slides 讲得是相当清楚了:
http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf
配合中文翻译来看:
https://www.cnblogs.com/cx2016/p/11385009.html
default boxes 核心点讲解 及 .cpp 代码见:https://www.cnblogs.com/sddai/p/10206929.html
小哥的后续论文:
PUBLICATIONS
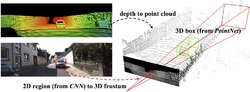 |
Frustum PointNets for 3D Object Detection from RGB-D Data [arXiv] [code] [KITTI benchmark] Charles R. Qi, Wei Liu, Chenxia Wu, Hao Su and Leonidas J. Guibas CVPR 2018 |
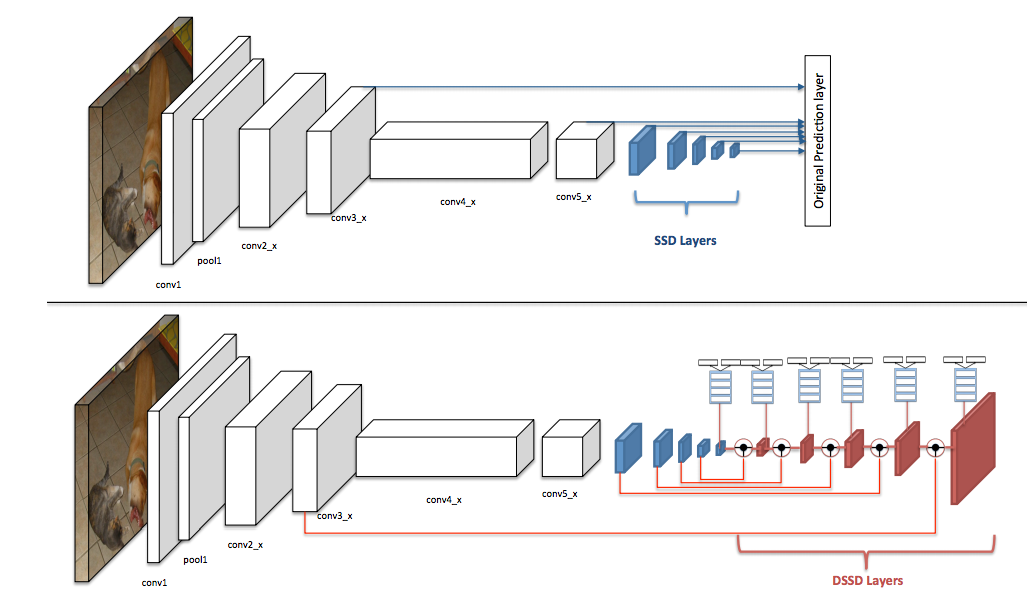 |
DSSD : Deconvolutional Single Shot Detector [arXiv] [demo] Cheng-Yang Fu*, Wei Liu*, Ananth Ranga, Ambrish Tyagi, and Alexander C. Berg arXiv preprint arXiv:1701.06659, *=Equal Contribution |
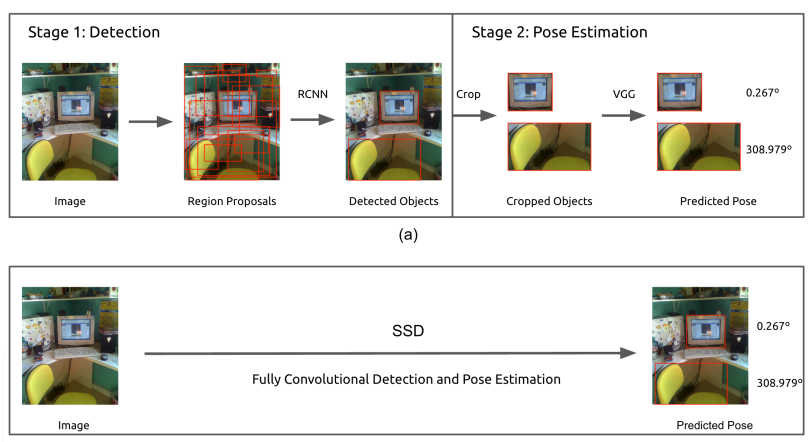 |
Fast Single Shot Detection and Pose Estimation [pdf] [arXiv] Patrick Poirson, Phil Ammirato, Cheng-Yang Fu, Wei Liu, Jana Kosecka, and Alexander C. Berg 3DV 2016. |
 |
SSD: Single Shot MultiBox Detector [pdf] [arXiv] [code] [video] [slides (pdf)] [slides (keynote)] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg ECCV 2016 Oral. |
研究领域:
I did a great internship at Google Mountain View in 2014 summer. Our team GoogLeNet won the classification and detection challenge in ILSVRC2014. My research speciality is computer vision. The main focus of my current research include:
- Abrige the semantic gap of image understanding with deep neural networks
- 用深度神经网络缩小图像理解的语义 gap
