论文总结 - 模型剪枝 Model Pruning
模型剪枝是常用的模型压缩方法之一。这篇是最近看的模型剪枝相关论文的总结。
Deep Compression, Han Song
抛去LeCun等人在90年代初的几篇论文,HanSong是这个领域的先行者。发表了一系列关于模型压缩的论文。其中NIPS 2015上的这篇Learning both weights and connections for efficient neural network着重讨论了对模型进行剪枝的方法。这篇论文之前我已经写过了阅读总结,比较详细。
概括来说,作者提出的主要观点包括,L1 norm作为neuron是否重要的metric,train -> pruning -> retrain三阶段方法以及iteratively pruning。需要注意的是,作者的方法只能得到非结构化的稀疏,对于作者的专用硬件EIE可能会很有帮助。但是如果想要在通用GPU或CPU上用这种方法做加速,是不太现实的。
SSL,WenWei
既然非结构化稀疏对现有的通用GPU/CPU不友好,那么可以考虑构造结构化的稀疏。将Conv中的某个filter或filter的某个方形区域甚至是某个layer直接去掉,应该是可以获得加速效果的。WenWei论文Learning Structured Sparsity in Deep Neural Networks发表在NIPS 2016上,介绍了如何使用LASSO,给损失函数加入相应的惩罚,进行结构化稀疏。这篇论文之前也已经写过博客,可以参考博客文章。
概括来说,作者引入LASSO正则惩罚项,通过不同的具体形式,构造了对不同结构化稀疏的损失函数。
L1-norm Filter Pruning,Li Hao
在通用GPU/CPU上,加速效果最好的还是整个Filter直接去掉。作者发表在ICLR 2017上的论文Pruning Filters for Efficient ConvNets提出了一种简单的对卷积层的filter进行剪枝的方法。
