
learning to see.pdf

@lutingting 2016-11-04 16:15 字数 10899 阅读 4087SIFT特征提取及匹配
1.SIFT(Scale-invariant feature transform)算子的核心思想
由于SIFT特征的检测方式,使得它具有:
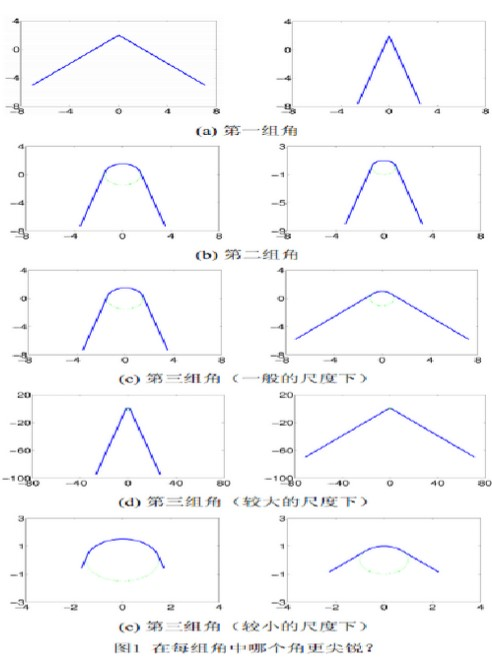
2.什么是尺度空间呢?2.1 一篇百度文库的文章关于尺度空间的分析具体内容参考文献4 通常会听到尺度变化等这类词语,看到的也总是一堆的数学公式,有时候真的不知道这到底有啥用,有啥意义,没有弄懂这些意义,当然就更不可能理解,不可能去掌握、应用它了,现在我才理解,小波变化其实也是一种尺度变化。今天我看到一篇南航数学系写的关于尺度空间解释的文章,感觉很通俗易懂,我们不从数学上来推导什么是尺度空间,只是从生活常识方面来解释尺度空间的意义,意义懂了,数学方面自然就好理解了。 例子1首先我们提出一个问题,请看下面的图片,让我们人为的进行判断:下面所显示的左右图片中哪个的角尖锐?
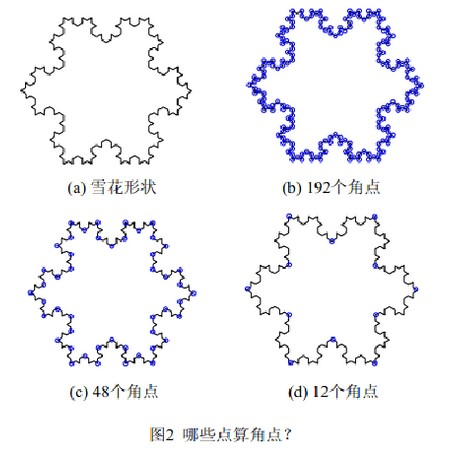
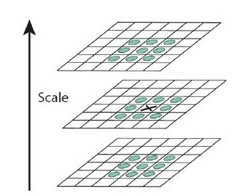
此例子的结果阐述了“尺度”对于解决视觉问题的重要性,即一个视觉问题的答案往往会依赖于其所在的尺度。在生活中这样的例子也比比皆是,比如要观察一棵树,所选择的尺度应该是“米”级;如果观察树上的树叶,所选择的尺度则应该是“厘米”级。一般来说,摄像设备所能呈现的画面分辨率是固定的。要以同样的分辨率分别观察树和树叶,我们需要调整摄像设备的摄像位置。因此,视觉问题中的“尺度”概念也可以被形象地理解为摄像设备与被观察物体之间的距离:较远的距离对应较大的尺度,较近的距离对应较小的尺度。 例子2接下来我们看看第二个例子吧,看看图二中显示的图片那些是角点?
同例1 一样,本例中问题的答案依赖于问题所在的尺度:当我们非常靠近雪花形状观察它时(即在较小的尺度下),能够看清楚所有的细节,却不容易感知其整体轮廓,从而倾向于不加区分地选取图2(b)中所标记的192 个点作为角点。反过来,当我们从一个很远的距离观察雪花形状时(即在较大的尺度下),虽然轮廓的细节已经模糊不清,但却能够一眼看出其整体结构,从而倾向于选取图2(d) 中所标记的12 个点作为角点。此外,图2(c) 中所标记的角点对于理解雪花形状也很有帮助。事实上,如果我们不是保守地将自己固定在某个尺度下来观察物体,便能够获得充足的视觉信息。比如说图2(b)-2(d) 所呈现的三组角点已经很好地向我们展示了雪花形状的三个结构层次。这一效果是其中的任意一组角点都无法实现的。 现实生活中的例子现实生活中视觉问题的复杂性也往往需要我们做到这一点:当我们去参观某处文化遗迹时,远远地就已经开始观察建筑物的外形,然后较近距离时开始注意到门窗、台阶、梁柱的建筑风格,最后会凑上前去细看门窗上的图案、石碑上的碑文等。当一部机器人也能够自主地做到这一点时,说明它已经具备了更高的人工智能。我们对尺度空间技术的研究也正是朝着这个方向努力。概括地说,“尺度空间”的概念就是在多个尺度下观察目标,然后加以综合的分析和理解。 这里用的是图像来解释尺度,当然,对于抽象的信号,理解还是一样的,不过到时候我们看的工具不是我们人眼或者是摄像机从外表区分了,这时候我们用的工具也可能是时域的分析法,也可能是频率域的傅里叶变化等分析法,它是我们进一步发现我们感兴趣事物的工具。 2.2 SIFT中的尺度空间的概念
3.SIFT特征提取一幅图像的SIFT特征提取,分为4个步骤:
下面分别是这四部分的详细内容 3.1 尺度空间极值检测SIFT特征点其实就是尺度空间中稳定的点/极值点,那么,为了得到这些稳定点:
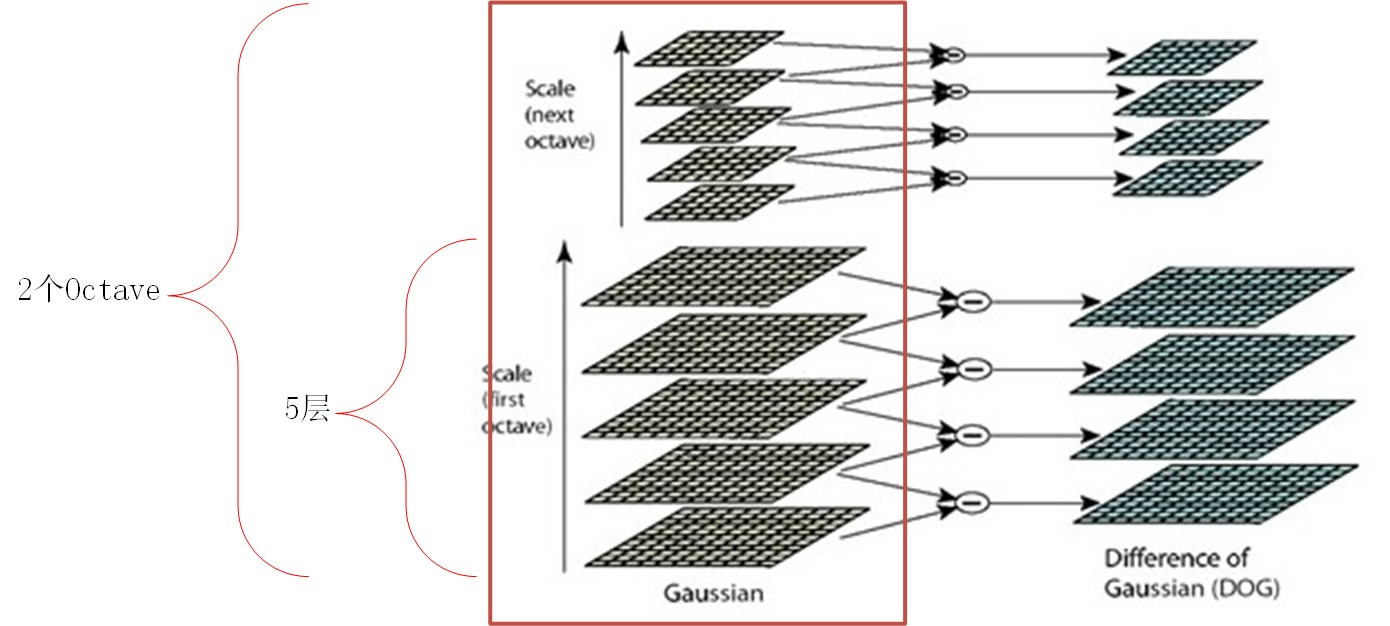
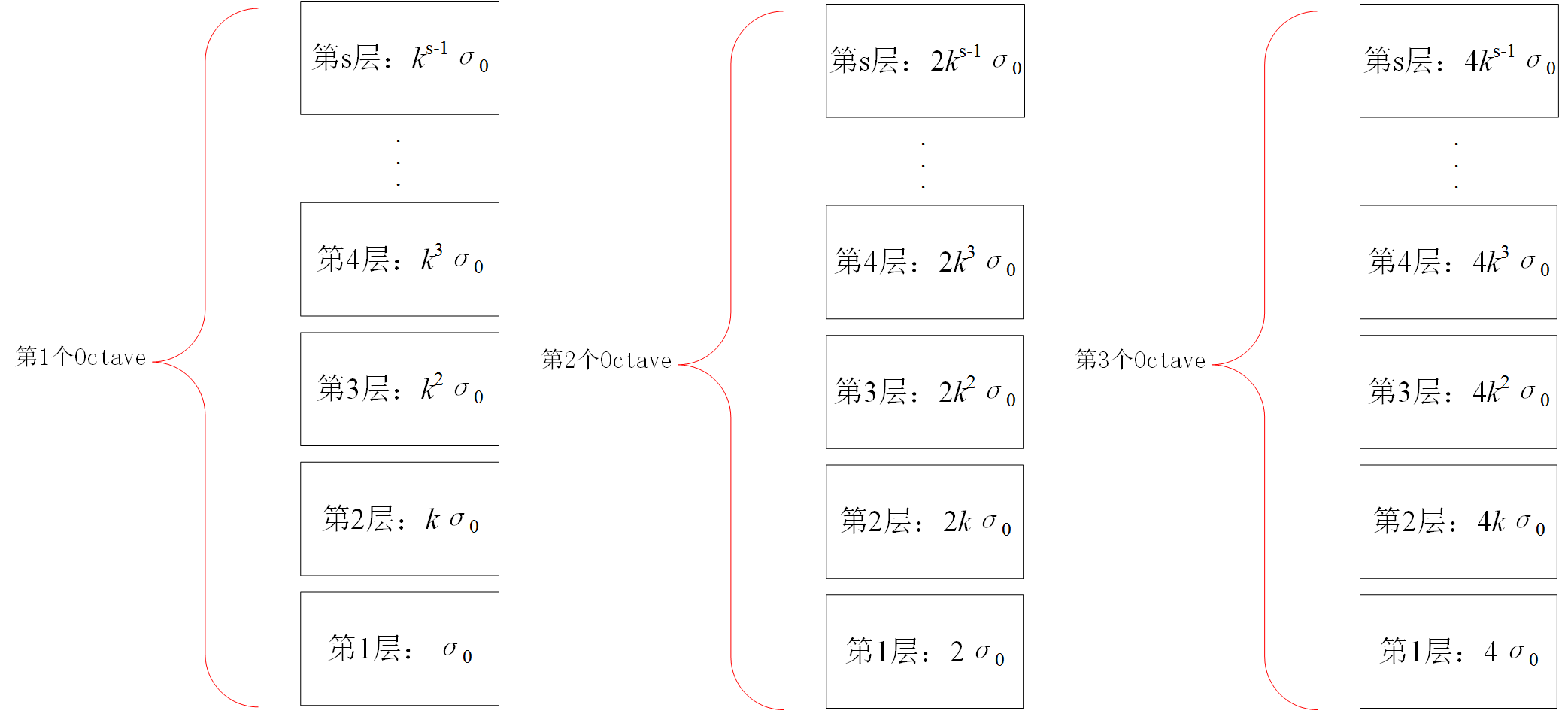
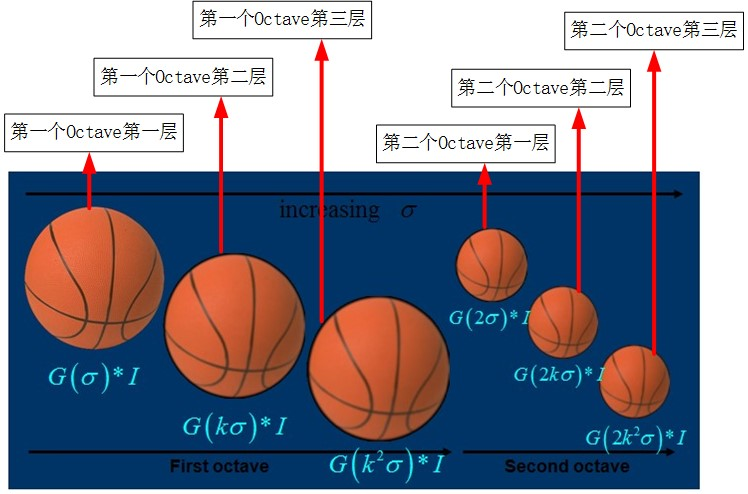
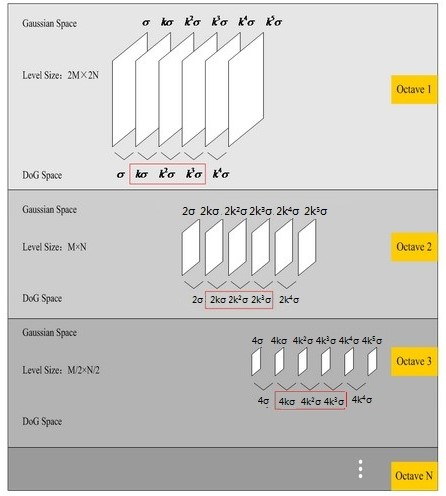
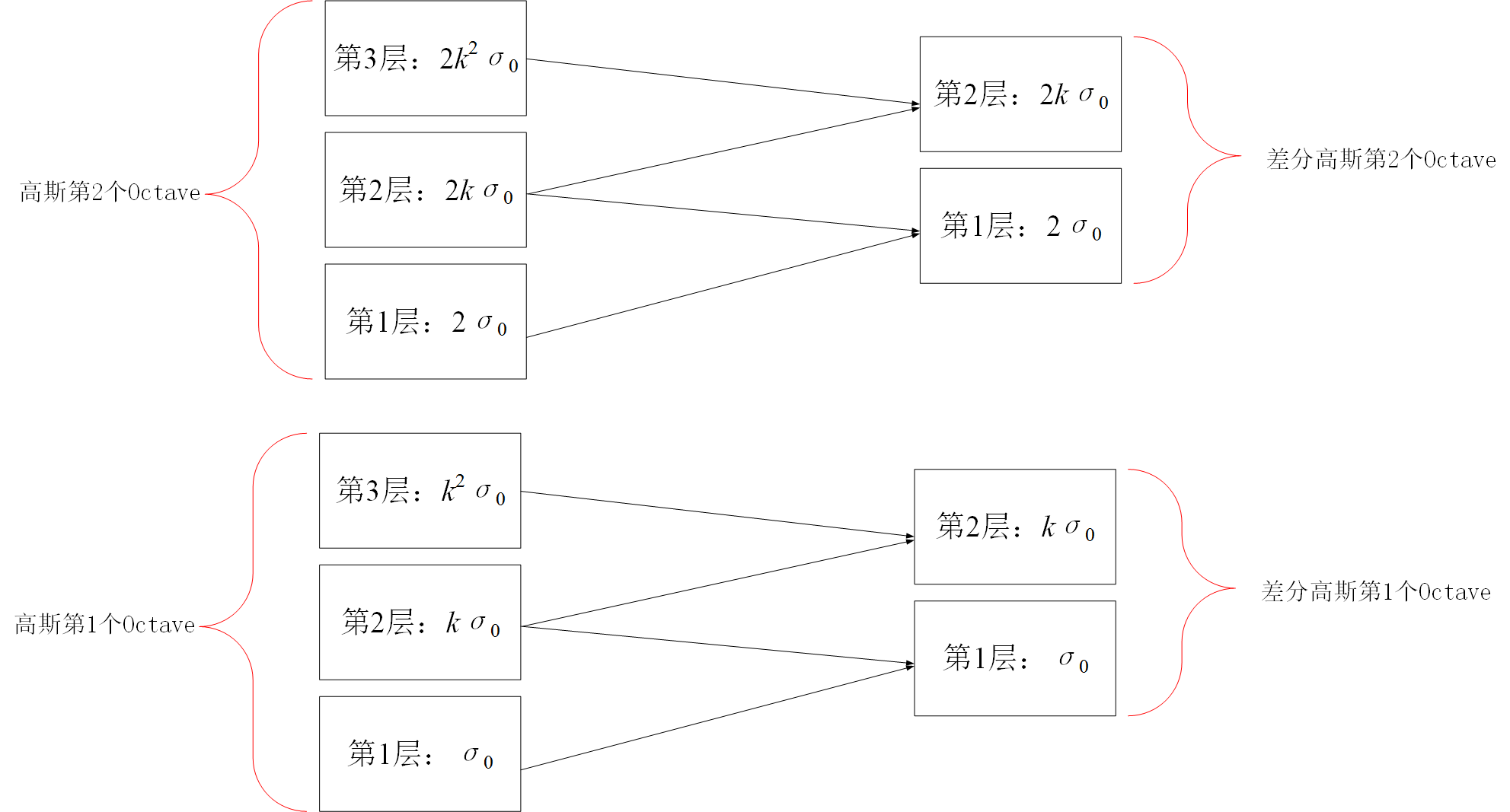
3.1.1 尺度空间的建立(高斯金字塔的建立)对于一幅输入图像,为了进行sift特征检测、实现scale-invariant(任何尺度下都能够有对应的特征点),需要对该图像的尺度空间进行分析,即建立高斯金字塔图像、得到不同scale的图像,这里的高斯金字塔与最原始的高斯金字塔稍微有点区别,因为它在构造尺度空间时,将这些不同尺度图像分为了多个Octave、每个Octave又分为了多层。下图左侧框内给出了Sift中的高斯金字塔的结构图;
为什么已经使用了不同尺度的高斯函数进行滤波还需要引入高斯金字塔呢? 不同octave之间的尺度差异靠高斯金字塔在分辨率上的区别实现,同一个octave内部不同层之间的尺度差异靠高斯函数的方差变化来实现。另外SIFT在DOG问题上并不是使用DOG函数直接滤波,而是用相邻两层的高斯滤波结果相减得到的,为什么要这样呢? 不同对应的高斯核函数到底有什么作用呢?下面做个小实验,可以发现,不同高斯核尺度会对图像产生不同的平滑效果,尺度因子越大(高斯函数方差越大),对图像的平滑程度越大;
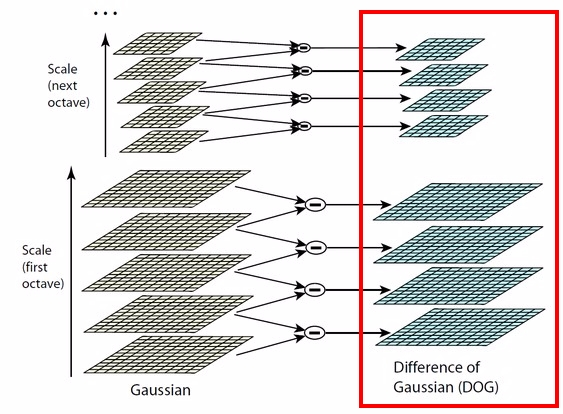