- Recognize and detect objects from large scale image and video dataset
- 从大规模图像和视频数据集中识别和检测物体
这篇把核心的contrib点讲清楚了
基于”Proposal + Classification”的Object Detection的方法,RCNN系列(R-CNN、SPPnet、Fast R-CNN以及Faster R-CNN)取得了非常好的效果,因为这一类方法先预先回归一次边框,然后再进行骨干网络训练,所以精度要高,这类方法被称为two stage的方法。但也正是由于此,这类方法在速度方面还有待改进。由此,YOLO[8]应运而生,YOLO系列只做了一次边框回归和打分,所以相比于RCNN系列被称为one stage的方法,这类方法的最大特点就是速度快。但是YOLO虽然能达到实时的效果,但是由于只做了一次边框回归并打分,这类方法导致了小目标训练非常不充分,对于小目标的检测效果非常的差。简而言之,YOLO系列对于目标的尺度比较敏感,而且对于尺度变化较大的物体泛化能力比较差。
针对YOLO和Faster R-CNN的各自不足与优势,WeiLiu等人提出了Single Shot MultiBox Detector,简称为SSD。SSD整个网络采取了one stage的思想,以此提高检测速度。并且网络中融入了Faster R-CNN中的anchors思想,并且做了特征分层提取并依次计算边框回归和分类操作,由此可以适应多种尺度目标的训练和检测任务。SSD的出现使得大家看到了实时高精度目标检测的可行性。
[目标检测]SSD:Single Shot MultiBox Detector
基于”Proposal + Classification”的Object Detection的方法,RCNN系列(R-CNN、SPPnet、Fast R-CNN以及Faster R-CNN)取得了非常好的效果,因为这一类方法先预先回归一次边框,然后再进行骨干网络训练,所以精度要高,这类方法被称为two stage的方法。但也正是由于此,这类方法在速度方面还有待改进。由此,YOLO[8]应运而生,YOLO系列只做了一次边框回归和打分,所以相比于RCNN系列被称为one stage的方法,这类方法的最大特点就是速度快。但是YOLO虽然能达到实时的效果,但是由于只做了一次边框回归并打分,这类方法导致了小目标训练非常不充分,对于小目标的检测效果非常的差。简而言之,YOLO系列对于目标的尺度比较敏感,而且对于尺度变化较大的物体泛化能力比较差。
针对YOLO和Faster R-CNN的各自不足与优势,WeiLiu等人提出了Single Shot MultiBox Detector,简称为SSD。SSD整个网络采取了one stage的思想,以此提高检测速度。并且网络中融入了Faster R-CNN中的anchors思想,并且做了特征分层提取并依次计算边框回归和分类操作,由此可以适应多种尺度目标的训练和检测任务。SSD的出现使得大家看到了实时高精度目标检测的可行性。
一、网络结构
