基于 Apache Flink 和规则引擎的实时风控解决方案
对一个互联网产品来说,典型的风控场景包括:注册风控、登陆风控、交易风控、活动风控等,而风控的最佳效果是防患于未然,所以事前事中和事后三种实现方案中,又以事前预警和事中控制最好。这要求风控系统一定要有实时性。本文就介绍一种实时风控解决方案。风控是业务场景的产物,风控系统直接服务于业务系统,与之相关的还有惩罚系统和分析系统,各系统关系与角色如下:
业务系统,通常是 APP + 后台 或者 web,是互联网业务的载体,风险从业务系统触发;
- 风控系统,为业务系统提供支持,根据业务系统传来的数据或埋点信息来判断当前用户或事件有无风险;
- 惩罚系统,业务系统根据风控系统的结果来调用,对有风险的用户或事件进行控制或惩罚,比如增加验证码、限制登陆、禁止下单等等;
- 分析系统,该系统用以支持风控系统,根据数据来衡量风控系统的表现,比如某策略拦截率突然降低,那可能意味着该策略已经失效,又比如活动商品被抢完的时间突然变短,这表明总体活动策略可能有问题等等,该系统也应支持运营/分析人员发现新策略;
其中风控系统和分析系统是本文讨论的重点,而为了方便讨论,我们假设业务场景如下:
风控系统有规则和模型两种技术路线,规则的优点是简单直观、可解释性强、灵活,所以长期活跃在风控系统之中,但缺点是容易被攻破,一但被黑产猜中就会失效,于是在实际的风控系统中,往往需要再结合上基于模型的风控环节来增加健壮性。但限于篇幅,本文中我们只重点讨论一种基于规则的风控系统架构,当然如果有模型风控的诉求,该架构也完全支持。规则就是针对事物的条件判断,我们针对注册、登陆、交易、活动分别假设几条规则,比如:
- 某 IP 最近 1 小时注册账号数超过 10 个;
- 某账号群体最近 1 小时购买优惠商品超过 100 件;
规则可以组合成规则组,为了简单起见,我们这里只讨论规则。
- 事实,即被判断的主体和属性,如上面规则的账号及登陆次数、IP 和注册次数等;
- 指标阈值,判断的依据,比如登陆次数的临界阈值,注册账号数的临界阈值等;
规则可由运营专家凭经验填写,也可由数据分析师根据历史数据发掘,但因为规则在与黑产的攻防之中会被猜中导致失效,所以无一例外都需要动态调整。
- 实时风控数据流,由红线标识,同步调用,为风控调用的核心链路;
- 准实时指标数据流,由蓝线标识,异步写入,为实时风控部分准备指标数据;
- 准实时/离线分析数据流,由绿线标识,异步写入,为风控系统的表现分析提供数据;
实时风控是整个系统的核心,被业务系统同步调用,完成对应的风控判断。前面提到规则往往由人编写并且需要动态调整,所以我们会把风控判断部分与规则管理部分拆开。规则管理后台为运营服务,由运营人员去进行相关操作:
- 场景管理,决定某个场景是否实施风控,比如活动场景,在活动结束后可以关闭该场景;
- 黑白名单,人工/程序找到系统的黑白名单,直接过滤;
- 规则管理,管理规则,包括增删或修改,比如登陆新增 IP 地址判断,比如下单新增频率校验等;
- 阈值管理,管理指标的阈值,比如规则为某 IP 最近 1 小时注册账号数不能超过 10 个,那 1 和 10 都属于阈值;
讲完管理后台,那规则判断部分的逻辑也就十分清晰了,分别包括前置过滤、事实数据准备、规则判断三个环节。
2.1.1 前置过滤
业务系统在特定事件(如注册、登陆、下单、参加活动等)被触发后同步调用风控系统,附带相关上下文,比如 IP 地址,事件标识等,规则判断部分会根据管理后台的配置决定是否进行判断,如果是,接着进行黑白名单过滤,都通过后进入下一个环节。
2.1.2 实时数据准备
在进行判断之前,系统必须要准备一些事实数据,比如:
- 注册场景,假如规则为单一 IP 最近 1 小时注册账号数不超过 10 个,那系统需要根据 IP 地址去 Redis/Hbase 找到该 IP 最近 1 小时注册账号的数目,比如 15;
- 登陆场景,假如规则为单一账号最近 3 分钟登陆次数不超过 5 次,那系统需要根据账号去 Redis/Hbase 找到该账号最近 3 分钟登陆的次数,比如 8;
Redis/Hbase 的数据产出我们会在第 2.2 节准实时数据流中进行介绍。
2.2.3 规则判断
在得到事实数据之后,系统会根据规则和阈值进行判断,然后返回结果,整个过程便结束了。整个过程逻辑上是清晰的,我们常说的规则引擎主要在这部分起作用,一般来说这个过程有两种实现方式:
- 借助成熟的规则引擎,比如 Drools,Drools 和 Java 环境结合的非常好,本身也非常完善,支持很多特性,不过使用比较繁琐,有较高门槛,可参考文章【1】;
- 基于 Groovy 等动态语言自己完成,这里不做赘述。可参考文章【2】;
这部分属于后台逻辑,为风控系统服务,准备事实数据。把数据准备与逻辑判断拆分,是出于系统的性能/可扩展性的角度考虑的。前边提到,做规则判断需要事实的相关指标,比如最近一小时登陆次数,最近一小时注册账号数等等,这些指标通常有一段时间跨度,是某种状态或聚合,很难在实时风控过程中根据原始数据进行计算,因为风控的规则引擎往往是无状态的,不会记录前面的结果。同时,这部分原始数据量很大,因为用户活动的原始数据都要传过来进行计算,所以这部分往往由一个流式大数据系统来完成。在这里我们选择 Flink,Flink 是当今流计算领域无可争议的 No.1,不管是性能还是功能,都能很好的完成这部分工作。
-
业务系统把埋点数据发送到 Kafka;
-
Flink 订阅 Kafka,完成原子粒度的聚合;