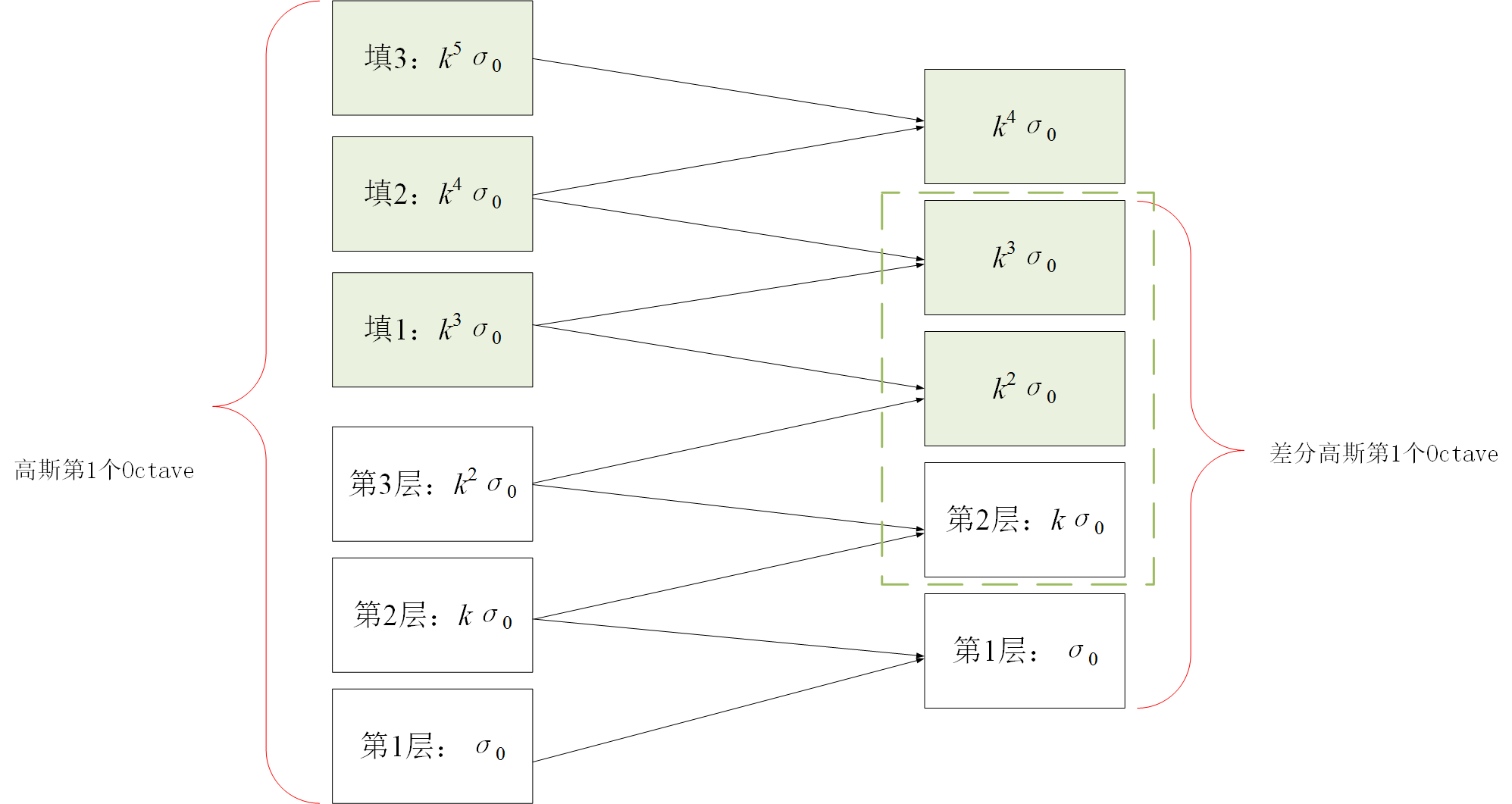
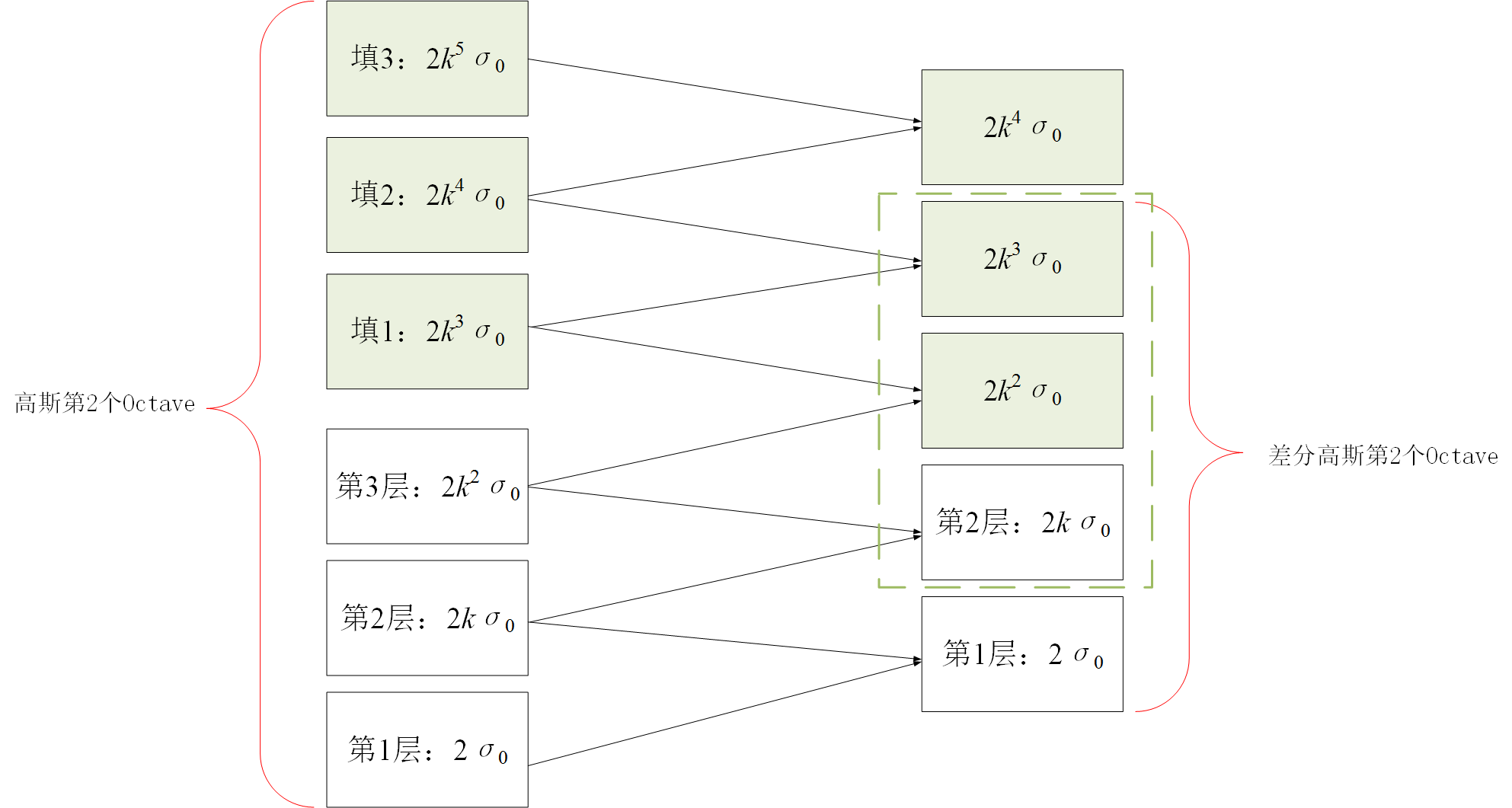
得到了图像的尺度空间后,需要在尺度中间内检测稳定特征点,从而需要比较不同尺度图像之间的差别,实现极值点的检测,实际上,Laplacian of Gaussian和Difference of Gaussian都能够实现这样的目的,但LoG需要大量的计算,而DoG的计算相对简单,并且DoG是对LoG的一个很好的今昔 3.1.2 图像差分高斯金字塔(DoG)的建立对于高斯金字塔中的每一个塔的不同层,可以计算得到相邻层之间的差值,从而可以得到差分高斯,对高斯金字塔中每一个塔都进行同样的操作,从而得到差分高斯金字塔,如下图右侧所示,即显示了由左侧的高斯金字塔构造得到的差分高斯金字塔,该差分高斯金字塔包含2个塔,每个塔都有四层 差分高斯表征了相邻尺度的高斯图像之前的差别,大值表示区别大,小值表示区别小,后续的特征点检测都是差分高斯图像金字塔中进行的! 3.1.3 尺度空间中特征点的检测(DoG中极值点的检测)构造完尺度空间(差分高斯金字塔)后,接下来的任务就是“在尺度中间中检测出图像中的稳定特征点”: 对于DoG中每一个采样点(每一个Octave中每一层),将其与它邻域内所有像素点(8+18=26)进行比较,判断其是否为局部极值点(极大或者极小),更加具体地:如下图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。 一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点。但要注意:这种相邻层之间的极值点的寻找是在同一Octave中的相邻尺度之间进行寻找的,而不要跨组! 同时,应该注意到一个问题,在极值比较的过程中,每一Octave图像的首末两层是无法进行极值比较的,为了满足尺度变化的连续性,需要进行一些修正:在高斯金字塔中生成S+3层图像,具体解释如下:假设s=3,也就是每个塔里有3层,则k=21/s=21/3:
3.2 关键点位置及尺度确定通过拟和“三维二次函数”可以精确确定关键点的位置和尺度(达到亚像素精度),具体方法还未知,可以得到一系列的SIFT候选特征点集合,但由于这些关键点中有些具有较低的对比对,有些输属于不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),所以,为了增强匹配稳定性、提高抗噪声能力,应该将这2类关键点去除,实现对候选SIFT特征点集合的进一步净化:
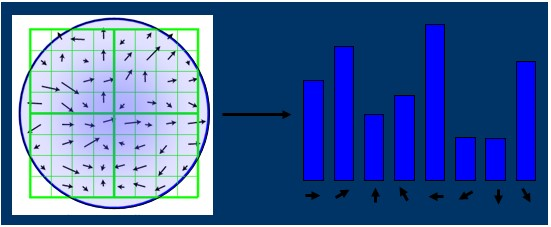
3.3 关键点方向确定
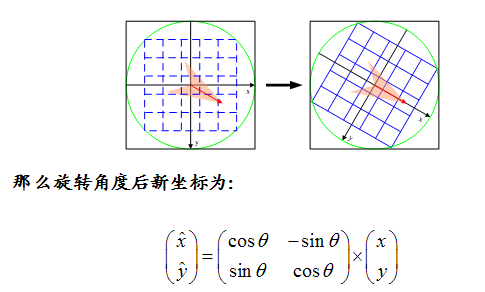
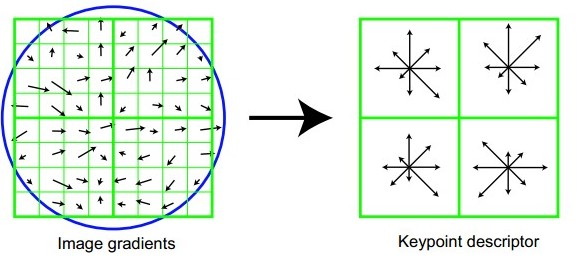
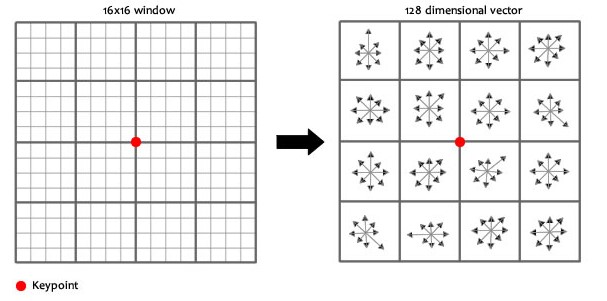
至此,得到了图像中所有关键点的方向!实际上,关键点方向的确定是为了接下来的特征向量生成中的坐标旋转使用的! 3.4 特征向量生成上面只是得到了每个关键点的方向,接下来,需要确定每个关键点的特征向量,具体方式如下:
至此,关键点特征向量完全确定!此时SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则可以进一步去除光照变化的影响。 4.SIFT特征的匹配现有A、B两幅图像,分别利用上面的方法从各幅图像中提取到了k1个sift特征点和k2个特征点及其对应的特征描述子,即维和维的特征,现在需要将两图中各个scale(所有scale)的描述子进行匹配。 接下来采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。
Reference 5.下面是一些参考程序5.1
5.2
|
|
3.Hough变换的优缺点优点:
缺点:
Hough变换利用的是一种投票思想 Reference
|
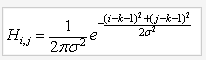



转自: http://www.bfcat.com/index.php/2012/12/inverting-visualizing-features-object-detection/
所有人都知道,计算机视觉是关于看的学问,在调程序的时候,可视化占到了一大部分的地位。当我们使用描述子的时候我们也希望能够看到这个描述字的图案,例如我们很熟悉的SIFT,SURF等描述子的可视化方式。
很多做目标检测的人都对HoG特征描述子非常熟悉,也经常用到。MIT的Carl Vondrick(老板是Antonio Torralba)公布了一个可以用来可视化HoG算子的代码。这段代码提供了4种可视化HoG算子的方式,和普通的,直接把描述子画在图像上的方式不同,这几种可视化方式更直观的展示了HoG描述子在图像上的响应。好像让研究者戴上“HoG眼镜”来像计算机一样观察世界。
在我们用HoG算子进行样本训练的时候,可以利用这种可视化来检查为什么一些负样本会导致虚警,也可以检查正样本自己的类内方差。
