-------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------
第5 章 运维保障333
王 康/5.1 360 如何用QConf 搞定两万以上服务器的配置管理.333
5.1.1 设计初衷333
5.1.2 整体认识334
5.1.3 架构介绍335
5.1.4 QConf 服务端336
5.1.5 QConf 客户端336
5.1.6 QConf 管理端340
5.1.7 其他341
5.1.8 疑问与解惑343
-------------------------------------------------------------------------------------------------------------------------------------
QConf是奇虎360广泛使用的配置管理服务,现已开源,欢迎大家关注使用。
https://github.com/Qihoo360/QConf
本文从设计初衷,架构实现,使用情况及相关产品比较四个方面进行介绍。
设计初衷
在分布式环境中,出于负载、容错等种种需要,几乎所有的服务都会在不同的机器节点上部署多个实例。而业务项目中又总少不了各种类型的配置文件。因此,我们常常会遇到这样的问题,仅仅是一个配置内容的修改,便需要重新进行代码提交SVN/Git、打包、分发上线的全部流程。当部署的机器有很多时,分发上线本身就是一个很繁杂的工作。何况,配置文件的修改频率又远远大于代码本身。
追本溯源,我们认为麻烦的根源是日常管理和发布过程中不加区分配置和代码造成的。配置本身源于代码,是我们为了提高代码的灵活性而提取出来的一些经常变化的或需要定制的内容,而正是配置的这种天生的变化特征给我们带了巨大的麻烦。
因此,我们开发了分布式配置管理系统QConf,并依托QConf在360内部提供了一整套配置管理服务,QConf致力于将配置内容从代码中完全分离出来,及时可靠高效地提供配置访问和更新服务。
-------------------------------------------------------------------------------------------------------------------------------------
尤 勇/5.2 深度剖析开源分布式监控CAT347
5.2.1 背景介绍347
5.2.2 整体设计348
5.2.3 客户端设计349
5.2.4 服务端设计352
5.2.5 总结感悟357
-------------------------------------------------------------------------------------------------------------------------------------
深度剖析开源分布式监控CAT
CAT(Central Application Tracking)是一个实时和接近全量的监控系统,它侧重于对Java应用的监控,基本接入了美团上海侧所有核心应用。目前在中间件(MVC、RPC、数据库、缓存等)框架中得到广泛应用,为美团各业务线提供系统的性能指标、健康状况、监控告警等。

自2014年开源以来,Github 收获 7700+ Star,2800+ Forks,被 100+ 公司企业使用,其中不乏携程、陆金所、猎聘网、平安等业内知 名公司。在每年全球 QCon 大会、全球架构与运维技术峰会等都有持续的技术输出,受到行业内认可,越来越多的企业伙伴加入了 CAT 的开 源建设工作,为 CAT 的成⻓贡献了巨大的力量。
项目的开源地址是 http://github.com/dianping/cat。
本文会对CAT整体设计、客户端、服务端等的一些设计思路做详细深入的介绍。
背景介绍
CAT整个产品研发是从2011年底开始的,当时正是大众点评从.NET迁移到Java的核心起步阶段。当初大众点评已经有核心的基础中间件、RPC组件Pigeon、统一配置组件Lion。整体Java迁移已经在服务化的路上。随着服务化的深入,整体Java在线上部署规模逐渐变多,同时,暴露的问题也越来越多。典型的问题有:
- 大量报错,特别是核心服务,需要花很久时间才能定位。
- 异常日志都需要线上权限登陆线上机器排查,排错时间长。
- 有些简单的错误定位都非常困难(一次将线上的库配置到了Beta,花了整个通宵排错)。
- 很多不了了之的问题怀疑是网络问题(从现在看,内网真的很少出问题)。
虽然那时候也有一些简单的监控工具(比如Zabbix,自己研发的Hawk系统等),可能单个工具在某方面的功能还不错,但整体服务化水平参差不齐、扩展能力相对较弱,监控工具间不能互通互联,使得查找问题根源基本都需要在多个系统之间切换,有时候真的是靠“人品”才能找出根源。
适逢在eBay工作长达十几年的吴其敏加入大众点评成为首席架构师,他对eBay内部应用非常成功的CAL系统有深刻的理解。就在这样天时地利人和的情况下,我们开始研发了大众点评第一代监控系统——CAT。
CAT的原型和理念来源于eBay的CAL系统,最初是吴其敏在大众点评工作期间设计开发的。他之前曾CAT不仅增强了CAL系统核心模型,还添加了更丰富的报表。
整体设计
监控整体要求就是快速发现故障、快速定位故障以及辅助进行程序性能优化。为了做到这些,我们对监控系统的一些非功能做了如下的要求:
- 实时处理:信息的价值会随时间锐减,尤其是事故处理过程中。
- 全量数据:最开始的设计目标就是全量采集,全量的好处有很多。
- 高可用:所有应用都倒下了,需要监控还站着,并告诉工程师发生了什么,做到故障还原和问题定位。
- 故障容忍:CAT本身故障不应该影响业务正常运转,CAT挂了,应用不该受影响,只是监控能力暂时减弱。
- 高吞吐:要想还原真相,需要全方位地监控和度量,必须要有超强的处理吞吐能力。
- 可扩展:支持分布式、跨IDC部署,横向扩展的监控系统。
- 不保证可靠:允许消息丢失,这是一个很重要的trade-off,目前CAT服务端可以做到4个9的可靠性,可靠系统和不可靠性系统的设计差别非常大。
CAT从开发至今,一直秉承着简单的架构就是最好的架构原则,主要分为三个模块:CAT-client、CAT-consumer、CAT-home。
- Cat-client 提供给业务以及中间层埋点的底层SDK。
- Cat-consumer 用于实时分析从客户端提供的数据。
- Cat-home 作为用户给用户提供展示的控制端。
在实际开发和部署中,Cat-consumer和Cat-home是部署在一个JVM内部,每个CAT服务端都可以作为consumer也可以作为home,这样既能减少整个层级结构,也可以增加系统稳定性。
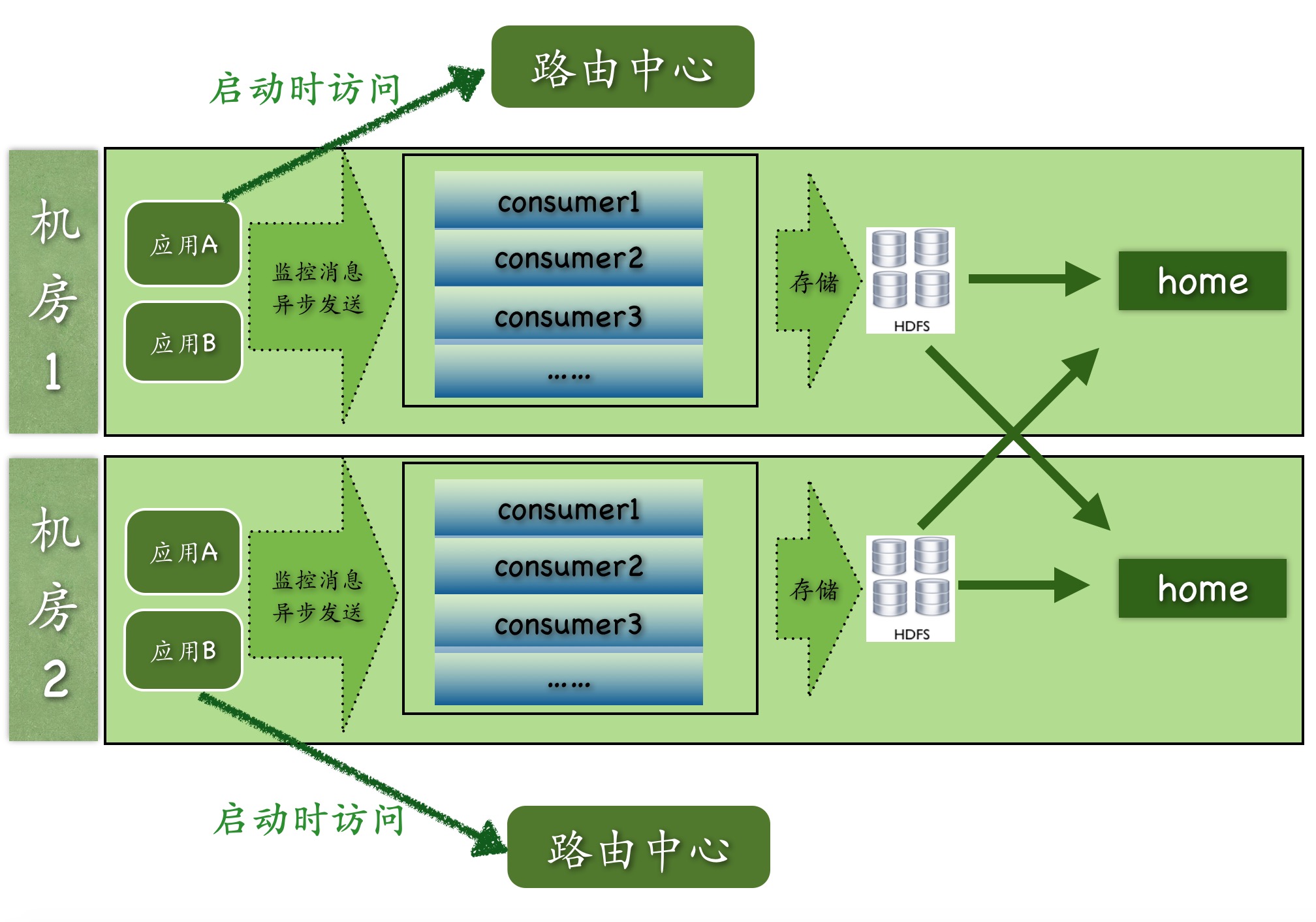
上图是CAT目前多机房的整体结构图,图中可见:
- 路由中心是根据应用所在机房信息来决定客户端上报的CAT服务端地址,目前美团有广州、北京、上海三地机房。
- 每个机房内部都有独立的原始信息存储集群HDFS。
- CAT-home可以部署在一个机房也可以部署在多个机房,在最后做展示的时候,home会从consumer中进行跨机房的调用,将所有的数据合并展示给用户。
- 实际过程中,consumer、home以及路由中心都是部署在一起的,每个服务端节点都可以充当任何一个角色。
客户端设计
客户端设计是CAT系统设计中最为核心的一个环节,客户端要求是做到API简单、高可靠性能,无论在任何场景下都不能影响客业务性能,监控只是公司核心业务流程一个旁路环节。CAT核心客户端是Java,也支持Net客户端,近期公司内部也在研发其他多语言客户端。以下客户端设计及细节均以Java客户端为模板。
设计架构
CAT客户端在收集端数据方面使用ThreadLocal(线程局部变量),是线程本地变量,也可以称之为线程本地存储。其实ThreadLocal的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,属于Java中一种较为特殊的线程绑定机制,每一个线程都可以独立地改变自己的副本,不会和其它线程的副本冲突。
在监控场景下,为用户提供服务都是Web容器,比如tomcat或者Jetty,后端的RPC服务端比如Dubbo或者Pigeon,也都是基于线程池来实现的。业务方在处理业务逻辑时基本都是在一个线程内部调用后端服务、数据库、缓存等,将这些数据拿回来再进行业务逻辑封装,最后将结果展示给用户。所以将所有的监控请求作为一个监控上下文存入线程变量就非常合适。
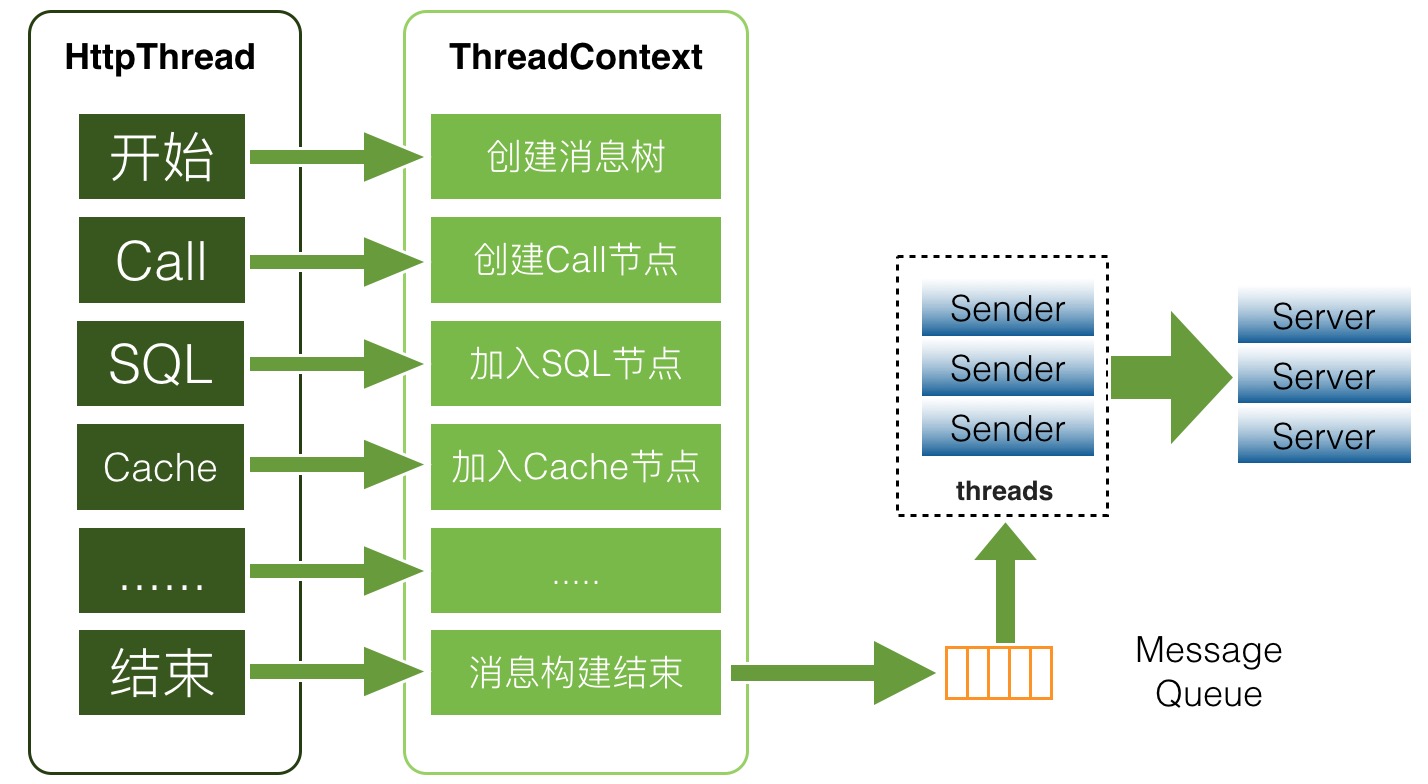
如上图所示,业务执行业务逻辑的时候,就会把此次请求对应的监控存放于线程上下文中,存于上下文的其实是一个监控树的结构。在最后业务线程执行结束时,将监控对象存入一个异步内存队列中,CAT有个消费线程将队列内的数据异步发送到服务端。
API设计
监控API定义往往取决于对监控或者性能分析这个领域的理解,监控和性能分析所针对的场景有如下几种:
- 一段代码的执行时间,一段代码可以是URL执行耗时,也可以是SQL的执行耗时。
- 一段代码的执行次数,比如Java抛出异常记录次数,或者一段逻辑的执行次数。
- 定期执行某段代码,比如定期上报一些核心指标:JVM内存、GC等指标。
- 关键的业务监控指标,比如监控订单数、交易额、支付成功率等。
在上述领域模型的基础上,CAT设计自己核心的几个监控对象:Transaction、Event、Heartbeat、Metric。
一段监控API的代码示例如下:

序列化和通信
序列化和通信是整个客户端包括服务端性能里面很关键的一个环节。
- CAT序列化协议是自定义序列化协议,自定义序列化协议相比通用序列化协议要高效很多,这个在大规模数据实时处理场景下还是非常有必要的。
- CAT通信是基于Netty来实现的NIO的数据传输,Netty是一个非常好的NIO开发框架,在这边就不详细介绍了。
客户端埋点
日志埋点是监控活动的最重要环节之一,日志质量决定着监控质量和效率。当前CAT的埋点目标是以问题为中心,像程序抛出exception就是典型问题。我个人对问题的定义是:不符合预期的就可以算问题,比如请求未完成、响应时间快了慢了、请求TPS多了少了、时间分布不均匀等等。
在互联网环境中,最突出的问题场景,突出的理解是:跨越边界的行为。包括但不限于:
- HTTP/REST、RPC/SOA、MQ、Job、Cache、DAL;
- 搜索/查询引擎、业务应用、外包系统、遗留系统;
- 第三方网关/银行, 合作伙伴/供应商之间;
- 各类业务指标,如用户登录、订单数、支付状态、销售额。
遇到的问题
通常Java客户端在业务上使用容易出问题的地方就是内存,另外一个是CPU。内存往往是内存泄露,占用内存较多导致业务方GC压力增大; CPU开销最终就是看代码的性能。
以前我们遇到过一个极端的例子,我们一个业务请求做餐饮加商铺的销售额,业务一般会通过for循环所有商铺的分店,结果就造成内存OOM了,后来发现这家店是肯德基,有几万分店,每个循环里面都会有数据库连接。在正常场景下,ThreadLocal内部的监控一个对象就存在几万个节点,导致业务Oldgc特别严重。所以说框架的代码是不能想象业务方会怎么用你的代码,需要考虑到任何情况下都有出问题的可能。
在消耗CPU方面我们也遇到一个case:在某个客户端版本,CAT本地存储当前消息ID自增的大小,客户端使用了MappedByteBuffer这个类,这个类是一个文件内存映射,测试下来这个类的性能非常高,我们仅仅用这个存储了几个字节的对象,正常情况理论上不会有任何问题。在一次线上场景下,很多业务线程都block在这个上面,结果发现当本身这台机器IO存在瓶颈时候,这个也会变得很慢。后来的优化就是把这个IO的操作异步化,所以客户端需要尽可能异步化,异步化序列化、异步化传输、异步化任何可能存在时间延迟的代码操作。
服务端设计
服务端主要的问题是大数据的实时处理,目前后端CAT的计算集群大约35台物理机,存储集群大约35台物理机,每天处理了约100TB的数据量。线上单台机器高峰期大约是110MB/s,接近千兆网打满。
下面我重点讲下CAT服务端一些设计细节。
架构设计
在最初的整体介绍中已经画了架构图,这边介绍下单机的consumer中大概的结构如下:
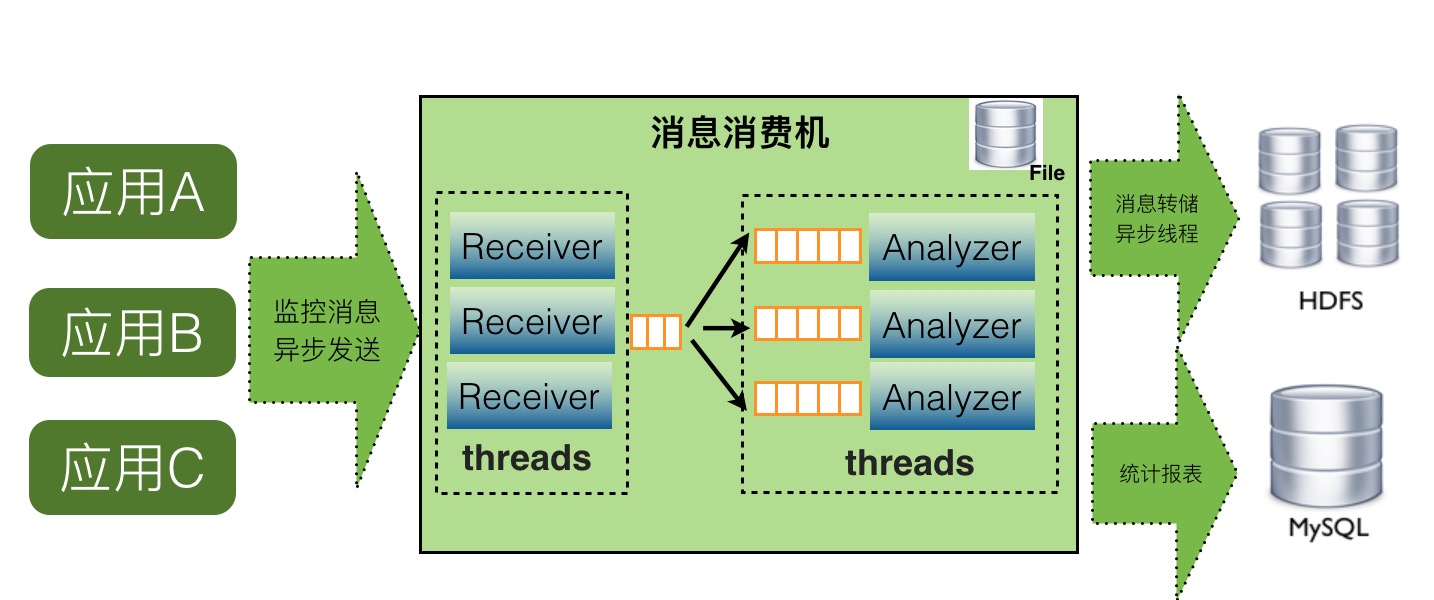
如上图,CAT服务端在整个实时处理中,基本上实现了全异步化处理。
- 消息接受是基于Netty的NIO实现。
- 消息接受到服务端就存放内存队列,然后程序开启一个线程会消费这个消息做消息分发。
- 每个消息都会有一批线程并发消费各自队列的数据,以做到消息处理的隔离。
- 消息存储是先存入本地磁盘,然后异步上传到HDFS文件,这也避免了强依赖HDFS。
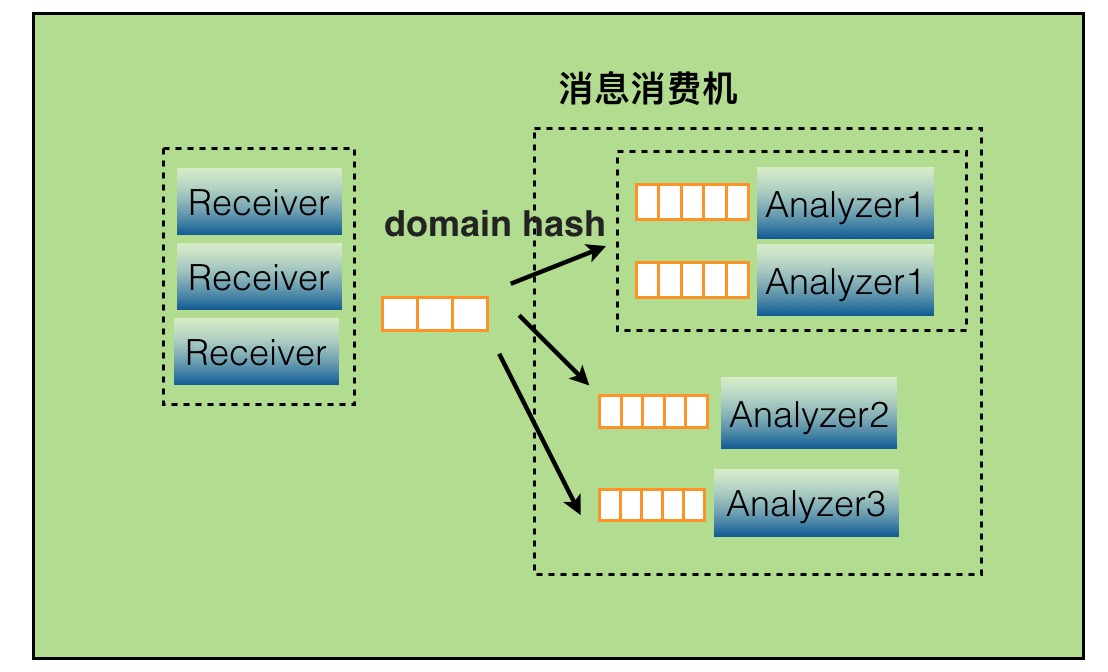
当某个报表处理器处理来不及时候,比如Transaction报表处理比较慢,可以通过配置支持开启多个Transaction处理线程,并发消费消息。
实时分析
CAT服务端实时报表分析是整个监控系统的核心,CAT重客户端采集的是是原始的logview,目前一天大约有1000亿的消息,这些原始的消息太多了,所以需要在这些消息基础上实现丰富报表,来支持业务问题及性能分析的需要。
CAT是根据日志消息的特点(比如只读特性)和问题场景,量身定做的,它将所有的报表按消息的创建时间,一小时为单位分片,那么每小时就产生一个报表。当前小时报表的所有计算都是基于内存的,用户每次请求即时报表得到的都是最新的实时结果。对于历史报表,因为它是不变的,所以实时不实时也就无所谓了。
CAT基本上所有的报表模型都可以增量计算,它可以分为:计数、计时和关系处理三种。计数又可以分为两类:算术计数和集合计数。典型的算术计数如:总个数(count)、总和(sum)、均值(avg)、最大/最小(max/min)、吞吐(tps)和标准差(std)等,其他都比较直观,标准差稍微复杂一点,大家自己可以推演一下怎么做增量计算。那集合运算,比如95线(表示95%请求的完成时间)、999线(表示99.9%请求的完成时间),则稍微复杂一些,系统开销也更大一点。
报表建模
CAT每个报表往往有多个维度,以transaction报表为例,它有5个维度,分别是应用、机器、Type、Name和分钟级分布情况。如果全维度建模,虽然灵活,但开销将会非常之大。CAT选择固定维度建模,可以理解成将这5个维度组织成深度为5的树,访问时总是从根开始,逐层往下进行。
CAT服务端为每个报表单独分配一个线程,所以不会有锁的问题,所有报表模型都是非线程安全的,其数据是可变的。这样带来的好处是简单且低开销。
CAT报表建模是使用自研的Maven Plugin自动生成的。所有报表是可合并和裁剪的,可以轻易地将2个或多个报表合并成一个报表。在报表处理代码中,CAT大量使用访问者模式(visitor pattern)。
性能分析报表