注:Flink 仅完成原子粒度的聚合是和规则的动态变更逻辑相关的。举例来说,在注册场景中,运营同学会根据效果一会要判断某 IP 最近 1 小时的注册账号数,一会要判断最近 3 小时的注册账号数,一会又要判断最近 5 小时的注册账号数……也就是说这个最近 N 小时的 N 是动态调整的。那 Flink 在计算时只应该计算 1 小时的账号数,在判断过程中根据规则来读取最近 3 个 1 小时还是 5 个 1 小时,然后聚合后进行判断。因为在 Flink 的运行机制中,作业提交后会持续运行,如果调整逻辑需要停止作业,修改代码,然后重启,相当麻烦;同时因为 Flink 中间状态的问题,重启还面临着中间状态能否复用的问题。所以假如直接由 Flink 完成 N 小时的聚合的话,每次 N 的变动都需要重复上面的操作,有时还需要追数据,非常繁琐。
- Flink 把汇总的指标结果写入 Redis 或 Hbase,供实时风控系统查询。两者问题都不大,根据场景选择即可。
通过把数据计算和逻辑判断拆分开来并引入 Flink,我们的风控系统可以应对极大的用户规模。前面的东西静态来看是一个完整的风控系统,但动态来看就有缺失了,这种缺失不体现在功能性上,而是体现在演进上。即如果从动态的角度来看一个风控系统的话,我们至少还需要两部分,一是衡量系统的整体效果,一是为系统提供规则/逻辑升级的依据。
- 判断规则是否多余,比如某规则从来没拦截过任何事件;
- 判断规则是否有漏洞,比如在举办某个促销活动或发放代金券后,福利被领完了,但没有达到预期效果;
- 发现全局规则,比如某人在电子产品的花费突然增长了 100 倍,单独来看是有问题的,但整体来看,可能很多人都出现了这个现象,原来是苹果发新品了……
- 识别某种行为的组合,单次行为是正常的,但组合是异常的,比如用户买菜刀是正常的,买车票是正常的,买绳子也是正常的,去加油站加油也是正常的,但短时间内同时做这些事情就不是正常的。
- 群体识别,比如通过图分析技术,发现某个群体,然后给给这个群体的所有账号都打上群体标签,防止出现那种每个账号表现都正常,但整个群体却在集中薅羊毛的情况。
这便是分析系统的角色定位,在他的工作中有部分是确定性的,也有部分是探索性的,为了完成这种工作,该系统需要尽可能多的数据支持,如:
- 业务系统的数据,业务的埋点数据,记录详细的用户、交易或活动数据;
- 风控拦截数据,风控系统的埋点数据,比如某个用户在具有某些特征的状态下因为某条规则而被拦截,这条拦截本身就是一个事件数据;
这是一个典型的大数据分析场景,架构也比较灵活,我仅仅给出一种建议的方式。