SSD网络主体设计的思想是特征分层提取,并依次进行边框回归和分类。因为不同层次的特征图能代表不同层次的语义信息,低层次的特征图能代表低层语义信息(含有更多的细节),能提高语义分割质量,适合小尺度目标的学习。高层次的特征图能代表高层语义信息,能光滑分割结果,适合对大尺度的目标进行深入学习。所以作者提出的SSD的网络理论上能适合不同尺度的目标检测。
所以SSD网络中分为了6个stage,每个stage能学习到一个特征图,然后进行边框回归和分类。SSD网络以VGG16的前5层卷积网络作为第1个stage,然后将VGG16中的fc6和fc7两个全连接层转化为两个卷积层Conv6和Conv7作为网络的第2、第3个stage。接着在此基础上,SSD网络继续增加了Conv8、Conv9、Conv10和Conv11四层网络,用来提取更高层次的语义信息。如下图3.1所示就是SSD的网络结构。在每个stage操作中,网络包含了多个卷积层操作,每个卷积层操作基本上都是小卷积。
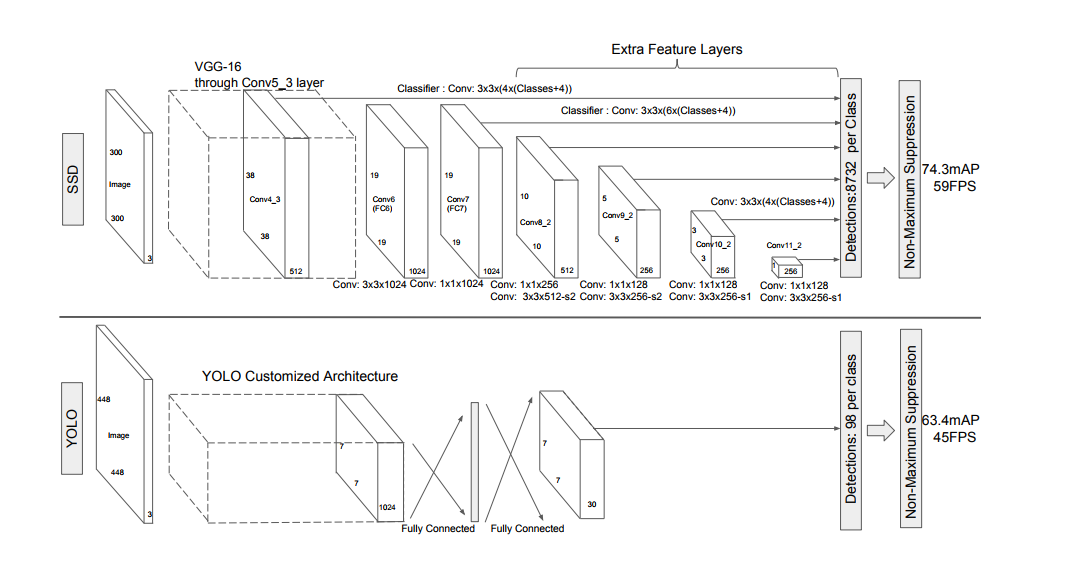
骨干网络:SSD前面的骨干网络选用的VGG16的基础网络结构,如上图所示,虚线框内的是VGG16的前5层网络。然后后面的Conv6和Conv7是将VGG16的后两层全连接层网络(fc6, fc7)转换而来。
另外:在此基础上,SSD网络继续增加了Conv8和Conv9、Conv10和Conv11四层网络。图中所示,立方体的长高表示特征图的大小,厚度表示是channel。
二、设计要点
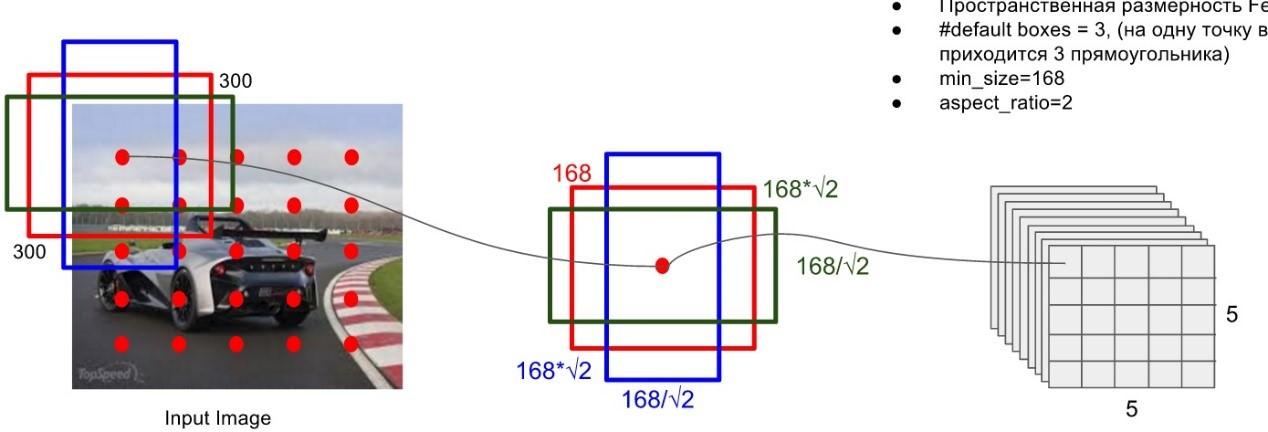
1. Default Boxes生成
在目标检测网络设计中,Default Boxes生成都是重中之重,也许直接决定了网络能针对的任务以及检测的性能。在SSD中,作者充分的吸取了Faster R-CNN中的Anchors机制,在每个Stage中根据Feature Map的大小,按照固定的Scale和Radio生成Default Boxes。这里为了方便阐述,选取了Conv9的Feature Map,输出大小为5x5。SSD网络中作者设置Conv9的每个点默认生成6个box,如下图所示。因此在这一层上,共生成了5x5x6=150个boxes。
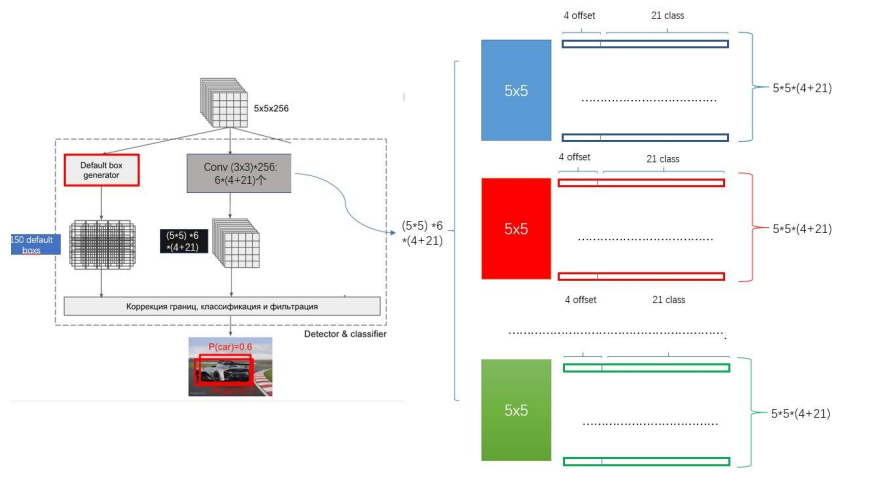
2. 特征向量生成
在每张特征图上得到许多Default Box后还需要生成相应的特征向量,用来进行边框回归和分类。对于边框回归,只需要4维向量即可,分别代表边框缩放尺度(坐标轴两个方向)和平移向量(坐标轴两个方向)。对于分类,SSD网络采取为每个类别进行打分的策略,也就是说对于每个Default Box,SSD网络会计算出相应的每个类别的分数。假设数据集类别数为c,加上背景,那么总的类别数就是c+1类。SSD网络采用了c+1维向量来分别代表该Default Box对于每个类别所得到的分数。这里,假设是VOC数据集,那么每个Default Box将生成一个20 + 1 + 4 = 25维的特征向量。同样,以Conv9输出特征图5x5为例。
3. 新增卷积网络
SSD网络在VGG基础上新增加了几个卷积网络(如网络结构中所述)。SSD网络总共增加了Conv8、Conv9、Conv10和Conv11四个卷积网络层。新增的这些网络都是通过一些小的卷积核操作。引用论文所说,这些小的卷积核操作是SSD网络性能优秀的核心。下面本报告将简单的阐述一下作者对于卷积网络的简单配置。
