本篇博客介绍最经典的手写数字识别Mnist在tf上的应用。
Mnist有两种模型,一种是将其数据集看作是没有关系的像素值点,用softmax回归来做。另一种就是利用卷积神经网络,考虑局部图片像素的相关性,显然第二种方法明显优于第一种方法,下面主要介绍这两种方法。
- softmax回归
mnist.py
import tensorflow as tf import input_data #read the mnist data mnist = input_data.read_data_sets("mnist/", one_hot=True) #create the softmax model x = tf.placeholder("float", [None, 784]) W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x,W) + b) #the ground truth y_ = tf.placeholder("float", [None,10]) #calculate the cross_entropy cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #define the model loss in order to minimize the cross_entropy by a learning rate of 0.01 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) #initialize all variables init = tf.global_variables_initializer() #start Session sess = tf.Session() #run the Session sess.run(init) #every batch feed the parameter of placeholder and train the model for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) #calculate the classification model mAP in test set correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
input_data.py文件
# This is input_data.py
# Copyright 2015 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== """Functions for downloading and reading MNIST data.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function # pylint: disable=unused-import import gzip import os import tempfile import numpy from six.moves import urllib from six.moves import xrange # pylint: disable=redefined-builtin import tensorflow as tf from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets # pylint: enable=unused-import
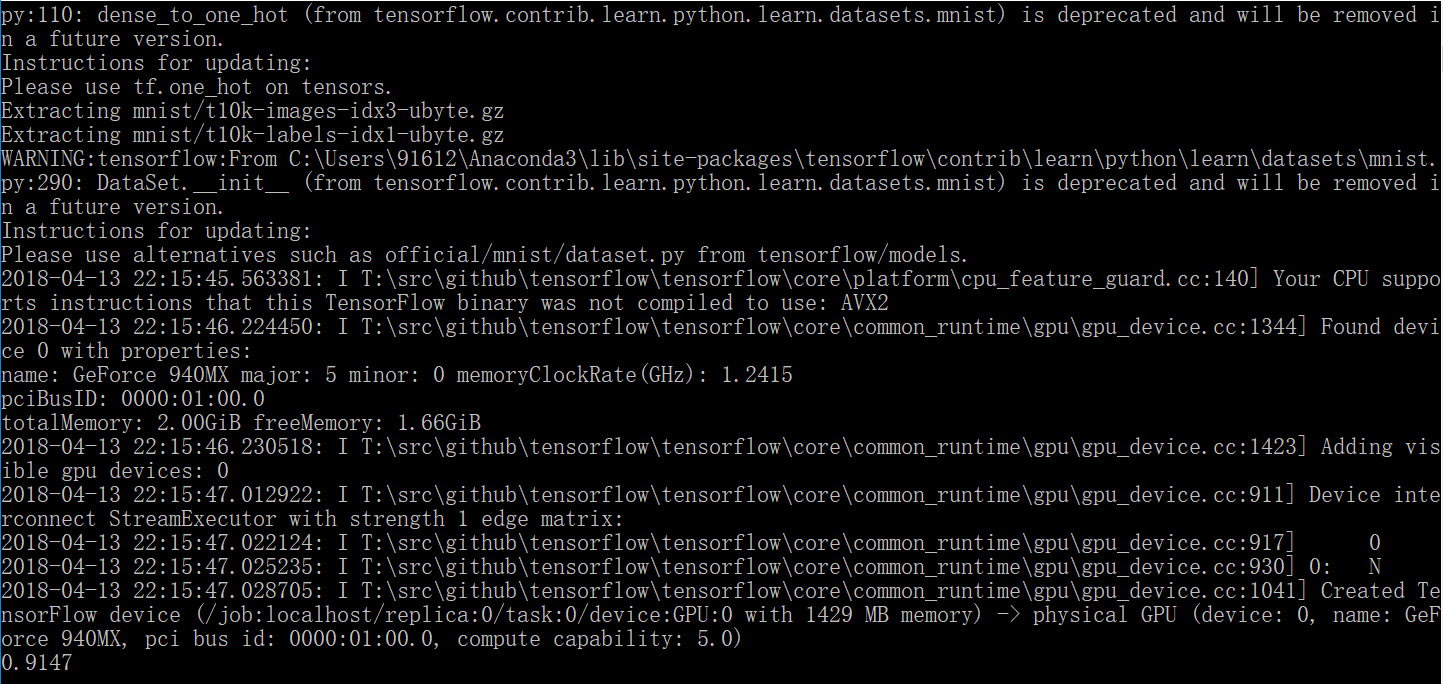
本次测试的精度是:91.47%
- 卷积神经网络
虽然上面我们得到了91%左右的精度,然而我们并没有满足,因为对于这一个经典的简单问题来说,如果只是百分之91,只能说明技术仍然落后,泡沫异常严重,然而事实情况是我们可以实现99.99%的精度,当然多来几个9,也是可以的,这很大程度上归功于深度学习技术的发展,但理论上仍然面临重大挑战和变革。不曾想,在某某实验室,又在某某角落里,有着某某某,悄无声息,却给整个世纪带来了惊喜!
