万字长文带你一览ICLR2020最新Transformers进展(上)
原文链接:http://gsarti.com/post/iclr2020-transformers/
作者:Gabriele Sarti
编译:朴素人工智能
Transformer体系结构最初是在Attention is All You Need中提出的,它是顺序语言建模方法(如LSTM)的有效替代方法,此后在自然语言处理领域变得无处不在,从而推动了大多数下游语言的发展相关任务。
今年的国际学习表示法会议(ICLR)中有许多文章对原始的Transformer及其最新的BERT和Transformer-XL进行了改进。这些改进措施解决了Transformer众所周知的弱点:
- 优化自我注意力计算。
- 在模型架构中注入出于语言动机的归纳偏差。
- 使模型更具参数和数据效率。
这篇文章希望总结并提供这些贡献的高层概述,重点介绍更好和更快的自然语言处理模型的当前趋势。所有图像版权归其各自的论文作者。
1. Self-atention的变体
可缩放的点积自注意力是标准Transformer层中的主要组件之一,无论依赖关系在输入中的距离如何,都可以对其进行建模。自注意力机制大家都已经很熟悉,其公式为:
进一步,多头自注意力机制的公式为:
本节介绍了自我注意组件的一些变体,使其在上下文处理中更加有效。
Long-Short Range Attention
Introduced in: Lite Transformer with Long-Short Range Attention by Wu, Liu et al.
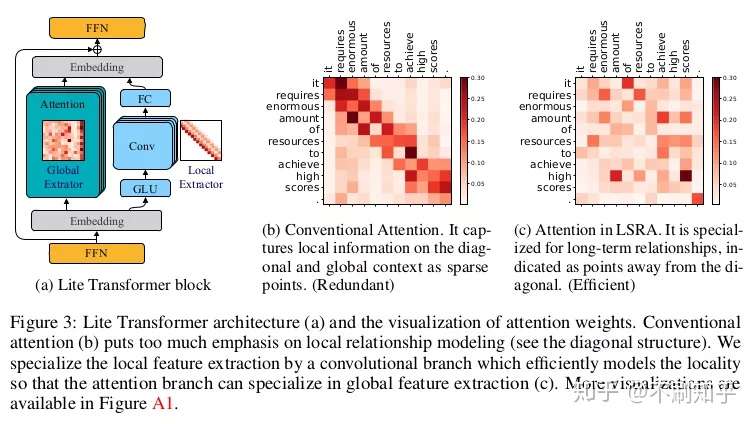
通过将输入沿通道尺寸分成两部分并将每个部分输入两个模块,Long-Short Range Attention (LSRA) 可使计算效率更高。两个模块分别是使用标准自注意的全局提取器和使用轻量级深度卷积的局部提取器。作者指出这种方法可以减少一半模型的整体计算,使其适合于移动端。
Tree-Structured Attention with Subtree Masking
Introduced in: Tree-Structured Attention with Hierarchical Accumulation by Nguyen et al.
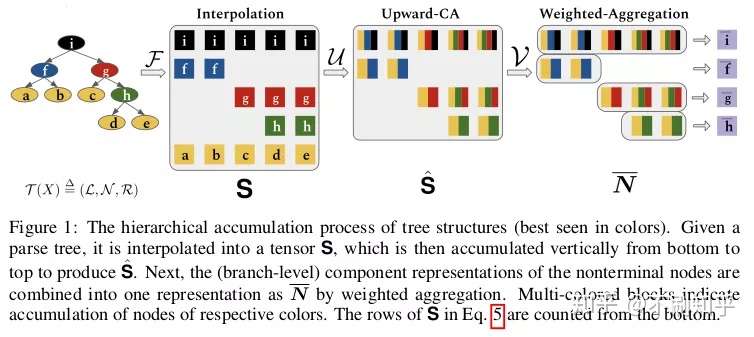
标准Transformer的一个缺点是缺少归纳偏差来解释语言的层次结构。这部分是由于通常通过递归或递归机制建模的树状结构,难以保持恒定的自我注意时间复杂性。
本文所提出的解决方案是利用输入文本的句法分析来构建隐藏状态树,并使用分层累加将非叶子节点的值用子节点聚合来表示。最终的输出表示通过分支级表示的加权聚合来构建。
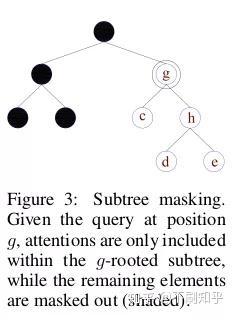
本文另一个有趣的想法是通过限制每个节点查询仅关注其子树,使用子树遮罩来过滤掉多余的噪声。这种归纳偏差的引入方式会增加计算和存储成本,文章使用参数共享来减轻这种成本。
Hashed Attention
Introduced in: Reformer: The Efficient Transformer by Kitaev et al.