卷积核配置
- 假设Feature Map通道数为P,SSD网络中每个Stage的卷积核大小统一为33P。其中padding和stride都为1。保证卷积后的Feature Map和卷积前是一样大小。
卷积滤波器
- 每个Feature Map上mxn个大小的特征点对应K个Default Boxes,假设类别数+背景=c,最终通过卷积滤波器得到c+4维特征向量。那么一个Feature Map上的每个点就需要使用kx(c+4)个这样的滤波器。
4. 联合LOSS FUNCTION

三、训练策略
训练SSD和基于region proposal方法的最大区别就是:SSD需要精确的将ground truth映射到输出结果上。这样才能提高检测的准确率。文中主要采取了以下几个技巧来提高检测的准确度。
- 匹配策略
- Default boxes生成器
- Hard Negative Mining
- Data Augmentation
1. 匹配策略
这里的匹配是指的ground truth和Default box的匹配。这里采取的方法与 Faster R-CNN中的方法类似。主要是分为两步:第一步是根据最大的overlap将ground truth和default box进行匹配(根据ground truth找到default box中IOU最大的作为正样本),第二步是将default boxes与overlap大于某个阈值(目标检测中通常选取0.5,Faster R-CNN中选取的是0.7)的ground truth进行匹配。
2. Default Boxes生成器


3. Hard Negative Mining
经过匹配策略会得到大量的负样本,只有少量的正样本。这样导致了正负样本不平衡,经过试验表明,正负样本的不均衡是导致检测正确率低下的一个重要原因。所以在训练过程中采用了Hard Negative Mining的策略,根据Confidence Loss对所有的box进行排序,使得正负样本的比例控制在1:3之内,经过作者实验,这样做能提高4%左右的准确度。
4. Data Augmentation
为了模型更加鲁棒,需要使用不同尺度目标的输入,作者对数据进行了增强处理。
- 使用整张图像作为输入
- 使用IOU和目标物体为0.1、0.3、0.5、0.7和0.9的patch,这些patch在原图的大小的[0.1, 1]之间,相应的宽高比在[1/2, 2]之间。
- 随机采取一个patch
四、实验结果
1. PASCAL VOC 2007
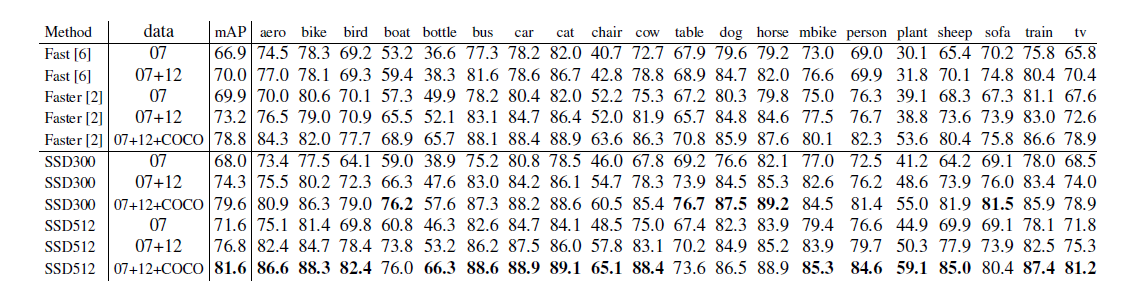
2. 模型分析


3. PASCAL VOC 2012

五、参考文献
[1]He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//European Conference on Computer Vision. Springer, Cham, 2014: 346-361.
[2]Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788.