最后,作者还和Weinzaepfel et al.设计的SIFT 可视化方式(P. Weinzaepfel, H. Jegou, and P. Perez. Reconstructing an image from its local descriptors. In CVPR, 2011.)进行了对比。
这个程序以及技术报告的网页在这里:http://mit.edu/vondrick/ihog/index.html#overview
https://github.com/cvondrick/ihog
Pinned |
|

想法:怎么把一些“常识”约束加进来——或者“object 和 ambient things 的关系概率”
或者检测出来:鸳鸯、水、以及“汽车”之后,再做一轮PK —— 背后的核心思路是说,“汽车”这个物体和周围的从像素到物体的金字塔各层的关联性(共现)要比较好才行~
pat 点

CNN网络可视化·Visualizing and Understanding Convolutional Networks
Matthew D. Zeiler,Rob Fergus. Visualizing and Understanding Convolutional Networks.CVPR2014.论文下载
一、相关理论本篇博文主要讲解2014年ECCV上的一篇经典文献:《Visualizing and Understanding Convolutional Networks》,可以说是CNN领域可视化理解的开山之作,这篇文献告诉我们CNN的每一层到底学习到了什么特征,然后作者通过可视化进行调整网络,提高了精度。最近两年深层的卷积神经网络,进展非常惊人,在计算机视觉方面,识别精度不断的突破,CVPR上的关于CNN的文献一大堆。然而很多学者都不明白,为什么通过某种调参、改动网络结构等,精度会提高。可能某一天,我们搞CNN某个项目任务的时候,你调整了某个参数,结果精度飙升,但如果别人问你,为什么这样调参精度会飙升呢,你所设计的CNN到底学习到了什么牛逼的特征? 这篇文献的目的,就是要通过特征可视化,告诉我们如何通过可视化的角度,查看你的精度确实提高了,你设计CNN学习到的特征确实比较牛逼。这篇文献是经典必读文献,才发表了一年多,引用次数就已经达到了好几百,学习这篇文献,对于我们今后深入理解CNN,具有非常重要的意义。总之这篇文章,牛逼哄哄。 二、利用反卷积实现特征可视化为了解释卷积神经网络为什么work,我们就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,paper通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积网络在文献《Adaptive deconvolutional networks for mid and high level feature learning》中被提出,是用于无监督学习的。然而本文的反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积网络模型,没有学习训练的过程。 反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。 1、反池化过程我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解: 以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是3*3,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是3*3大小,经过pooling后,就变成了1*1大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到3*3个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子: 在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。 2、反激活我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。 3、反卷积对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),这一点我现在也不是很明白,估计要采用数学的相关理论进行证明。 最后可视化网络结构如下: 网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。到了这边,可以说我们的算法已经学习完毕了,其它部分是文献要解释理解CNN部分,可学可不学。 总的来说算法主要有两个关键点:1、反池化 2、反卷积,这两个源码的实现方法,需要好好理解。 三、理解可视化特征可视化:一旦我们的网络训练完毕了,我们就可以进行可视化,查看学习到了什么东西。但是要怎么看?怎么理解,又是一回事了。我们利用上面的反卷积网络,对每一层的特征图进行查看。 1、特征可视化结果:总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。 2、特征学习的过程。作者给我们显示了,在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一整张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图: 结果:(1)仔细看每一层,在迭代的过程中的变化,出现了sudden jumps;(2)从层与层之间做比较,我们可以看到,低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散嘛。