这篇论文真的很简单。。。主要观点就是通过Filter的L1 norm来判断这个filter是否重要。人为设定剪枝比例后,将该层不重要的那些filter直接去掉,并进行fine tune。在确定剪枝比例的时候,假定每个layer都是互相独立的,分别对其在不同剪枝比例下进行剪枝,并评估模型在验证集上的表现,做sensitivity分析,然后确定合理的剪枝比例。在实现的时候要注意,第ii个layer中的第jj个filter被去除,会导致其输出的feature map中的第jj个channel缺失,所以要相应调整后续的BN层和Conv层的对应channel上的参数。
另外,实现起来还有一些细节,这些可以参见原始论文。提一点,在对ResNet这种有旁路结构的网络进行剪枝时,每个block中的最后一个conv不太好处理。因为它的输出要与旁路做加和运算。如果channel数量不匹配,是没法做的。作者在这里的处理方法是,听identity那一路的。如果那一路确定了剪枝后剩余的index是多少,那么F(x)F(x)那一路的最后那个conv也这样剪枝。
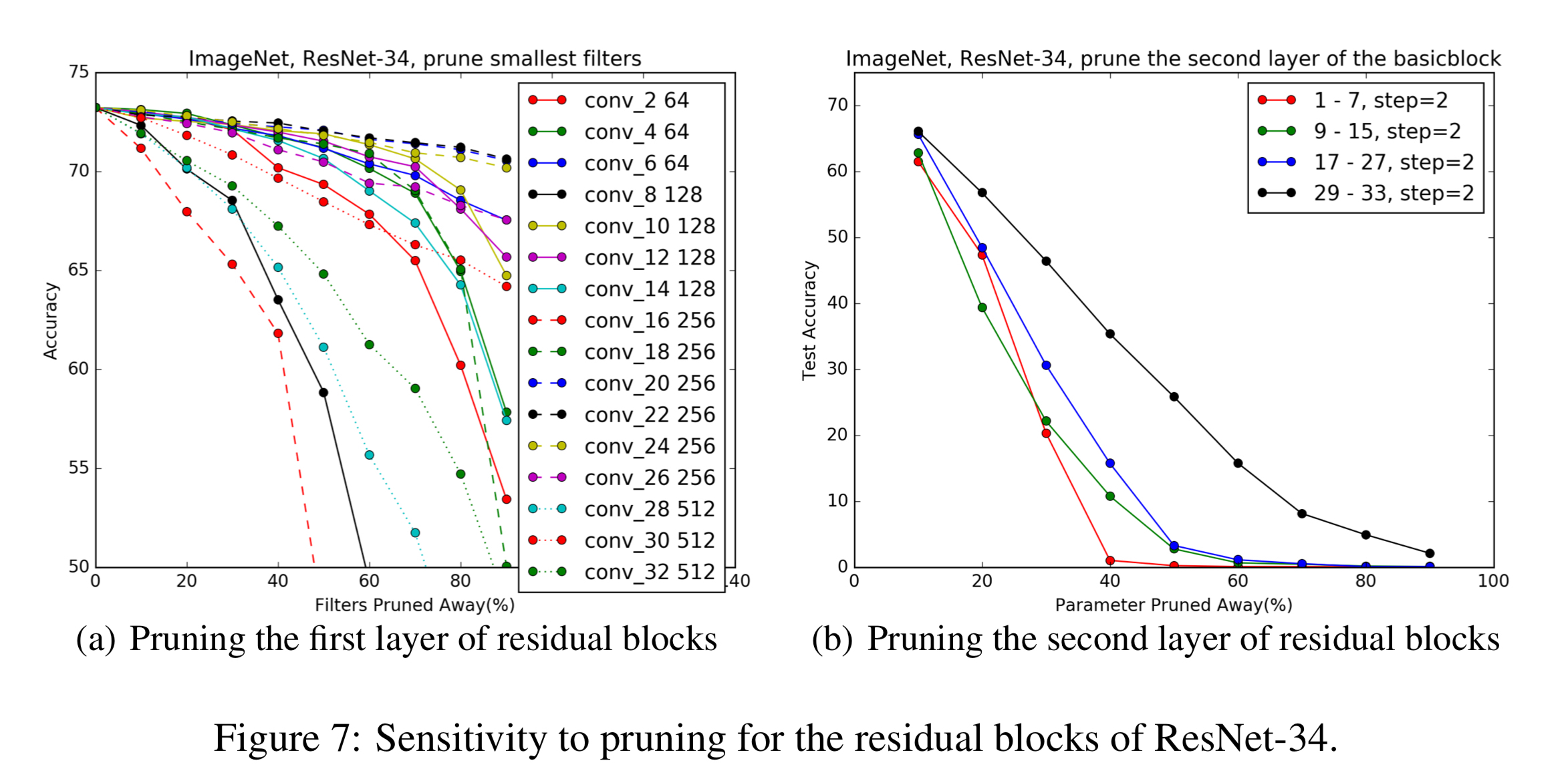
这里给出一张在ImageNet上做sensitivity analysis的图表。需要对每个待剪枝的layer进行类似的分析。
Automated Gradual Pruning, Gupta
这篇文章发表在NIPS 2017的一个关于移动设备的workshop上,名字很有意思(这些人起名字为什么都这么熟练啊):To prune, or not to prune: exploring the efficacy of pruning for model compression。TensorFlow的repo中已经有了对应的实现(亲儿子。。):Model pruning: Training tensorflow models to have masked connections。哈姆雷特不能回答的问题,作者的答案则是Yes。
这篇文章主要有两个贡献。一是比较了large模型经过prune之后得到的large-sparse模型和相似memory footprint但是compact-small模型的性能,得出结论:对于很多网络结构(CNN,stacked LSTM, seq-to-seq LSTM)等,都是前者更好(为什么??)。具体的数据参考论文。