相对来说这个系统是最开放的,既有固定的指标分析,也可以使用机器学习/数据分析技术发现更多新的规则或模式,限于篇幅,这里就不详细展开了。http://archive.keyllo.com/L-编程/drools-从Drools规则引擎到风控反洗钱系统v0.3.2.pdfhttps://www.jianshu.com/p/d6f45f91bedehttps://jinfei21.github.io/2018/09/29/基于规则的风控系统/https://sq.163yun.com/blog/article/183314611296591872https://sq.163yun.com/blog/article/213006222321659904https://github.com/sunpeak/riskcontrol
Apache Flink 及大数据领域盛会 Flink Forward Asia 2019 将于 11月28-30日在北京国家会议中心举办,大会议程已上线,点击「阅读原文」可了解大会议程详情。
(点击图片可查看 Flink Forward Asia 2019 详情)
从滴滴的Flink CEP引擎说起

CEP业务场景
复杂事件处理(Complex Event Process,简称CEP)用来检测无尽数据流中的复杂模 式,拥有从不同的数据行中辨识查找模式的能力。模式匹配是复杂事件处理的一个强 大援助。 例子包括受一系列事件驱动的各种业务流程,例如在安全应用中侦测异常行为;在金 融应用中查找价格、交易量和其他行为的模式。其他常见的用途如欺诈检测应用和传 感器数据的分析等。
说了这么多可能还是觉得比较抽象,那么我们可以看看这次滴滴分享的FlinkCEP在滴滴中的业务场景。



吐槽时刻:
虽然,业务场景ppt写的很好,但是最近几次顺风车事故,给大家留下了糟糕的印象。大数据没用起来,cep其实应该也可以用在顺风车安全检测上吧。
Flink CEP
Flink的CEP是基于Flink Runtime构建的实时数据规则引擎,擅长解决跨事件的匹配问题。
可以看看,滴滴的屁屁踢上给出的两个demo
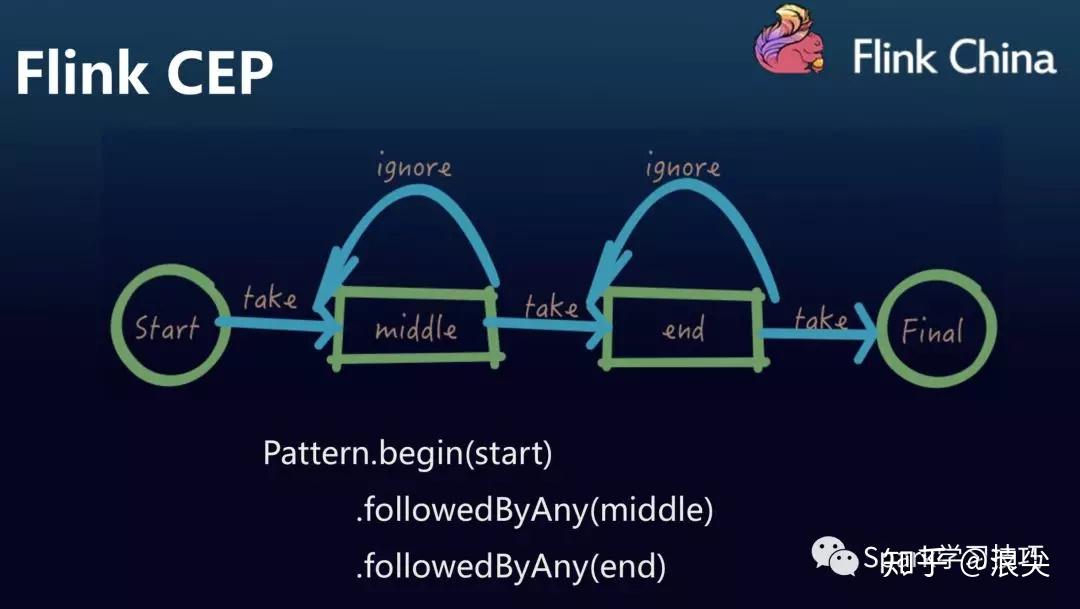
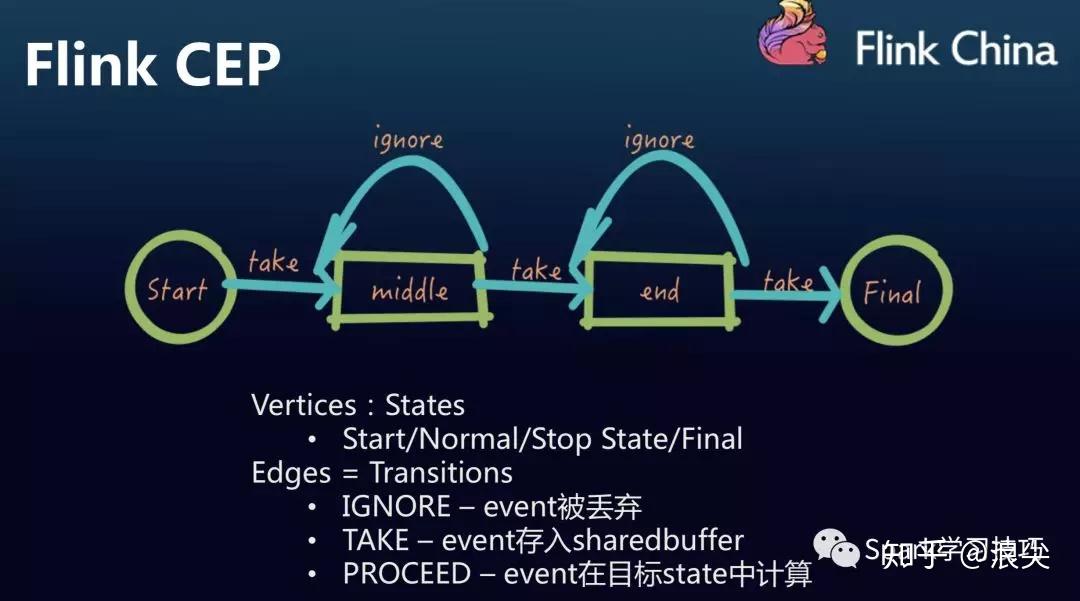
Flink CEP的特点

动态规则
其实,对于实时领域的规则引擎,我们不想每次修改都要打包编码,只希望简单修改一下规则就让它能执行。
当然,最好规则是sql 的形式,运营人员直接参与规则编写而不是频繁提需求,很麻烦。。。。此处,省略万字。。
要知道flink CEP官网给出的API也还是很丰富的,虽然滴滴这比也给出了他们完善的内容。

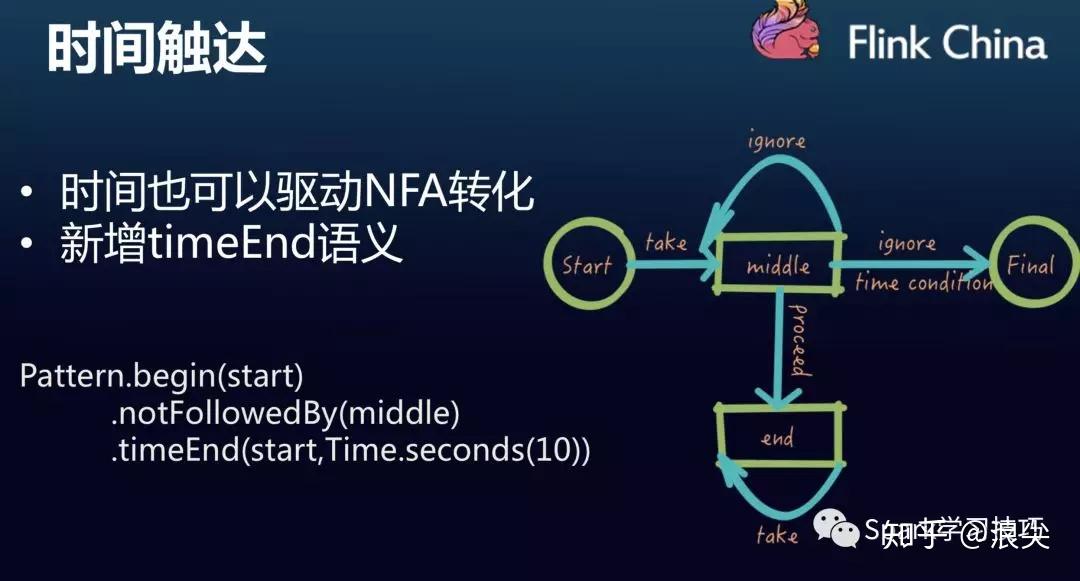