故障发现报表
- 实时业务指标监控 :核心业务都会定义自己的业务指标,这不需要太多,主要用于24小时值班监控,实时发现业务指标问题,图中一个是当前的实际值,一个是基准值,就是根据历史趋势计算的预测值。如下图就是当时的情景,能直观看到支付业务出问题的故障。
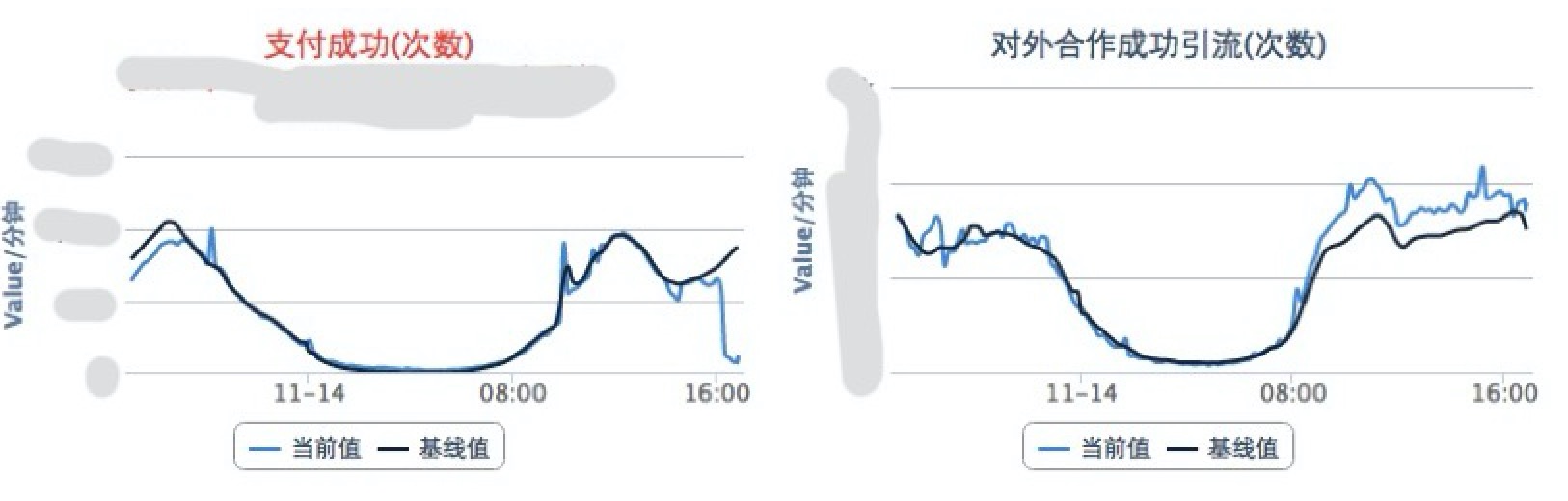
- 系统报错大盘。
- 实时数据库大盘、服务大盘、缓存大盘等。
存储设计
CAT系统的存储主要有两块:
- CAT的报表的存储。
- CAT原始logview的存储。
报表是根据logview实时运算出来的给业务分析用的报表,默认报表有小时模式、天模式、周模式以及月模式。CAT实时处理报表都是产生小时级别统计,小时级报表中会带有最低分钟级别粒度的统计。天、周、月等报表都是在小时级别报表合并的结果报表。
原始logview存储一天大约100TB的数据量,因为数据量比较大所以存储必须要要压缩,本身原始logview需要根据Message-ID读取,所以存储整体要求就是批量压缩以及随机读。在当时场景下,并没有特别合适成熟的系统以支持这样的特性,所以我们开发了一种基于文件的存储以支持CAT的场景,在存储上一直是最难的问题,我们一直在这块持续的改进和优化。
消息ID的设计
CAT每个消息都有一个唯一的ID,这个ID在客户端生成,后续都通过这个ID在进行消息内容的查找。典型的RPC消息串起来的问题,比如A调用B的时候,在A这端生成一个Message-ID,在A调用B的过程中,将Message-ID作为调用传递到B端,在B执行过程中,B用context传递的Message-ID作为当前监控消息的Message-ID。
CAT消息的Message-ID格式ShopWeb-0a010680-375030-2,CAT消息一共分为四段:
- 第一段是应用名shop-web。
- 第二段是当前这台机器的IP的16进制格式,0a01010680表示10.1.6.108。
- 第三段的375030,是系统当前时间除以小时得到的整点数。
- 第四段的2,是表示当前这个客户端在当前小时的顺序递增号。
存储数据的设计
消息存储是CAT最有挑战的部分。关键问题是消息数量多且大,目前美团每天处理消息1000亿左右,大小大约100TB,单物理机高峰期每秒要处理100MB左右的流量。CAT服务端基于此流量做实时计算,还需要将这些数据压缩后写入磁盘。
整体存储结构如下图:
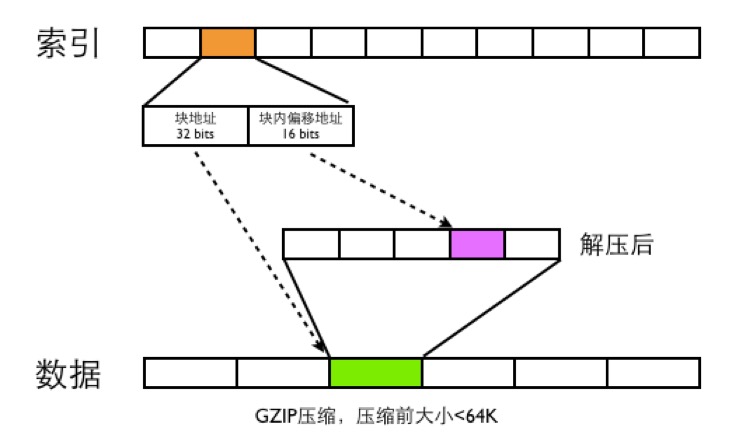
CAT在写数据一份是Index文件,一份是Data文件.
- Data文件是分段GZIP压缩,每个分段大小小于64K,这样可以用16bits可以表示一个最大分段地址。
- 一个Message-ID都用需要48bits的大小来存索引,索引根据Message-ID的第四段来确定索引的位置,比如消息Message-ID为ShopWeb-0a010680-375030-2,这条消息ID对应的索引位置为2*48bits的位置。
- 48bits前面32bits存数据文件的块偏移地址,后面16bits存数据文件解压之后的块内地址偏移。
- CAT读取消息的时候,首先根据Message-ID的前面三段确定唯一的索引文件,在根据Message-ID第四段确定此Message-ID索引位置,根据索引文件的48bits读取数据文件的内容,然后将数据文件进行GZIP解压,在根据块内偏移地址读取出真正的消息内容。
服务端设计总结
CAT在分布式实时方面,主要归结于以下几点因素:
- 去中心化,数据分区处理。
- 基于日志只读特性,以一个小时为时间窗口,实时报表基于内存建模和分析,历史报表通过聚合完成。
- 基于内存队列,全面异步化、单线程化、无锁设计。
- 全局消息ID,数据本地化生产,集中式存储。
- 组件化、服务化理念。
总结
最后我们再花一点点时间来讲一下我们在实践里做的一些东西。
一、MVP版本,Demo版本用了1个月,MVP版本用了3个月。
为什么强调MVP版本?因为做这个项目需要老板和业务的支持。大概在2011年左右,我们整个生产环境估计也有一千台机器(虚拟机),一旦出现问题就到运维那边看日志,看日志的痛苦大家都应该理解,这时候发现一台机器核心服务出错,可能会导致更多的问题。我们就做了MVP版本解决这个问题,当时我们大概做了两个功能:一个是实时知道所有的API接口访问量成功率等;第二是实时能在CAT平台上看到异常日志。这里我想说的是MVP版本不要做太多内容,但是在做一个产品的时候必须从MVP版本做起,要做一些最典型特别亮眼的功能让大家支持你。
二、数据质量。数据质量是整个监控体系里面非常关键,它决定你最后的监控报表质量。所以我们要和跟数据库框架、缓存框架、RPC框架、Web框架等做深入的集成,让业务方便收集以及看到这些数据。
三、单机开发环境,这也是我们认为对整个项目开发效率提升最重要的一点。单机开发环境实际上就是说你在一台机器里可以把你所有的项目都启起来。如果你在一个单机环境下把所有东西启动起来,你就会想方设法地知道我依赖的服务挂了我怎么办?比如CAT依赖了HDFS。单机开发环境除了大幅度提高你的项目开发效率之外,还能提升你整个项目的可靠性。
四、最难的事情是项目上线推动。CAT整个项目大概有两三个人,当时白天都是支持业务上线,培训,晚上才能code,但是一旦随着产品和完善以及业务使用逐渐变多,一些好的产品后面会形成良性循环,推广就会变得比较容易。
五、开放生态。公司越大监控的需求越多,报表需求也更多,比如我们美团,产品有很多报表,整个技术体系里面也有很多报表非常多的自定义报表,很多业务方都提各自的需求。最后我们决定把整个CAT系统里面所有的数据都作为API暴露出去,这些需求并不是不能支持,而是这事情根本是做不完的。美团内部下游有很多系统依赖CAT的数据,来做进一步的报表展示。
CAT项目从2011年开始做,到现在整个生产环境大概有三千应用,监控的服务端从零到几千,再到今天的两万多的规模,整个项目是从历时看起来是一个五年多的项目,但即使是做了五年多的这样一个项目,目前还有很多的需求需要开发。这边也打个广告,我们团队急缺人,欢迎对监控系统研发有兴趣的同学加入,请联系yong.you@dianping.com.
-------------------------------------------------------------------------------------------------------------------------------------
杨尚刚/5.3 单表60 亿记录等大数据场景的MySQL 优化和运维之道359
5.3.1 前言359
5.3.2 数据库开发规范.360
5.3.3 数据库运维规范.363
5.3.4 性能优化368
5.3.5 疑问与解惑375
-------------------------------------------------------------------------------------------------------------------------------------
单表 60 亿记录等大数据场景的 MySQL 优化和运维之道 | 高可用架构 - FrancisSoung - SegmentFault 思否此文是根据杨尚刚在【QCON 高可用架构群】中,针对 MySQL 在单表海量记录等场景下,业界广泛关注的 MySQL 问题的经验分享整理而成,转发请注明出处。
此文是根据杨尚刚在【QCON 高可用架构群】中,针对 MySQL 在单表海量记录等场景下,业界广泛关注的 MySQL 问题的经验分享整理而成,转发请注明出处。
杨尚刚,美图公司数据库高级 DBA,负责美图后端数据存储平台建设和架构设计。前新浪高级数据库工程师,负责新浪微博核心数据库架构改造优化,以及数据库相关的服务器存储选型设计。
前言
MySQL 数据库大家应该都很熟悉,而且随着前几年的阿里的去 IOE,MySQL 逐渐引起更多人的重视。
MySQL 历史
-
1979 年,Monty Widenius 写了最初的版本,96 年发布 1.0
-
1995-2000 年,MySQL AB 成立,引入 BDB
-
2000 年 4 月,集成 MyISAM 和 replication
-
2001 年,Heikki Tuuri 向 MySQL 建议集成 InnoDB
-
2003 发布 5.0,提供了视图、存储过程等功能
-
2008 年,MySQL AB 被 Sun 收购,09 年推出 5.1
-
2009 年 4 月,Oracle 收购 Sun,2010 年 12 月推出 5.5
-
2013 年 2 月推出 5.6 GA,5.7 开发中
MySQL 的优点
-
使用简单
-
开源免费
-
扩展性 “好”,在一定阶段扩展性好
-
社区活跃
-
性能可以满足互联网存储和性能需求,离不开硬件支持
上面这几个因素也是大多数公司选择考虑 MySQL 的原因。不过 MySQL 本身存在的问题和限制也很多,有些问题点也经常被其他数据库吐槽或鄙视
MySQL 存在的问题
-
优化器对复杂 SQL 支持不好
-
对 SQL 标准支持不好
-
大规模集群方案不成熟,主要指中间件
-
ID 生成器,全局自增 ID
-
异步逻辑复制,数据安全性问题
-
Online DDL
-
HA 方案不完善
-
备份和恢复方案还是比较复杂,需要依赖外部组件
-
展现给用户信息过少,排查问题困难
-
众多分支,让人难以选择
看到了刚才讲的 MySQL 的优势和劣势,可以看到 MySQL 面临的问题还是远大于它的优势的, 很多问题也是我们实际需要在运维中优化解决的,这也是 MySQL DBA 的一方面价值所在。并且 MySQL 的不断发展也离不开社区支持,比如 Google 最早提交的半同步 patch,后来也合并到官方主线。Facebook Twitter 等也都开源了内部使用 MySQL 分支版本,包含了他们内部使用的 patch 和特性。
数据库开发规范
数据库开发规范定义:开发规范是针对内部开发的一系列建议或规则, 由 DBA 制定 (如果有 DBA 的话)。
开发规范本身也包含几部分:基本命名和约束规范,字段设计规范,索引规范,使用规范。
规范存在意义
-
保证线上数据库 schema 规范
-
减少出问题概率
-
方便自动化管理
-
规范需要长期坚持,对开发和 DBA 是一个双赢的事情
想想没有开发规范,有的开发写出各种全表扫描的 SQL 语句或者各种奇葩 SQL 语句,我们之前就看过开发写的 SQL 可以打印出好几页纸。这种造成业务本身不稳定,也会让 DBA 天天忙于各种救火。
基本命名和约束规范
-
表字符集选择 UTF8 ,如果需要存储 emoj 表情,需要使用 UTF8mb4(MySQL 5.5.3 以后支持)
-
存储引擎使用 InnoDB
-
变长字符串尽量使用 varchar varbinary
-
不在数据库中存储图片、文件等
-
单表数据量控制在 1 亿以下
-
库名、表名、字段名不使用保留字
-
库名、表名、字段名、索引名使用小写字母,以下划线分割 ,需要见名知意
-
库表名不要设计过长,尽可能用最少的字符表达出表的用途
字段规范
-
所有字段均定义为 NOT NULL ,除非你真的想存 Null
-
字段类型在满足需求条件下越小越好,使用 UNSIGNED 存储非负整数 ,实际使用时候存储负数场景不多
-
使用 TIMESTAMP 存储时间
-
使用 varchar 存储变长字符串 ,当然要注意 varchar(M) 里的 M 指的是字符数不是字节数;使用 UNSIGNED INT 存储 IPv4 地址而不是 CHAR(15) ,这种方式只能存储 IPv4,存储不了 IPv6
-
使用 DECIMAL 存储精确浮点数,用 float 有的时候会有问题
-
少用 blob text
关于为什么定义不使用 Null 的原因
1、浪费存储空间,因为 InnoDB 需要有额外一个字节存储
2、表内默认值 Null 过多会影响优化器选择执行计划
关于使用 datatime 和 timestamp,现在在 5.6.4 之后又有了变化,使用二者存储在存储空间上大差距越来越小 ,并且本身 datatime 存储范围就比 timestamp 大很多,timestamp 只能存储到 2038 年。
索引规范
-
单个索引字段数不超过 5,单表索引数量不超过 5,索引设计遵循 B+ Tree 索引最左前缀匹配原则
-
选择区分度高的列作为索引
-
建立的索引能覆盖 80% 主要的查询,不求全,解决问题的主要矛盾
-
DML 和 order by 和 group by 字段要建立合适的索引
-
避免索引的隐式转换
-
避免冗余索引
关于索引规范,一定要记住索引这个东西是一把双刃剑,在加速读的同时也引入了很多额外的写入和锁,降低写入能力,这也是为什么要控制索引数原因。之前看到过不少人给表里每个字段都建了索引,其实对查询可能起不到什么作用。
冗余索引例子
-
idx_abc(a,b,c)
-
idx_a(a) 冗余
-
idx_ab(a,b) 冗余
隐式转换例子
字段:remark varchar(50) NOT Null
MySQL>SELECT id, gift_code FROM gift WHERE deal_id = 640 AND remark=115127; 1 row in set (0.14 sec) MySQL>SELECT id, gift_code FROM pool_gift WHEREdeal_id = 640 AND remark=‘115127’; 1 row in set (0.005 sec)
字段定义为 varchar,但传入的值是个 int,就会导致全表扫描,要求程序端要做好类型检查
SQL 类规范
-
尽量不使用存储过程、触发器、函数等
-
避免使用大表的 JOIN,MySQL 优化器对 join 优化策略过于简单
-
避免在数据库中进行数学运算和其他大量计算任务
-
SQL 合并,主要是指的 DML 时候多个 value 合并,减少和数据库交互
-
合理的分页,尤其大分页
-
UPDATE、DELETE 语句不使用 LIMIT ,容易造成主从不一致
数据库运维规范
运维规范主要内容
-
SQL 审核,DDL 审核和操作时间,尤其是 OnlineDDL
-
高危操作检查,Drop 前做好数据备份
-
权限控制和审计
-
日志分析,主要是指的 MySQL 慢日志和错误日志
-
高可用方案
-
数据备份方案
版本选择
-
MySQL 社区版,用户群体最大
-
MySQL 企业版,收费
-
Percona Server 版,新特性多
-
MariaDB 版,国内用户不多
建议选择优先级为:MySQL 社区版 > Percona Server > MariaDB > MySQL 企业版,不过现在如果大家使用 RDS 服务,基本还以社区版为主。
Online DDL 问题
原生 MySQL 执行 DDL 时需要锁表,且锁表期间业务是无法写入数据的,对服务影响很大,MySQL 对这方面的支持是比较差的。大表做 DDL 对 DBA 来说是很痛苦的,相信很多人经历过。如何做到 Online DDL 呢,是不是就无解了呢?当然不是!