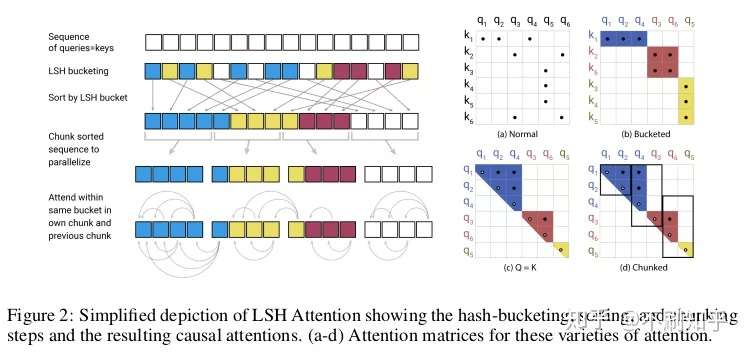
由于self-attention的时间复杂度与序列长度的平方成正比,给建模长序列带来了困难。Reformer提出将每个查询所涉及的候选者池限制为通过本地敏感哈希(LSH)找到的一小部分邻居。由于LSH分桶采用随机投影的方法,因此类似的向量有时可能会落在不同的邻域中。文中使用多轮并行哈希处理来缓解此问题。使用LSH注意可以将自我注意操作的计算成本降低到,允许模型在更长的序列上运行。
关于LSH可以参考我们之前的文章REALM后续:最近邻搜索,MIPS,LSH和ALSH。
eXtra Hop Attention
Introduced in: Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention by Zhao et al.
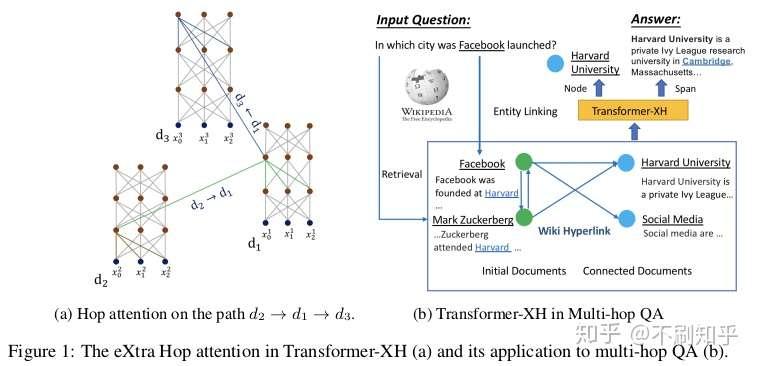
尽管对Transformer可以在单个序列或序列对上进行操作获得很好结果,但它们却很难推广到证据分散在多段文本中的情况,例如颇具挑战性的多跳问答任务。
Transformer-XH引入了一种新的注意力变体eXtra Hop Attention,可以将其应用于由边(例如,超链接)连接的文本序列图。这种新的注意力机制将每个序列开头的特殊标记[CLS]用作关注中心(attention hub),该中心attend到图中的其他相连接的序列。然后将所得表示通过线性投影的标准自注意力机制进行组合。模型展示出对需要对图进行推理任务的显着改进,但新的注意力机制引入了额外的计算代价。
2. 训练目标
Transformer模型的预训练通常是通过多个不受监督的目标来实现的,并利用了大量的非注释文本。用于此目的的最常见任务是自回归语言建模(也称为标准语言建模,LM)和对掩码输入的自动编码(通常称为掩码语言建模,MLM)。
标准的Transformer实现及其GPT变体采用自回归方法,利用序列内部的单向上下文(正向或反向)估计下一个token的概率分布:
类似BERT的方法使用双向上下文来恢复输入被特殊[MASK] token替代的一小部分。事实证明,此变体对下游自然语言理解任务特别有效。
除了单词级建模之外,由于许多重要的语言应用程序都需要理解两个序列之间的关系,因此通常在训练过程中添加诸如下一个句子预测(NSP)之类的句子级分类任务。关于BERT,可以参考我们之前的文章[预训练语言模型专题] BERT,开启NLP新时代的王者。
尽管这些任务可以获得有意义的token和句子层表示,但本节将介绍一些更好的替代方法,这些方法可以使学习更加有效。
Discriminative Replacement Task
Introduced in: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators by Clark et al.