[3] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[4] https://zhuanlan.zhihu.com/p/24954433
[5] github源码地址
数据增广:
目标检测:SSD的数据增强算法
代码地址
https://github.com/weiliu89/caffe/tree/ssd
论文地址
https://arxiv.org/abs/1512.02325
数据增强:
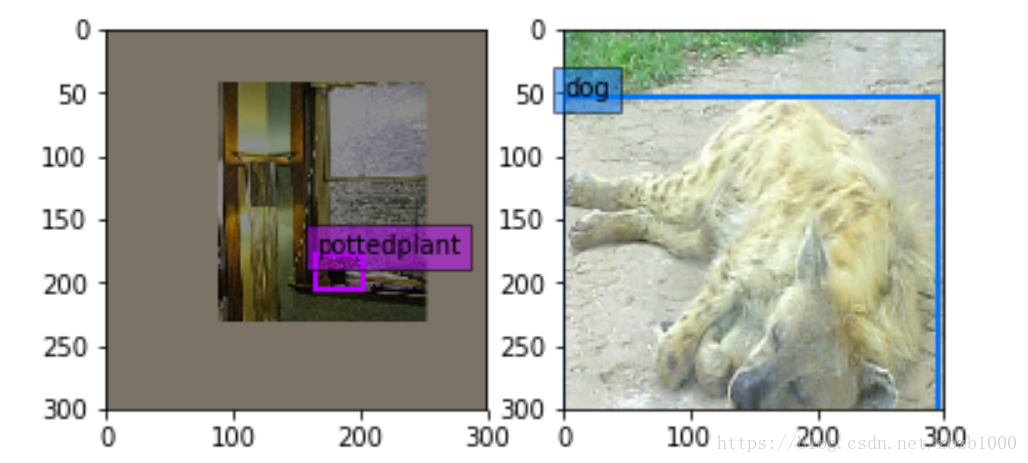
SSD数据增强有两种新方法:(1)expand ,左图(2)batch_sampler,右图
expand_param {
prob: 0.5 //expand发生的概率
max_expand_ratio: 4 //expand的扩大倍数
}
- 1
- 2
- 3
- 4
expand是指对图像进行缩小,图像的其余区域补0,下图是expand的方法。个人认为这样做的目的是在数据处理阶段增加多尺度的信息。大object通过expand方法的处理可以变成小尺度的物体训练。提高ssd对尺度的泛化性。
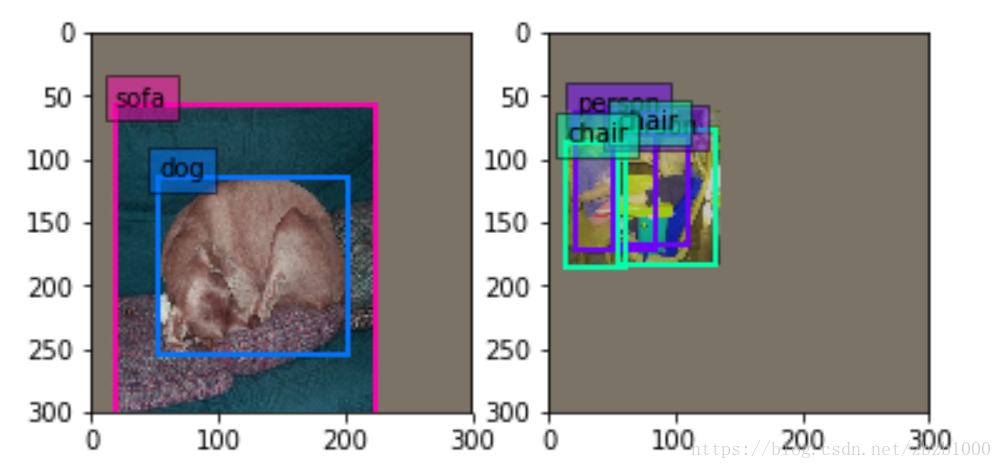
annotated_data_param {//以下有7个batch_sampler
batch_sampler {
max_sample: 1
max_trials: 1
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.1
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.3
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.5
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.7
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
max_jaccard_overlap: 1
}
max_sample: 1
max_trials: 50
}
batch_sampler是对图像选取一个满足限制条件的区域(注意这个区域是随机抓取的)。限制条件就是抓取的patch和GT(Ground Truth)的IOU的值。
步骤是:先在区间[min_scale,max_sacle]内随机生成一个值,这个值作为patch的高Height,然后在[min_aspect_ratio,max_aspect_ratio]范围内生成ratio,从而得到patch的Width。到此为止patch的宽和高随机得到,然后在图像中进行一次patch,要求满足与GT的最小IOU是0.9,也就是IOU>=0.9。如果随机patch满足这个条件,那么张图会被resize到300300(**在SSD300300中**)送进网络训练。如下图。
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
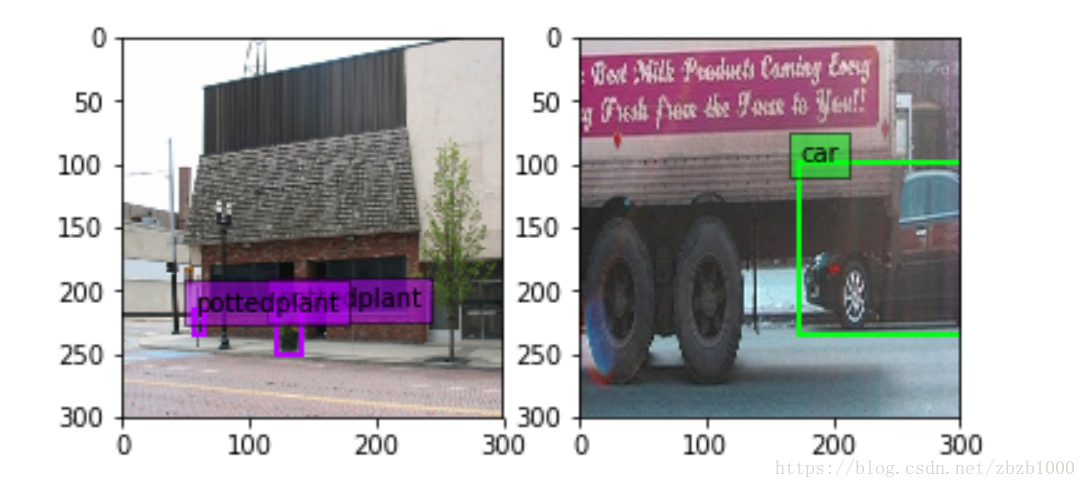
SSD数据增广中的图像变换与裁剪
SSD在数据增广部分做了很多工作,处理方法集中在load_batch函数中,首先是对每一帧图像,即每个datum做DistortImage处理,DistortImage包括亮度、饱和度,色调,颜色灰度扭曲等变换,再进行ExpandImage处理
>>>:现在的方法基本上就是靠大量训练数据(&negative sampling >>> 题外话:负采样效果好,有没有理论上的一些分析,比如稀疏、低维流形啥的),然后“分类” ;
而人类识别感觉是提取到了这类物体的 backbone/sketch,后续再加上各种颜色上的交换等,是顺理成章的 —— 是否能搞一种 attention 机制;或者是 orthogonal 叠加的机制( 形状骨架 + 换肤主题,然后再叠加)
另外总觉得 2-D 目标检测是伪命题——能否将calibration、透视变换、parts 组合成 object ... 这些结构性的机制引入进来?