上面表格里提到的 Facebook OSC 和 5.6 OSC 也是目前两种比较靠谱的方案
MySQL 5.6 的 OSC 方案还是解决不了 DDL 的时候到从库延时的问题,所以现在建议使用 Facebook OSC 这种思路更优雅
下图是 Facebook OSC 的思路

后来 Percona 公司根据 Facebook OSC 思路,用 perl 重写了一版,就是我们现在用得很多的 pt-online-schema-change,软件本身非常成熟,支持目前主流版本。
使用 pt-online-schema-change 的优点有:
-
无阻塞写入
-
完善的条件检测和延时负载策略控制
值得一提的是,腾讯互娱的 DBA 在内部分支上也实现了 Online DDL,之前测试过确实不错,速度快,原理是通过修改 InnoDB 存储格式来实现。
使用 pt-online-schema-change 的限制有:
-
改表时间会比较长 (相比直接 alter table 改表)
-
修改的表需要有唯一键或主键
-
在同一端口上的并发修改不能太多
可用性
关于可用性,我们今天分享一种无缝切主库方案,可以用于日常切换,使用思路也比较简单
在正常条件下如何无缝去做主库切换,核心思路是让新主库和从库停在相同位置,主要依赖 slave start until 语句,结合双主结构,考虑自增问题。

MySQL 集群方案:
-
集群方案主要是如何组织 MySQL 实例的方案
-
主流方案核心依然采用的是 MySQL 原生的复制方案
-
原生主从同步肯定存在着性能和安全性问题
MySQL 半同步复制:
现在也有一些理论上可用性更高的其它方案
-
Percona XtraDB Cluster(没有足够的把控力度,不建议上)
-
MySQL Cluster(有官方支持,不过实际用的不多)

红框内是目前大家使用比较多的部署结构和方案。当然异常层面的 HA 也有很多第三方工具支持,比如 MHA、MMM 等,推荐使用 MHA。
sharding 拆分问题
-
Sharding is very complex, so itʼs best not to shard until itʼs obvious that you will actually need to!
-
sharding 是按照一定规则数据重新分布的方式
-
主要解决单机写入压力过大和容量问题
-
主要有垂直拆分和水平拆分两种方式
-
拆分要适度,切勿过度拆分
-
有中间层控制拆分逻辑最好,否则拆分过细管理成本会很高
曾经管理的单表最大 60 亿+,单表数据文件大小 1TB+,人有时候就要懒一些。

上图是水平拆分和垂直拆分的示意图
数据库备份
首先要保证的,最核心的是数据库数据安全性。数据安全都保障不了的情况下谈其他的指标 (如性能等),其实意义就不大了。
备份的意义是什么呢?
-
数据恢复!
-
数据恢复!
-
数据恢复!
目前备份方式的几个纬度:
-
全量备份 VS 增量备份
-
热备 VS 冷备
-
物理备份 VS 逻辑备份
-
延时备份
-
全量 binlog 备份
建议方式:
-
热备+物理备份
-
核心业务:延时备份+逻辑备份
-
全量 binlog 备份
借用一下某大型互联网公司做的备份系统数据:一年 7000+次扩容,一年 12+次数据恢复,日志量每天 3TB,数据总量 2PB,每天备份数据量百 TB 级,全年备份 36 万次,备份成功了 99.9%。
主要做的几点:
-
备份策略集中式调度管理
-
xtrabackup 热备
-
备份结果统计分析
-
备份数据一致性校验
-
采用分布式文件系统存储备份
备份系统采用分布式文件系统原因:
-
解决存储分配的问题
-
解决存储 NFS 备份效率低下问题
-
存储集中式管理
-
数据可靠性更好
使用分布式文件系统优化点:
-
Pbzip 压缩,降低多副本存储带来的存储成本,降低网络带宽消耗
-
元数据节点 HA,提高备份集群的可用性
-
erasure code 方案调研
数据恢复方案
目前的 MySQL 数据恢复方案主要还是基于备份来恢复,可见备份的重要性。比如我今天下午 15 点删除了线上一张表,该如何恢复呢?首先确认删除语句,然后用备份扩容实例启动,假设备份时间点是凌晨 3 点,就还需要把凌晨 3 点到现在关于这个表的 binlog 导出来,然后应用到新扩容的实例上,确认好恢复的时间点,然后把删除表的数据导出来应用到线上。
性能优化
复制优化
MySQL 复制:
-
是 MySQL 应用得最普遍的应用技术,扩展成本低
-
逻辑复制
-
单线程问题,从库延时问题
-
可以做备份或读复制
问题很多,但是能解决基本问题。
上图是 MySQL 复制原理图,红框内就是 MySQL 一直被人诟病的单线程问题。
单线程问题也是 MySQL 主从延时的一个重要原因,单线程解决方案:
-
官方 5.6 + 多线程方案
-
Tungsten 为代表的第三方并行复制工具
-
sharding

上图是 MySQL5.6 目前实现的并行复制原理图,是基于库级别的复制,所以如果你只有一个库,使用这个意义不大。
当然 MySQL 也认识到 5.6 这种并行的瓶颈所在,所以在 5.7 引入了另外一种并行复制方式,基于 logical timestamp 的并行复制,并行复制不再受限于库的个数,效率会大大提升。

上图是 5.7 的 logical timestamp 的复制原理图
刚才我也提到 MySQL 原来只支持异步复制,这种数据安全性是非常差的,所以后来引入了半同步复制,从 5.5 开始支持。

上图是原生异步复制和半同步复制的区别。可以看到半同步通过从库返回 ACK 这种方式确认从库收到数据,数据安全性大大提高。
在 5.7 之后,半同步也可以配置你指定多个从库参与半同步复制,之前版本都是默认一个从库。
对于半同步复制效率问题有一个小的优化,就是使用 5.6 + 的 mysqlbinlog 以 daemon 方式作为从库,同步效率会好很多。
关于更安全的复制,MySQL 5.7 也是有方案的,方案名叫 Group replication 官方多主方案,基于 Corosync 实现。

主从延时问题
原因:一般都会做读写分离,其实从库压力反而比主库大/从库读写压力大非常容易导致延时。
解决方案:
-
首先定位延时瓶颈
-
如果是 IO 压力,可以通过升级硬件解决,比如替换 SSD 等
-
如果 IO 和 CPU 都不是瓶颈,非常有可能是 SQL 单线程问题,解决方案可以考虑刚才提到的并行复制方案
-
如果还有问题,可以考虑 sharding 拆分方案
提到延时不得不提到很坑人的 Seconds behind master,使用过 MySQL 的应该很熟悉。
这个值的源码里算法
long time_diff= ((long)(time(0) – mi->rli.last_master_timestamp) – mi->clock_diff_with_master);
Secondsbehindmaster来判断延时不可靠,在网络抖动或者一些特殊参数配置情况下,会造成这个值是 0 但其实延时很大了。通过 heartbeat 表插入时间戳这种机制判断延时是更靠谱的
复制注意点:
-
Binlog 格式,建议都采用 row 格式,数据一致性更好
-
Replication filter 应用
主从数据一致性问题:
-
row 格式下的数据恢复问题
InnoDB 优化
成熟开源事务存储引擎,支持 ACID,支持事务四个隔离级别,更好的数据安全性,高性能高并发,MVCC,细粒度锁,支持 O_DIRECT。
主要优化参数:
-
innodbfileper_table =1
-
innodbbufferpool_size,根据数据量和内存合理设置
-
innodbflushlog_attrxcommit= 0 1 2
-
innodblogfile_size,可以设置大一些
-
innodbpagesize
-
Innodbflushmethod = o_direct
-
innodbundodirectory 放到高速设备 (5.6+)
-
innodbbufferpool_dump
-
atshutdown ,bufferpool dump (5.6+)

上图是 5.5 4G 的 redo log 和 5.6 设置大于 4G redo log 文件性能对比,可以看到稳定性更好了。innodblogfile_size 设置还是很有意义的。
InnoDB 比较好的特性:
-
Bufferpool 预热和动态调整大小,动态调整大小需要 5.7 支持
-
Page size 自定义调整,适应目前硬件
-
InnoDB 压缩,大大降低数据容量,一般可以压缩 50%,节省存储空间和 IO,用 CPU 换空间
-
Transportable tablespaces,迁移 ibd 文件,用于快速单表恢复
-
Memcached API,full text,GIS 等
InnoDB 在 SSD 上的优化:
-
在 5.5 以上,提高 innodbwriteiothreads 和 innodbreadiothreads
-
innodbiocapacity 需要调大 *
-
日志文件和 redo 放到机械硬盘,undo 放到 SSD,建议这样,但必要性不大
-
atomic write, 不需要 Double Write Buffer
-
InnoDB 压缩
-
单机多实例
也要搞清楚 InnoDB 哪些文件是顺序读写,哪些是随机读写。
随机读写:
-
datadir
-
innodbdata file_path
-
innodbundo directory
顺序读写:
-
innodbloggrouphomedir
-
log-bin
InnoDB VS MyISAM:
-
数据安全性至关重要,InnoDB 完胜,曾经遇到过一次 90G 的 MyISAM 表 repair,花了两天时间,如果在线上几乎不可忍受
-
并发度高
-
MySQL 5.5 默认引擎改为 InnoDB,标志着 MyISAM 时代的落幕
TokuDB:
-
支持事务 ACID 特性,支持多版本控制 (MVCC)
-
基于 Fractal Tree Index,非常适合写入密集场景
-
高压缩比,原生支持 Online DDL
-
主流分支都支持,收费转开源 。目前可以和 InnoDB 媲美的存储引擎
目前主流使用 TokuDB 主要是看中了它的高压缩比,Tokudb 有三种压缩方式:quicklz、zlib、lzma,压缩比依次更高。现在很多使用 zabbix 的后端数据表都采用的 TokuDB,写入性能好,压缩比高。
下图是我之前做的测试对比和 InnoDB


上图是 sysbench 测试的和 InnoDB 性能对比图,可以看到 TokuDB 在测试过程中写入稳定性是非常好的。
tokudb 存在的问题:
-
官方分支还没很好的支持
-
热备方案问题,目前只有企业版才有
-
还是有 bug 的,版本更新比较快,不建议在核心业务上用
比如我们之前遇到过一个问题:TokuDB 的内部状态显示上一次完成的 checkpoint 时间是 “Jul 17 12:04:11 2014”,距离当时发现现在都快 5 个月了,结果堆积了大量 redo log 不能删除,后来只能重启实例,结果重启还花了七八个小时。
MySQL 优化相关的 case
Query cache,MySQL 内置的查询加速缓存,理念是好的, 但设计不够合理,有点 out。
锁的粒度非常大 MySQL 5.6 默认已经关闭
When the query cache helps, it can help a lot. When it hurts, it can hurt a lot. 明显前半句已经没有太大用处,在高并发下非常容易遇到瓶颈。
关于事务隔离级别 ,InnoDB 默认隔离级别是可重复读级别,当然 InnoDB 虽然是设置的可重复读,但是也是解决了幻读的,建议改成读已提交级别,可以满足大多数场景需求,有利于更高的并发,修改 transaction-isolation。


上图是一个比较经典的死锁 case,有兴趣可以测试下。
关于 SSD
关于 SSD,还是提一下吧。某知名大 V 说过 “最近 10 年对数据库性能影响最大的是闪存”,稳定性和性能可靠性已经得到大规模验证,多块 SATA SSD 做 Raid5,推荐使用。采用 PCIe SSD,主流云平台都提供 SSD 云硬盘支持。
最后说一下大家关注的单表 60 亿记录问题,表里数据也是线上比较核心的。
先说下当时情况,表结构比较简单,都是 bigint 这种整型,索引比较多,应该有 2-3 个,单表行数 60 亿+,单表容量 1.2TB 左右,当然内部肯定是有碎片的。
形成原因:历史遗留问题,按照我们前面讲的开发规范,这个应该早拆分了,当然不拆有几个原因:
-
性能未遇到瓶颈 ,主要原因
-
DBA 比较 “懒 “
-
想看看 InnoDB 的极限,挑战一下。不过风险也是很大的,想想如果在一个 1.2TB 表上加个字段加个索引,那感觉绝对酸爽。还有就是单表恢复的问题,恢复时间不可控。
我们后续做的优化 ,采用了刚才提到的 TokuDB,单表容量在 InnoDB 下 1TB+,使用 Tokudb 的 lzma 压缩到 80GB,压缩效果非常好。这样也解决了单表过大恢复时间问题,也支持 online DDL,基本达到我们预期。
今天讲的主要针对 MySQL 本身优化和规范性质的东西,还有一些比较好的运维经验,希望大家能有所收获。今天这些内容是为后续数据库做平台化的基础。我今天分享就到这里,谢谢大家。
QA
Q1:use schema;select from table; 和 select from schema.table; 两种写法有什么不一样吗?会对主从同步有影响吗?
对于主从复制来说执行效率上差别不大,不过在使用 replication filter 时候这种情况需要小心,应该要使用 ReplicateWildIgnoreTable 这种参数,如果不使用带 wildignore,第一种方式会有问题,过滤不起作用。
Q2:对于用于 MySQL 的 ssd,测试方式和 ssd 的参数配置方面,有没有好的建议?主要针对 ssd 的配置哈
关于 SATA SSD 配置参数,建议使用 Raid5,想更保险使用 Raid50,更土豪使用 Raid 10