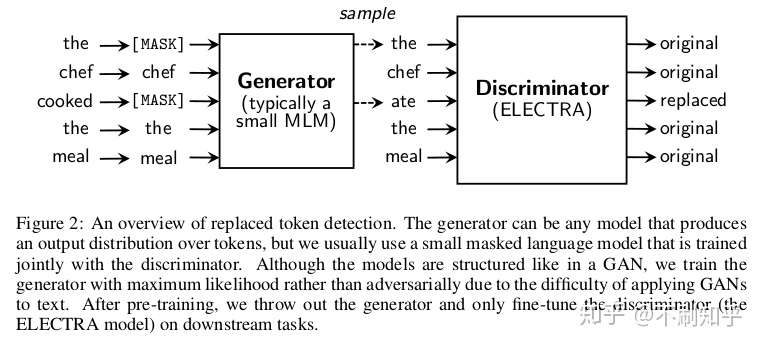
在类似BERT的模型中使用的掩蔽策略在数据上效率很低,仅使用约15%的输入文本来完成MLM任务。但是,由于过多的masked token可能会使整体上下文信息损失严重,因此很难增加屏蔽数据的百分比。
ELECTRA提出了一种简单而有效的方法来应对这种效率低下的问题。像普通的MLM一样,训练一个小的屏蔽语言模型,然后将其用作生成器,用其填充输入中被屏蔽的token。但是,主模型的新任务将是一个分类任务:除了预测掩盖的token之外,该模型还必须检测生成器替换了哪些token。这允许利用整个输入序列进行训练。正如作者所提到的,在相同的计算预算下,这种方法始终优于MLM预训练。
关于Electra,可以参考我们之前的文章性能媲美BERT却只有其1/10参数量? | 近期最火模型ELECTRA解析。
Word and Sentence Structural Tasks
Introduced in: StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding by Wang et al.
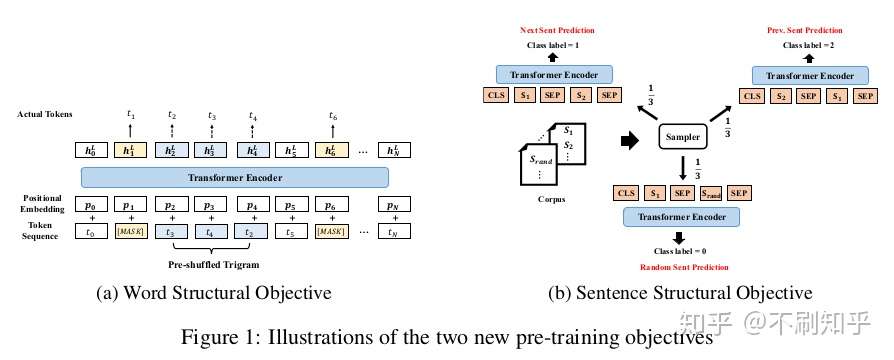
如前所述,Transformers并未明确考虑输入中存在的语言结构。虽然树状结构的注意力在模型体系结构中注入了很多的结构信息,但StructBERT采用了两种更轻便但有效的方法,使生成的表示形式更了解语言的基本顺序。
第一个是单词结构目标(word structural objective),即输入的三字组(trigram)被随机打乱,模型必须重新构造其原始顺序。这是与常规MLM并行完成的。句子结构目标(sentence structural objective) 是ERNIE 2.0中句子重排任务和ALBERT中SOP任务的轻量级变体:给定一对句子对(S1, S2)作为输入,我们要求模型区分S1是在S2之前、之后或与之无关。这项新任务扩展了标准的NSP任务,NSP对于学习有意义的句子关系来说太容易了。这些改进带来了自然语言理解能力的提升。
Type-Constrained Entity Replacement
Introduced in: Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model by Xiong et al.