seems like a fertile field
可能标注数据集也需要修正;
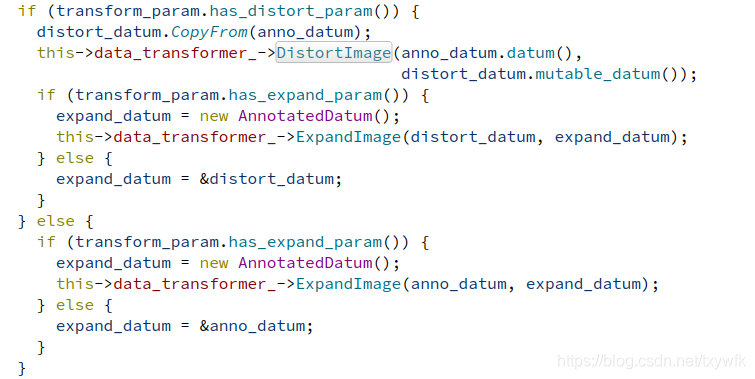
在DistortImage函数中,首先用OpenCV的 cv_img = DecodeDatumToCVMat(datum, param_.force_color())函数将图像从Datum数据中解码出来,数据的变形是针对图片来做的,在ApplyDistort(const cv::Mat& in_img, const DistortionParameter& param)函数中,输入一个Mat格式的图片,输出一个经过DistortionParameter参数所变换后的图像,其中包括随机亮度失真变换,随机对比度失真变换,做随机饱和度失真变换,随机色调失真变换和随机图像通道变换,这里是一种排列组合的方法,变换的顺序不同,得到的图片结果也不同,根据随机数是否大于0.5来确定对比度和色调失真变换的顺序。代码如下:

返回变换后的图片,再将其编码成Datum的格式,编码函数EncodeCVMatToDatum(const cv::Mat& cv_img, const string& encoding, Datum* datum),其中用到了一个opencv图像编码的接口cv::imencode("."+encoding, cv_img, buf);再把数据写入datum中。代码如下:

接着是ExpandImage(distort_datum, expand_datum)的操作,这个操作是按照百分之五十的概率发生的。ExpandImage可以理解为裁剪操作,在SSD中作者也提到裁剪相当与zoom in放大效果,可以使网络对尺度更加不敏感,因此可以识别小的物体。通过将原图缩小放到一个画布上再去裁剪达到缩小的效果。在原文中的Fig.6提到了在数据增强之后SSD网络确实对小物体识别能力有很大提升。裁剪后的图像至少一个 groundtruth box 的中心(centroid) 位于该图像块中.这样就可以避免不包含明显的前景目标的图像块不用于网络训练(只有包含明显的前景目标的图像块采用于网络训练.)同时,保证只有部分前景目标可见的图片用于网络训练.例如,下面图像中,Groundtruth box 表示为红色,裁剪的图像块表示为绿色. 由于是随机裁剪(概率百分之五十),因此有些图像是包含扩展的画布,有些则不包含.


