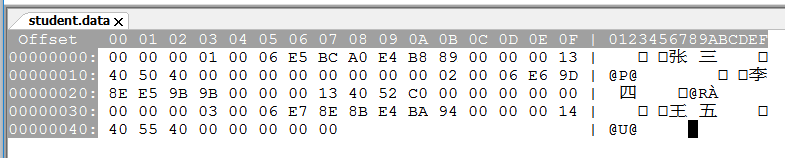
有点懒,就分析一行,其余两行类似:
00 00 00 01代表1
00 06 代表字符所占用的字节数,一个中文字符占三个字节
E5 BC A0 E4 B8 89代表张三
00 00 00 13 代表’19’
40 50 40 00 00 00 00 00 代表19.65
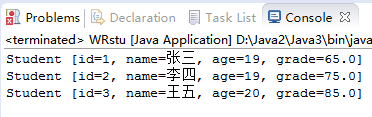
4.4 使用ObjectInputStream(读), ObjectOutputStream(写)读写学生。(截图关键代码,出现学号) //参考ObjectStreamTest目录


5. Scanner基本概念组装对象
编写public static List<Student> readStudents(String fileName)从fileName指定的文本文件中读取所有学生,并将其放入到一个List中。应该使用那些IO相关的类?说说你的选择理由。

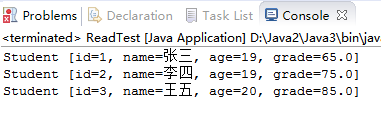
答:要使用到的类有File类,FileInputStream类,InputStreamReader类,BufferedReader类,其中BufferedReader类中带有的较大的缓冲区可以让我们更快的进行数据的读写。
6. 选做:RandomAccessFile
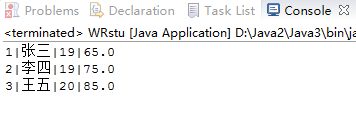
6.1 使用RandomAccessFile实现题目1.1。(截图关键代码,出现学号)



6.2 分析文件大小
大小为72个字节,和4.2中的分析一样。
6.3 编写一个函数public Student getStuByIndext(int index),可以根据序号index使用RandomAccessFile从文件中将该学生的信息取出。(截图关键代码,出现学号)。并回答,哪里体现了RandomAccessFile对文件的随机访问特性。


RandomAccessFile可以通过seek(),skipBytes()以及length等方法定位到文件的任何一个位置,在此基位置上进行一些文件的操作。
7. 文件操作
编写一个程序,可以根据指定目录和文件名,搜索该目录及子目录下的所有文件,如果没有找到指定文件名,则显示无匹配,否则将所有找到的文件名与文件夹名显示出来。
7.1 编写public static void findFile(String path,String filename)函数,以path指定的路径为根目录,使用递归方式,在其目录与子目录下查找所有和filename相同的文件名,一旦找到就马上输出到控制台。(截图关键代码,出现学号)