上图是主要的参数优化,性能提升最大的是第一个修改调度算法的
Q3:数据库规范已制定好,如何保证开发人员必须按照规范来开发?
关于数据库规范实施问题,也是有两个方面吧,第一、定期给开发培训开发规范,让开发能更了解。第二、还是在流程上规范,比如把我们日常通用的建表和字段策略固化到程序,做成自动化审核系统。这两方面结合 效果会比较好。
Q4:如何最大限度提高 innodb 的命中率?
这个问题前提是你的数据要有热点,读写热点要有交集,否则命中率很难提高。在有热点的前提下,也要求你的你的内存要足够大,能够存更多的热点数据。尽量不要做一些可能污染 bufferpool 的操作,比如全表扫描这种。
Q5:主从复制的情况下,如果有 CAS 这样的需求,是不是只能强制连主库?因为有延迟的存在,如果读写不在一起的话,会有脏数据。
如果有 CAS 需求,确实还是直接读主库好一些,因为异步复制还是会有延迟的。只要 SQL 优化的比较好,读写都在主库也是没什么问题的。
Q6:关于开发规范,是否有必要买国标?
这个国标是什么东西,不太了解。不过从字面看,国标应该也是偏学术方面的,在具体工程实施时候未必能用好。
Q7:主从集群能不能再细化一点那?不知道这样问合适不?
看具体哪方面吧。主从集群每个小集群一般都是采用一主多从方式,每个小集群对应特定的一组业务。然后监控备份和 HA 都是在每个小集群实现。
Q8:如何跟踪数据库 table 某个字段值发生变化?
追踪字段值变化可以通过分析 row 格式 binlog 好一些。比如以前同事就是通过自己开发的工具来解析 row 格式 binlog,跟踪数据行变化。
Q9:对超大表水平拆分,在使用 MySQL 中间件方面有什么建议和经验分享?
对于超大表水平拆分,在中间件上经验不是很多,早期人肉搞过几次。也使用过自己研发的数据库中间件,不过线上应用的规模不大。关于目前众多的开源中间件里,360 的 atlas 是目前还不错的,他们公司内部应用的比较多。
Q10:我们用的 MySQL proxy 做读负载,但是少量数据压力下并没有负载,请问有这回事吗?
少量数据压力下,并没有负载 ,这个没测试过,不好评价
Q11:对于 binlog 格式,为什么只推荐 row,而不用网上大部分文章推荐的 Mix ?
这个主要是考虑数据复制的可靠性,row 更好。mixed 含义是指如果有一些容易导致主从不一致的 SQL ,比如包含 UUID 函数的这种,转换为 row。既然要革命,就搞的彻底一些。这种 mix 的中间状态最坑人了。
Q12: 读写分离,一般是在程序里做,还是用 proxy ,用 proxy 的话一般用哪个?
这个还是独立写程序好一些,与程序解耦方便后期维护。proxy 国内目前开源的比较多,选择也要慎重。
Q13: 我想问一下关于 mysql 线程池相关的问题,什么情况下适合使用线程池,相关的参数应该如何配置,老师有这方面的最佳实践没有?
线程池这个我也没测试过。从原理上来说,短链接更适合用线程池方式,减少建立连接的消耗。这个方面的最佳配置,我还没测试过,后面测试有进展可以再聊聊。
Q14: 误删数据这种,数据恢复流程是怎么样的 (从库也被同步删除的情况)?
看你删除数据的情况,如果只是一张表,单表在几 GB 或几十 GB。如果能有延时备份,对于数据恢复速度是很有好处的。恢复流程可以参考我刚才分享的部分。目前的 MySQL 数据恢复方案主要还是基于备份来恢复 ,可见备份的重要性。比如我今天下午 15 点删除了线上一张表,该如何恢复呢。首先确认删除语句,然后用备份扩容实例启动,假设备份时间点是凌晨 3 点。就还需要把凌晨 3 点到现在关于这个表的 binlog 导出来,然后应用到新扩容的实例上。确认好恢复的时间点,然后把删除表的数据导出来应用到线上。
Q15: 关于备份,binlog 备份自然不用说了,物理备份有很多方式,有没有推荐的一种,逻辑备份在量大的时候恢复速度比较慢,一般用在什么场景?
物理备份采用 xtrabackup 热备方案比较好。逻辑备份一般用在单表恢复效果会非常好。比如你删了一个 2G 表,但你总数据量 2T,用物理备份就会要慢了,逻辑备份就非常有用了。
-------------------------------------------------------------------------------------------------------------------------------------
秦 迪/5.4 微博在大规模、高负载系统问题排查方法379
5.4.1 背景379
5.4.2 排查方法及线索.379
5.4.3 总结384
5.4.4 疑问与解惑385
-------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------
秦 迪/5.5 系统运维之为什么每个团队存在大量烂代码387
5.5.1 写烂代码很容易.387
5.5.2 烂代码终究是烂代码388
5.5.3 重构不是万能药.392
5.5.4 写好代码很难.393
5.5.5 悲观的结语394
-------------------------------------------------------------------------------------------------------------------------------------
(1 条消息) 关于烂代码的那些事 - 为什么每个团队存在大量烂代码_weixin_45583158 的博客 - CSDN 博客
编者按:本文由秦迪向「高可用架构」投稿,介绍编写好代码的思考与感悟。转载请注明来自高可用架构公众号「ArchNotes」。
秦迪,微博研发中心技术专家,2013 年加入微博,负责微博平台通讯系统的设计和研发、微博平台基础工具的开发和维护,并负责微博平台的架构改进工作,在工作中擅长排查复杂系统的各类疑难杂症。爱折腾,喜欢研究从内核到前端的所有方向,近几年重点关注大规模系统的架构设计和性能优化,重度代码洁癖:以 code review 为己任,重度工具控:有现成工具的问题就用工具解决,没有工具能解决的问题就写个工具解决。业余时间喜欢偶尔换个语言写代码放松一下。
最近写了不少代码,review 了不少代码,也做了不少重构,总之是对着烂代码工作了几周。为了抒发一下这几周里好几次到达崩溃边缘的情绪,我决定写一篇文章谈一谈烂代码的那些事。这里是上篇,谈一谈烂代码产生的原因和现象。
1、写烂代码很容易
刚入程序员这行的时候经常听到一个观点:你要把精力放在 ABCD(需求文档 / 功能设计 / 架构设计 / 理解原理)上,写代码只是把想法翻译成编程语言而已,是一个没什么技术含量的事情。
当时的我在听到这种观点时会有一种近似于高冷的不屑:你们就是一群傻 X,根本不懂代码质量的重要性,这么下去迟早有一天会踩坑,呸。
可是几个月之后,他们似乎也没怎么踩坑。而随着编程技术一直在不断发展,带来了更多的我以前认为是傻 X 的人加入到程序员这个行业中来。
语言越来越高级、封装越来越完善,各种技术都在帮助程序员提高生产代码的效率,依靠层层封装,程序员真的不需要了解一丁点技术细节,只要把需求里的内容逐行翻译出来就可以了。
很多程序员不知道要怎么组织代码、怎么提升运行效率、底层是基于什么原理,他们写出来的是在我心目中一堆垃圾代码。但是那一坨垃圾代码竟然能正常工作。
即使我认为他们写的代码是垃圾,但是从不接触代码的人的视角来看(比如说你的 boss),代码编译过了,测试过了,上线运行了一个月都没出问题,你还想要奢求什么?
所以,即使不情愿,也必须承认,时至今日,写代码这件事本身没有那么难了。
2、烂代码终究是烂代码
但是偶尔有那么几次,写烂代码的人离职了之后,事情似乎又变得不一样了。
想要修改功能时却发现程序里充斥着各种无法理解的逻辑、改完之后莫名其妙的 bug 一个接一个,接手这个项目的人开始漫无目的的加班,并且原本一个挺乐观开朗的人渐渐的开始无法接受了。
我总结了几类经常被鄙视到的烂代码:
2.1 意义不明
能力差的程序员容易写出意义不明的代码,他们不知道自己究竟在做什么。
就像这样:
|
1 2 3 4 5 6 |
public void save() { for(int i=0;i<100;i++) { // 防止保存失败,重试 100 次 document.save(); } } |
对于这类程序员,建议他们尽早转行。
2.2 不说人话
不说人话是新手最经常出现的问题,直接的表现就是写了一段很简单的代码,其他人却看不懂。
比如下面这段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
public boolean getUrl(Long id) { UserProfile up = us.getUser(ms.get(id).getMessage().aid); if (up == null) { return false; } if (up.type == 4 || ((up.id >> 2) & 1) == 1) { return false; } if(Util.getUrl(up.description)) { return true; } else { return false; } } |
还有很多程序员喜欢复杂,各种宏定义、位运算之类写的天花乱坠,生怕代码让别人一下子看懂了会显得自己水平不够。
简单的说,他们的代码是写给机器的,不是给人看的。
2.3 不恰当的组织
不恰当的组织是高级一些的烂代码,程序员在写过一些代码之后,有了基本的代码风格,但是对于规模大一些的工程的掌控能力不够,不知道代码应该如何解耦、分层和组织。
这种反模式的现象是经常会看到一段代码在工程里拷来拷去;某个文件里放了一大坨堆砌起来的代码;一个函数堆了几百上千行;或者一个简单的功能七拐八绕的调了几十个函数,在某个难以发现的猥琐的小角落里默默的调用了某些关键逻辑。
这类代码大多复杂度高,难以修改,经常一改就崩;而另一方面,创造了这些代码的人倾向于修改代码,畏惧创造代码,他们宁愿让原本复杂的代码一步步变得更复杂,也不愿意重新组织代码。当你面对一个几千行的类,问为什么不把某某逻辑提取出来的时候,他们会说:
“但是,那样就多了一个类了呀。”
2.4. 假设和缺少抽象
相对于前面的例子,假设这种反模式出现的场景更频繁,花样更多,始作俑者也更难以自己意识到问题。比如:
|
1 2 3 4 |
public String loadString() { File file = new File("c:/config.txt"); // read something } |
文件路径变更的时候,会把代码改成这样:
|
1 2 3 4 |
public String loadString(String name) { File file = new File(name); // read something } |
需要加载的内容更丰富的时候,会再变成这样:
|
1 2 3 4 5 6 7 8 |
public String loadString(String name) { File file = new File(name); // read something } public Integer loadInt(String name) { File file = new File(name); // read something } |
之后可能会再变成这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public String loadString(String name) { File file = new File(name); // read something } public String loadStringUtf8(String name) { File file = new File(name); // read something } public Integer loadInt(String name) { File file = new File(name); // read something } public String loadStringFromNet(String url) { HttpClient ... } public Integer loadIntFromNet(String url) { HttpClient ... } |
这类程序员往往是项目组里开发效率比较高的人,但是大量的业务开发工作导致他们不会做多余的思考,他们的口头禅是:“我每天要做 XX 个需求” 或者 “先做完需求再考虑其他的吧”。
这种反模式表现出来的后果往往是代码很难复用,面对 deadline 的时候,程序员迫切的想要把需求落实成代码,而这往往也会是个循环:写代码的时候来不及考虑复用,代码难复用导致之后的需求还要继续写大量的代码。
一点点积累起来的大量的代码又带来了组织和风格一致性等问题,最后形成了一个新功能基本靠拷的遗留系统。
2.5 还有吗
烂代码还有很多种类型,沿着功能 - 性能 - 可读 - 可测试 - 可扩展这条路线走下去,还能看到很多匪夷所思的例子。
那么什么是烂代码?个人认为,烂代码包含了几个层次:
-
如果只是一个人维护的代码,满足功能和性能要求倒也足够了。
-
如果在一个团队里工作,那就必须易于理解和测试,让其它人员有能力修改各自的代码。
-
同时,越是处于系统底层的代码,扩展性也越重要。
所以,当一个团队里的底层代码难以阅读、耦合了上层的逻辑导致难以测试、或者对使用场景做了过多的假设导致难以复用时,虽然完成了功能,它依然是垃圾代码。
2.6 够用的代码
而相对的,如果一个工程的代码难以阅读,能不能说这个是烂代码?很难下定义,可能算不上好,但是能说它烂吗?如果这个工程自始至终只有一个人维护,那个人也维护的很好,那它似乎就成了 “够用的代码”。
很多工程刚开始可能只是一个人负责的小项目,大家关心的重点只是代码能不能顺利的实现功能、按时完工。
过上一段时间,其他人参与时才发现代码写的有问题,看不懂,不敢动。需求方又开始催着上线了,怎么办?只好小心翼翼的只改逻辑而不动结构,然后在注释里写上这么实现很 ugly,以后明白内部逻辑了再重构。
再过上一段时间,有个相似的需求,想要复用里面的逻辑,这时才意识到代码里做了各种特定场景的专用逻辑,复用非常麻烦。为了赶进度只好拷代码然后改一改。问题解决了,问题也加倍了。
几乎所有的烂代码都是从 “够用的代码” 演化来的,代码没变,使用代码的场景发生变了,原本够用的代码不符合新的场景,那么它就成了烂代码。
3、重构不是万能药
程序员最喜欢跟程序员说的谎话之一就是:现在进度比较紧,等 X 个月之后项目进度宽松一些再去做重构。
不能否认在某些(极其有限的)场景下重构是解决问题的手段之一,但是写了不少代码之后发现,重构往往是程序开发过程中最复杂的工作。花一个月写的烂代码,要花更长的时间、更高的风险去重构。
曾经经历过几次忍无可忍的大规模重构,每一次重构之前都是找齐了组里的高手,开了无数次分析会,把组内需求全部暂停之后才敢开工,而重构过程中往往哀嚎遍野,几乎每天都会出上很多意料之外的问题,上线时也几乎必然会出几个问题。
从技术上来说,重构复杂代码时,要做三件事:理解旧代码、分解旧代码、构建新代码。而待重构的旧代码往往难以理解;模块之间过度耦合导致牵一发而动全身,不易控制影响范围;旧代码不易测试导致无法保证新代码的正确性。
这里还有一个核心问题,重构的复杂度跟代码的复杂度不是线性相关的。比如有 1000 行烂代码,重构要花 1 个小时,那么 5000 行烂代码的重构可能要花 2、3 天。要对一个失去控制的工程做重构,往往还不如重写更有效率。
而抛开具体的重构方式,从受益上来说,重构也是一件很麻烦的事情:它很难带来直接受益,也很难量化。这里有个很有意思的现象,基本关于重构的书籍无一例外的都会有独立的章节介绍 “如何向 boss 说明重构的必要性”。
重构之后能提升多少效率?能降低多少风险?很难答上来,烂代码本身就不是一个可以简单的标准化的东西。
举个例子,一个工程的代码可读性很差,那么它会影响多少开发效率?