在代码中实现ExpandImage的方法是,先按(1:max_expand_ratio)随机产生一个比例系数expand_ratio,创造一个expand_ratio*原图大小的0填充图,再按照代码里的方式确定一个顶点,用于将原图粘贴到所创造的“画布”中,并且确定好需要这张图需要裁剪的区域expand_bbox(这个区域我不太懂),然后用平均值进行画布填充,得到一张较大的图,用于后期的裁剪,这样做的原因,上文提到了(参考别人说的)

接着就是把填充的图片编码成expand_datum,然后进入TransformAnnotation函数,在上面的ExpandImage中,不存在任何对原数据中的AnnotationGroup的处理,即这里所生成的expand_datum仅仅是图片的裁剪的datum格式,expand_datum中的Annotation并没有做任何赋值或者更新,这一部分工作在TransformAnnotation函数中进行,主要是将原图的AnnotationGroup中的NormalizedBBox,通过映射变换后,复制到expand_datum的annotation中,注意这里所取的原图NormalizedBBox有条件,得满足这个框的中心点在裁剪图之中,其他在裁剪框之外的NormalizedBBox就直接舍弃。代码如下:

这里就解读到ExpandImage函数,下一篇将解读Samples这块儿的操作。
SSD(Single Shot MultiBox Detector)笔记
为什么要学习SSD,是因为SSD和YOLO一样,都是
one-stage的经典构架,我们必须对其理解非常深刻才能举一反三设计出更加优秀的框架。SSD这个目标检测网络全称为Single Shot MultiBox Detector,重点在MultBox上,这个思想很好地利用了多尺度的优势,全面提升了检测精度,之后的YOLOv2就借鉴了SSD这方面的思路才慢慢发展起来。

前言
本文用于记录学习SSD目标检测的过程,并且总结一些精华知识点。
为什么要学习SSD,是因为SSD和YOLO一样,都是one-stage的经典构架,我们必须对其理解非常深刻才能举一反三设计出更加优秀的框架。SSD这个目标检测网络全称为Single Shot MultiBox Detector,重点在MultBox上,这个思想很好地利用了多尺度的优势,全面提升了检测精度,之后的YOLOv2就借鉴了SSD这方面的思路才慢慢发展起来。
强烈建议阅读官方的论文去好好理解一下SSD的原理以及设计思路。这里也提供了相关的pdf:http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf
当然也有很多好的博客对其进行了介绍,在本文的最下方会有相关链接。本篇文章主要为自己的笔记,其中加了一些自己的思考。
网络构架
SSD的原始网络构架建议还是以论文为准,毕竟平时我们接触到的都是各种魔改版(也就是所谓的换了backbone,例如最常见的SSD-mobilenetv2),虽然与原版大同小异,不过对于理解来说,会增大我们理解的难度,因此,完全有必要看一遍原始的论文描述。
SSD在论文中是采取的VGG网络作为主干结构,但是去除了VGG中的最后几层(也就是我们经常说的分类层),随后添加了一些新的内容(在原文中叫做auxiliary structure),这些层分别是:
- 额外的特征提取层(Extra Feature Layers),作用就是和原本
backbone的层相结合共同提取出不同尺寸的特征信息,相当于加强了之前的backbone,使其网络更深,提取能力更加强大。 - 分类层(classification headers),对之前网络中的不同位置网络层输出的特征层(不同尺度),进行卷积得出每个特征图中每个坐标对应的分类信息(每个坐标对应着许多default boxes)。
- 坐标位置回归层(regression hearders),结构与分类层相仿,只是输出的通道略有不同,通过对不同尺度的特征图进行卷积,输出的是每个特征图中每个坐标对应的default boxes的偏移坐标(文章中称为shape offset)。

总体来说,SSD网络结构其实有四部分组成,backbone部分、额外添加的特征提取层、分类层以及坐标位置回归层。注意当初这篇SSD是出于Yolo一代之后二代之前,Yolo二代三代中不同尺度的特征图思想是有借鉴于SSD的。
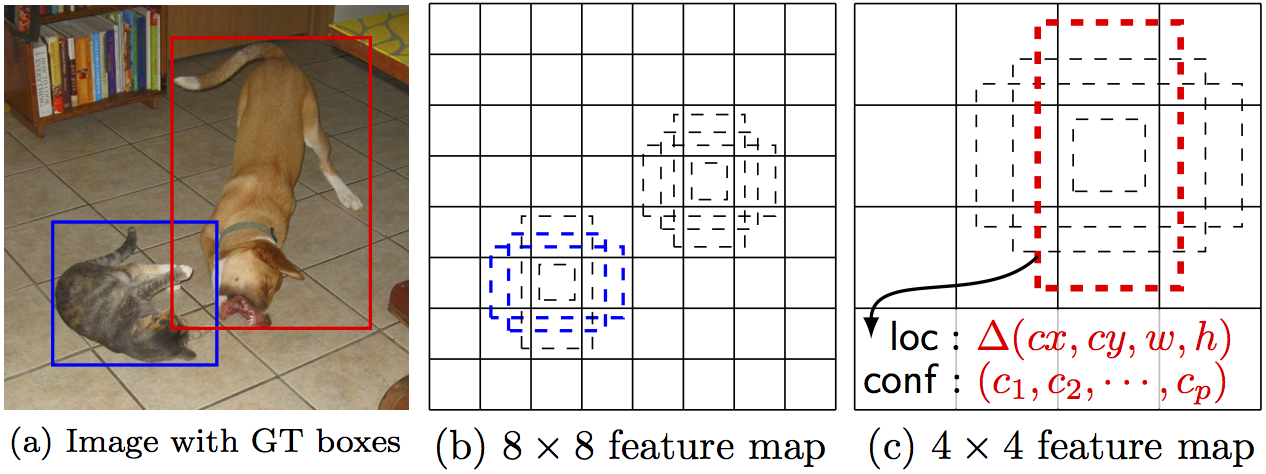
用于检测的多尺度特征图
多尺度特征图具体表示就是SSD在整个网络的不同位置,取出相应的特征层进行预测,每个特征层因为尺度不一样可以检测的视野以及目标物体的大小也不同。每个特征图可以预测出分类信息和位置信息,如下图中可以看到整个网络使用从前到后使用了6个不同的特征图,从38x38x512到1x1x256一共六个不同尺度的特征图。
也就是使用低层feature map检测小目标,使用高层feature map检测大目标,是SSD的突出贡献。

那么default box是如何产生?
default box
论文中的原话是这样的:
We associate a set of default bounding boxes with each feature map cell, for multiple feature maps at the top of the network. The default boxes tile the feature map in a convolutional manner, so that the position of each box relative to its corresponding cell is fixed. At each feature map cell, we predict the offsets relative to the default box shapes in the cell, as well as the per-class scores that indicate the presence of a class instance in each of those boxes.