(3)从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。 3、图像变换。从文献中的图片5可视化结果,我们可以看到对于一张经过缩放、平移等操作的图片来说:对网络的第一层影响比较大,到了后面几层,基本上这些变换提取到的特征没什么比较大的变化。 个人总结:我个人感觉学习这篇文献的算法,不在于可视化,而在于学习反卷积网络,如果懂得了反卷积网络,那么在以后的文献中,你会经常遇到这个算法。大部分CNN结构中,如果网络的输出是一整张图片的话,那么就需要使用到反卷积网络,比如图片语义分割、图片去模糊、可视化、图片无监督学习、图片深度估计,像这种网络的输出是一整张图片的任务,很多都有相关的文献,而且都是利用了反卷积网络,取得了牛逼哄哄的结果。所以我觉得我学习这篇文献,更大的意义在于学习反卷积网络。 参考文献: 1、《Visualizing and Understanding Convolutional Networks》 ******************作者:hjimce 时间:2016.1.10 联系QQ:1393852684 原创文章,转载请保留原文地址、作者等信息********** |
|
利用pytorch实现Visualising Image Classification Models and Saliency Maps
saliency mapsaliency map即特征图,可以告诉我们图像中的像素点对图像分类结果的影响。 计算它的时候首先要计算与图像像素对应的正确分类中的标准化分数的梯度(这是一个标量)。如果图像的形状是(3, H, W),这个梯度的形状也是(3, H, W);对于图像中的每个像素点,这个梯度告诉我们当像素点发生轻微改变时,正确分类分数变化的幅度。 计算saliency map的时候,需要计算出梯度的绝对值,然后再取三个颜色通道的最大值;因此最后的saliency map的形状是(H, W)为一个通道的灰度图。 下图即为例子: 上图为图像,下图为特征图,可以看到下图中亮色部分为神经网络感兴趣的部分。 理论依据程序解释下面为计算特征图函数,上下文信息通过注释来获取。
输出为: 另一种梯度的计算法,通过了损失函数计算出来的梯度
这中方法的output为: 参考资料:1、 Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps”, ICLR Workshop 2014. |
|
卷积神经网络可视化原
可视化可以让我们知道一个神经网络正在学习什么。当我们建立一个神经网络结构来进行图片分类预测时,我们想要解释网络预测的原理,例如,我们想要知道为什么网络会预测一张图片是宇宙飞船。 论文一:Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps 论文一为可视化一个正在运行的神经网络提供了两种思路,它们都需要计算输出图片相对于输入图片的梯度。 分类模型可视化:分类任务是产生一个最具代表性的图片。思考:图片的什么地方看起来更像一艘宇宙飞船?我们会发现当图片I的最大分数是Sc(I) 时,这个图片被归类为c。 注:得分Sc(I)是卷积神经网络输出经过softmax函数得出的值,并不是预测可能性。 我们可以开始图片I,使用后向传播算法计算相对于I的梯度,使用梯度上升发现一个更好的I。这个过程是非常相似于优化一个神经网络,不同的是,我们保持权重固定不变,优化图片。 点:有点像E-M?也会存在局部极小点的问题?这个问题可以/值得深入研究?
图片分类的显著性:这个任务的目标是发现图片中的那些像素对确定为一个类别有着比较大的影响力。思考:图片中的那些像素对把图片分类为宇宙飞船有着比较大的影响力?记下分数Sc相对于输入图片I,然后计算图片I0。
上面的计算会使我们在每个像素点处获得一个标量值,利用标量值进行正则化可以获得图片的显著图。
图片的显著图可以用来定位感兴趣的目标,使用分割算法进行分割。注意分类模型智能给出类别,不能进行定位,被称为弱监督定位。 论文二: Learning Deep Features for Discriminative Localization 论文二提出了一种不同的方法可视化图片的显著性图,与论文一使用的后向传播算法不同的是,论文二提出修改前向网络结构实现分类和定位。 网络使用一系列卷积层作为网络的开始,通过一个图片,卷积网络生成K个特征图。每个特征图包含i*j个激活,f(k)(i,j)代表特征图k中的定位点(i,j)。
注:通常情况,图像分类使用卷积层后接全链接层和softmax层,使得输入图片的大小需要一致,论文二采用特征映射的方法使得网络可以处理不同大小的输入,了解更多可以参考Global Average Pooling。 为了使用上面的结构进行分类操作,我们可以获得一个显著图,也叫激活图,对每一个特征图学习一个权重。
论文二的方法可以从激活图中计算分类分数,同时相对于后向优化可以产生更好的可视化效果(?)。 |
|
Pinned |
|
|
Nice! 56 posts in total. Keep on posting.
