- 人,体验感觉好:“这个计算机运行得真快”
- 机器,压榨CPU资源





进程调度的时机 + 调度算法

https://www.shiyanlou.com/courses/195


搜索结果
|
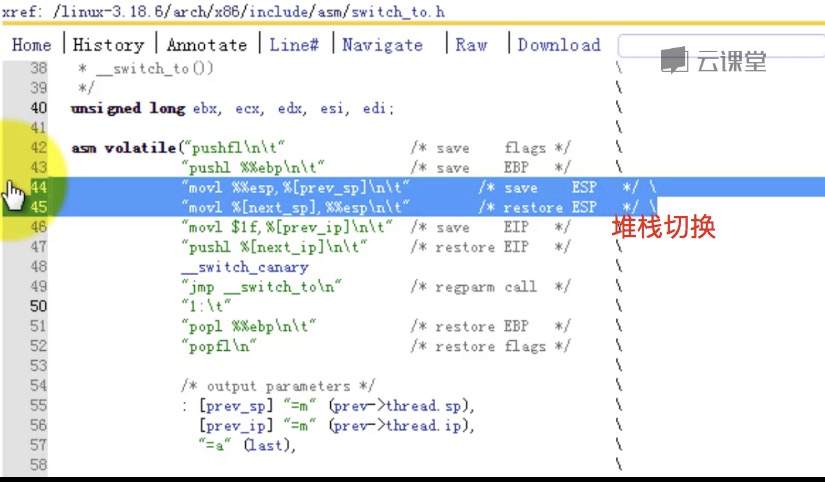
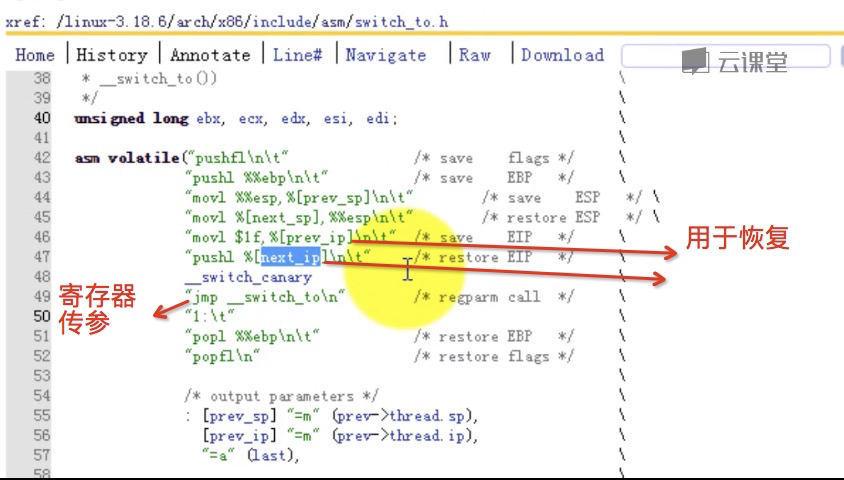
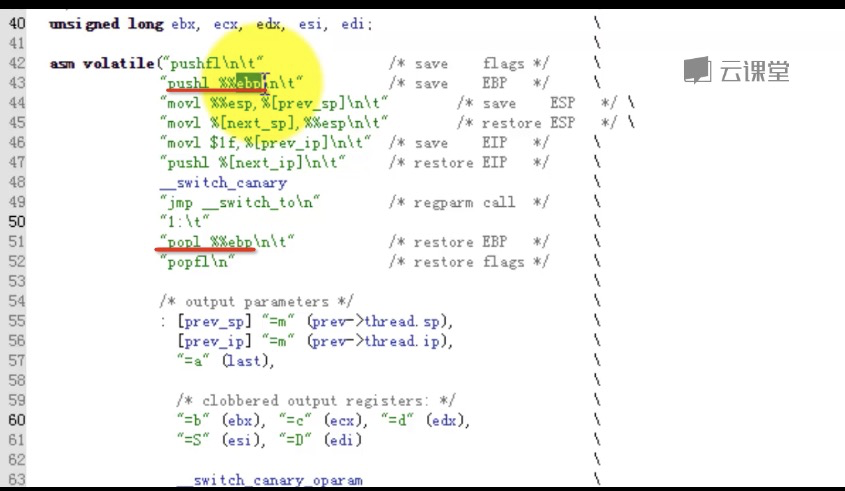
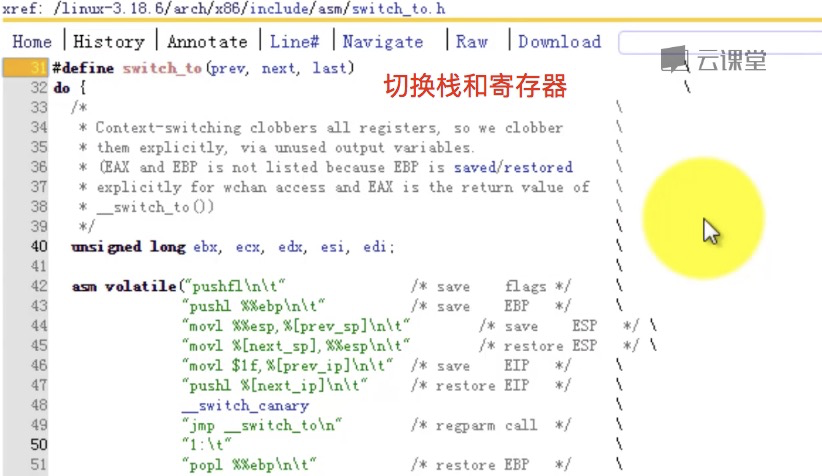
首先简单提一下这个宏和函数的被调用关系: schedule() --> context_switch() --> switch_to --> __switch_to() 这里面,schedule是主调度函数,涉及到一些调度算法,这里不讨论。当schedule()需要暂停A进程的执行而继续B进程的执行时,就发生了进程之间的切换。进程切换主要有两部分:1、切换全局页表项;2、切换内核堆栈和硬件上下文。这个切换工作由context_switch()完成。其中switch_to和__switch_to()主要完成第二部分。更详细的,__switch_to()主要完成硬件上下文切换,switch_to主要完成内核堆栈切换。 阅读switch_to时请注意:这是一个宏,不是函数,它的参数prev, next, last不是值拷贝,而是它的调用者context_switch()的局部变量。局部变量是通过%ebp寄存器来索引的,也就是通过n(%ebp),n是编译时决定的,在不同的进程的同一段代码中,同一局部变量的n是相同的。在switch_to中,发生了堆栈的切换,即ebp发生了改变,所以要格外留意在任一时刻的局部变量属于哪一个进程。关于__switch_to()这个函数的调用,并不是通过普通的call来实现,而是直接jmp,函数参数也并不是通过堆栈来传递,而是通过寄存器来传递。 在下文中提到一些局部变量和寄存器值,为了不引起混淆,在名字后面加上_X,表示是X进程的成员。如esp_A表示进程A的esp的值,prev_B,表示进程B中的prev变量,等等。 switch_to切换主要有以下三部分:
|
||||||||||
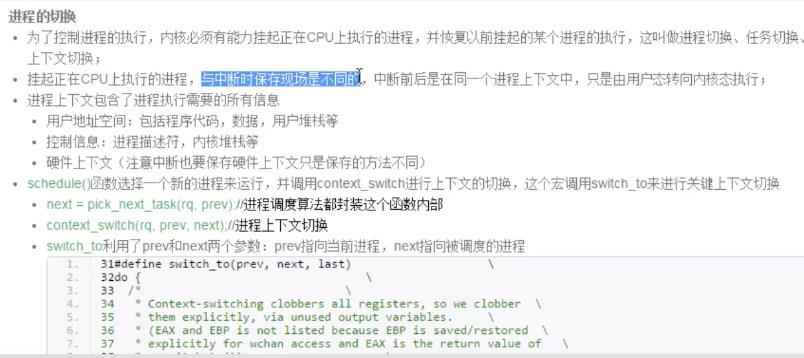