就是对于上述每一个不同尺度的特征图(38x38、19x19、10x10、5x5、3x3、1x1),每一个特征图中的坐标中(cell)产生多个default box。对于每个default box,SSD预测出与真实标定框的偏移(offsets,一共是4个数值,代表位置信息)以及对应于每个类的概率confidence(c1,c2,...,cpc1,c2,...,cp)。如果一共有c类,每一个坐标产生k个box,那么我们在进行训练的时候,每个cell就会产生(c+4)k个数据,如果特征图大小为mxn,那么总共就是(c+4)kmn,例如3x3的特征图,mxn就是3x3。
注意下,上述的那个offset不仅是相对于default box,换个角度来说,也是相对于真实标定框的偏移,通俗了说就是default box加上offsets就是真实标定框的位置。这个offsets是我们在训练学习过程中可以计算出来用于损失函数来进行优化的。
在实际预测中,我们要预测出每个default box的category以及对应的offset。

这部分我看到更好的介绍,所以这里不进行赘述,可以直接看这里:解读SSD中的Default box(Prior Box)。
训练过程
不光要从论文中理解一个网络的细节部分,还需要详细了解一下训练的具体过程:
因为我们要在特征图上生成default box,那么在训练阶段我们就需要将GT(Ground Truth)与default box相对应才能进行训练,怎么个对应法,SSD中使用了一个IOU阈值来控制实际参与计算的default box的数量,这一步骤发生在数据准备中:

首先要保证每个GT与和它度量距离最近的(就是iou最大)default box对应,这个很重要,可以保证我们训练的正确性。另外,因为我们有很多狠多的default box,所以不只是iou最大的default box要保留,iou满足一定阈值大小的也要保留下来。
也就是说,训练的过程中就是要判断哪个default boxes和具体每一张图中的真实标定框对应,但实际中我们在每个特征图的每个cell中已经产生了很多default boxes,SSD是将所有和真实标定框的IOU(也就是jaccard overlap)大于一定阈值(论文中设定为0.5)的default boxes都保留下来,而不是只保留那个最大IOU值的default box(为什么要这么做,原论文中说这样有利于神经网络的学习,也就是学习难度会降低一些)。
这样我们就在之前生成的default boxes中,精挑细选出用于训练的default boxes(为了方便,实际训练中default boxes的数量是不变的,只不过我们直接将那些iou低于一定阈值的default boxes的label直接置为0也就是背景)。
损失函数
损失函数也是很简单,一共有俩,分别是位置损失以及分类损失:
L(x,c,l,g)=1N(Lconf(x,c)+αLloc(x,l,g))L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
其中NN为matched default boxes的数量,这个NN就是训练过程一开始中精挑细选出来的default boxes。当NN为0的时候,此时总体的损失值也为0。而αα是通过交叉验证最终得到的权重系数,论文中的值为1。
位置损失
其中xijp={1,0}xijp={1,0}表示当前defalut box是否与真实的标定框匹配(第ii个defalut box与第jj个真实的标定框,其中类别是pp),经过前面的match步骤后,有∑ixijp∑ixijp大于等于1。
Lloc(x,l,g)=∑i∈P os m∈{cx,cy,w,h}N∑(cx,cy,w,h}xijksmoothL1(lim−g^jm)Lloc(x,l,g)=i∈P os m∈{cx,cy,w,h}∑N(cx,cy,w,h}∑xijksmoothL1(lim−g^jm)
注意,上式中的g^jmg^jm是进行变化后的GroundTruth,变化过程与default box有关,也就是我们训练过程中使用的GroundTruth值是首先通过default box做转换,转化后的值,分别为g^jcx,g^jcy,g^jw,g^jhg^jcx,g^jcy,g^jw,g^jh,这四个值,分别是真实的标定框对应default box的中心坐标x,yx,y以及宽度ww和高度hh的偏移量。
也就是下面四个转换关系,稍微花一点心思就可以看明白,在训练的时候实际带入损失函数的就是下面这四个转化后的值:
g^jcx=(gjcx−dicx)/diwg^jcy=(gjcy−dicy)/dihg^jcx=(gjcx−dicx)/diwg^jcy=(gjcy−dicy)/dih
g^jw=log(gjwdiw)g^jh=log(gjhdih)g^jw=log(diwgjw)g^jh=log(dihgjh)
同理,既然我们在训练过程中学习到的是default box -> GroundTruth Box的偏移量,那么我们在推测的时候自然也要有一个相反的公式给计算回来,将上面的四个公式反转一下即可。
分类损失
分类损失使用交叉熵损失,
Lconf(x,c)=−∑i∈PosNxijplog(c^ip)−∑i∈Neglog(c^i0) where c^ip=exp(cip)∑pexp(cip)Lconf(x,c)=−i∈Pos∑Nxijplog(c^ip)−i∈Neg∑log(c^i0) where c^ip=∑pexp(cip)