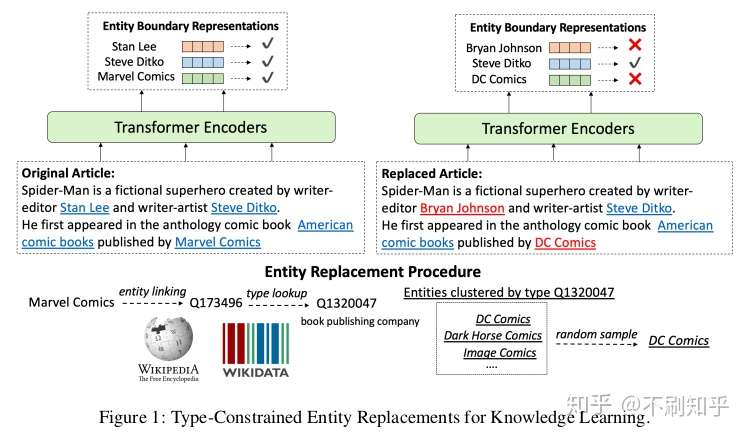
尽管很多研究已经显示,经过预训练的Transformer模型隐式地捕获了现实世界的知识,但是它们的标准训练目标并未明确考虑到在现实世界中进行可靠推理所需的以实体为中心的信息。
带类型约束的实体替换(Type-constrained entity replacement) 是一种弱监督的方法,文本中的实体随机地被具有相同实体类型的其他来自Wikidata的实体替换。然后,该模型使用类似于ELECTRA的判别目标来确定实体是否被替换。这是在多任务设置中与MLM一起完成的,并且作者报告说,由于更深入地了解实体,该模型在例如开放域QA和实体类型预测等问题中有显著的提升。
下集已经更新,链接在此
不刷知乎:万字长文带你一览ICLR2020最新Transformers进展(下)zhuanlan.zhihu.com
更多精彩内容欢迎关注公众号【朴素人工智能】
参考资料
[1] Attention is All You Need: https://arxiv.org/abs/1706.03762
[2] LSTM: https://www.researchgate.net/publication/13853244_Long_Short-term_Memory
[3] ICLR官网: https://iclr.cc/
[4] BERT: https://www.aclweb.org/anthology/N19-1423/
[5] Transformer-XL: https://www.aclweb.org/anthology/P19-1285/
[6] Lite Transformer with Long-Short Range Attention: http ://http://iclr.cc/virtual_2020/poster_ByeMPlHKPH.html
[7] Tree-Structured Attention with Hierarchical Accumulation: https://iclr.cc/virtual_2020/poster_HJxK5pEYvr.html
[8] Reformer: The Efficient Transformer: https://iclr.cc/virtual_2020/poster_rkgNKkHtvB.html
[9] Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention: https://iclr.cc/virtual_2020/poster_r1eIiCNYwS.html
[10] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators: https://iclr.cc/virtual_2020/poster_r1xMH1BtvB.html
[11] StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding: https://iclr.cc/virtual_2020/poster_BJgQ4lSFPH.html
[12] Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model: https://iclr.cc/virtual_2020/poster_BJlzm64tDH.html
万字长文带你一览ICLR2020最新Transformers进展(下)
原文链接:http://gsarti.com/post/iclr2020-transformers/
作者:Gabriele Sarti
编译:朴素人工智能
上集请戳:
万字长文带你一览ICLR2020最新Transformers进展(上)mp.weixin.qq.com
话不多说,直入主题
3. Embeddings
原始的Transformer依靠两组嵌入来表示输入序列:
- 词汇表中存在的每个标记的学习单词嵌入(word embedding),用作模型的标记向量表示。
- 位置嵌入(position embedding),用于注入有关token在序列中的位置的信息。对于位置和维度,位置嵌入与正弦周期函数相对应,根据经验显示这些正弦周期函数与通过学习获得的嵌入效果相当:
对于能够在多个输入段上运行的类似BERT的模型,还使用第三组可学习的分段嵌入(segment embedding)来区分属于不同句子的token。
所有这些嵌入都具有相同的尺寸,并被加在一起以获得输入最终的表示。本节介绍的方法旨在给嵌入注入更多结构,或优化其尺寸以提高效率。
Position-Aware Complex Word Embeddings
Introduced in: Encoding word order in complex[1] embeddings by Wang et al.