你可以说:之前改一个模块要 3 天,重构之后 1 天就可以了。但是怎么应对 “不就是做个数据库操作吗为什么要 3 天” 这类问题?烂代码 “烂” 的因素有不确定性、开发效率也因人而异,想要证明这个东西 “确实” 会增加两天开发时间,往往反而会变成 “我看了 3 天才看懂这个函数是做什么的” 或者 “我做这么简单的修改要花 3 天” 这种神经病才会去证明的命题。
而另一面,许多技术负责人也意识到了代码质量和重构的必要性,“那就重构嘛”,或者 “如果看到问题了,那就重构”。上一个问题解决了,但实际上关于重构的代价和收益仍然是一笔糊涂账,在没有分配给你更多资源、没有明确的目标、没有具体方法的情况下,很难想象除了有代码洁癖的人还有谁会去执行这种莫名 其妙的任务。
于是往往就会形成这种局面:
-
不写代码的人认为应该重构,重构很简单,无论新人还是老人都有责任做重构。
-
写代码老手认为应该迟早应该重构,重构很难,现在凑合用,这事别落在我头上。
-
写代码的新手认为不出 bug 就谢天谢地了,我也不知道怎么重构。
4、写好代码很难
与写出烂代码不同的是,想写出好代码有很多前提:
-
理解要开发的功能需求。
-
了解程序的运行原理。
-
做出合理的抽象。
-
组织复杂的逻辑。
-
对自己开发效率的正确估算。
-
持续不断的练习。
写出好代码的方法论很多,但我认为写出好代码的核心反而是听起来非常 low 的 “持续不断的练习”。这里就不展开了,留到下篇再说。
很多程序员在写了几年代码之后并没有什么长进,代码仍然烂的让人不忍直视,原因有两个主要方面:
-
环境是很重要的因素之一,在烂代码的熏陶下很难理解什么是好代码,知道的人大部分也会选择随波逐流。
-
还有个人性格之类的说不清道不明的主观因素,写出烂代码的程序员反而都是一些很好相处的人,他们往往热爱公司团结同事平易近人工作任劳任怨–只是代码很烂而已。
而工作几年之后的人很难再说服他们去提高代码质量,你只会反复不断的听到:“那又有什么用呢?”或者 “以前就是这么做的啊?” 之类的说法。
那么从源头入手,提高招人时对代码的质量的要求怎么样?
前一阵面试的时候增加了白板编程、最近又增加了上机编程的题目。发现了一个现象:一个人工作了几年、做过很多项目、带过团队、发了一些文章,不一定能代表他代码写的好;反之,一个人代码写的好,其它方面的能力一般不会太差。
举个例子,最近喜欢用 “写一个代码行数统计工具” 作为面试的上机编程题目。很多人看到题目之后第一反映是,这道题太简单了,这不就是写写代码嘛。
从实际效果来看,这道题识别度却还不错。
首先,题目足够简单,即使没有看过《面试宝典》之类书的人也不会吃亏。而题目的扩展性很好,即使提前知道题目,配合不同的条件,可以变成不同的题目。比如要求按文件类型统计行数、或者要求提高统计效率、或者统计的同时输出某些单词出现的次数,等等。
从考察点来看,首先是基本的树的遍历算法;其次有一定代码量,可以看出程序员对代码的组织能力、对问题的抽象能力;上机编码可以很简单的看出应聘者是不是很久没写程序了;还包括对于程序易用性和性能的理解。
最重要的是,最后的结果是一个完整的程序,我可以按照日常工作的标准去评价程序员的能力,而不是从十几行的函数里意淫这个人在日常工作中大概会有什么表现。
但即使这样,也很难拍着胸脯说,这个人写的代码质量没问题。毕竟面试只是代表他有写出好代码的能力,而不是他将来会写出好代码。
5、悲观的结语
说了那么多,结论其实只有两条,作为程序员:
-
不要奢望其他人会写出高质量的代码
-
不要以为自己写出来的是高质量的代码
如果你看到了这里还没有丧失希望,那么可以期待一下这篇文章的第二部分,关于如何提高代码质量的一些建议和方法。
本文由秦迪投稿,编辑四正,想更多交流上述高质量代码话题,可以回复 join 申请进群。转载本文请注明来自高可用架构 「ArchNotes」微信公众号并包含以下二维码。
1、写烂代码很容易2、烂代码终究是烂代码但是偶尔有那么几次,写烂代码的人离职了之后,事情似乎又变得不一样了。2.1 意义不明2.2 不说人话2.3 不恰当的组织2.4. 假设和缺少抽象2.5 还有吗2.6 够用的代码3、重构不是万能药4、写好代码很难5、悲观的结语
-------------------------------------------------------------------------------------------------------------------------------------
秦 迪/5.6 系统运维之评价代码优劣的方法395
5.6.1 什么是好代码.395
5.6.2 结语403
5.6.3 参考阅读403
-------------------------------------------------------------------------------------------------------------------------------------
关于烂代码的那些事 – 评价代码优劣的方法 - 云 + 社区 - 腾讯云秦迪,微博研发中心技术专家,2013 年加入微博,负责微博平台通讯系统的设计和研发、微博平台基础工具的开发和维护,并负责微博平台的架构改进工作,在工作中擅长排查...
秦迪,微博研发中心技术专家,2013 年加入微博,负责微博平台通讯系统的设计和研发、微博平台基础工具的开发和维护,并负责微博平台的架构改进工作,在工作中擅长排查复杂系统的各类疑难杂症。爱折腾,喜欢研究从内核到前端的所有方向,近几年重点关注大规模系统的架构设计和性能优化,重度代码洁癖:以 code review 为己任,重度工具控:有现成工具的问题就用工具解决,没有工具能解决的问题就写个工具解决。业余时间喜欢偶尔换个语言写代码放松一下。
“代码重复分为两种:模块内重复和模块间重复。无论何种重复,都在一定程度上说明了程序员的水平有问题。” —— 秦迪
这是烂代码系列的第二篇,在文章中我会跟大家讨论一下如何尽可能高效和客观的评价代码的优劣。 在发布了关于烂代码的那些事(上)之后(参看文末链接),发现这篇文章竟然意外的很受欢迎,很多人也描 (tu) 述(cao)了各自代码中这样或者那样的问题。最近部门在组织 bootcamp,正好我负责培训代码质量部分,在培训课程中让大家花了不少时间去讨论、改进、完善自己的代码。虽然刚毕业的同学对于代码质量都很用心,但最终呈现出来的质量仍然没能达到 “十分优秀” 的程度。 究其原因,主要是不了解好的代码 “应该” 是什么样的。
1、什么是好代码
写代码的第一步是理解什么是好代码。在准备 bootcamp 的课程的时候,我就为这个问题犯了难,我尝试着用一些精确的定义区分出 “优等品”、“良品”、“不良品”;但是在总结的过程中,关于“什么是好代码” 的描述却大多没有可操作性。
1.1. 好代码的定义
随便从网上搜索了一下 “优雅的代码”,找到了下面这样的定义:
Bjarne Stroustrup,C++ 之父:
逻辑应该是清晰的,bug 难以隐藏;
依赖最少,易于维护;
错误处理完全根据一个明确的策略;
性能接近最佳化,避免代码混乱和无原则的优化;
整洁的代码只做一件事。
Grady Booch,《面向对象分析与设计》作者:
整洁的代码是简单、直接的;
整洁的代码,读起来像是一篇写得很好的散文;
整洁的代码永远不会掩盖设计者的意图,而是具有少量的抽象和清晰的控制行。
Michael Feathers,《修改代码的艺术》作者:
整洁的代码看起来总是像很在乎代码质量的人写的;
没有明显的需要改善的地方;
代码的作者似乎考虑到了所有的事情。
看起来似乎说的都很有道理,可是实际评判的时候却难以参考,尤其是对于新人来说,如何理解 “简单的、直接的代码” 或者“没有明显的需要改善的地方”?
而实践过程中,很多同学也确实面对这种问题:对自己的代码总是处在一种心里不踏实的状态,或者是自己觉得很好了,但是却被其他人认为很烂,甚至有几次我和新同学因为代码质量的标准一连讨论好几天,却谁也说服不了谁:我们都坚持自己对于好代码的标准才是正确的。
在经历了无数次 code review 之后,我觉得这张图似乎总结的更好一些:
代码质量的评价标准某种意义上有点类似于文学作品,比如对小说的质量的评价主要来自于它的读者,由个体主观评价形成一个相对客观的评价。并不是依靠字数,或者作者使用了哪些修辞手法之类的看似完全客观但实际没有什么意义的评价手段。
但代码和小说还有些不一样,它实际存在两个读者:计算机和程序员。就像上篇文章里说的,即使所有程序员都看不懂这段代码,它也是可以被计算机理解并运行的。
所以对于代码质量的定义我需要于从两个维度分析:主观的,被人类理解的部分;还有客观的,在计算机里运行的状况。
既然存在主观部分,那么就会存在个体差异,对于同一段代码评价会因为看代码的人的水平不同而得出不一样的结论,这也是大多数新人面对的问题:他们没有一个可以执行的评价标准,所以写出来的代码质量也很难提高。
有些介绍代码质量的文章讲述的都是倾向或者原则,虽然说的很对,但是实际指导作用不大。所以在这篇文章里我希望尽可能把评价代码的标准用(我自认为)与实际水平无关的评价方式表示出来。
1.2. 可读的代码
在权衡很久之后,我决定把可读性的优先级排在前面:一个程序员更希望接手一个有 bug 但是看的懂的工程,还是一个没 bug 但是看不懂的工程?如果是后者,可以直接关掉这个网页,去做些对你来说更有意义的事情。
1.2.1. 逐字翻译
在很多跟代码质量有关的书里都强调了一个观点:程序首先是给人看的,其次才是能被机器执行,我也比较认同这个观点。在评价一段代码能不能让人看懂的时候,我习惯让作者把这段代码逐字翻译成中文,试着组成句子,之后把中文句子读给另一个人没有看过这段代码的人听,如果另一个人能听懂,那么这段代码的可读性基本就合格了。
用这种判断方式的原因很简单:其他人在理解一段代码的时候就是这么做的。阅读代码的人会一个词一个词的阅读,推断这句话的意思,如果仅靠句子无法理解,那么就需要联系上下文理解这句代码,如果简单的联系上下文也理解不了,可能还要掌握更多其它部分的细节来帮助推断。大部分情况下,理解一句代码在做什么需要联系的上下文越多,意味着代码的质量越差。
逐字翻译的好处是能让作者能轻易的发现那些只有自己知道的、没有体现在代码里的假设和可读性陷阱。无法从字面意义上翻译出原本意思的代码大多都是烂代码,比如 “ms 代表 messageService “,或者 “ ms.proc() 是发消息 “,或者 “ tmp 代表当前的文件”。
1.2.2. 遵循约定
约定包括代码和文档如何组织,注释如何编写,编码风格的约定等等,这对于代码未来的维护很重要。对于遵循何种约定没有一个强制的标准,不过我更倾向于遵守更多人的约定。
与开源项目保持风格一致一般来说比较靠谱,其次也可以遵守公司内部的编码风格。但是如果公司内部的编码风格和当前开源项目的风格冲突比较严重,往往代表着这个公司的技术倾向于封闭,或者已经有些跟不上节奏了。
但是无论如何,遵守一个约定总比自己创造出一些规则要好很多,这降低了理解、沟通和维护的成本。如果一个项目自己创造出了一些奇怪的规则,可能意味着作者看过的代码不够多。
一个工程是否遵循了约定往往需要代码阅读者有一定经验,或者需要借助 checkstyle 这样的静态检查工具。如果感觉无处下手,那么大部分情况下跟着 google 做应该不会有什么大问题:可以参考 google code style ,其中一部分有对应的 中文版 。
另外,没有必要纠结于遵循了约定到底有什么收益,就好像走路是靠左好还是靠右好一样,即使得出了结论也没有什么意义,大部分约定只要遵守就可以了。
1.2.3. 文档和注释
文档和注释是程序很重要的部分,他们是理解一个工程或项目的途径之一。两者在某些场景下定位会有些重合或者交叉(比如 javadoc 实际可以算是文档)。
对于文档的标准很简单,能找到、能读懂就可以了,一般来说我比较关心这几类文档:
对于项目的介绍,包括项目功能、作者、目录结构等,读者应该能 3 分钟内大致理解这个工程是做什么的。
针对新人的 QuickStart,读者按照文档说明应该能在 1 小时内完成代码构建和简单使用。
针对使用者的详细说明文档,比如接口定义、参数含义、设计等,读者能通过文档了解这些功能(或接口)的使用方法。
有一部分注释实际是文档,比如之前提到的 javadoc。这样能把源码和注释放在一起,对于读者更清晰,也能简化不少文档的维护的工作。
还有一类注释并不作为文档的一部分,比如函数内部的注释,这类注释的职责是说明一些代码本身无法表达的作者在编码时的思考,比如 “为什么这里没有做 XXX”,或者 “这里要注意 XXX 问题”。
一般来说我首先会关心注释的数量:函数内部注释的数量应该不会有很多,也不会完全没有,个人的经验值是滚动几屏幕看到一两处左右比较正常。过多的话可能意味着代码本身的可读性有问题,而如果一点都没有可能意味着有些隐藏的逻辑没有说明,需要考虑适当的增加一点注释了。
其次也需要考虑注释的质量:在代码可读性合格的基础上,注释应该提供比代码更多的信息。文档和注释并不是越多越好,它们可能会导致维护成本增加。关于这部分的讨论可以参考简洁部分的内容。
1.2.4. 推荐阅读
《代码整洁之道》
1.3. 可发布的代码
新人的代码有一个比较典型的特征,由于缺少维护项目的经验,写的代码总会有很多考虑不到的地方。比如说测试的时候似乎没什么异常,项目发布之后才发现有很多意料之外的状况;而出了问题之后不知道从哪下手排查,或者仅能让系统处于一个并不稳定的状态,依靠一些巧合勉强运行。
1.3.1. 处理异常
新手程序员普遍没有处理异常的意识,但代码的实际运行环境中充满了异常:服务器会死机,网络会超时,用户会胡乱操作,不怀好意的人会恶意攻击你的系统。
我对一段代码异常处理能力的第一印象来自于单元测试的覆盖率。大部分异常难以在开发或者测试环境里复现,即使有专业的测试团队也很难在集成测试环境中模拟所有的异常情况。
而单元测试可以比较简单的模拟各种异常情况,如果一个模块的单元测试覆盖率连 50% 都不到,很难想象这些代码考虑了异常情况下的处理,即使考虑了,这些异常处理的分支都没有被验证过,怎么指望实际运行环境中出现问题时表现良好呢?
1.3.2. 处理并发
我收到的很多简历里都写着:精通并发编程 / 熟悉多线程机制,诸如此类,跟他们聊的时候也说的头头是道,什么锁啊互斥啊线程池啊同步啊信号量啊一堆一堆的名词滔滔不绝。而给应聘者一个实际场景,让应聘者写一段很简单的并发编程的小程序,能写好的却不多。
实际上并发编程也确实很难,如果说写好同步代码的难度为 5,那么并发编程的难度可以达到 100 。这并不是危言耸听,很多看似稳定的程序,在面对并发场景的时候仍然可能出现问题:比如最近我们就碰到了一个 linux kernel 在调用某个系统函数时由于同步问题而出现 crash 的情况。
而是否高质量的实现并发编程的关键并不是是否应用了某种同步策略,而是看代码中是否保护了共享资源:
局部变量之外的内存访问都有并发风险(比如访问对象的属性,访问静态变量等)
访问共享资源也会有并发风险(比如缓存、数据库等)。
被调用方如果不是声明为线程安全的,那么很有可能存在并发问题(比如 java 的 hashmap )。
所有依赖时序的操作,即使每一步操作都是线程安全的,还是存在并发问题(比如先删除一条记录,然后把记录数减一)。
前三种情况能够比较简单的通过代码本身分辨出来,只要简单培养一下自己对于共享资源调用的敏感度就可以了。
但是对于最后一种情况,往往很难简单的通过看代码的方式看出来,甚至出现并发问题的两处调用并不是在同一个程序里(比如两个系统同时读写一个数据库,或者并发的调用了一个程序的不同模块等)。但是,只要是代码里出现了不加锁的,访问共享资源的 “先做 A,再做 B” 之类的逻辑,可能就需要提高警惕了。
1.3.3. 优化性能
性能是评价程序员能力的一个重要指标,很多程序员也对程序的性能津津乐道。但程序的性能很难直接通过代码看出来,往往要借助于一些性能测试工具,或者在实际环境中执行才能有结果。
如果仅从代码的角度考虑,有两个评价执行效率的办法:
算法的时间复杂度,时间复杂度高的程序运行效率必然会低。
单步操作耗时,单步耗时高的操作尽量少做,比如访问数据库,访问 io 等。
而实际工作中,也会见到一些程序员过于热衷优化效率,相对的会带来程序易读性的降低、复杂度提高、或者增加工期等等。对于这类情况,简单的办法是让作者说出这段程序的瓶颈在哪里,为什么会有这个瓶颈,以及优化带来的收益。