二是提出了一个渐进的自动调节的pruning策略。首先,作者也着眼于非结构化稀疏。同时和上面几篇文章一样,作者也使用绝对值大小作为衡量importance的标准,作者提出,sparsity可以按照下式自动调节:
其中,sisi是初始剪枝比例,一般为00。sfsf为最终的剪枝比例,开始剪枝的迭代次数为t0t0,剪枝间隔为ΔtΔt,共进行nn次。
Net Sliming, Liu Zhuang & Huang Gao
这篇文章Learning Efficient Convolutional Networks through Network Slimming发表在ICCV 2017,利用CNN网络中的必备组件——BN层中的gamma参数,实现端到端地学习剪枝参数,决定某个layer中该去除掉哪些channel。作者中有DenseNet的作者——姚班学生刘壮和康奈尔大学博士后黄高。代码已经开源:liuzhuang13/slimming。
作者的主要贡献是提出可以使用BN层的gamma参数,标志其前面的conv输出的feature map的某个channel是否重要,相应地,也是conv参数中的那个filter是否重要。
首先,需要给BN的gamma参数加上L1 正则惩罚训练模型,新的损失函数变为L=∑(x,y)l(f(x,W),y)+λ∑γ∈Γg(γ)L=∑(x,y)l(f(x,W),y)+λ∑γ∈Γg(γ)。
接着将该网络中的所有gamma进行排序,根据人为给出的剪枝比例,去掉那些gamma很小的channel,也就是对应的filter。最后进行finetune。这个过程可以反复多次,得到更好的效果。如下所示: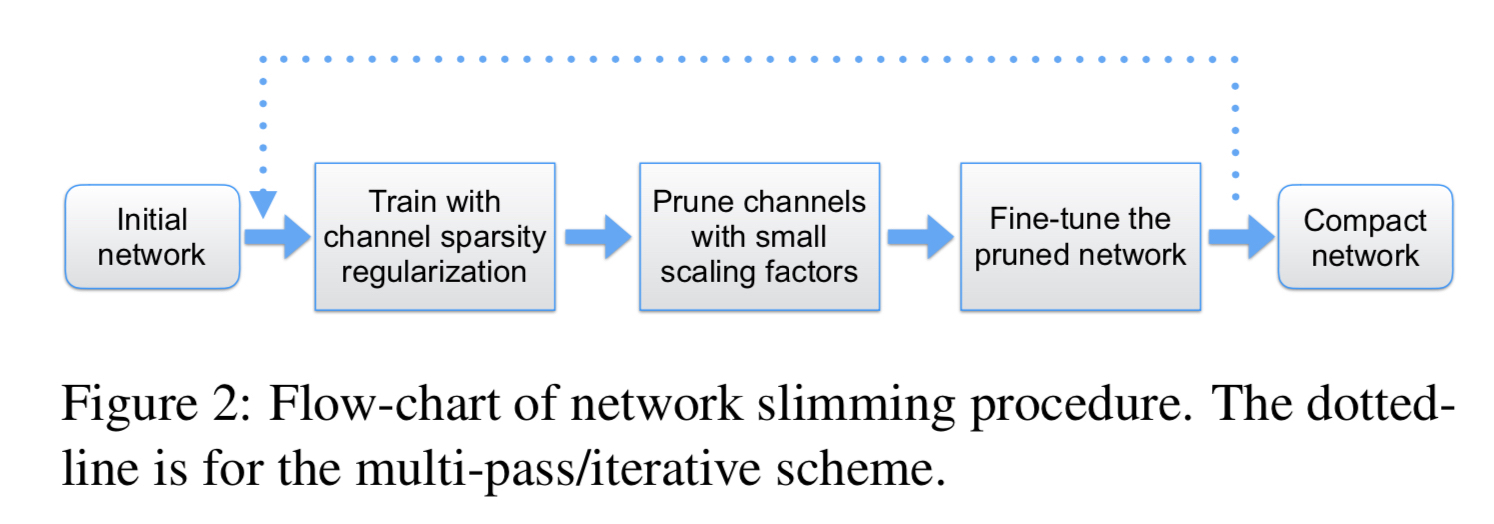
还是上面遇到过的问题,如果处理ResNet或者DenseNet Feature map会多路输出的问题。这里作者提出使用一个”channel selection layer”,统一对该feature map的输出进行处理,只选择没有被mask掉的那些channel输出。具体实现可以参见开源代码channel selection layer:
略微解释一下:在开始加入L1正则,惩罚gamma的时候,相当于identity变换;当确定剪枝参数后,相应index会被置为00,被mask掉,这样输出就没有这个channel了。后面的几路都可以用这个共同的输出。