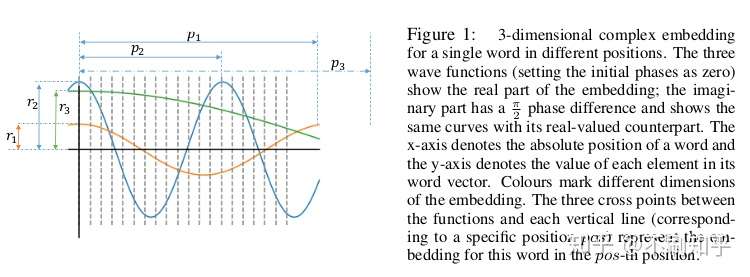
尽管PE在输入中捕获了不同的位置,但它们没有明确考虑这些位置之间的关系,即顺序关系(标准PE只关注距离,不关注先后,可以自己推导看看)。Transformer-XL已通过利用单词之间的相对距离而不是原始位置索引来解决此问题。
本文提出的改进是将单词嵌入泛化为与位置相关的连续函数,并扩展到复数值域,以便从更丰富的表示形式中获益。生成的复值嵌入(complex-valued embeddings)引入了新的关于幅度、频率和初始相位的参数,这些参数确定了嵌入的各种属性(例如位置敏感性)。实验结果表明,具有参数共享方案的复值嵌入优于以前的嵌入方法,而可训练参数的数量却没有显着增加。
Hierarchical Embeddings
Introduced in: Tree-Structured Attention with Hierarchical Accumulation[2] by Nguyen et al.
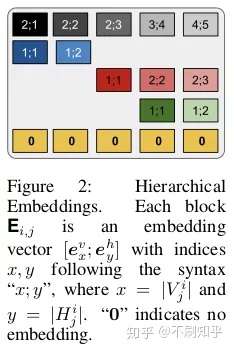
在之前对树状结构注意的概述中,我们看到了如何使用层次累加来形成基于非叶子节点后代的表示。但是,此过程的缺点是没有考虑后代的层次结构。
通过将垂直和水平嵌入矩阵连接起来,分别表示分支内部的层次结构顺序和子树中同级节点之间的关系,使得分层嵌入(Hierarchical embeddings) 可以注入更多的结构信息。这些嵌入在注意力头之间共享,因此仅占总参数的0.1%。
Factorized Embedding Parametrization
Introduced in: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[3] by Lan et al.
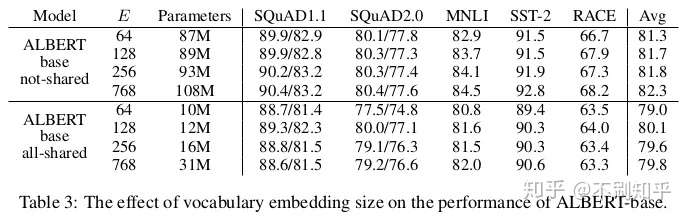
在基于BERT和Transformer-XL的最新模型中,embedding大小与隐藏层的大小有关,即。这在实际操作时有很大的弊端:要增强模型的上下文表示能力通常要增大隐层,这会导致嵌入矩阵的变大,因为,其中是词汇量。即使对于相对较小的隐藏层尺寸,这中关系也会导致数十亿个参数,而且这些参数在训练期间很少更新。
ALBERT作者建议在和(我感觉,这个应该是)之间插入一个投影使两个维度独立,这种方法在时对减少参数量特别有效。一个, 包含21M参数(表3中为89M,而BERT为110M)的ALBERT,可以在许多下游任务上获得与具有相同配置的BERT基础相当的性能。
4. 模型架构
原始的Transformer体系结构由编码器和解码器组成,每个编码器和解码器由相同层的堆叠序列组成,这些堆叠序列对具有相同尺寸的嵌入进行转换(因此称为Transformer)。Transformer编码器的每一层都由两个子层:一个多头自我注意机制和一个前馈网络组成,前者被残差连接所包围,然后进行层归一化。解码器还包括第三层,对编码器的输出执行多头自我注意,并解码器的自注意力子层也和编码器不同。因为由于自回归语言模型的要求,这里需要避免后文参与运算(否则就泄露了)。
Transformer的双向变体(如BERT)放弃了解码器结构,仅专注于编码器,以生成各种任务(包括MLM)所需的上下文嵌入。
特别的,Transformer-XL为Transformer网络引入了一种内存概念,其中在前段中获得的隐藏状态会被重用以更好地对长程依赖性进行建模,从而防止上下文碎片化。
关于Transformer-XL可以参考我们之前的文章。
[预训练语言模型专题] Transformer-XL 超长上下文注意力模型mp.weixin.qq.com
以下方法尝试在当前结构的基础上进一步改善长程建模、减少参数数量或优化模型执行的计算。
Compressive Memory
Introduced in: Compressive Transformers for Long-Range Sequence Modelling[4] by Rae et al.