flink官方的CEP文章,浪尖及浪尖组织的flink小团队,已经翻译过了。链接如下:
https://github.com/crestofwave1/oneFlink/blob/master/doc/CEP/FlinkCEPOfficeWeb.md
那么,为了实现动态规则编写,滴滴的架构如下:
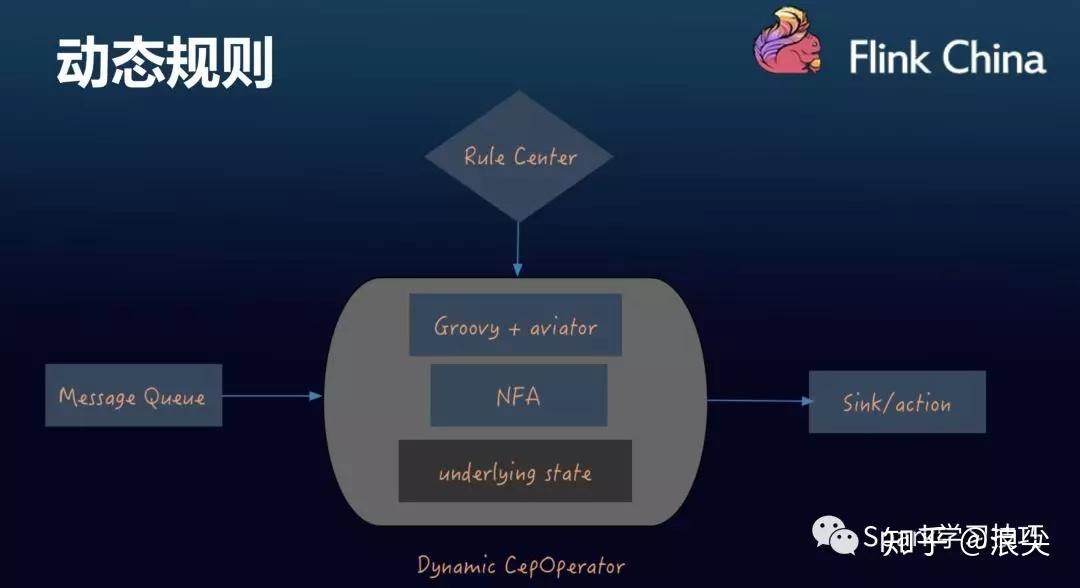
具体的规则实现如下:

可以看到,其规则还是要编码成java代码,然后再用groovy动态编译解析,不知道效率如何。。。
对于规则引擎,当然很多人想到的是drools,这个跟flink结合也很简单,但是效率不怎么苟同。
Flink CEP的SQL实现
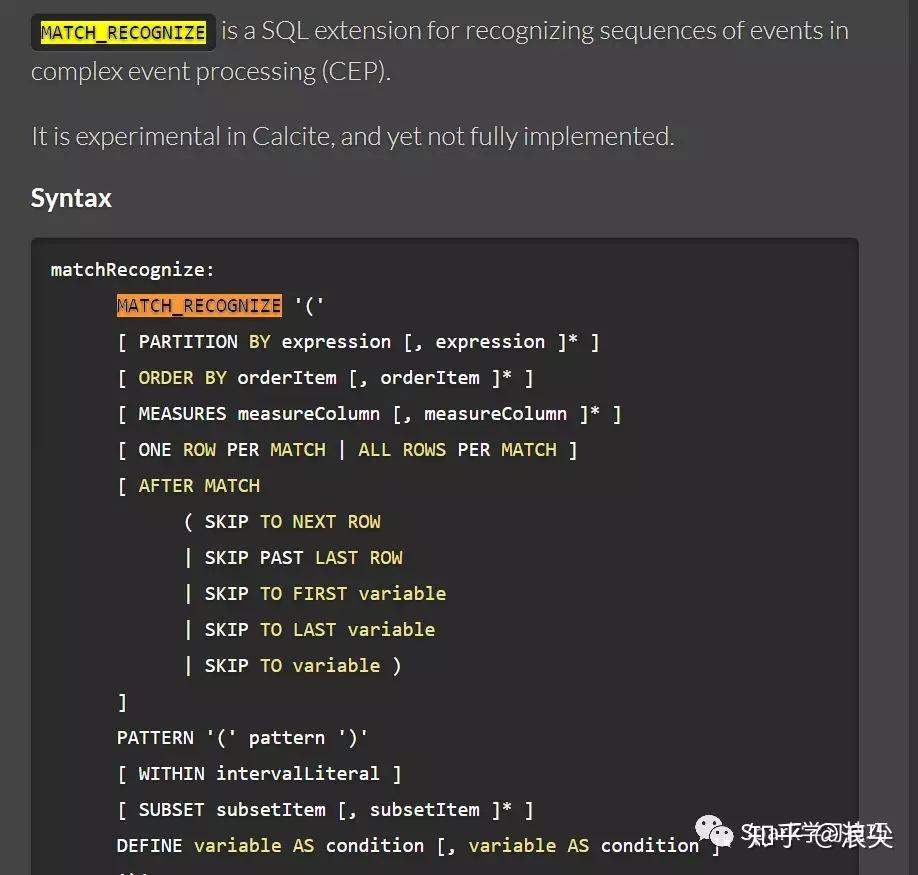
熟悉flink的小伙伴肯定都知道Flink的SQL引擎是基于Calcite来实现的。那么细心的小伙伴,在calcite官网可以发现,calcite有个关键字MATCH_RECOGNIZE。可以在这个网页搜索,找到MATCH_RECOGNIZE关键字使用。
http://calcite.apache.org/docs/reference.html
那么这时候可能会兴冲冲写个demo。
final String sql = "select frequency,word,timestamp1 "
+ " from wc match_recognize "
+ " ("
+ " order by timestamp1 "
+ " measures A.timestamp1 as timestamp1 ,"
+ " A.word as word ,"
+ " A.frequency as frequency "
+ " ONE ROW PER MATCH "
+ " pattern (A B) "
+ " within interval '5' second "
+ " define "
+ " A AS A.word = 'bob' , "
+ " B AS B.word = 'kaka' "
+ " ) mr";很扫兴的它报错了:
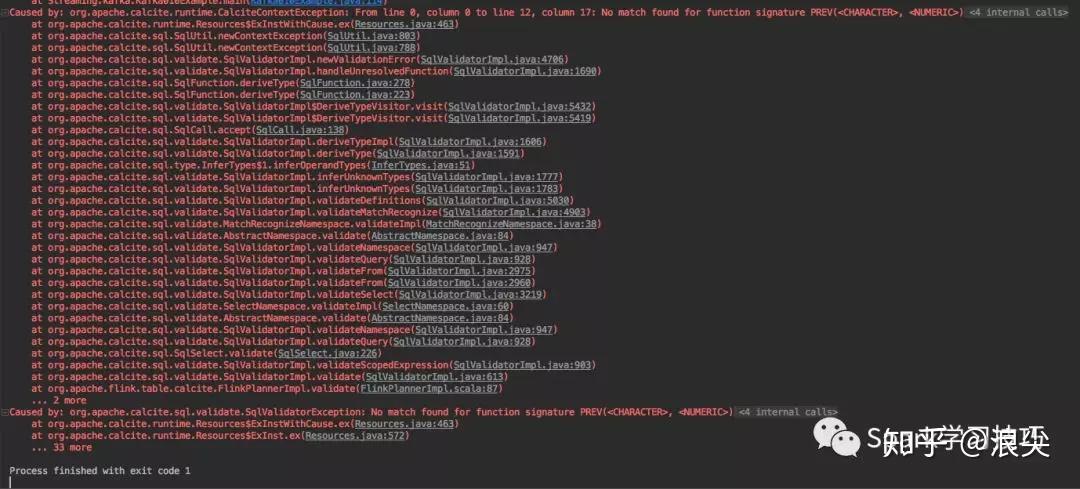
那么问题来了,calcite支持而flink不支持,为啥?
赶紧发了个issue,然后迅速得到官方回复:

但是,翻翻阿里的blink使用手册和华为的flink使用手册发现两者都支持。
好吧。其实,很不服气,周末,除了健身就是加班。
波折一番,解决了,需要修改flink-table相关的内容,执行计划,coden等。
最终,实现了。

滴滴是如何从零构建集中式实时计算平台的?
阅读数:35242019 年 2 月 7 日 09:00