AutoPruner, Wu Jianxin
这篇文章AutoPruner: An End-to-End Trainable Filter Pruning Method for Efficient Deep Model Inference是南大Wu Jianxin组新进发的文章,还没有投稿到任何学术会议或期刊,只是挂在了Arvix上,应该是还不够完善。他们还有一篇文章ThiNet:ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression发表在ICCV 2017上。
这篇文章的主要贡献是提出了一种端到端的模型剪枝方法,如下图所示。为第ii个Conv输出加上一个旁路,输入为其输出的Feature map,依次经过Batch-wise Pooling -> FC -> scaled sigmoid的变换,按channel输出取值在[0,1][0,1]范围的向量作为mask,与Feature map做积,mask掉相应的channel。通过学习FC的参数,就可以得到适当的mask,判断该剪掉第ii个Conv的哪个filter。其中,scaled sigmoid变换是指y=σ(αx)y=σ(αx)。通过训练过程中不断调大αα,就可以控制sigmoid的“硬度”,最终实现0−10−1门的效果。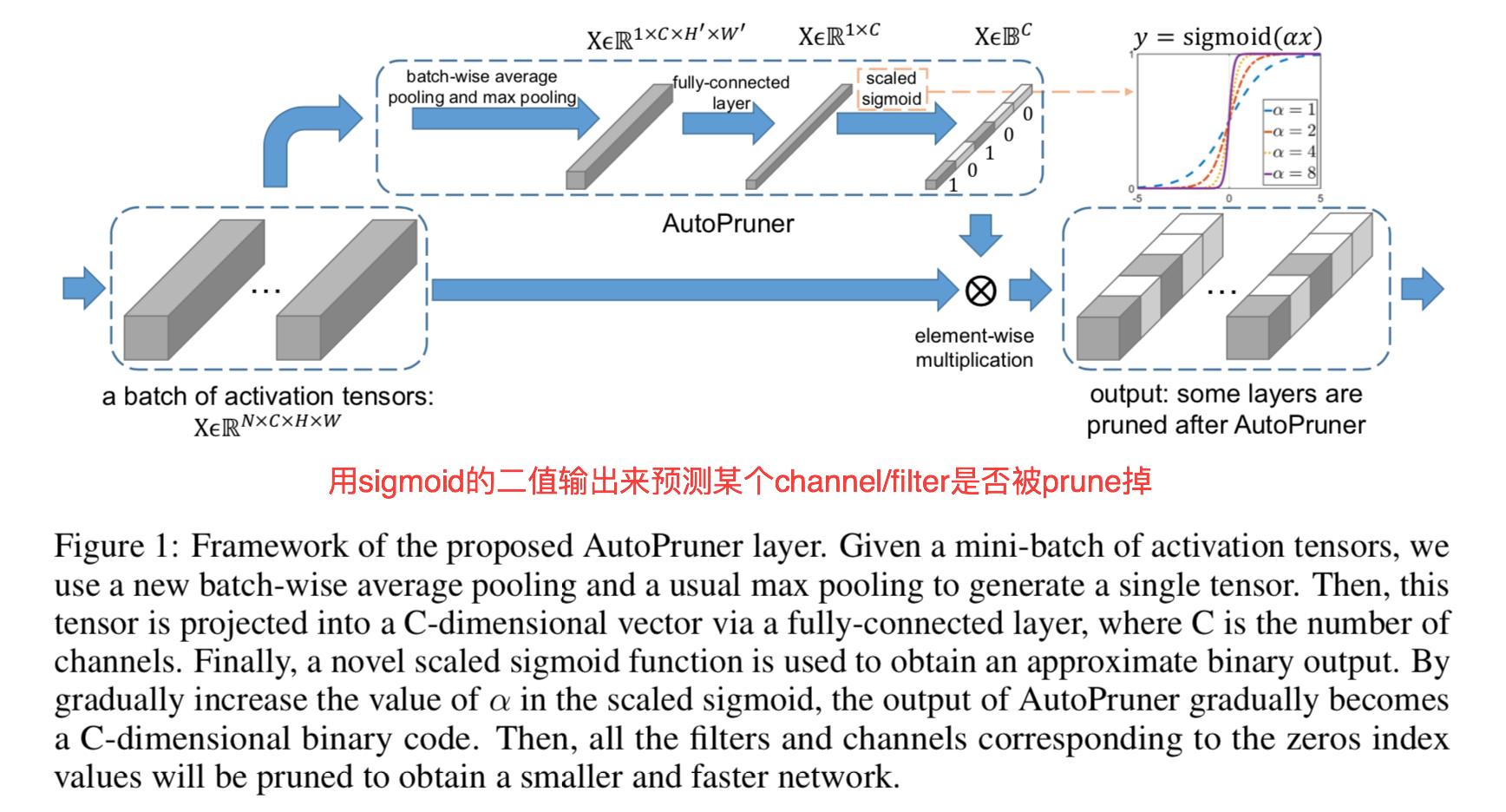
构造损失函数L=Lcross-entropy+λ∥∥v∥1C−r∥22L=Lcross-entropy+λ‖‖v‖1C−r‖22。其中,vv是sigmoid输出的mask,CC为输出的channel数量,rr为目标稀疏度。
不过在具体的细节上,作者表示要注意的东西很多。主要是FC层的初始化和几个超参数的处理。作者在论文中提出了相应想法:
- FC层初始化权重为00均值,方差为102n−−√102n的高斯分布,其中n=C×H×Wn=C×H×W。
- 上述αα的控制,如何增长αα。作者设计了一套if-else的规则。
- 上述损失函数中的比例λλ,作者使用了λ=100|rb−r|λ=100|rb−r|的自适应调节方法。

Rethinking Net Pruning, 匿名