当然,无论是优化不足还是优化过度,判断性能指标最好的办法是用数据说话,而不是单纯看代码,性能测试这部分内容有些超出这篇文章的范围,就不详细展开了。
1.3.4. 日志
日志代表了程序在出现问题时排查的难易程度,经 (jing) 验(chang)丰 (cai) 富(keng)的程序员大概都会遇到过这个场景:排查问题时就少一句日志,查不到某个变量的值不知道是什么,导致死活分析不出来问题到底出在哪。
对于日志的评价标准有三个:
日志是否足够,所有异常、外部调用都需要有日志,而一条调用链路上的入口、出口和路径关键点上也需要有日志。
日志的表达是否清晰,包括是否能读懂,风格是否统一等。这个的评价标准跟代码的可读性一样,不重复了。
日志是否包含了足够的信息,这里包括了调用的上下文、外部的返回值,用于查询的关键字等,便于分析信息。
对于线上系统来说,一般可以通过调整日志级别来控制日志的数量,所以打印日志的代码只要不对阅读造成障碍,基本上都是可以接受的。
1.3.5. 扩展阅读
《Release It!: Design and Deploy Production-Ready Software》(不要看中文版,翻译的实在是太烂了)
Numbers Everyone Should Know
1.4. 可维护的代码
相对于前两类代码来说,可维护的代码评价标准更模糊一些,因为它要对应的是未来的情况,一般新人很难想象现在的一些做法会对未来造成什么影响。不过根据我的经验,一般来说,只要反复的提问两个问题就可以了:
他离职了怎么办?
他没这么做怎么办?
1.4.1. 避免重复
几乎所有程序员都知道要避免拷代码,但是拷代码这个现象还是不可避免的成为了程序可维护性的杀手。
代码重复分为两种:模块内重复和模块间重复。无论何种重复,都在一定程度上说明了程序员的水平有问题,模块内重复的问题更大一些,如果在同一个文件里都能出现大片重复的代码,那表示他什么不可思议的代码都有可能写出来。
对于重复的判断并不需要反复阅读代码,一般来说现代的 IDE 都提供了检查重复代码的工具,只需点几下鼠标就可以了。
除了代码重复之外,很多热衷于维护代码质量的程序员新人很容易出现另一类重复:信息重复。
我见过一些新人喜欢在每行代码前面写一句注释,比如:
// 成员列表的长度 > 0 并且 0 && memberList.size() < 200) {
// 返回当前成员列表
return memberList;
}
看起来似乎很好懂,但是几年之后,这段代码就变成了:
// 成员列表的长度 > 0 并且 0 && memberList.size() < 200 || (tmp.isOpen() && flag)) {
// 返回当前成员列表
return memberList;
}
再之后可能会改成这样:
//
// 成员列表的长度 > 0 并且 0 && memberList.size() < 200 || (tmp.isOpen() && flag)) {
// 返回当前成员列表
// return memberList;
//}
if(tmp.isOpen() && flag) {
return memberList;
}
随着项目的演进,无用的信息会越积越多,最终甚至让人无法分辨哪些信息是有效的,哪些是无效的。
如果在项目中发现好几个东西都在做同一件事情,比如通过注释描述代码在做什么,或者依靠注释替代版本管理的功能,那么这些代码也不能称为好代码。
1.4.2. 模块划分
模块内高内聚与模块间低耦合是大部分设计遵循的标准,通过合理的模块划分能够把复杂的功能拆分为更易于维护的更小的功能点。
一般来说可以从代码长度上初步评价一个模块划分的是否合理,一个类的长度大于 2000 行,或者一个函数的长度大于两屏幕都是比较危险的信号。
另一个能够体现模块划分水平的地方是依赖。如果一个模块依赖特别多,甚至出现了循环依赖,那么也可以反映出作者对模块的规划比较差,今后在维护这个工程的时候很有可能出现牵一发而动全身的情况。
一般来说有不少工具能提供依赖分析,比如 IDEA 中提供的 Dependencies Analysis 功能,学会这些工具的使用对于评价代码质量会有很大的帮助。
值得一提的是,绝大部分情况下,不恰当的模块划分也会伴随着极低的单元测试覆盖率:复杂模块的单元测试非常难写的,甚至是不可能完成的任务。所以直接查看单元测试覆盖率也是一个比较靠谱的评价方式。
1.4.3. 简洁与抽象
只要提到代码质量,必然会提到简洁、优雅之类的形容词。简洁这个词实际涵盖了很多东西,代码避免重复是简洁、设计足够抽象是简洁,一切对于提高可维护性的尝试实际都是在试图做减法。
编程经验不足的程序员往往不能意识到简洁的重要性,乐于捣鼓一些复杂的玩意并乐此不疲。但复杂是代码可维护性的天敌,也是程序员能力的一道门槛。
跨过门槛的程序员应该有能力控制逐渐增长的复杂度,总结和抽象出事物的本质,并体现到自己设计和编码中。一个程序的生命周期也是在由简入繁到化繁为简中不断迭代的过程。
对于这部分我难以总结出简单易行的评价标准,它更像是一种思维方式,除了要理解、还需要练习。多看、多想、多交流,很多时候可以简化的东西会大大超出原先的预计。
1.4.4. 推荐阅读
《重构 - 改善既有代码的设计》
《设计模式 - 可复用面向对象软件的基础》
《Software Architecture Patterns-Understanding Common Architecture Patterns and When to Use Them》
2、结语
这篇文章主要介绍了一些评价代码质量优劣的手段,这些手段中,有些比较客观,有些主观性更强。之前也说过,对代码质量的评价是一件主观的事情,这篇文章里虽然列举了很多评价手段。但是实际上,很多我认为没有问题的代码也会被其他人吐槽,所以这篇文章只能算是初稿,更多内容还需要今后继续补充和完善。虽然每个人对于代码质量评价的倾向都不一样,但是总体来说评价代码质量的能力可以被比作程序员的 “品味”,评价的准确度会随着自身经验的增加而增长。在这个过程中,需要随时保持思考、学习和批判的精神。
下篇文章里,会谈一谈具体如何提高自己的代码质量。
原文:http://www.open-open.com/lib/view/open1454117276261.html
-------------------------------------------------------------------------------------------------------------------------------------
秦 迪/5.7 系统运维之如何应对烂代码404
5.7.1 改善可维护性.404
5.7.2 改善性能与健壮性409
5.7.3 改善生存环境.412
5.7.4 个人感想414
-------------------------------------------------------------------------------------------------------------------------------------
(1 条消息) 如何应对身边的烂代码_lilinshugg 的博客 - CSDN 博客
如何应对身边的烂代码
1. 改善可维护性
改善代码质量是项大工程,要开始这项工程,从可维护性入手往往是一个好的开始,但也仅仅只是开始而已。
1.1. 重构的悖论
很多人把重构当做一种一次性运动,代码实在是烂的没法改了,或者没什么新的需求了,就召集一帮人专门拿出来一段时间做重构。这在传统企业开发中多少能生效,但是对于互联网开发来说却很难适应,原因有两个:
- 互联网开发讲究快速迭代,如果要做大型重构,往往需要暂停需求开发,这个基本上很难实现。
- 对于没有什么新需求的项目,往往意味着项目本身已经过了发展期,即使做了重构也带来不了什么收益。
这就形成了一个悖论:一方面那些变更频繁的系统更需要重构;另一方面重构又会耽误开发进度,影响变更效率。
面对这种矛盾,一种方式是放弃重构,让代码质量自然下降,直到工程的生命周期结束,选择放弃或者重来。在某些场景下这种方式确实是有效的,但是我并不喜欢:比起让工程师不得不把每天的精力都浪费在毫无意义的事情上,为什么不做些更有意义的事呢?
1.2. 重构 step by step
1.2.1. 开始之前
开始改善代码的第一步是把 IDE 的重构快捷键设到一个顺手的键位上,这一步非常重要:决定重构成败的往往不是你的新设计有多么牛逼,而是重构本身会占用多少时间。
比如对于 IDEA 来说,我会把重构菜单设为快捷键:
这样在我想去重构的时候就可以随手打开菜单,而不是用鼠标慢慢去点,快捷键每次只能为重构节省几秒钟时间,但是却能明显减少工程师重构时的心理负担,后面会提到,小规模的重构应该跟敲代码一样属于日常开发的一部分。
我把重构分为三类:模块内部的重构、模块级别的重构、工程级别的重构。分为这三类并不是因为我是什么分类强迫症,后面会看到对重构的分类对于重构的意义。
1.2.2. 随时进行模块内部的重构
模块内部重构的目的是把模块内部的逻辑梳理清楚,并且把一个巨大无比的函数拆分成可维护的小块代码。大部分 IDE 都提供了对这类重构的支持,类似于:
- 重命名变量
- 重命名函数
- 提取内部函数
- 提取内部常量
- 提取变量
这类重构的特点是修改基本集中在一个地方,对代码逻辑的修改很少并且基本可控,IDE 的重构工具比较健壮,因而基本没有什么风险。
以下例子演示了如何通过 IDE 把一个冗长的函数做重构:
上图的例子中,我们基本依靠 IDE 就把一个冗长的函数分成了两个子函数,接下来就可以针对子函数中的一些烂代码做进一步的小规模重构,而两个函数内部的重构也可以用同样的方法。每一次小规模重构的时间都不应该超过 60s,否则将会严重影响开发的效率,进而导致重构被无尽的开发需求淹没。
在这个阶段需要对现有的模块补充一些单元测试,以保证重构的正确。不过以我的经验来看,一些简单的重构,例如修改局部变量名称,或者提取变量之类的重构,即使没有测试也是基本可靠的,如果要在快速完成模块内部重构和 100% 的单元测试覆盖率中选一个,我可能会选择快速完成重构。
而这类重构的收益主要是提高函数级别的可读性,以及消除超大函数,为未来进一步做模块级别的拆分打好基础。
1.2.3. 一次只做一个较模块级别的的重构
之后的重构开始牵扯到多个模块,例如:
- 删除无用代码
- 移动函数到其它类
- 提取函数到新类
- 修改函数逻辑
IDE 往往对这类重构的支持有限,并且偶尔会出一些莫名其妙的问题,(例如修改类名时一不小心把配置文件里的常量字符串也给修改了)。
这类重构主要在于优化代码的设计,剥离不相关的耦合代码,在这类重构期间你需要创建大量新的类和新的单元测试,而此时的单元测试则是必须的了。
为什么要创建单元测试?
- 一方面,这类重构因为涉及到具体代码逻辑的修改,靠集成测试很难覆盖所有情况,而单元测试可以验证修改的正确性。
- 更重要的意义在于,写不出单元测试的代码往往意味着糟糕的设计:模块依赖太多或者一个函数的职责太重,想象一下,想要执行一个函数却要模拟十几个输入对象,每个对象还要模拟自己依赖的对象…… 如果一个模块无法被单独测试,那么从设计的角度来考虑,无疑是不合格的。
还需要啰嗦一下,这里说的单元测试只对一个模块进行测试,依赖多个模块共同完成的测试并不包含在内——例如在内存里模拟了一个数据库,并在上层代码中测试业务逻辑 - 这类测试并不能改善你的设计。
在这个期间还会写一些过渡用的临时逻辑,比如各种 adapter、proxy 或者 wrapper,这些临时逻辑的生存期可能会有几个月到几年,这些看起来没什么必要的工作是为了控制重构范围,例如:
class Foo {
String foo() {
...
}
}
如果要把函数声明改成
class Foo {
boolean foo() {
...
}
}
那么最好通过加一个过渡模块来实现:
class FooAdaptor {
private Foo foo;
boolean foo() {
return foo.foo().isEmpty();
}
}
这样做的好处是修改函数时不需要改动所有调用方,烂代码的特征之一就是模块间的耦合比较高,往往一个函数有几十处调用,牵一发而动全身。而一旦开始全面改造,往往就会把一次看起来很简单的重构演变成几周的大工程,这种大规模重构往往是不可靠的。
每次模块级别的重构都需要精心设计,提前划分好哪些是需要修改的,哪些是需要用兼容逻辑做过渡的。但实际动手修改的时间都不应该超过一天,如果超过一天就意味着这次重构改动太多,需要控制一下修改节奏了。
1.2.4. 工程级别的重构不能和任何其他任务并行
不安全的重构相对而言影响范围比较大,比如:
- 修改工程结构
- 修改多个模块
我更建议这类操作不要用 IDE,如果使用 IDE,也只使用最简单的 “移动” 操作。这类重构单元测试已经完全没有作用,需要集成测试的覆盖。不过也不必紧张,如果只做 “移动” 的话,大部分情况下基本的冒烟测试就可以保证重构的正确性。
这类重构的目的是根据代码的层次或者类型进行拆分,切断循环依赖和结构上不合理的地方。如果不知道如何拆分,可以依照如下思路:
- 优先按部署场景进行拆分,比如一部分代码是公用的,一部分代码是自己用的,可以考虑拆成两个部分。换句话说,A 服务的修改能不能影响 B 服务。
- 其次按照业务类型拆分,两个无关的功能可以拆分成两个部分。换句话说,A 功能的修改能不能影响 B 功能。
- 除此之外,尽量控制自己的代码洁癖,不要把代码切成一大堆豆腐块,会给日后的维护工作带来很多不必要的成本。
- 案可以提前 review 几次,多参考一线工程师的意见,避免实际动手时才冒出新的问题。
而这类重构绝对不能跟正常的需求开发并行执行:代码冲突几乎无法避免,并且会让所有人崩溃。我的做法一般是在这类重构前先演练一次:把模块按大致的想法拖来拖去,通过编译器找到依赖问题,在日常上线中把容易处理的依赖问题解决掉;然后集中团队里的精英,通知所有人暂停开发,花最多 2、3 天时间把所有问题集中突击掉,新的需求都在新代码的基础上进行开发。
如果历史包袱实在太重,可以把这类重构也拆成几次做:先大体拆分成几块,再分别拆分。无论如何,这类重构务必控制好变更范围,一次严重的合并冲突有可能让团队中的所有人几个周缓不过劲来。
1.3. 重构的周期
典型的重构周期类似下面的过程:
- 在正常需求开发的同时进行模块内部的重构,同时理解工程原有代码。
- 在需求间隙进行模块级别的重构,把大模块拆分为多个小模块,增加脚手架类,补充单元测试,等等。
- (如果有必要,比如工程过于巨大导致经常出现相互影响问题)进行一次工程级别的拆分,期间需要暂停所有开发工作,并且这次重构除了移动模块和移动模块带来的修改之外不做任何其他变更。
- 重复 1、2 步骤
1.3.1. 一些重构的 tips
- 只重构经常修改的部分,如果代码一两年都没有修改过,那么说明改动的收益很小,重构能改善的只是可维护性,重构不维护的代码不会带来收益。
- 抑制住自己想要多改一点的冲动,一次失败的重构对代码质量改进的影响可能是毁灭性的。
- 重构需要不断的练习,相比于写代码来说,重构或许更难一些。
- 重构可能需要很长时间,有可能甚至会达到几年的程度(我之前用断断续续两年多的时间重构了一个项目),主要取决于团队对于风险的容忍程度。
- 删除无用代码是提高代码可维护性最有效的方式,切记,切记。
- 单元测试是重构的基础,如果对单元测试的概念还不是很清晰,可以参考使用 Spock 框架进行单元测试。
2. 改善性能与健壮性
2.1. 改善性能的 80%
性能这个话题越来越多的被人提起,随便收到一份简历不写上点什么熟悉高并发、做过性能优化之类的似乎都不好意思跟人打招呼。
说个真事,几年前在我做某公司的 ERP 项目,里面有个功能是生成一个报表。而使用我们系统的公司里有一个人,他每天要在下班前点一下报表,导出到 excel,再发一封邮件出去。
问题是,那个报表每次都要 2,3 分钟才能生成。
我当时正年轻气盛,看到有个两分钟才能生成的报表一下就来了兴趣,翻出了那段不知道谁写的代码,发现里面用了 3 层循环,每次都会去数据库查一次数据,再把一堆数据拼起来,一股脑塞进一个 tableview 里。