滴滴出行作为一家出行领域的互联网公司,其核心业务是一个实时在线服务。因此具有丰富的实时数据和实时计算场景。本文将介绍滴滴实时计算发展之路以及平台架构实践。
01 实时计算演进
随着滴滴业务的发展,滴滴的实时计算架构也在快速演变。到目前为止大概经历了三个阶段,第一阶段是业务方自建小集群;第二阶段是集中式大集群、平台化;第三阶段是 SQL 化。图 1 标识了其中重要的里程碑,下面给出详细阐述。
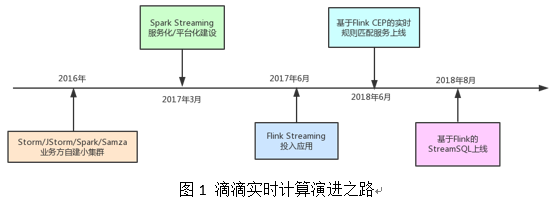
在 2017 年以前滴滴并有没有统一的实时计算平台,而是各个业务方自建小集群。其中用到的引擎有 Storm、JStorm、Spark Streaming、Samza 等。业务方自建小集群模式存在如下弊端:
(1)需要预先采购大量机器,由于单个业务独占,资源利用率通常比较低;
(2)缺乏有效的监控报警体系;
(3)维护难度大,需要牵涉业务方大量精力来保障集群的稳定性;
(4)缺乏有效技术支持,且各自沉淀的东西难以共享。
为了有效解决以上问题,滴滴从 2017 年年初开始构建统一的实时计算集群及平台。技术选型上,我们基于滴滴现状选择了内部用以大规模数据清洗的 Spark Streaming 引擎,同时引入 On-YARN 模式。利用 YARN 的多租户体系构建了认证、鉴权、资源隔离、计费等机制。相对于离线计算,实时计算任务对于稳定性有着更高的要求,为此我们构建了两层资源隔离体系。
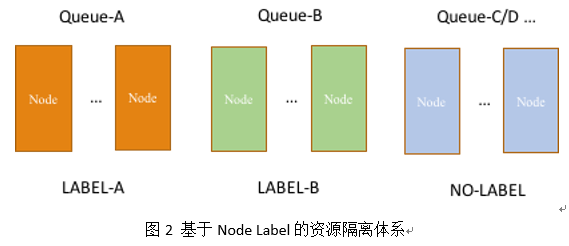
第一层是基于 CGroup 做进程(Container)级别的 CPU 及内存隔离。第二层是物理机器级别的隔离。我们通过改造 YARN 的 FairScheduler 使其支持 Node Label。达到的效果如图 2 所示:普通业务的任务混跑在同一个 Label 机器上,而特殊业务的任务跑在专用 Label 的机器上。
通过集中式大集群和平台化建设,基本消除了业务方自建小集群带来的弊端,实时计算也进入了第二阶段。伴随着业务的发展,我们发现 Spark Streaming 的 Micro Batch 模式在一些低延时的报警业务及在线业务上显得捉襟见肘。于是我们引入了基于 Native Streaming 模式的 Flink 作为新一代实时计算引擎。Flink 不仅延时可以做到毫秒级,而且提供了基于 Process Time/Event Time 丰富的窗口函数。基于 Flink 我们联合业务方构架了滴滴流量最大的业务网关监控系统,并快速支持了诸如乘客位置变化通知、轨迹异常检测等多个线上业务。
02 实时计算平台架构
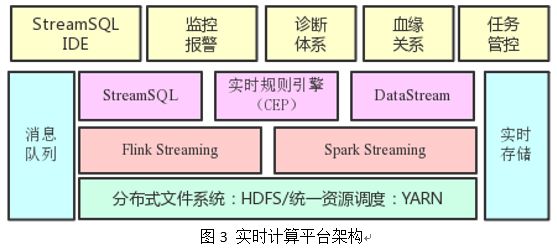