这篇文章Rethinking the Value of Network Pruning有意思了。严格说来,它还在ICLR 2019的匿名评审阶段,并没有被接收。不过这篇文章的炮口已经瞄准了之前提出的好几个model pruning方法,对它们的结果提出了质疑。上面的链接中,也有被diss的方法之一的作者He Yihui和本文作者的交流。
之前的剪枝算法大多考虑两个问题:
- 怎么求得一个高效的剪枝模型结构,如何确定剪枝方式和剪枝比例:在哪里剪,剪多少
- 剪枝模型的参数求取:如何保留原始模型中重要的weight,对进行补偿,使得accuracy等性能指标回复到原始模型
而本文的作者check了六种SOA的工作,发现:在剪枝算法得到的模型上进行finetune,只比相同结构,但是使用random初始化权重的网络performance好了一点点,甚至有的时候还不如。作者的结论是:
- 训练一个over parameter的model对最终得到一个efficient的小模型不是必要的
- 为了得到剪枝后的小模型,求取大模型中的important参数其实并不打紧
- 剪枝得到的结构,相比求得的weight,更重要。所以不如将剪枝算法看做是网络结构搜索的一种特例。
作者立了两个论点来打:
- 要先训练一个over-parameter的大模型,然后在其基础上剪枝。因为大模型有更强大的表达能力。
- 剪枝之后的网络结构和权重都很重要,是剪枝模型finetune的基础。
作者试图通过实验证明,很多剪枝方法并没有他们声称的那么有效,很多时候,无需剪枝之后的权重,而是直接随机初始化并训练,就能达到这些论文中的剪枝方法的效果。当然,这些论文并不是一无是处。作者提出,是剪枝之后的结构更重要。这些剪枝方法可以看做是网络结构的搜索。
论文的其他部分就是对几种现有方法的实验和diss。我还没有细看,如果后续这篇论文得到了接收,再做总结吧~夹带一些私货,基于几篇论文的实现经验和在真实数据集上的测试,这篇文章的看法我是同意的。
更新:这篇文章的作者原来正是Net Sliming的作者Liu Zhuang和Huang Gao,那实验和结论应该是很有保障的。最近这篇文章确实也引起了大家的注意,值得好好看一看。
其他论文等资源
- Distiller:一个使用PyTorch实现的剪枝工具包