Moco 文章阅读笔记
既然前一篇帖子开了头记录Contrastive Loss的阅读心得,这一篇干脆就记录 Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie and Ross Girshick 的 Momentum Contrast for Unsupervised Visual Representation Learning简称 MoCo 的阅读笔记吧。个人阅历很浅,不能列举各种方法的原始文献,笔记也可能有谬误,轻拍。
对比损失函数 Contrastive Loss function
LeCun 2006年提出对比损失(Contrastive Loss),训练过程将同类样本尽量拉近,异类样本尽量推远。因异类样本可以推到无穷远,所以设定最远推出距离为m,防止训练无边界。LeCun文章中,样本特征之间的距离定义为欧几里德距离,
其中 是神经网络,
是网络参数,
是两个输入样本。
如下损失函数的定义完美体现了上面的描述,
其中 Y=0 表示一对样本 属于同类,Y=1 表示两者属于异类。同类则最小化第一项,即两者之间的距离。异类则看两者距离是否天生大于 m,是则忽略更新,否则增大距离到m。
样本识别 Instance Discrimination
原始的对比损失要知道每个样本的标签,依此判断两个样本是否同类。属于监督学习。
KaiMing及其合作者文章的题目有“非监督图像表示学习“,如果不知图像标签,如何判断同类异类,进而做对比损失训练?这就涉及到“Instance Discrimination", 参考文献【2】。这种方案简单说就是将每张图片在训练数据集中的序号作为标签,它与训练集中其他所有图片都是异类。对同一张图片做(剪切,旋转,缩放,调色等 Augmentation)等增强产生的图片与源图片同类。
在分类任务中,神经网络对相似的类给出相近的预测。文献【2】的作者在文中有这样一段话,非常的有启发。
We take the class-wise supervision to the extreme of instance-wise supervision, and ask: can we learn a meaningful metric that reflects apparent similarity among instances via pure discriminative learning?
前段时间火起来的半监督学习 MixMatch 以及 UDA 中,就有最小化两个同源图片在特征空间距离的损失函数项, 。从这个层面上来说,MoCo 相当于从半监督往非监督又迈了一步。
加噪对比估计 Noise-Contrastive Estimation (NCE)
一个自然的想法是,如果使用 cosine similarity,计算两个单位向量的点乘,则同类样本最小夹角为0,异类样本最大夹角为 , 不需要人为设定最远推出距离。MoCo 使用了这种对比损失函数,名字为 InfoNCE,参考文献 【3】
其中 是查询向量,对应当前样本的编码。
是键向量,对应之前样本的编码字典。
是温度,是一个可调参数,调节同一类的弥散程度。
一眼看过去,这个损失函数跟 softmax 很像,它跟 softmax 又有什么关系呢?其实一开始,在“Instance Discrimination” 文章中,作者尝试过 softmax, 做多标签分类,每个训练样本的序号就是它们的标签。如果第 i 张图 的潜在表示为
, 那么一张新图 x (其潜在表示
)被识别为第 i 个样本的概率为,
其中 是最后一个隐藏层到输出层第 i 个神经元之间的连接矩阵权重。因为输出层第 i 个神经元对应着第 i 张图,
表示
与第 i 个样本的匹配程度。
这种方法有两个问题 (1) 被训练的只对第 j 个训练样本敏感,不能很好的泛化到新的样本。(2)训练集很大,标签个数 n 太多(百万个类),分母上的求和
做不了。
为了解决第一个问题,文献【2】的作者们祭出了非参数化(扔掉)分类器,
在这个分类器里,作者将每个样本的特征表示 保存在一个记忆仓库(memory bank)中。训练时用 L2 正规化使得
,得到高维空间的单位向量。之前的
被替换成两个单位向量的 cos similarity。这种非参数化的分类器,类似于将最后一层 Densely connected layer 换成了 Global Average Pooling。不用再算
及其梯度,同时能够更好泛化到新样本。对负样本使用 Memory Bank 缓存,不用每次计算负样本的特征表示。
学习目标是能够正确识别每一个样本在训练集中的序号,最大化所有训练样本的联合预测概率 ,或最小化 negative log-likelihood,
有没有很眼熟?MoCo 使用的损失函数与它基本一致,除了多出对所有训练样本的求和。注意这里的损失函数是对所有训练样本的,而真正训练时,是使用mini-batch分批训练。所以在 MoCo 文章中,拿掉了前面这个求和。
第二个存在的问题是分母上 求和项太多。文献【2】的作者们进一步改进,通过抽样的方法,从 n 个样本(~
)中随机抽出 m 个(~
),作为代表计算求和,最后再乘以因子 n/m。作者在文中表示m=4096可以达到 m = 49999 的精度,大大加速计算。
Momentum vs Proximal Regularization