为了最大程度方便业务方开发和管理流计算任务,我们构建了如图 3 所示的实时计算平台。在流计算引擎基础上提供了 StreamSQL IDE、监控报警、诊断体系、血缘关系、任务管控等能力。以下分别介绍各自的作用:
(1)StreamSQL IDE。下文会介绍,是一个 Web 化的 SQL IDE;
(2)监控报警。提供任务级的存活、延时、流量等监控以及基于监控的报警能力;
(3)诊断体系。包括流量曲线、Checkpoint、GC、资源使用等曲线视图,以及实时日志检索能力。
(4)血缘关系。我们在流计算引擎中内置了血缘上报能力,进而在平台上呈现流任务与上下游的血缘关系;
(5)任务管控。实现了多租户体系下任务提交、启停、资产管理等能力。通过 Web 化任务提交消除了传统客户机模式,使得平台入口完全可控,内置参数及版本优化得以快速上线。
03 实时规则匹配服务建设
在滴滴内部有大量的实时运营场景,比如“某城市乘客冒泡后 10 秒没有下单”。针对这类检测事件之间依赖关系的场景,用 Fink 的 CEP 是非常合适的。但是社区版本的 CEP 不支持描述语言,每个规则需要开发一个应用,同时不支持动态更新规则。为了解决这些问题,滴滴做了大量功能扩展及优化工作。功能扩展方面主要改动有:
(1)支持 wait 算子。对于刚才例子中的运营规则,社区版本是表达不了的。滴滴通过增加 wait 算子,实现了这类需求;
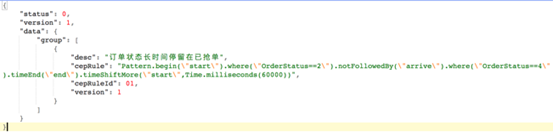
(2)支持 DSL 语言。基于 Groovy 和 Aviator 解析引擎,我们实现了如图 4 所示的 DSL 描述规则能力。
(3)单任务多规则及规则动态更新。由于实时运营规则由一线运营同学来配置,所以规则数量,规则内容及规则生命周期会经常发生变化。这种情况每个规则一个应用是不太现实的。为此我们开发了多规则模式且支持了动态更新。
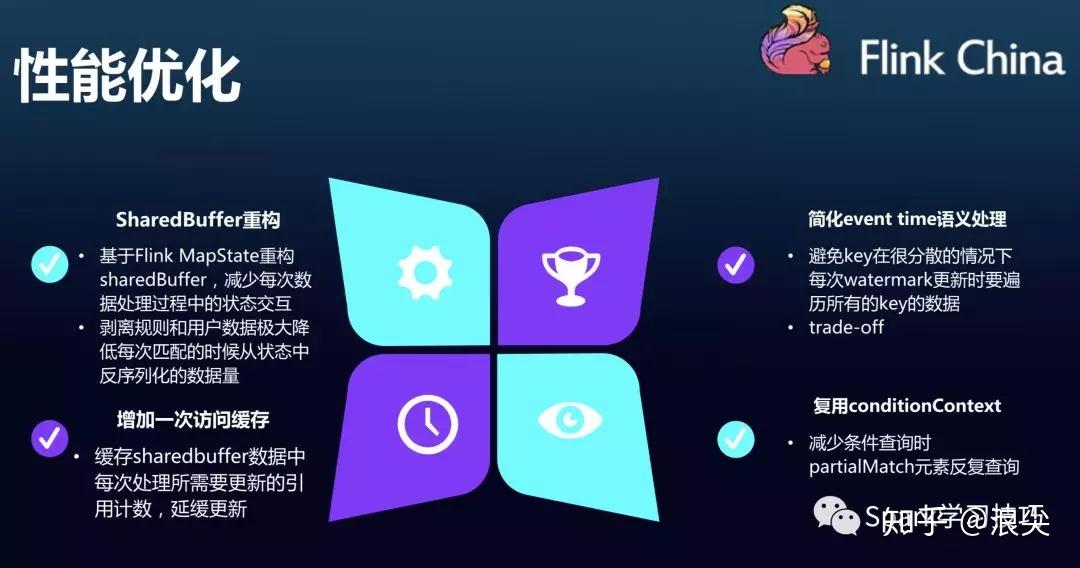
除了功能拓展之外,为了应对大规模运营规则的挑战,滴滴在 CEP 性能上也做了大量优化,主要有:
(1)SharedBuffer 重构。基于 Flink MapState 重构 SharedBuffer,减少每次数据处理过程中的状态交互。同时剥离规则和用户数据极大降低每次匹配的时候从状态中反序列化的数据量;
(2)增加访问缓存(已贡献社区)。缓存 SharedBuffer 数据中每次处理所需要更新的引用计数,延缓更新;
(3)简化 event time 语义处理。避免 key 在很分散情况下每次 watermark 更新时要遍历所有 key 的数据;