mnistconv.py
import input_data import tensorflow as tf #read the data mnist = input_data.read_data_sets('mnist', one_hot=True) #create the model of iput and output x = tf.placeholder(tf.float32, [None, 784]) y_ = tf.placeholder(tf.float32, [None, 10]) #start the Session sess = tf.InteractiveSession() #weight parameters initial function def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) #bias parameters initial function def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) #convolution layer function def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') #pooling layer function def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #the first convolution and pooling layer W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32]) x_image = tf.reshape(x, [-1,28,28,1]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) #the second convolution and pooling layer W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) #the fully connected layer W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) #create dropout layer for fc layer keep_prob = tf.placeholder("float") h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) #softmax classification layer W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #calculate the cross_entropy cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv)) #Adam algorithm train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #for training correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) sess.run(tf.global_variables_initializer()) for i in range(20000): batch = mnist.train.next_batch(50) if i%100 == 0: train_accuracy = accuracy.eval(feed_dict={ x:batch[0], y_: batch[1], keep_prob: 1.0}) print ("step %d, training accuracy %g"%(i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) # test batch,the raw code will run out of GPU memory for my machine,so one batch of 50 images for 10 times,then calculate the mAP. a = 10 b = 50 sum = 0 for i in range(a): testSet = mnist.test.next_batch(b) c = accuracy.eval(feed_dict={x: testSet[0], y_: testSet[1], keep_prob: 1.0}) sum += c * b #print("test accuracy %g" % c) print("test accuracy %g" % (sum / (b * a)))
在这里需要解释清楚的是,tf的卷积和池化层参数,它们的形式如下:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
tf.nn.max_pool(value, ksize, strides, padding, name=None)
这里显然用的是5*5的kernel,而stride和ksize参数所表示的四维tensor,其实第二位和第三位表示在height和width上的操作,而第一和第四位表示在batch和channel上的操作,更值得说明的是,此处是28*28变成14*14再变成7*7,因为卷积并没有改变特征图大小,而池化减半,主要是这里卷积设置padding的参数‘SAME’,表示输入输出不改变大小,默认用0填充,另一种‘VALID’方式表示不填充。
训练和测试结果如下:
step 0, training accuracy 0.18 step 100, training accuracy 0.74 step 200, training accuracy 0.9 step 300, training accuracy 0.92 step 400, training accuracy 0.92 step 500, training accuracy 0.92 step 600, training accuracy 0.92 step 700, training accuracy 0.96 step 800, training accuracy 0.98 step 900, training accuracy 1 step 1000, training accuracy 1 step 1100, training accuracy 0.96 step 1200, training accuracy 0.98 step 1300, training accuracy 0.94 step 1400, training accuracy 0.96 step 1500, training accuracy 0.98 step 1600, training accuracy 1 step 1700, training accuracy 0.94 step 1800, training accuracy 0.98 step 1900, training accuracy 0.98 step 2000, training accuracy 0.98 step 2100, training accuracy 0.98 step 2200, training accuracy 0.96 step 2300, training accuracy 1 step 2400, training accuracy 0.98 step 2500, training accuracy 0.96 step 2600, training accuracy 1 step 2700, training accuracy 0.98 step 2800, training accuracy 0.96 step 2900, training accuracy 0.98 step 3000, training accuracy 0.96 step 3100, training accuracy 1 step 3200, training accuracy 1 step 3300, training accuracy 1 step 3400, training accuracy 0.98 step 3500, training accuracy 1 step 3600, training accuracy 0.98 step 3700, training accuracy 0.98 step 3800, training accuracy 0.98 step 3900, training accuracy 1 step 4000, training accuracy 0.98 step 4100, training accuracy 1 step 4200, training accuracy 1 step 4300, training accuracy 0.98 step 4400, training accuracy 1 step 4500, training accuracy 0.98 step 4600, training accuracy 1 step 4700, training accuracy 1 step 4800, training accuracy 0.98 step 4900, training accuracy 1 step 5000, training accuracy 0.98 step 5100, training accuracy 1 step 5200, training accuracy 1 step 5300, training accuracy 1 step 5400, training accuracy 0.98 step 5500, training accuracy 1 step 5600, training accuracy 1 step 5700, training accuracy 1 step 5800, training accuracy 1 step 5900, training accuracy 1 step 6000, training accuracy 0.98 