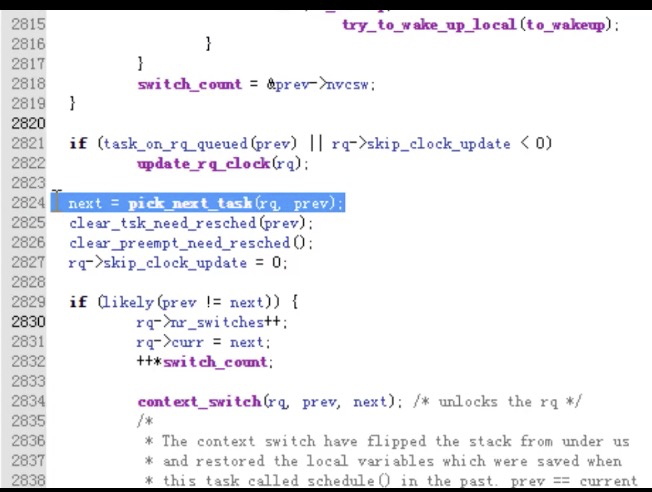
7.switch_to 到底干了啥?第六讲(传送门:fork + execve:一个进程的诞生)我们介绍了进程的诞生,可是操作系统中有很多进程,进程之间怎么切换的,又有哪些奥秘?我们回到源码,细细阅读。 操作系统原理中介绍了大量进程调度算法,这些算法从实现的角度看仅仅是从运行队列中选择一个新进程,选择的过程中运用了不同的策略而已。 对于理解操作系统的工作机制,反而是进程的调度时机与进程的切换机制更为关键。 进程调度的时机: 1. 中断处理过程(包括时钟中断、I/O 中断、系统调用和异常)中,直接调用 schedule(),或者返回用户态时根据 need_resched 标记调用 schedule(); 2. 内核线程可以直接调用 schedule() 进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度; 3. 用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。 进程的切换 为了控制进程的执行,内核必须有能力挂起正在 CPU 上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换; 挂起正在 CPU 上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行; 进程上下文包含了进程执行需要的所有信息 1. 用户地址空间:包括程序代码,数据,用户堆栈等 2. 控制信息:进程描述符,内核堆栈等 3. 硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同) schedule() 函数选择一个新的进程来运行,并调用 context_switch 进行上下文的切换,这个宏调用 switch_to 来进行关键上下文切换。 next= pick_next_task(rq, prev);// 进程调度算法都封装这个函数内部 context_switch(rq,prev, next);// 进程上下文切换 switch_to 利用了 prev 和 next 两个参数:prev 指向当前进程,next 指向被调度的进程 |
|