7.2 使用队列、使用图形界面、使用Java NIO.2完成(任选1)
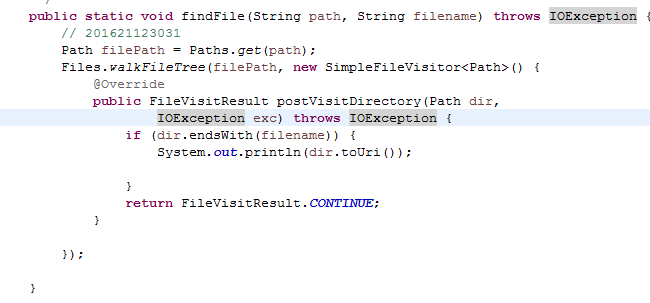

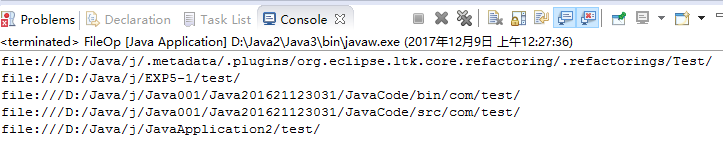
NIO.2的File工具类提供了一个walkFileTree来进行遍历,相比于上一题的递归,更加高效且优雅,然后在内部使用了遍历行为控制器FileVisitor,它是一个接口,里面提供四个方法来指定遍历过程中的事件处理,但是实际上,我在遍历时用的是直接继承FileVisitor的适配器SimpleFileVisitor,它相较于FileVisitor的好处就是可以不用实现四个方法,只需实现需要的方法即可。但是发现使用NIO.2遍历的文件似乎不会区分大小写耶。
7.3 选做:性能测试,测试你的findFile查找匹配文件的速度。有什么解决方案,可以让查找速度更快一些。比如类似Everything的搜索速度。
测试findFile的运行速度:
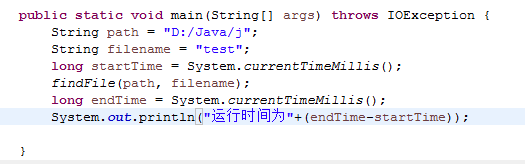
使用普通遍历法的运行时间:
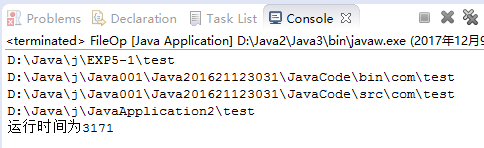
使用NIO.2方法的遍历时间:
通过上面图片可以看出,使用NIO.2的运行时间更短,其实上题就说过了,使用NIO.2可以提高遍历的效率。