2019淘宝 oCPC 算法笔记graph-embedding假设检验pCTRdeep-ctr-models贝叶斯定理Xavier 初始化方法RTB 广告竞价策略2018Lookalike 算法综述量化交易笔记CNN 模型压缩方法Optical FlowLoss FunctionAI 精彩视频剪辑:战术竞技类游戏直播视频静态区域检测小波变换简介CNN:目标检测CNN:细粒度分类BackpropCNN 可视化解释:Saliency MapsResNet 学习笔记2017生成模型无约束最优化问题求解iOS 私有 API 调用检测机制探讨在线学习方法概述GloVeGBDTReinforce LearningDeep LearningActivationFactorization MachineMatrix Factorization尝试改进微信读书个性化推荐:一个基于 CTR 预估的方法iOS App 启动必 crash 监控R 语言线性回归应用:拟合 iOS 录音波形图HTML基于word2vec协同过滤推荐2016微信读书冷启动推荐实战:一种基于用户属性的方法学习协同过滤推荐 w 100行Python代码thai-photos初学潜水微信读书冷启动用户书籍推荐初探:一个借助微信用户画像的方法微信读书排版引擎自动化测试iOS 启动连续闪退保护方案2015尝试解决 Xcode7.1 覆盖率测试 GCDA 文件损坏问题notes-on-7-concurrency-model-in-7-weekslearn-haskell五毛和阴谋论SCIP学习笔记通过Swift学函数式编程笔记:软件开发的转折——并发化我的马克思主义观是如何崩塌的Google Chrome Canary:一个可以慢速调试css动画的浏览器2014TODO每晚睡4.5小时,保持精力充沛的秘诀编程珠玑II C12笔记: rand num generator |
|
|
对卷积网络可视化与可解释性相关资料的一些整理,不断更新中~ 目的

博客:
论文:
代码:
Additional: Keras codebase: Tensorflow codebase: PyTorch Regression Activation Map Other Visualization: To look at: 编辑于 2019-01-09
|
|
|
CNN可视化 [TOC] 参考文献:胡秀. 基于卷积神经网络的图像特征可视化研究[D]. 对 CNN 模型的可解释性问题,也称之为深度可视化问题[35]。目前深度可视化方法主要分为两大类,一类通过前向计算直接可视化深度卷积网络每一层的卷积核以及提取的特征图,然后观察其数值变化。一个训练成功的 CNN 网络,其特征图的值会伴随网络深度的加深而越来越稀疏。 另一类可视化方法则通过反向计算,将低维度的特征图反向传播至原图像像素空间,观察特征图被原图的哪一部分激活,从而理解特征图从原图像中学习了何种特征。经典方法有反卷积(Deconvolution)[36]和导向反向传播(Guided-backpropagation)。这两种方法能够在一定程度上“看到”CNN 模型中较深的卷积层所学习到的特征。从本质上说,反卷积和导向反向传播的基础都是反向传播,即对输入进行求导。二者唯一的区别在于反向传播过程中经过 ReLU 层时对梯度的处理策略不同。虽然借助反卷积和导向反向传播方法,能够了解 CNN 模型神秘的内部,但这些方法同时把所有能提取的特征都展示出来了,而对类别并不敏感,因此还不能解释 CNN 分类的结果。 为了更好地理解 CNN,近几年有大量研究工作都在对 CNN 所学到的内部特征进行可视化分析。最初的可视化工作由多伦多大学的 Krizhevshy 等人在 2012 年提出的AlexNet 一文中出现[20]。在这篇开创深度学习新纪元的论文中,Krizhevshy 直接可视化了第一个卷积层的卷积核,如图 1-4 所示[20]。最早使用图片块来可视化卷积核是在 RCNN论文中出现[37]。Girshick 的工作显示了数据库中对 AlexNet 模型较高层某个通道具有较强响应的图片块。如图 1-5 所示[37] 另一种可视化神经网络的思路是通过特征重构出图像,将重构结果与原图进行比较来分析 CNN 的每一层保留了图像的哪些特征。这种可视化思路将 CNN 提取特征的过程视为编码的过程,而对提取到的特征进行重建的过程正好是编码的逆过程,称为解码过程。2014 年,Aravindh Mahendran 等人就提出这种通过重构特征的思想来可视化分析CNN[39]。图像理解的关键部分是图像特征表达。而人对图像特征表征的理解是有限的,因此 Mahendran 采用了一种反演的方法来分析图像特征中所含的视觉信息。之后,Mahendran 又加入自然图像先验的信息进一步通过一些可视化技术来加深人们对图像表示的理解。 2015 年,Yosinski[40]根据以往的可视化成果开发出了两个可视化 CNN 模型的工具。其中一个是针对已经训练好的网络,当传入一张图片或一段视频时,通过对该网络中每一层的激活值进行可视化。另一个可视化工具是通过在图像空间加正则化优化来对深度神经网络每一层提取的特征进行可视化。 在通过重建特征可视化 CNN 的基础上,2016 年,Alexey Dosovitskiy 等人通过建立一个上卷积神经网络(Up-Convolutional Neural Networks,UCNN),对 CNN 不同层提取的图像特征进行重建,从而可以知道输入图像中的哪些信息被保留在所提取的特征中[32]。尽管这种方法也能对全连接层进行可视化,也只是显示全连接层保留了哪些信息,而未对这些信息的相关性及重要性进行分析[41]。 周伯雷等人[42]提出的类别激活映射(Class Activation Mapping,CAM)可视化方法,采用 NIN 和 GoogLeNet 中所用到的全局平均池化(Global Average Pooling,GAP),将卷积神经网络最后的全连接层换成全卷积层,并将输出层的权重反向投影至卷积层特征。这一结构的改进能有效定位图像中有助于分类任务的关键区域。从定位的角度来讲,CAM 方法还能起到目标检测的作用,而且不需要给出目标的边框就能大概定位出图像中的目标位置。尽管CAM已经达到了很不错的可视化效果,但要可视化一个通用的CNN模型,就需要用 GAP 层取代最后的全连接层,这就需要修改原模型的结构,导致重新训练该模型带来大量的工作,限制了 CAM 的使用场景。2016 年,R.Selvaraju 等人[43] 在 CAM 的基础上提出了 Grad-CAM。CAM 通过替换全连接层为 GAP 层,重新训练得到权重,而 Grad-CAM 另辟蹊径,用梯度的全局平均来计算每对特征图对应的权重,最后求一个加权和。Grad-CAM 与 CAM 的主要区别在于求权重的过程。 Deep Visualization:可视化并理解CNN https://blog.csdn.net/zchang81/article/details/78095378 谷歌的新CNN特征可视化方法,构造出一个华丽繁复的新世界 https://www.leiphone.com/news/201711/aNw8ZjqMuqvygzlz.html CNN可视化理解的最新综述 http://m.elecfans.com/article/686276.html CNN模型的可视化 http://www.cctime.com/html/2018-4-12/1373705.htm CNN特征可视化报告 https://wenku.baidu.com/view/86311603f011f18583d049649b6648d7c1c708ed.html Visualizing and Understanding Convolutional Networks https://arxiv.org/pdf/1311.2901.pdf 深度可视化技术己经成为了深度学习中一个学术研究热点,但仍然处于探索阶段。本文的主要研究对象是深度神经网络中数以千计的卷积滤波器。深度神经网络中不同的滤波器会从输入图像中提取不同特征表示。己有的研究表明低层的卷积核提取了图像的低级语义特性(如边缘、角点),高层的卷积滤波器提取了图像的高层语义特性(如图像类别)。但是,由于深度神经网络会以逐层复合的方式从输入数据中提取特征,我们仍然无法像Sobel算子提取的图像边缘结果图一样直观地观察到深度神经网络中的卷积滤波器从输入图像中提取到的特征表示。 第一章 卷积神经网络「深度学习系列」CNN模型的可视化这个网站有cvpr今年的可解释性的文献集合,还挺多的http://openaccess.thecvf.com/CVPR2019_workshops/CVPR2019_Explainable_AI.py、 一个很好的可视化网站:http://shixialiu.com/publications/cnnvis/demo/1.1 网络结构1.2 训练过程1.3 网络搭建1.4 优化算法第二章 CNN可视化概述2.5 窥探黑盒-卷积神经网络的可视化**https://blog.csdn.net/shenziheng1/article/details/85058430 目前卷积深度表示的可视化/解释方法中间激活态/特征图可视化。也就是对卷积神经网络的中间输出特征图进行可视化,这有助于理解卷积神经网络连续的层如何对输入的数据进行展开变化,也有注意了解卷及神经网络每个过滤器的含义。 更深入的, 笔者曾经讲中间激活态结合‘注意力机制’进行联合学习,确实显著提高了算法的精度。 空间滤波器组可视化。卷积神经网络学习的实质可以简单理解为学习一系列空间滤波器组的参数。可视化滤波器组有助于理解视觉模式/视觉概念。 更深入的,笔者曾经思考过,如何才能引导dropout趋向各项同性空间滤波器。因为从视觉感知对信息的捕捉效果来看,更倾向于捕捉高频成分,诸如边缘特征、纹理等。 原始图像中各组分贡献热力图。我们都知道,卷积神经网络是基于感受野以及感受野再次组合进行特征提取的。但是我们需要了解图像中各个部分对于目标识别的贡献如何?这里将会介绍一种hotmap的形式,判断图像中各个成分对识别结果的贡献度概率。 作者:沈子恒 来源:CSDN 原文:https://blog.csdn.net/shenziheng1/article/details/85058430 版权声明:本文为博主原创文章,转载请附上博文链接! 2.1 背景介绍 在当前深度学习的领域,有一个非常不好的风气:一切以经验论,好用就行,不问为什么,很少深究问题背后的深层次原因。从长远来看,这样做就埋下了隐患。举个例子,在1980年左右的时候,美国五角大楼启动了一个项目:用神经网络模型来识别坦克(当时还没有深度学习的概念),他们采集了100张隐藏在树丛中的坦克照片,以及另100张仅有树丛的照片。一组顶尖的研究人员训练了一个神经网络模型来识别这两种不同的场景,这个神经网络模型效果拔群,在测试集上的准确率尽然达到了100%!于是这帮研究人员很高兴的把他们的研究成果带到了某个学术会议上,会议上有个哥们提出了质疑:你们的训练数据是怎么采集的?后来进一步调查发现,原来那100张有坦克的照片都是在阴天拍摄的,而另100张没有坦克的照片是在晴天拍摄的……也就是说,五角大楼花了那么多 的经费,最后就得到了一个用来区分阴天和晴天的分类模型。 当然这个故事应该是虚构的,不过它很形象的说明了什么叫“数据泄露”,这在以前的Kaggle比赛中也曾经出现过。大家不妨思考下,假如我们手里现在有一家医院所有医生和护士的照片,我们希望训练出一个图片分类模型,能够准确的区分出医生和护士。当模型训练完成之后,准确率达到了99%,你认为这个模型可靠不可靠呢?大家可以自己考虑下这个问题。 好在学术界的一直有人关注着这个问题,并引申出一个很重要的分支,就是模型的可解释性问题。那么本文从就从近几年来的研究成果出发,谈谈如何让看似黑盒的CNN模型“说话”,对它的分类结果给出一个解释。注意,本文所说的“解释”,与我们日常说的“解释”内涵不一样:例如我们给孩子一张猫的图片,让他解释为什么这是一只猫,孩子会说因为它有尖耳朵、胡须等。而我们让CNN模型解释为什么将这张图片的分类结果为猫,只是让它标出是通过图片的哪些像素作出判断的。(严格来说,这样不能说明模型是否真正学到了我们人类所理解的“特征”,因为模型所学习到的特征本来就和人类的认知有很大区别。何况,即使只标注出是通过哪些像素作出判断就已经有很高价值了,如果标注出的像素集中在地面上,而模型的分类结果是猫,显然这个模型是有问题的) 作者:丽宝儿 来源:CSDN 原文:https://blog.csdn.net/heruili/article/details/90214280 版权声明:本文为博主原创文章,转载请附上博文链接! 2.2 反卷积和导向反向传播 关于CNN模型的可解释问题,很早就有人开始研究了,姑且称之为CNN可视化吧。比较经典的有两个方法,反卷积(Deconvolution)和导向反向传播(Guided-backpropagation),通过它们,我们能够一定程度上“看到”CNN模型中较深的卷积层所学习到的一些特征。当然这两个方法也衍生出了其他很多用途,以反卷积为例,它在图像语义分割中有着非常重要的作用。 2.2.1 反向传播2.2.2 反卷积2.2.3 导向反向传播2.2.4 反卷积、导向反向传播和反向传播的区别 从本质上说,反卷积和导向反向传播的基础都是反向传播,其实说白了就是对输入进行求导,三者唯一的区别在于反向传播过程中经过ReLU层时对梯度的不同处理策略。
作者:丽宝儿 来源:CSDN 原文:https://blog.csdn.net/heruili/article/details/90214280 版权声明:本文为博主原创文章,转载请附上博文链接! 第三章 基于反卷积的特征可视化使用反卷积(Deconvnet)可视化CNN卷积层,查看各层学到的内容 https://blog.csdn.net/sean2100/article/details/83663212 为了解释卷积神经网络为什么work,我们就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,paper通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积网络在文献《Adaptive deconvolutional networks for mid and high level feature learning》中被提出,是用于无监督学习的。然而本文的反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积网络模型,没有学习训练的过程。 反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张1313大小的特征图(conv5大小为1313),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。 3.1 反池化过程我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解:
以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是33,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是33大小,经过pooling后,就变成了11大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到33个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子:
在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。 3.2 反激活我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。 3.3 反卷积对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),反卷积实际上应该叫卷积转置。 最后可视化网络结构如下: 网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。到了这边,可以说我们的算法已经学习完毕了,其它部分是文献要解释理解CNN部分,可学可不学。 总的来说算法主要有两个关键点:1、反池化 2、反卷积,这两个源码的实现方法,需要好好理解。 3.4 特征可视化结果特征可视化:一旦我们的网络训练完毕了,我们就可以进行可视化,查看学习到了什么东西。但是要怎么看?怎么理解,又是一回事了。我们利用上面的反卷积网络,对每一层的特征图进行查看。 总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。 3.5 特征学习的过程作者给我们显示了,在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一整张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图:
结果:(1)仔细看每一层,在迭代的过程中的变化,出现了sudden jumps;(2)从层与层之间做比较,我们可以看到,低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散嘛。(3)从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。 第四章 基于类别激活映射的特征可视化4.1 GAP让我们小小地绕行一下,先介绍下**全局平均池化(global average pooling,GAP)**这一概念。为了避免全连接层的过拟合问题,网中网(Network in Network)提出了GAP层。GAP层,顾名思义,就是对整个特征映射应用平均池化,换句话说,是一种极端激进的平均池化。 作者:论智链接:https://www.zhihu.com/question/274926848/answer/473562723来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 4.2 CAM从另一方面来说,GAP层的输出,可以认为是“简要概括”了之前卷积层的特征映射。在网中网架构中,GAP后面接softmax激活,ResNet-50中,GAP层后面接一个带softmax激活的全连接层。softmax激活是为了保证输出分类的概率之和为1,对于热图来说,我们并不需要这一约束。所以可以把softmax拿掉。拿掉softmax的全连接层,其实就是线性回归。结果发现,这样一处理,效果挺不错的: 作者:论智链接:https://www.zhihu.com/question/274926848/answer/473562723来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 4.3 Grad-CAM但是CAM要发挥作用,前提是网络架构里面有GAP层,但并不是所有模型都配GAP层的。另外,线性回归的训练是额外的工作。为了克服CAM的这些缺陷,Selvaraju等提出了Grad-CAM。其基本思路是对应于某个分类的特征映射的权重可以表达为梯度,这样就不用额外训练线性回归(或者说线性层)。然后全局平均池化其实是一个简单的运算,并不一定需要专门使用一个网络层。 作者:论智 链接:https://www.zhihu.com/question/274926848/answer/473562723 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 基于局部梯度的神经网络可视化解释 https://www.jianshu.com/p/53062ee77e62 4.4 Grad-CAM++为了得到更好的效果(特别是在某一分类的物体在图像中不止一个的情况下),Chattopadhyay等又进一步提出了Grad-CAM++,主要的变动是在对应于某个分类的特征映射的权重表示中加入了ReLU和权重梯度 4.5 CAM、Grad-CAM、Grad-CAM++架构对比https://blog.csdn.net/weixin_39875161/article/details/90553266 4.6 LIMEhttp://bindog.github.io/blog/2018/02/11/model-explanation-2/ 4.1 CAM CAM方法获取显著图:基于pytorch的实现https://blog.csdn.net/zsx1713366249/article/details/87902476
4.2 Grad-CAM 凭什么相信你,我的CNN模型? http://bindog.github.io/blog/2018/02/10/model-explanation/ 4.3 Grad-CAM 2.2.2.2 卷积神经网络可视化——Grad CAM Python实现 https://blog.csdn.net/ZWX2445205419/article/details/86521829 2.2.3 请问注意力机制中生成的类似热力图或者柱状图是如何生成的? https://www.zhihu.com/question/274926848/answer/473562723 代码 GitHub上有不少Grad-CAM(++)的实现,你可以根据情况自行选择。例如:
当然,你也可以根据Grad-CAM++论文自行实现。 2.2.3.5 Guided Grad-CAM(导向反向传播和Grad-CAM的结合) 1)问题:虽然Grad-CAM可以很好的类别判别能力,也可以将相关区域定位出来,但是其不具备像素空间梯度可视化(比如导向反向传播和反卷积这种细粒度重要性可视化)的方法 2)解决问题: 2.1)首先对图像使用插值法进行上采样 2.2)然后将导向反向传播和Grad-CAM结合起来,实现可视化 第五章 用优化方法形成可视化谷歌的新CNN特征可视化方法,构造出一个华丽繁复的新世界 https://www.leiphone.com/news/201711/aNw8ZjqMuqvygzlz.html 雷锋网 AI 科技评论按:深度神经网络解释性不好的问题一直是所有研究人员和商业应用方案上方悬着的一团乌云,现代CNN网络固然有强大的特征抽取能力,但没有完善的理论可以描述这个抽取过程的本质,人类也很难理解网络学到的表征。 当然了,研究人员们从来都不会放弃尝试。IMCL 2017的最佳论文奖就颁给了 Pang Wei Koh 和 Percy Liang的「Understanding Black-box Predictions via Influence Functions」,探究训练数据对模型训练过程的影响(现场演讲全文点这里);近期引发全面关注的 Geoffery Hinton的胶囊论文也通过多维激活向量带来了更好的解释性,不同的维度表征着不同的属性(虽然解释性的提高算不上是他的原意;论文全文翻译看这里)。 近日,来自谷歌大脑和谷歌研究院的一篇技术文章又从一个新的角度拓展了人类对神经网络的理解,得到的可视化结果也非常亮眼、非常魔性,比如下面这样,文中的结果也在Twitter上引发了许多关注和讨论。
这表达的是什么?这又是怎么来的呢?雷锋网 AI 科技评论把研究内容详细介绍如下。 5.1 用优化方法形成可视化作者们的目标是可视化呈现让网络激活的那些特征,也就是回答“模型都在图像中找什么特征”这个问题。他们的思路是新生成一些会让网络激活的图像,而不是看那些数据集中已有的能让网络激活的图像,因为已有图像中的特征很可能只是“有相关性”,在分析的时候可能只不过是“人类从许多特征中选出了自己认为重要的”,而下面的优化方法就能真正找到图像特征和网络行为中的因果性。 总体来说,神经网络是关于输入可微的。如果要找到引发网络某个行为的输入,不管这个行为只是单个神经元的激活还是最终的分类器输出,都可以借助导数迭代地更新输入,最终确认输入图像和选定特征之间的因果关系。(实际执行中当然还有一些技巧,见下文“特征可视化的实现过程”节)
从随机噪音开始,迭代优化一张图像让它激活指定的某一个神经元(以4a层的神经元11为例) 作者们基于带有 Inception 模块的 GoogLeNet展开了研究,这是一个2014年的模型 (https://arxiv.org/pdf/1409.4842.pdf ),当年也以6.67%的前5位错误率拿下了 ILSVRC 2014图像分类比赛的冠军。模型结构示意图如下;训练数据集是 ImageNet。
GoogLeNet 结构示意图。共有9个Inception模块;3a模块前有两组前后连接的卷积层和最大池化层;3b和4a、4e和5a之间各还有一个最大池化层。
5.2 优化目标有了思路和网络之后就要考虑以网络的哪部分结构作为输入优化的目标;即便对于在数据集中找样本的方法也需要考虑这个。这里就有很多种选择,是单个神经元、某个通道、某一层、softmax前的类别值还是softmax之后的概率。不同的选择自然会带来不同的可视化结果,如下图
以不同的网络结构为目标可以找到不同的输入图像。这里 n 为层序号,x,y 为空间位置, z 为通道序号,k 为类别序号。 要理解网络中的单个特征,比如特定位置的某个神经元、或者一整个通道,就可以找让这个特征产生很高的值的样本。文中多数的图像都是以通道作为目标生成的。 要理解网络中的完整一层,就可以用 DeepDream的目标,找到整个层觉得“有兴趣”的图像。 要从分类器的阶段出发找到输入样本的话,会遇到两个选择,优化softmax前的类别值还是优化softmax后的类别概率。softmax前的类别值其实可以看作每个类别出现的证据确凿程度,softmax后的类别概率就是在给定的证据确凿程度之上的似然值。不过不幸的是,增大softmax后的某一类类别概率的最简单的办法不是让增加这一类的概率,而是降低别的类的概率。所以根据作者们的实验,以softmax前的类别值作为优化目标可以带来更高的图像质量。 5.3 可视化结果一:不同的层优化得到不同的图像3a层
第一个Inception层就已经显示出了一些有意思的纹理。由于每个神经元只有一个很小的感受野,所以整个通道的可视化结果就像是小块纹理反复拼贴的结果。 3b层
纹理变得复杂了一些,但还都是比较局部的特征 4a层
4a层跟在了一个最大池化层之后,所以可以看到复杂性大幅度增加。图像中开始出现更复杂的模式,甚至有物体的一部分。 4b层 可以明显看到物体的某些部分了,检测台球的例子中就能清楚看到球的样子。这时的可视化结果也开始带有一些环境信息,比如树的例子中就能看到树背后的蓝天和树脚下的地面。 4c层 这一层的结果已经足够复杂了,只看几个神经元的优化结果可以比看整个通道更有帮助。有一些神经元只关注拴着的小狗,有的只关注轮子,也有很多其它的有意思的神经元。这也是作者们眼中最有收获的一层。 4d层 这一层中有更复杂的概念,比如第一张图里的某种动物的口鼻部分。另一方面,也能看到一些神经元同时对多个没什么关系的概念产生响应。这时需要通过优化结果的多样性和数据集中的样本帮助理解神经元的行为。 4e层 在这一层,许多神经元已经可以分辨不同的动物种类,或者对多种不同的概念产生响应。不过它们视觉上还是很相似,就会产生对圆盘天线和墨西哥宽边帽都产生反应的滑稽情况。这里也能看得到关注纹理的检测器,不过这时候它们通常对更复杂的纹理感兴趣,比如冰激凌、面包和花椰菜。这里的第一个例子对应的神经元正如大家所想的那样对可以乌龟壳产生反应,不过好玩的是它同样也会对乐器有反应。 5a层 这里的可视化结果已经很难解释了,不过它们针对的语义概念都还是比较特定的 5b层 这层的可视化结果基本都是找不到任何规律的拼贴组合。有可能还能认得出某些东西,但基本都需要多样性的优化结果和数据集中的样本帮忙。这时候能激活神经元的似乎并不是有什么特定语义含义的结构。 5.4 可视化结果二:样本的多样性其实得到可视性结果之后就需要回答一个问题:这些结果就是全部的答案了吗?由于过程中存在一定的随机性和激活的多重性,所以即便这些样本没什么错误,但它们也只展示了特征内涵的某一些方面。 不同激活程度的样本 在这里,作者们也拿数据集中的真实图像样本和生成的样本做了比较。真实图像样本不仅可以展现出哪些样本可以极高程度地激活神经元,也能在各种变化的输入中看到神经元分别激活到了哪些程度。如下图 可以看到,对真实图像样本来说,多个不同的样本都可以有很高的激活程度。 多样化样本 作者们也根据相似性损失或者图像风格转换的方法产生了多样化的样本。如下图 多样化的特征可视化结果可以更清晰地看到是哪些结构能够激活神经元,而且可以和数据集中的照片样本做对比,确认研究员们的猜想的正确性(这反过来说就是上文中理解每层网络的优化结果时有时需要依靠多样化的样本和数据集中的样本)。 比如这张图中,单独看第一排第一张简单的优化结果,我们很容易会认为神经元激活需要的是“狗头的顶部”这样的特征,因为优化结果中只能看到眼睛和向下弯曲的边缘。