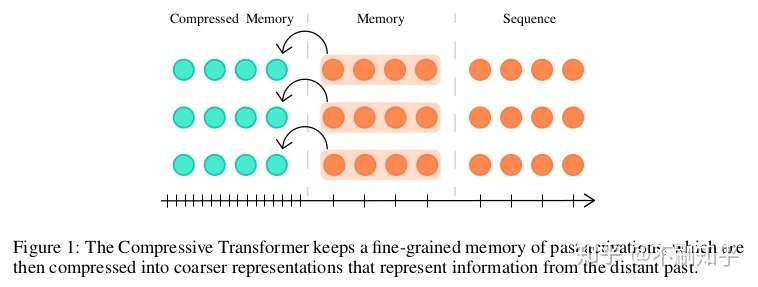
在Transformer-XL的循环存储方法中,旧记忆会被丢弃,从而能够以先进先出的方式存储新的记忆。此方法仅考虑先后远近,而不考虑可能会丢弃的信息的相关性。
Compressive Transformers添加了新的压缩记忆机制,保存历史记忆的粗糙表示,而非直接丢弃旧记忆。作者尝试使用多种压缩函数,最后选择一种注意力重建损失函数(attention-reconstruction loss),该损失会丢弃网络未被注意(not attended)到的信息。压缩内存的使用显示了对少见单词建模的巨大改进,实验证明网络通过压缩机制学习到了如何保留有用的信息。
Reversible Layers
Introduced in: Reformer: The Efficient Transforme[5] by Kitaev et al.
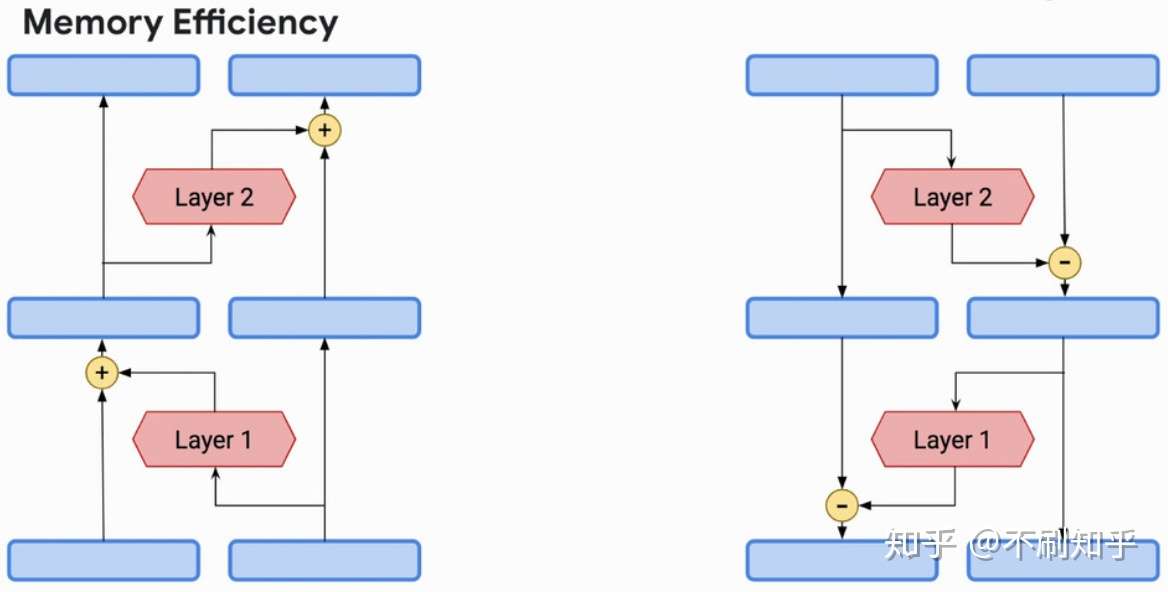
可逆性(reversibility)背后的主要思想是可以通过仅使用后续层的激活情况和模型参数来恢复网络任意层中的激活情况。当与Transformer模型结合时,它变得特别有趣,因为Transformers通常由一大堆堆叠的层组成,并且模型的内存复杂度随层数线性增长。
通过将自注意力和前馈子层组合成为单个可逆层,Reformer在Transformer体系结构中引入了可逆性。这允许仅在存储最上层的激活情况,并通过在反向传播期间反转各层来恢复所有其他激活,从而使模型大小与层数无关。通过在前馈和可逆层中进行分块独立计算,还可以进一步改进空间复杂性。
Cross-Layer Parameter Sharing
Introduced in: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[3] by Lan et al.