step 6100, training accuracy 0.98 step 6200, training accuracy 1 step 6300, training accuracy 0.98 step 6400, training accuracy 1 step 6500, training accuracy 0.98 step 6600, training accuracy 1 step 6700, training accuracy 1 step 6800, training accuracy 1 step 6900, training accuracy 0.98 step 7000, training accuracy 1 step 7100, training accuracy 0.98 step 7200, training accuracy 1 step 7300, training accuracy 0.98 step 7400, training accuracy 1 step 7500, training accuracy 0.96 step 7600, training accuracy 1 step 7700, training accuracy 1 step 7800, training accuracy 1 step 7900, training accuracy 0.98 step 8000, training accuracy 1 step 8100, training accuracy 1 step 8200, training accuracy 0.98 step 8300, training accuracy 1 step 8400, training accuracy 1 step 8500, training accuracy 1 step 8600, training accuracy 1 step 8700, training accuracy 0.98 step 8800, training accuracy 1 step 8900, training accuracy 0.98 step 9000, training accuracy 1 step 9100, training accuracy 0.98 step 9200, training accuracy 1 step 9300, training accuracy 1 step 9400, training accuracy 1 step 9500, training accuracy 1 step 9600, training accuracy 1 step 9700, training accuracy 1 step 9800, training accuracy 1 step 9900, training accuracy 1 step 10000, training accuracy 1 step 10100, training accuracy 1 step 10200, training accuracy 1 step 10300, training accuracy 0.98 step 10400, training accuracy 0.98 step 10500, training accuracy 1 step 10600, training accuracy 1 step 10700, training accuracy 0.98 step 10800, training accuracy 1 step 10900, training accuracy 1 step 11000, training accuracy 0.98 step 11100, training accuracy 1 step 11200, training accuracy 1 step 11300, training accuracy 1 step 11400, training accuracy 1 step 11500, training accuracy 1 step 11600, training accuracy 1 step 11700, training accuracy 0.98 step 11800, training accuracy 1 step 11900, training accuracy 1 step 12000, training accuracy 1 step 12100, training accuracy 1 step 12200, training accuracy 1 step 12300, training accuracy 1 step 12400, training accuracy 1 step 12500, training accuracy 1 step 12600, training accuracy 0.98 step 12700, training accuracy 1 step 12800, training accuracy 1 step 12900, training accuracy 1 step 13000, training accuracy 0.98 step 13100, training accuracy 1 step 13200, training accuracy 1 step 13300, training accuracy 1 step 13400, training accuracy 1 step 13500, training accuracy 1 step 13600, training accuracy 0.98 step 13700, training accuracy 1 step 13800, training accuracy 1 step 13900, training accuracy 1 step 14000, training accuracy 1 step 14100, training accuracy 1 step 14200, training accuracy 1 step 14300, training accuracy 1 step 14400, training accuracy 1 step 14500, training accuracy 1 step 14600, training accuracy 1 step 14700, training accuracy 1 step 14800, training accuracy 1 step 14900, training accuracy 1 step 15000, training accuracy 1 step 15100, training accuracy 1 step 15200, training accuracy 1 step 15300, training accuracy 1 step 15400, training accuracy 1 step 15500, training accuracy 0.98 step 15600, training accuracy 1 step 15700, training accuracy 1 step 15800, training accuracy 1 step 15900, training accuracy 1 step 16000, training accuracy 1 step 16100, training accuracy 1 step 16200, training accuracy 1 step 16300, training accuracy 1 step 16400, training accuracy 1 step 16500, training accuracy 1 step 16600, training accuracy 1 step 16700, training accuracy 1 step 16800, training accuracy 1 step 16900, training accuracy 1 step 17000, training accuracy 1 step 17100, training accuracy 1 step 17200, training accuracy 1 step 17300, training accuracy 1 step 17400, training accuracy 1 step 17500, training accuracy 1 step 17600, training accuracy 1 step 17700, training accuracy 1 step 17800, training accuracy 1 step 17900, training accuracy 1 step 18000, training accuracy 1 step 18100, training accuracy 1 step 18200, training accuracy 1 step 18300, training accuracy 1 step 18400, training accuracy 1 step 18500, training accuracy 1 step 18600, training accuracy 0.98 step 18700, training accuracy 1 step 18800, training accuracy 1 step 18900, training accuracy 1 step 19000, training accuracy 1 step 19100, training accuracy 1 step 19200, training accuracy 1 step 19300, training accuracy 1 step 19400, training accuracy 1 step 19500, training accuracy 1 step 19600, training accuracy 1 step 19700, training accuracy 1 step 19800, training accuracy 1 step 19900, training accuracy 1 test accuracy 0.988
最后只有98.8%。