7.4 选做:实现删掉指定目录(如果该目录非空,删除掉该目录下及其子目录下的所有文件与目录)。
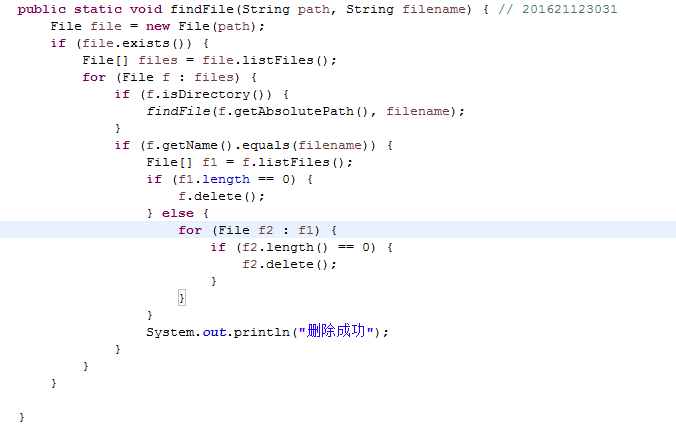
7.5 选做:将指定目录及子目录下的所有.java文件,转化成UTF-8编码格式,并测试。
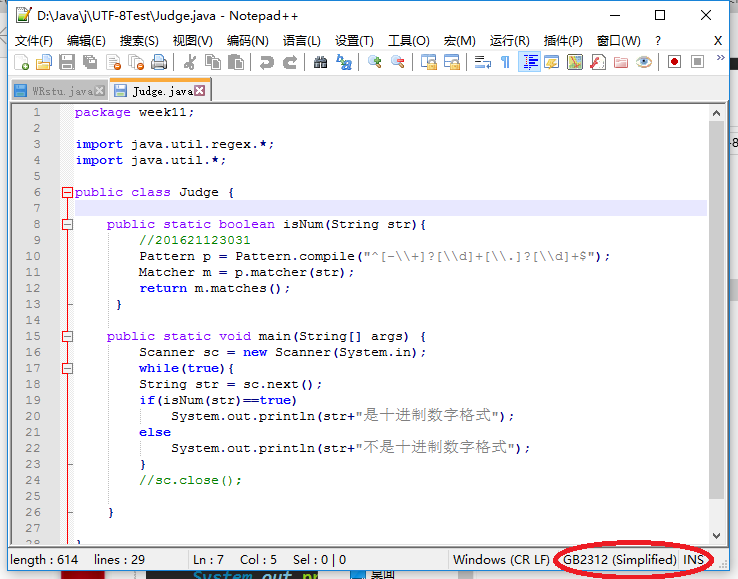
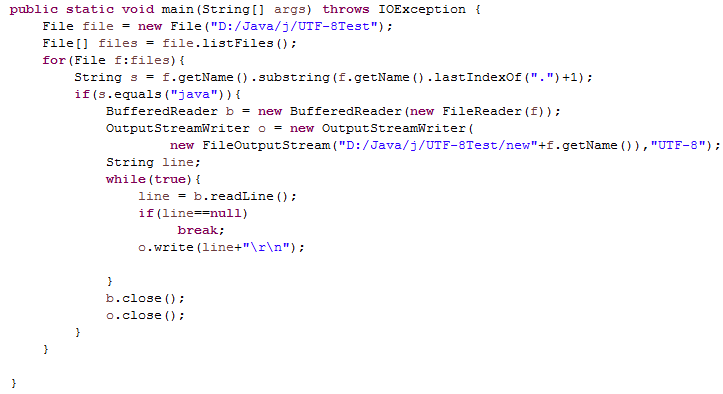
8. 正则表达式
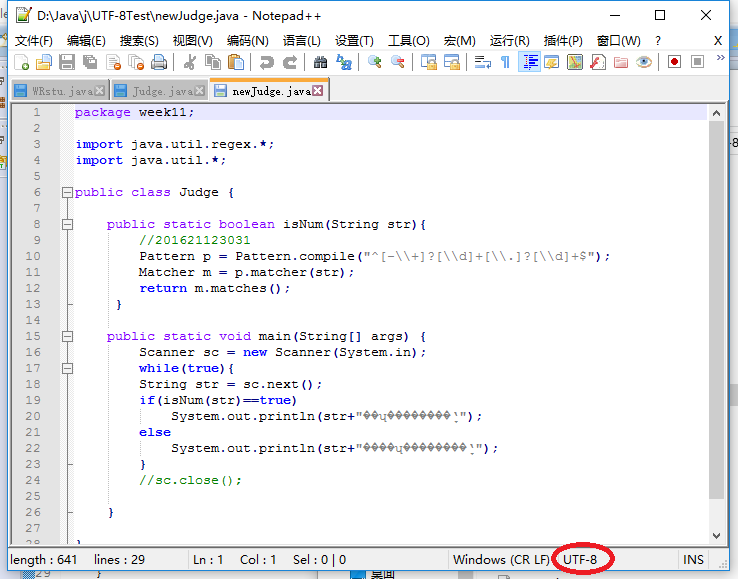
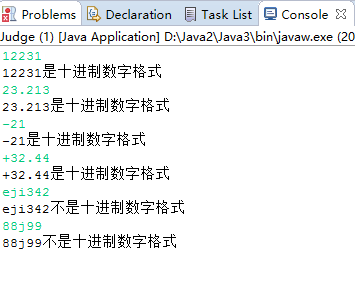
8.1 使用正则表达式判断给定的字符串是否是10进制数字格式?尝试编程进行验证,要给测试数据集及运行结果(可以转化为PTA)。(截图关键代码,出现学号)
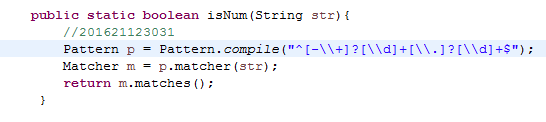
8.2 解释自己编写的正则表达式。
我编写的正则表达式为^[-\+]?[\d]+[\.]?[\d]+$
^代表匹配输入字符串的开始位置
[-\+]?代表字符串中”-”和”+”可以出现0次或1次
[\d]+代表数字可以出现1次或多次
[\.]?代表”.”可以出现0次或1次
$代表匹配输入字符串的结束位置