介绍:最基本的GAN版本,在实际运用中很少使用,而深度卷积对抗生成网络(DCGAN)由于网络训练状态稳定,并可以有效实现高质量的图片生成以及相关的生成模型应用,在实际工程中有广泛的使用,在它之后的大量的GAN模型是在它基础上改进的。
《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》
论文链接:http://arxiv.org/abs/1511.06434
为了使得GAN能够很好的适应于卷积神经网络,DCGAN提出了以下4点架构设计规则:
1、卷积层代替池化层:为了能够让网络自身去学习空间上采样与下采样,使得判别器和生成器都有效的具备相应的能力。
2、去除全连接层
3、使用批归一化
4、使用恰当的激活函数
下面是对上面四点的详细介绍:
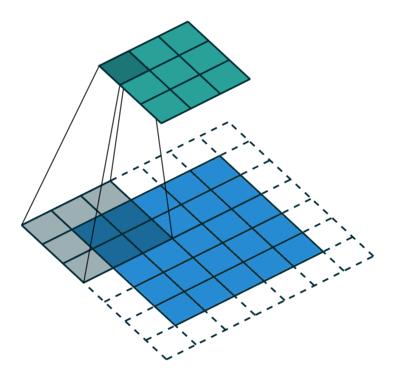
1.1对于判别器,我们使用步长卷积(strided convolution)来代替池化层,对于生成器,使用分数步长卷积(fractional-strided convolutions)代替池化。其中,步长卷积在判别器中进行空间下采样(spatial downsampling)。示例如下:输入为5x5的矩阵,使用3x3的过滤器,步长为2x2,最终输出为3x3.
步长卷积示意图(strided convolution)
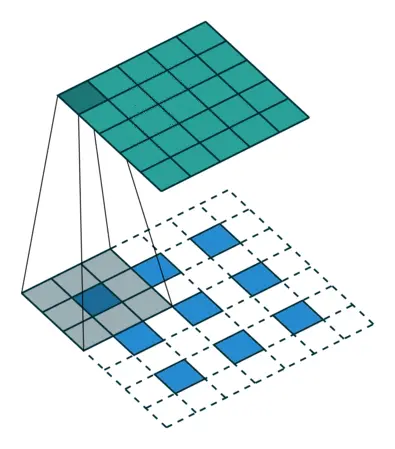
下图展示是“分数步长卷积”,其在生成器中进行上采样(spatial upsampling),输入为3x3矩阵,也使用3x3的卷积核,步长为1x1,故在每个输入矩阵的点之间填充一个0,最终输出为5x5.
分数步长卷积示意图
2.1去除全连接层,现在很多研究都在试图去除全连接层,在常规的CNN中,在卷积层的后面添加全连接层以输出最终向量,但由于全连接层参数过多,容易使网络过拟合。有研究使用了全局平均池化来代替全连接层,可以使得模型更稳定,但会影响收敛速度。
该论文中提出了一种折中方案,将生成器的随机输入直接与卷积层特征输入进行连接,同样,判别器的输出层与卷积层的输出特征连接。
3、使用批归一化:由于深度学习的神经网络层数很多,每一层都会使得输出数据的分布发生变化,随着层数的增加,网络的整体偏差会越来越大。批归一化的目标则是为了解决这一问题,通过对每一层的输入进行归一化处理,能够有效的使得数据服从某个固定的数据分布。
4、激活函数的作用是为了在神经网络中进行非线性变换,如sigmoid、tanh、Relu、leakRelu。
在DCGAN中,生成器和判别器使用不同的激活函数。在生成器中使用ReLU函数,但在输出层使用了tanh函数,因为发现使用有边界的激活函数可以让模型更快的学习,并能快速覆盖色彩空间。在判别器中对所有层使用leakyRelu。
代码如下:
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import sys
import numpy as np
class DCGAN():
def __init__(self):
# Input shape
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
#输入数据为100维的随机数据z,经过一系列分数步长卷积后,最后形成一幅64x64x3的RGB图片
#先经过一层全连接层,变成128 * 7 * 7个元素矩阵,然后调整成7, 7, 128
model.add(Dense(128 * 7 * 7, activation