跨层参数共享是一种简单但非常有效的方法,可以大大减少深度Transformer模型内部的参数数量,正如ICLR 2019 在Universal Transformer[6]论文中所展示的那样。
ALBERT作者对自注意子层和前馈子层的跨层参数共享进行了实验,发现共享权重矩阵可以将模型的总参数数量大大减少,当结合前面的嵌入分解使时,模型大小可以变为原来的七分之一,而对最终结果的影响很小。参数共享还可以使层间的过渡更加平滑,有效地稳定网络参数。
Adaptive Depth Estimation
Introduced in: Depth-Adaptive Transformer[7] by Elbayad et al.
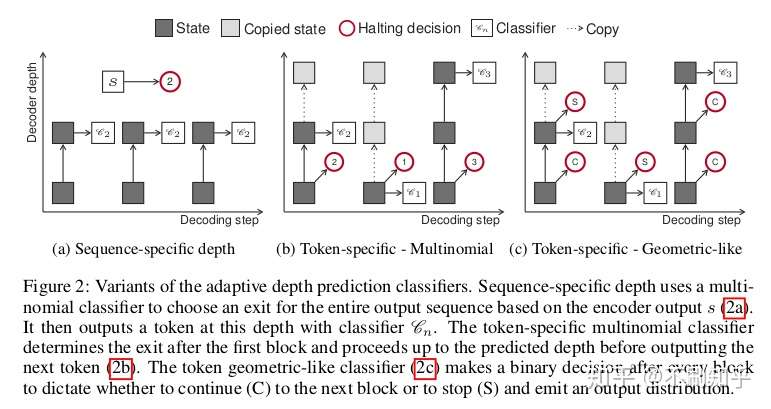
不管输入语句的复杂度如何,当前模型为每个输入执行的计算都是固定的。这个问题已经在Universal Transformer中被提出,Universal Transformer建议使用自适应计算时间(ACT)重复使用相同的层,但是由此导致的每层权重的增加大大降低了网络的计算速度。
Depth-adaptive Transformer通过使用标准Transformer编码器对序列进行编码并以可变步长对其进行解码来解决此问题。为此,将一个分类器连接到解码器的每层后面,然后使用首先在计算机视觉领域引入的anytime prediction方法,通过如图所示的对齐和混合训练(aligned and mixed training)对整个集合进行训练。作者探索了不同的机制来自适应地控制序列级别和token 级别的计算量,并得出结论:自适应可以缩减超过75%的解码器层,而不会对机器翻译任务造成任何性能损失。
(这篇没怎么看懂,大家可以参考知乎上的一些介绍)
结论
在ICLR 2020上引入的许多方法为解决原始Transformer从自注意力计算到模型结构本身的问题提供了大量的解决方案。
其中的许多方法似乎对Transformer的未来发展很有帮助,而且重要的是,一旦其中一些方法被组合起来,就有可能相互补充产生更进一步的改进。
我希望在ICLR 2021能看到更多的工作,将现存的策略组合在一起,呈现它们之间最有效的组合。
更多精彩内容欢迎关注公众号 【朴素人工智能】参考
- ^Encoding word order in complex https://iclr.cc/virtual_2020/poster_Hke-WTVtwr.html
- ^Tree-Structured Attention with Hierarchical Accumulation https://iclr.cc/virtual_2020/poster_HJxK5pEYvr.html
- ^abALBERT: A Lite BERT for Self-supervised Learning of Language Representations https://iclr.cc/virtual_2020/poster_H1eA7AEtvS.html
- ^Compressive Transformers for Long-Range Sequence Modelling https://iclr.cc/virtual_2020/poster_SylKikSYDH.html
- ^The Efficient Transforme https://iclr.cc/virtual_2020/poster_rkgNKkHtvB.html
- ^Universal Transformer https://arxiv.org/abs/1807.03819
- ^Depth-Adaptive Transformer https://iclr.cc/virtual_2020/poster_SJg7KhVKPH.html