面对这种代码,我还能做什么呢?
- 我立刻把那个三层循环干掉了,通过一个存储过程直接输出数据。
- sql 数据计算的逻辑也被我精简了,一些没必要做的外联操作被我干掉了。
- 我还发现很多 ctrl+v 生成的无用的控件(那时还是用的 delphi),那些控件密密麻麻的贴在显示界面上,只是被前面的大 table 挡住了,我当然也把这些玩意都删掉了;
- 打开界面的时候还做了一些杂七杂八的工作(比如去数据库里更新点击数之类的),我把这些放到了异步任务里。
- 后面我又觉得没必要每次打开界面都要加载所有数据(那个 tableview 有几千行,几百列!),于是我 hack 了默认的 tableview,每次打开的时候先计算当前实际显示了多少内容,把参数发给存储过程,初始化只加载这些数据,剩下的再通过线程异步加载。
做了这些之后,界面只需要不到 1s 就能展示出来了,不过我要说的不是这个。
后来我去客户公司给那个操作员演示新的模块的时候,点一下,刷,数据出来了。那个人很惊恐的看着我,然后问我,是不是数据不准了。
再后来,我又加了一个功能,那个模块每次打开之后都会显示一个进度条,上面的标题是 “正在校验数据……”,进度条走完大概要 1 分钟左右,我跟那人说校验数据计算量很大,会比较慢。当然,实际上那 60 秒里程序毛事都没做,只是在一点点的更新那个进度条(我还做了个彩蛋,在读进度的时候按上上下下左右左右 BABA 的话就可以加速 10 倍读条…)。客户很开心,说感觉数据准确多了,当然,他没发现彩蛋。
我写了这么多,是想让你明白一个事实:大部分程序对性能并不敏感。而少数对性能敏感的程序里,一大半可以靠调节参数解决性能问题;最后那一小撮需要修改代码优化性能的程序里,性价比高的工作又是少数。
什么是性价比?回到刚才的例子里,我做了那么多事,每件事的收益是多少?
- 把三层循环 sql 改成了存储过程,大概让我花了一天时间,让加载时间从 3 分钟变成了 2 秒,模块加载变成了” 唰 “的一下。
- 后面的一坨事情大概花了我一周多时间,尤其是 hack 那个 tableview,让我连周末都搭进去了。而所有的优化加起来,大概优化了 1 秒左右,这个数据是通过日志查到的:即使是我自己,打开模块也没感觉出有什么明显区别。
我现在遇到的很多面试者说程序优化时总是喜欢说一些玄乎的东西:调用栈、尾递归、内联函数、GC 调优…… 但是当我问他们:把一个普通函数改成内联函数是把原来运行速度是多少的程序优化成多少了,却很少有人答出来;或者是扭扭捏捏的说,应该很多,因为这个函数会被调用很多遍。我再问会被调用多少遍,每遍是多长时间,就答不上来了。
所以关于性能优化,我有两个观点:
- 优化主要部分,把一次网络 IO 改为内存计算带来的收益远大于捯饬编译器优化之类的东西。这部分内容可以参考 Numbers you should know;或者自己写一个 for 循环,做一个无限 i++ 的程序,看看一秒钟 i 能累加多少次,感受一下 cpu 和内存的性能。
- 性能优化之后要有量化数据,明确的说出优化后哪个指标提升了多少。如果有人因为” 提升性能 “之类的理由写了一堆让人无法理解的代码,请务必让他给出性能数据:这很有可能是一坨没有什么收益的烂代码。
至于具体的优化措施,无外乎几类:
- 让计算靠近存储
- 优化算法的时间复杂度
- 减少无用的操作
- 并行计算
关于性能优化的话题还可以讲很多内容,不过对于这篇文章来说有点跑题,这里就不再详细展开了。
2.2. 决定健壮性的 20%
前一阵听一个技术分享,说是他们在编程的时候要考虑太阳黑子对 cpu 计算的影响,或者是农民伯伯的猪把基站拱塌了之类的特殊场景。如果要优化程序的健壮性,那么有时候就不得不去考虑这些极端情况对程序的影响。
大部分的人应该不用考虑太阳黑子之类的高深的问题,但是我们需要考虑一些常见的特殊场景,大部分程序员的代码对于一些特殊场景都会有或多或少考虑不周全的地方,例如:
- 用户输入
- 并发
- 网络 IO
常规的方法确实能够发现代码中的一些 bug,但是到了复杂的生产环境中时,总会出现一些完全没有想到的问题。虽然我也想了很久,遗憾的是,对于健壮性来说,我并没有找到什么立竿见影的解决方案,因此,我只能谨慎的提出一点点建议:
- 更多的测试,测试的目的是保证代码质量,但测试并不等于质量,你做覆盖 80% 场景的测试,在 20% 测试不到的地方还是有可能出问题。关于测试又是一个巨大的话题,这里就先不展开了。
- 谨慎发明轮子。例如 UI 库、并发库、IO client 等等,在能满足要求的情况下尽量采用成熟的解决方案,所谓的 “成熟” 也就意味着经历了更多实际使用环境下的测试,大部分情况下这种测试的效果是更好的。
3. 改善生存环境
看了上面的那么多东西之后,你可以想一下这么个场景:
在你做了很多事情之后,代码质量似乎有了质的飞跃。正当你以为终于可以摆脱天天踩屎的日子了的时候,某次不小心瞥见某个类又长到几千行了。
你愤怒的翻看提交日志,想找出罪魁祸首是谁,结果却发现每天都会有人往文件里提交那么十几二十行代码,每次的改动看起来都没什么问题,但是日积月累,一年年过去,当初花了九牛二虎之力重构的工程又成了一坨烂代码……
任何一个对代码有追求的程序员都有可能遇到这种问题,技术在更新,需求在变化,公司人员会流动,而代码质量总会在不经意间偷偷的变差……
想要改善代码质量,最后往往就会变成改善生存环境。
3.1.1. 统一环境
团队需要一套统一的编码规范、统一的语言版本、统一的编辑器配置、统一的文件编码,如果有条件最好能使用统一的操作系统,这能避免很多无意义的工作。
就好像最近渣浪给开发全部换成了统一的 macbook,一夜之间以前的很多问题都变得不是问题了:字符集、换行符、IDE 之类的问题只要一个配置文件就解决了,不再有各种稀奇古怪的代码冲突或者不兼容的问题,也不会有人突然提交上来一些编码格式稀奇古怪的文件了。
3.1.2. 代码仓库
代码仓库基本上已经是每个公司的标配,而现在的代码仓库除了储存代码,还可以承担一些团队沟通、代码 review 甚至工作流程方面的任务,如今这类开源的系统很多,像 gitlab(github)、Phabricator 这类优秀的工具都能让代码管理变得简单很多。我这里无意讨论 svn、git、hg 还是什么其它的代码管理工具更好,就算最近火热的 git 在复杂性和集中化管理上也有一些问题,其实我是比较期待能有替代 git 的工具产生的,扯远了。
代码仓库的意义在于让更多的人能够获得和修改代码,从而提高代码的生命周期,而代码本身的生命周期足够持久,对代码质量做的优化才有意义。
3.1.3. 持续反馈
大多数烂代码就像癌症一样,当烂代码已经产生了可以感觉到的影响时,基本已经是晚期,很难治好了。
因此提前发现代码变烂的趋势很重要,这类工作可以依赖类似于 checkstyle,findbug 之类的静态检查工具,及时发现代码质量下滑的趋势,例如:
- 每天都在产生大量的新代码
- 测试覆盖率下降
- 静态检查的问题增多
有了代码仓库之后,就可以把这种工具与仓库的触发机制结合起来,每次提交的时候做覆盖率、静态代码检查等工作,jenkins+sonarqube 或者类似的工具就可以完成基本的流程:伴随着代码提交进行各种静态检查、运行各种测试、生成报告并供人参考。
在实践中会发现,关于持续反馈的五花八门的工具很多,但是真正有用的往往只有那么一两个,大部分人并不会去在每次提交代码之后再打开一个网页点击 “生成报告”,或者去登陆什么系统看一下测试的覆盖率是不是变低了,因此一个一站式的系统大多数情况下会表现的更好。与其追求更多的功能,不如把有限的几个功能整合起来,例如我们把代码管理、回归测试、代码检查、和 code review 集成起来,就是这个样子:
当然,关于持续集成还可以做的更多,篇幅所限,就不多说了。
3.1.4. 质量文化
不同的团队文化会对技术产生微妙的影响,关于代码质量没有什么共同的文化,每个公司都有自己的一套观点,并且似乎都能说得通。
对于我自己来说,关于代码质量是这样的观点:
- 烂代码无法避免
- 烂代码无法接受
- 烂代码可以改进
- 好的代码能让工作更开心一些
如何让大多数人认同关于代码质量的观点实际上是有一些难度的,大部分技术人员对代码质量的观点是既不赞成、也不反对的中立态度,而代码质量就像是熵值一样,放着不管总是会像更加混乱的方向演进,并且写烂代码的成本实在是太低了,以至于一个实习生花上一个礼拜就可以毁了你花了半年精心设计的工程。
所以在提高代码质量时,务必想办法拉上团队里的其他人一起。虽然 “引导团队提高代码质量” 这件事情一开始会很辛苦,但是一旦有了一些支持者,并且有了可以参考的模板之后,剩下的工作就简单多了。
这里推荐《布道之道:引领团队拥抱技术创新》这本书,里面大部分的观点对于代码质量也是可以借鉴的。仅靠喊口号很难让其他人写出高质量的代码,让团队中的其他人体会到高质量代码的收益,比喊口号更有说服力。
4. 最后再说两句
优化代码质量是一件很有意思,也很有挑战性的事情,而挑战不光来自于代码原本有多烂,要改进的也并不只是代码本身,还有工具、习惯、练习、开发流程、甚至团队文化这些方方面面的事情。
写这一系列文章前前后后花了半年多时间,一直处在写一点删一点的状态:我自身关于代码质量的想法和实践也在经历着不断变化。我更希望能写出一些能够实践落地的东西,而不是喊喊口号,忽悠忽悠 “敏捷开发”、“测试驱动” 之类的几个名词就结束了。
但是在写文章的过程中就会慢慢发现,很多问题的改进方法确实不是一两篇文章可以说明白的,问题之间往往又相互关联,全都展开说甚至超出了一本书的信息量,所以这篇文章也只能删去了很多内容。
我参与过很多代码质量很好的项目,也参与过一些质量很烂的项目,改进了很多项目,也放弃了一些项目,从最初的单打独斗自己改代码,到后来带领团队优化工作流程,经历了很多。无论如何,关于烂代码,我决定引用一下《布道之道》这本书里的一句话:
“‘更好’,其实不是一个目的地,而是一个方向… 在当前的位置和将来的目标之间,可能有很多相当不错的地方。你只需关注离开现在的位置,而不要关心去向何方。”
-------------------------------------------------------------------------------------------------------------------------------------
第6 章 大数据与数据库415
王 劲/6.1 某音乐公司的大数据实践.415
6.1.1 什么是大数据.415
6.1.2 某音乐公司大数据技术架构418
6.1.3 在大数据平台重构过程中踩过的坑425
6.1.4 后续的持续改进.430
王新春/6.2 实时计算在点评.431
6.2.1 实时计算在点评的使用场景431
6.2.2 实时计算在业界的使用场景432
6.2.3 点评如何构建实时计算平台433
6.2.4 Storm 基础知识简单介绍.434
6.2.5 如何保证业务运行的可靠性436
6.2.6 Storm 使用经验分享438
6.2.7 关于计算框架的后续想法442
6.2.8 疑问与解惑442
王卫华/6.3 百姓网Elasticsearch 2.x 升级之路.446
6.3.1 Elasticsearch 2.x 变化446
6.3.2 升级之路448
6.3.3 优化或建议451
6.3.4 百姓之道452
6.3.5 后话:Elasticsearch 5.0453
6.3.6 升级2.x 版本成功,5.x 版本还会远吗454
董西成 张虔熙/6.4 Hadoop、HBase 年度回顾457
6.4.1 Hadoop 2015 技术发展457
6.4.2 HBase 2015 年技术发展460
6.4.3 疑问与解惑466
常 雷/6.5 解密Apache HAWQ——功能强大的SQL-on-Hadoop 引擎.469
6.5.1 HAWQ 基本介绍469
6.5.2 Apache HAWQ 系统架构.472
6.5.3 HAWQ 中短期规划.479
6.5.4 贡献到Apache HAWQ 社区479
6.5.5 疑问与解惑480
萧少聪/6.6 PostgresSQL HA 高可用架构实战.482
6.6.1 PostgreSQL 背景介绍.482
6.6.2 在PostgreSQL 下如何实现数据复制技术的HA 高可用集群483
6.6.3 Corosync+Pacemaker MS 模式介绍484
6.6.4 Corosync+Pacemaker M/S 环境配置485
6.6.5 Corosync+Pacemaker HA 基础配置488
6.6.5 PostgreSQL Sync 模式当前的问题492
6.6.6 疑问与解惑492
王晶昱/6.7 从NoSQL 历史看未来.495
6.7.1 前言495
6.7.2 1970 年:We have no SQL496
6.7.3 1980 年:Know SQL 497
6.7.4 2000 年:No SQL .502
6.7.5 2005 年:不仅仅是SQL 504
6.7.6 2013 年:No,SQL .505
6.7.7 阿里的技术选择.505
6.7.8 疑问与解惑506
杨尚刚/6.8 MySQL 5.7 新特性大全和未来展望.508
6.8.1 提高运维效率的特性508
6.8.2 优化器Server 层改进.511
6.8.3 InnoDB 层优化513
6.8.4 未来发展517
6.8.5 运维经验总结.518
6.8.6 疑问与解惑519
谭 政/6.9 大数据盘点之Spark 篇521
6.9.1 Spark 的特性以及功能521
6.9.2 Spark 在Hulu 的实践.525
6.9.3 Spark 未来的发展趋势528
6.9.4 参考文章530
6.9.5 疑问与解惑530
萧少聪/6.10 从Postgres 95 到PostgreSQL 9.5:新版亮眼特性532
6.10.1 Postgres 95 介绍532
6.10.2 PostgresSQL 版本发展历史533
6.10.3 PostgresSQL 9.5 的亮眼特性534
6.10.4 PostgresSQL 还可以做什么544
6.10.5 疑问与解惑547
毕洪宇/6.11 MongoDB 2015 回顾:全新里程碑式的WiredTiger 存储引擎551
6.11.1 存储引擎的发展551
6.11.2 复制集改进.555
6.11.3 自动分片机制556
6.11.4 其他新特性介绍556
6.11.5 疑问与解惑.558
王晓伟/6.12 基于Xapian 的垂直搜索引擎的构建分析561
6.12.1 垂直搜索的应用场景561
6.12.2 技术选型.563
6.12.3 垂直搜索的引擎架构564
6.12.4 垂直搜索技术和业务细节.566
6.12.5 疑问与解惑568
第7 章 安全与网络572
郭 伟/7.1 揭秘DDoS 防护——腾讯云大禹系统572
7.1.1 有关DDoS 简介的问答.574
7.1.2 有关大禹系统简介的问答575
7.1.3 有关大禹系统硬件防护能力的问答576
7.1.4 有关算法设计的问答577
7.1.5 大禹和其他产品、技术的区别.578
冯 磊 赵星宇/7.2 App 域名劫持之DNS 高可用——开源版
HttpDNS 方案详解580
7.2.1 HttpDNSLib 库组成.581
7.2.2 HttpDNS 交互流程582
7.2.3 代码结构583
7.2.4 开发过程中的一些问题及应对.586
7.2.5 疑问与解惑593
马 涛/7.3 CDN 对流媒体和应用分发的支持及优化595
7.3.1 CDN 系统工作原理.595
7.3.2 网络分发过程中ISP 的影响602
7.3.3 防盗链.603
7.3.4 内容分发系统的问题和应对思路604
7.3.5 P2P 穿墙打洞607
7.3.6 疑问与解惑609
马 涛/7.4 HTTPS 环境使用第三方CDN 的证书难题与最佳实践611
蒋海滔/7.5 互联网主要安全威胁分析及应对方案613
7.5.1 互联网Web 应用面临的主要威胁613
7.5.2 威胁应对方案.616
7.5.3 疑问与解惑624