在文献【2】中,作者发现这种样本识别任务中每类只有一个样本,训练的时候每个Epoch只访问每个样本一次,训练样本的涨落导致训练误差剧烈震荡。作者采用了前人发明的 Proximal Regularization,在损失函数中加入 使得样本的特征表示更新过程尽量平滑。其中 t 是当前时刻,t-1 是前一次迭代。
MoCo 使用了动量机制,滑动平均来更新编码器参数 。其中 m 默认值是 0.999,
每次的增量等于 0.001
,非常微小。
Momentum Contrast (MoCo)
回到 MoCo, 其损失函数表示一个正样本与K个负样本的 negative log-likelihood, 对应 (K+1)类的 softmax (目标为将 分类为正样本
)。
最小化 有两种方法,第一种是增大分子
,使同类样本的特征表示夹角变小。第二种是减小分母
,使异类样本的特征表示夹角变大。所以这种损失函数也是一种 Contrastive Loss。通过梯度下降更新 q 编码器和 k 编码器的参数能够实现最小化
的目的。
在 Memory bank 方法中,每个样本的特征表示被保存在bank中。随着神经网络编码器的训练,不同样本被不同时期的编码器编码。每次抽样得到的K个负样本,其特征表示来自于多个时期的编码器的输出,不够自洽。
在 Momentum Contrast 方法中,放弃 memory bank, 使用队列保存最近几个mini-batch中训练样本的特征表示,提供 K 个负样本。随着训练的继续,老的 mini-batch 被从队列中移除,新 mini-batch 的特征表示被加入队列,保证字典中的负样本都来自于最新的键编码器。
按照MoCo的做法,对q编码器(查询)的更新比较激进,对k编码器(字典)的更新比较平滑,但也是使用 q 的梯度。按照 3.1 节的说法,两个编码器可以是同一个网络,或部分共享,或完全不同。但是好像没有看到如果q和k使用同一个编码器时的效果对比。
总结
从监督学习到半监督学习,再到非监督学习,每一步都是很大的进步。它山之石,可以攻玉。这里学到的方法,应该可以应用到更广泛的科学大数据中去。
参考文献
- Contrastive Loss function,Dimensionality Reduction by Learning an Invariant Mapping, 2006, Raia Hadsell, Sumit Chopra, Yann LeCun
- Instance Discrimination, Unsupervised Feature Learning via Non-Parametric Instance Discrimination, Wu ZhiRong, Yuanjun Xiong, Stella X. Yu, Dahua Lin
- InfoNCE or CPC, Representation Learning with Contrastive Predictive Coding, Aaron van den Oord, Yazhe Li, Oriol Vinyals, all from DeepMind
- Momentum Contrast for Unsupervised Visual Representation Learning, Kaiming He Haoqi Fan Yuxin Wu Saining Xie Ross Girshick, all from FAIR
文章被以下专栏收录
推荐阅读
深度学习面试100题(第1-5题):经典常考点CNN
1、梯度下降算法的正确步骤是什么?a.计算预测值和真实值之间的误差b.重复迭代,直至得到网络权重的最佳值c.把输入传入网络,得到输出值d.用随机值初始化权重和偏差e.对每一个产生误差的神…
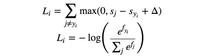
CS231n课程笔记翻译:线性分类笔记(上)

300 页干货!李宏毅《一天搞懂深度学习》(附下载)
XLNet 阅读笔记
背景:自编码与自回归语言模型的缺陷BERT 预训练方式属于自编码AE (Auto Encoder)。原因在于 BERT 预训练目标为根据上下文语境复原被 [MASK]随机遮挡的文字。此过程与降噪自编码机的原理一…
11 条评论
楼主你好,谢谢您的分享。
请问
【这种方法有两个问题 (1) W_{j}^{T} 被训练的只对第 j 个训练样本敏感,不能很好的泛化到新的样本。所以文中祭出非参版本...】
这句话如何理解呢?
您的意思是说:以前多分类是 学一个w 处理所有类,所以自适应新的测试样本。
而Memory bank 这里,每个w只能固定处理一个类, 所以
而每个样本(即这里的每个类)都学一个w 有什么不好呢?
1-如果有新的测试instance, 之前训练好所有的 w 并不能排上用场。直接没有泛化性。
2-需要学的w和training instance 数目相同,实在太暴力?
还有,
【在 Memory bank 方法中,每个样本的特征表示被保存在bank中。随着神经网络编码器的训练,不同样本被不同时期的编码器编码。每次抽样得到的K个负样本,其特征表示来自于多个时期的编码器的输出,不够自洽。】
不是固定住了 k-encoder 吗,怎么会出现
【每次抽样得到的K个负样本,其特征表示来自于多个时期的编码器的输出】呢?
您好,query和key所用的同一个编码器的参数不同,这样不会造成不一致吗?为什么会work呢?
分析很到位,看完细节清晰了很多,赞作者
我怎么觉得伪代码里面labels那里有点问题,就是应该是个[N,K+1]的矩阵,第一位为1,请问一下您觉的labels为什么是zeros(N)?