(4)复用 conditionContext(已贡献社区)。减少条件查询时对 partialMatch 元素的反复查询。
以上优化将 CEP 性能提升了多个数量级。配合功能扩展,我们在滴滴内部提供了如图 5 所示的服务模式。业务方只需要清洗数据并提供规则列表 API 即可具备负责规则的实时匹配能力。

目前滴滴 CEP 已经在快车个性化运营、实时异常工单检测等业务上落地,取得了良好的效果。
04 StreamSQL 建设
正如离线计算中 Hive 之于 MapReduce 一样,流式 SQL 也是必然的发展趋势。通过 SQL 化可以大幅度降低业务方开发流计算的难度,业务方不再需要学习 Java/Scala,也不需要理解引擎执行细节及各类参数调优。为此我们在 2018 年启动了 StreamSQL 建设项目。我们在社区 Flink SQL 基础上拓展了以下能力:
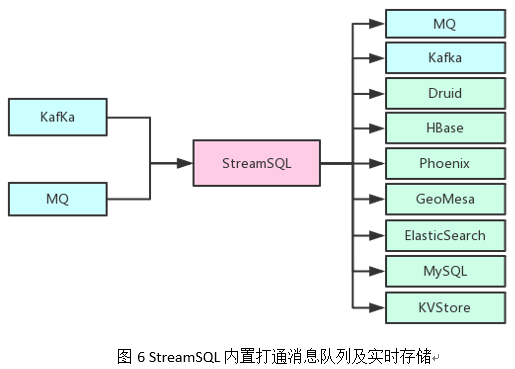
(1)扩展 DDL 语法。如图 6 所示,打通了滴滴内部主流的消息队列以及实时存储系统。通过内置常见消息格式(如 json、binlog、标准日志)的解析能力,使得用户可以轻松写出 DDL 语法,并避免重复写格式解析语句。
(2)拓展 UDF。针对滴滴内部常见处理逻辑,内置了大量 UDF,包括字符串处理、日期处理、Map 对象处理、空间位置处理等。
(3)支持分流语法。单个输入源多个输出流在滴滴内部非常常见,为此我们改造了 Calcite 使其支持分流语义。
(4)支持基于 TTL 的 join 语义。传统的 Window Join 因为存在 window 边界数据突变情况,不能满足滴滴内部的需求。为此我们引入了 TTL State,并基于此开发了基于 TTL Join 的双流 join 以及维表 join。
(5)StreamSQL IDE。前文提到平台化之后我们没有提供客户机,而是通过 Web 提交和管控任务。因此我们也相应开发了 StreamSQL IDE,实现 Web 上开发 StreamSQL,同时提供了语法检测、DEBUG、诊断等能力。
目前 StreamSQL 在滴滴已经成功落地,流计算开发成本得到大幅度降低。预期未来将承担 80% 的流计算业务量。
05 总结
作为一家出行领域的互联网公司,滴滴对实时计算有天然的需求。过去的一年多时间里,我们从零构建了集中式实时计算平台,改变了业务方自建小集群的局面。为满足低延时业务的需求,成功落地了 Flink Streaming,并基于 Flink 构建了实时规则匹配(CEP)服务以及 StreamSQL,使得流计算开发能力大幅度降低。未来将进一步拓展 StreamSQL,并在批流统一、IoT、实时机器学习等领域探索和建设。
本文转载自公众号“滴滴技术“。