在看过第二排的多样化样本之后,就会发现有些样本里没有包含眼睛,有些里包含的是向上弯曲的边缘。这样,我们就需要扩大我们的期待范围,神经元的激活靠的可能主要是皮毛的纹理。带着这个结论再去看看数据集中的样本的话,很大程度上是相符的;可以看到有一张勺子的照片也让神经元激活了,因为它的纹理和颜色都和狗的皮毛很相似。 对更高级别的神经元来说,多种不同类别的物体都可以激活它,优化得到的结果里也就会包含这各种不同的物体。比如下面的图里展示的就是能对多种不同的球类都产生响应的情况。 这种简单的产生多样化样本的方法有几个问题:首先,产生互有区别的样本的压力会在图像中增加无关的瑕疵;而且这个优化过程也会让样本之间以不自然的方式产生区别。比如对于上面这张球的可视化结果,我们人类的期待是看到不同的样本中出现不同种类的球,但实际上更像是在不同的样本中出现了各有不同的特征。 多样性方面的研究也揭露了另一个更基础的问题:上方的结果中展示的都还算是总体上比较相关、比较连续的,也有一些神经元感兴趣的特征是一组奇怪的组合。比如下面图中的情况,这个神经元对两种动物的面容感兴趣,另外还有汽车车身。 类似这样的例子表明,想要理解神经网络中的表义过程时,神经元可能不一定是合适的研究对象。 5.5 可视化结果三:神经元间的互动如果神经元不是理解神经网络的正确方式,那什么才是呢?作者们也尝试了神经元的组合。实际操作经验中,我们也认为是一组神经元的组合共同表征了一张图像。单个神经元就可以看作激活空间中的单个基础维度,目前也没发现证据证明它们之间有主次之分。 作者们尝试了给神经元做加减法,比如把表示“黑白”的神经元加上一个“马赛克”神经元,优化结果就是同一种马赛克的黑白版本。这让人想起了Word2Vec中词嵌入的语义加减法,或者生成式模型中隐空间的加减法。 联合优化两个神经元,可以得到这样的结果。 也可以在两个神经元之间取插值,便于更好理解神经元间的互动。这也和生成式模型的隐空间插值相似。 不过这些也仅仅是神经元间互动关系的一点点皮毛。实际上作者们也根本不知道如何在特征空间中选出有意义的方向,甚至都不知道到底有没有什么方向是带有具体的含义的。除了找到方向之外,不同反向之间如何互动也还存在疑问,比如刚才的差值图展示出了寥寥几个神经元之间的互动关系,但实际情况是往往有数百个神经元、数百个方向之间互相影响。 5.6 特征可视化的实现过程如前文所说,作者们此次使用的优化方法的思路很简单,但想要真的产生符合人类观察习惯的图像就需要很多的技巧和尝试了。直接对图像进行优化可能会产生一种神经网络的光学幻觉 —— 人眼看来是一副全是噪声、带有看不出意义的高频图样的图像,但网络却会有强烈的响应。即便仔细调整学习率,还是会得到明显的噪声。(下图学习率0.05) 这些图样就像是作弊图形,用现实生活中不存在的方式激活了神经元。如果优化的步骤足够多,最终得到的东西是神经元确实有响应,但人眼看来全都是高频图样的图像。这种图样似乎和对抗性样本的现象之间有紧密的关系。(雷锋网(公众号:雷锋网) AI 科技评论编译也有同感,关于对抗性样本的更早文章可以看这里) 作者们也不清楚这些高频图样的具体产生原因,他们猜想可能和带有步幅的卷积和最大池化操作有关系,两者都可以在梯度中产生高频率的图样。 通过反向传播过程作者们发现,每次带有步幅的卷积或者最大池化都会在梯度维度中产生棋盘般的图样 这些高频图样说明,虽然基于优化方法的可视化方法不再受限于真实样本,有着极高的自由性,它却也是一把双刃剑。如果不对图像做任何限制,最后得到的就是对抗性样本。这个现象确实很有意思,但是作者们为了达到可视化的目标,就需要想办法克服这个现象。 5.7 不同规范化方案的对比在特征可视化的研究中,高频噪音一直以来都是主要的难点和重点攻关方向。如果想要得到有用的可视化结果,就需要通过某些先验知识、规范化或者添加限制来产生更自然的图像结构。 实际上,如果看看特征可视化方面最著名的论文,它们最主要的观点之一通常都是使用某种规范化方法。不同的研究者们尝试了许多不同的方法。 文章作者们根据对模型的规范化强度把所有这些方法看作一个连续的分布。在分布的一端,是完全不做规范化,得到的结果就是对抗性样本;在另一端则是在现有数据集中做搜索,那么会出现的问题在开头也就讲过了。在两者之间就有主要的三大类规范化方法可供选择。 频率惩罚直接针对的就是高频噪音。它可以显式地惩罚相邻像素间出现的高变化,或者在每步图像优化之后增加模糊,隐式地惩罚了高频噪音。然而不幸的是,这些方法同时也会限制合理的高频特征,比如噪音周围的边缘。如果增加一个双边过滤器,把边缘保留下来的话可以得到一些改善。如下图。 变换健壮性会尝试寻找那些经过小的变换以后仍然能让优化目标激活的样本。对于图像的例子来说,细微的一点点变化都可以起到明显的作用,尤其是配合使用一个更通用的高频规范器之后。具体来说,这就代表着可以随机对图像做抖动、宣传或者缩放,然后把它应用到优化步骤中。如下图。 先验知识。作者们一开始使用的规范化方法都只用到了非常简单的启发式方法来保持样本的合理性。更自然的做法是从真实数据学出一个模型,让这个模型迫使生成的样本变得合理。如果有一个强力的模型,得到的效果就会跟搜索整个数据集类似。这种方法可以得到最真实的可视化结果,但是就很难判断结果中的哪些部分来自研究的模型本身的可视化,哪些部分来自后来学到的模型中的先验知识。 有一类做法大家都很熟悉了,就是学习一个生成器,让它的输出位于现有数据样本的隐空间中,然后在这个隐空间中做优化。比如GAN或者VAE。也有个替代方案是学习一种先验知识,通过它控制概率梯度;这样就可以让先验知识和优化目标共同优化。为先验知识和类别的可能性做优化是,就同步形成了一个限制在这个特定类别数据下的生成式模型。 5.8 预处理与参数化前面介绍的几种方法都降低了梯度中的高频成分,而不是直接去除可视化效果中的高频;它们仍然允许高频梯度形成,只不过随后去减弱它。 有没有办法不让梯度产生高频呢?这里就有一个强大的梯度变换工具:优化中的“预处理”。可以把它看作同一个优化目标的最速下降法,但是要在这个空间的另一个参数化形式下进行,或者在另一种距离下进行。这会改变最快速的那个下降方向,以及改变每个方向中的优化速度有多快,但它并不会改变最小值。如果有许多局部极小值,它还可以拉伸、缩小它们的范围大小,改变优化过程会掉入哪些、不掉入哪些。最终的结果就是,如果用了正确的预处理方法,就可以让优化问题大大简化。 那么带有这些好处的预处理器如何选择呢?首先很容易想到的就是让数据去相关以及白化的方法。对图像来说,这就意味着以Fourier变换做梯度下降,同时要缩放频率的大小这样它们可以都具有同样的能量。 不同的距离衡量方法也会改变最速下降的方向。L2范数梯度就和L∞度量或者去相关空间下的方向很不一样。 所有这些方向都是同一个优化目标下的可选下降方向,但是视觉上看来它们的区别非常大。可以看到在去相关空间中做优化能够减少高频成分的出现,用L∞则会增加高频。 选用去相关的下降方向带来的可视化结果也很不一样。由于超参数的不同很难做客观的比较,但是得到的结果看起来要好很多,而且形成得也要快得多。这篇文章中的多数图片就都是用去相关空间的下降和变换健壮性方法一起生成的(除特殊标明的外)。 那么,是不是不同的方法其实都能下降到同一个点上,是不是只不过正常的梯度下降慢一点、预处理方法仅仅加速了这个下降过程呢?还是说预处理方法其实也规范化(改变)了最终达到的局部极小值点?目前还很难说得清。一方面,梯度下降似乎能一直让优化过程进行下去,只要增加优化过程的步数 —— 它往往并没有真的收敛,只是在非常非常慢地移动。另一方面,如果关掉所有其它的规范化方法的话,预处理方法似乎也确实能减少高频图案的出现。 5.9 结论文章作者们提出了一种新的方法创造令人眼前一亮的可视化结果,在呈现了丰富的可视化结果同时,也讨论了其中的重大难点和如何尝试解决它们。 在尝试提高神经网络可解释性的漫漫旅途中,特征可视化是最有潜力、得到了最多研究的方向之一。不过单独来看,特征可视化也永远都无法带来完全让人满意的解释。作者们把它看作这个方向的基础研究之一,虽然现在还有许多未能解释的问题,但我们也共同希望在未来更多工具的帮助下,人们能够真正地理解深度学习系统。 第六章 理解与可视化卷积神经网络[12.1 可视化卷积神经网络学习到的东西](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1 可视化卷积神经网络学习到的东西)12.1.1可视化激活和第一层权重12.1.2 找到对神经元有最大激活的图像[12.1.3 用 t-SNE 嵌入代码](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1.3 用 t-SNE 嵌入代码)[12.1.4 遮挡部分图像](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1.4 遮挡部分图像)[12.1.5 可视化数据梯度及其他文献](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1.5 可视化数据梯度及其他文献)[12.1.6 基于CNN代码重构原始图像](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1.6 基于CNN代码重构原始图像)[12.1.7 保存了多少空间信息?](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1.7 保存了多少空间信息?)[12.1.8 根据图像属性绘制性能](https://blog.csdn.net/vvcrm01/article/details/82110877#12.1.8 根据图像属性绘制性能)[12.2 玩弄 ConvNets](https://blog.csdn.net/vvcrm01/article/details/82110877#12.2 玩弄 ConvNets)[12.3 将ConvNets 的结果与人类标签比较](https://blog.csdn.net/vvcrm01/article/details/82110877#12.3 将ConvNets 的结果与人类标签比较)第七章 可视化工具https://blog.csdn.net/dcxhun3/article/details/77746550 5.11.4 常见的网络可视化方法 Tensorflow,Pytorch等每一个主流的深度学习框架都提供了相对应的可视化模板,那有没有一种方法更加具有通用性呢?下面介绍常见的网络可视化方法: (1)Netron。Netron支持主流各种框架的模型结构可视化工作,github链接:https://github.com/lutzroeder/Netron 。 (2)Netscope。Netscope在线可视化链接:http://ethereon.github.io/netscope/#/editor。 (2)ConvNetDraw。ConvNetDraw的github链接:https://github.com/cbovar/ConvNetDraw。 (3)Draw_convnet。Draw_convnet的github链接:https://github.com/gwding/draw_convnet。 (4)PlotNeuralNet。PlotNeuralNet的github链接:https://github.com/HarisIqbal88/PlotNeuralNet。 (5)NN-SVG。NN-SVG的github链接:https://github.com/zfrenchee/NN-SVG。 (6)Python + Graphviz。针对节点较多的网络,用python编写一个简单的dot脚本生成工具(MakeNN),可以很方便的输入参数生成nn结构图。 (7)Graphviz - dot。Graphviz的官方链接:https://www.graphviz.org/。 (8)NetworkX。NetworkX的github链接:https://github.com/networkx。 (9)DAFT。daft官网链接:http://daft-pgm.org/。 第三章 可视化组件AlexNet进行了可视化 介绍三种可视化方法 卷积核输出的可视化卷积核输出的可视化(Visualizing intermediate convnet outputs (intermediate activations),即可视化卷积核经过激活之后的结果。能够看到图像经过卷积之后结果,帮助理解卷积核的作用 卷积核的可视化卷积核的可视化(Visualizing convnets filters),帮助我们理解卷积核是如何感受图像的 热度图可视化热度图可视化(Visualizing heatmaps of class activation in an image),通过热度图,了解图像分类问题中图像哪些部分起到了关键作用,同时可以定位图像中物体的位置。 作者:芥末的无奈 来源:CSDN 原文:https://blog.csdn.net/weiwei9363/article/details/79112872 版权声明:本文为博主原创文章,转载请附上博文链接! 第八章 可视化教程8.1 基于DeepStream的CNN的可视化理解https://blog.csdn.net/sparkexpert/article/details/74529094 8.2 Tensorflow实现卷积特征的可视化简单卷积神经网络的tensorboard可视化* https://blog.csdn.net/happyhorizion/article/details/77894048 https://blog.csdn.net/u014281392/article/details/74316028 8.3 基于MatConvNet框架的CNN卷积层与特征图可视化https://blog.csdn.net/jsgaobiao/article/details/80361494 程序下载链接:https://download.csdn.net/download/jsgaobiao/10422273 VGG-f模型链接:http://www.vlfeat.org/matconvnet/models/imagenet-vgg-f.mat 【题目】 编程实现可视化卷积神经网络的特征图,并探究图像变换(平移,旋转,缩放等)对特征图的影响。选择AlexNet等经典CNN网络的Pre-trained模型,可视化每个卷积层的特征图(网络输入图片自行选择)。其中,第一层全部可视化,其余层选取部分特征图进行可视化。然后对图像进行变换,观察图像变换后特征图的变化。 【方法概述】 本次实验使用了VGG-f作为预先加载的模型,通过MATLAB中的load方法将imagenet-vgg-f中的参数加载进程序。 imagenet-vgg-f是一个21层的卷积神经网络,其参数在ImageNet数据集上进行了训练。它的网络结构包括了5层卷积层、3层全连接层,输出的类别可达1000种。网络结构图太长了放在文章最后。 实验中共有6个输入图像,分别是原图input.jpg以及对它进行平移、缩放、旋转、水平翻转、垂直翻转后的图像 首先将输入图像进行归一化操作,也就是将图片resize到网络的标准输入大小224*224,并且将图片的每个像素与均值图片的每个像素相减,再输入网络。 接下来,可视化卷积核的时候,将网络第一层卷积核的参数net.layers{1}.weights{1}提取出来,并使用vl_imarraysc函数进行可视化。第一层卷积核的3个通道在可视化的过程中就被当作RGB三个通道。 对于feature map的可视化任务,需要先使用vl_simplenn将图片输入神经网络并获取其输出结果。我们需要可视化的是每个卷积层后经过ReLU的结果,每个输入图像对应5个特征图。 【结果分析】 由于卷积核的参数是预训练得到的,与输入图片无关,所以只展现一幅图就够了。如下图所示,第一层卷积核学到了图片中一些基础性的特征,比如各种方向的边缘和角点。 下面展示的是原始图片输入后,5个卷积层的可视化结果。需要说明的是,第二层之后的特征图数量较多,因此每层只选取了64个进行可视化。另外,特征图是单通道的灰度图片,为了可视化的效果更好,我将灰度值映射到了“蓝-黄”的颜色区间内,进行了伪彩色的处理,得到了如下的可视化结果。 其中,第一层特征图的细节比较清晰和输入图片较为相似,提取出了输入图片的边缘(包括刺猬身上的刺)。第2、3、4层特征图的分辨率较低,已经难以看出输入图片的特征,但是可以发现有些特征图对背刺区域激活显著,有些特征图对刺猬的外轮廓、背景等区域激活显著。可以猜测,它们提取了图片中比边缘和角点更高层的语义信息。最后一层特征图中有少量对背刺区域激活显著,少量几乎没有被激活。可以猜测,刺猬的背刺特征是网络判断其类别的显著特征,因此被分类为刺猬的图片在最后一个特征层的背刺区域激活最为明显。 【对比分析】 由于篇幅限制,这里只放置较小的略缩图,高清图片可以运行程序自行查看。 我们先对比最清晰的第一层特征图的可视化结果。 可以看出除了缩放的图片以外,其他特征图都随着输入图片的变化而变化:平移的图片作为输入,特征图也产生了相对的平移;翻转、旋转都有类似的效果。只有缩放的输入图片并不影响特征图的表现,其原因应该是VGG-f采用固定大小的输入数据,因此不论图片是否经过缩放,在输入VGG-f之前都会被归一化为同样的大小,所以直观上看并不影响特征图的表现。但是由于分辨率的不同,经过resize之后的图片可能会有像素级别的细微差异,人眼不容易分辨出来。 从另一方面来说,虽然特征图对于输入图片的变换产生了相同的变换,但是特征图中的激活区域并没有显著的变化。这说明VGG-f在图片分类的任务中,对输入图片的大小、旋转、翻转、平移等变化是不敏感的,并不会显著影响其分类结果的准确性。也说明了CNN网络具有一定程度的旋转/平移不变性。 与第一层特征图类似,其他层的特征图也产生了类似的表现,即除了缩放的图片以外,其他作用于输入图片的变换均体现在了特征图上。由于篇幅所限,这里不再单独放出。运行程序即可得到结果。 附上程序下载链接:https://download.csdn.net/download/jsgaobiao/10422273 [VGG-f网络结构图] 作者:jsgaobiao 来源:CSDN 原文:https://blog.csdn.net/jsgaobiao/article/details/80361494 版权声明:本文为博主原创文章,转载请附上博文链接! 8.4 Caffe 特征图可视化https://blog.csdn.net/u012938704/article/details/52767695 8.5 基于Keras的CNN可视化https://blog.csdn.net/weiwei9363/article/details/79112872 In [1]: Out[1]: Visualizing what convnets learnThis notebook contains the code sample found in Chapter 5, Section 4 of Deep Learning with Python. Note that the original text features far more content, in particular further explanations and figures: in this notebook, you will only find source code and related comments. It is often said that deep learning models are "black boxes", learning representations that are difficult to extract and present in a human-readable form. While this is partially true for certain types of deep learning models, it is definitely not true for convnets. The representations learned by convnets are highly amenable to visualization, in large part because they are representations of visual concepts. Since 2013, a wide array of techniques have been developed for visualizing and interpreting these representations. We won't survey all of them, but we will cover three of the most accessible and useful ones:
For the first method -- activation visualization -- we will use the small convnet that we trained from scratch on the cat vs. dog classification problem two sections ago. For the next two methods, we will use the VGG16 model that we introduced in the previous section. Visualizing intermediate activationsVisualizing intermediate activations consists in displaying the feature maps that are output by various convolution and pooling layers in a network, given a certain input (the output of a layer is often called its "activation", the output of the activation function). This gives a view into how an input is decomposed unto the different filters learned by the network. These feature maps we want to visualize have 3 dimensions: width, height, and depth (channels). Each channel encodes relatively independent features, so the proper way to visualize these feature maps is by independently plotting the contents of every channel, as a 2D image. Let's start by loading the model that we saved in section 5.2: In [2]: This will be the input image we will use -- a picture of a cat, not part of images that the network was trained on: In [3]: Let's display our picture: In [4]: In order to extract the feature maps we want to look at, we will create a Keras model that takes batches of images as input, and outputs the activations of all convolution and pooling layers. To do this, we will use the Keras class In [5]: When fed an image input, this model returns the values of the layer activations in the original model. This is the first time you encounter a multi-output model in this book: until now the models you have seen only had exactly one input and one output. In the general case, a model could have any number of inputs and outputs. This one has one input and 8 outputs, one output per layer activation. In [6]: For instance, this is the activation of the first convolution layer for our cat image input: In [7]: It's a 148x148 feature map with 32 channels. Let's try visualizing the 3rd channel: In [8]: This channel appears to encode a diagonal edge detector. Let's try the 30th channel -- but note that your own channels may vary, since the specific filters learned by convolution layers are not deterministic. In [9]: This one looks like a "bright green dot" detector, useful to encode cat eyes. At this point, let's go and plot a complete visualization of all the activations in the network. We'll extract and plot every channel in each of our 8 activation maps, and we will stack the results in one big image tensor, with channels stacked side by side. In [10]: 视频识别怎样理解?其实,我们可以将其可视化!综述: 本文主要描述的是为视频识别设计的深层网络的显著图(saliency maps)。从早前的论文《卷积神经网络的可视化》(European conference on computer vision. Springer, Cham, 2014)、《可识别定位的深度特征学习》(In CVPR, 2016),以及《Grad-cam:何出此言?基于梯度定位的深度网络视觉解释》(arXiv preprint arXiv:1610.02391 (2016). In ICCV 2017)可以看出,显著图能够有助于可视化模型之所以产生给定预测的原因,发现数据中的假象,并指向一个更好的架构。 什么是可解释性?http://www.sohu.com/a/215753405_465975 我们应该把可解释性看作人类模仿性(human simulatability)。如果人类可以在合适时间内采用输入数据和模型参数,经过每个计算步,作出预测,则该模型具备模仿性(Lipton 2016)。 这是一个严格但权威的定义。以医院生态系统为例:给定一个模仿性模型,医生可以轻松检查模型的每一步是否违背其专业知识,甚至推断数据中的公平性和系统偏差等。这可以帮助从业者利用正向反馈循环改进模型。 树正则化 --斯坦福完全可解释深度神经网络:你需要用决策树搞点事其论文《Beyond Sparsity: Tree Regularization of Deep Models for Interpretability》已被 AAAI 2018 接收。 很幸运,学界人士也提出了很多对深度学习的理解。以下是几个近期论文示例: http://www.sohu.com/a/215753405_465975
参考资料
参考文献.... 未完待续! |

























































