设置我们的flume配置信息
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, # software distributed under the License is distributed on an # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License. # The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent' agent1.sources = r1 agent1.channels = c1 agent1.sinks = s1 # For each one of the sources, the type is defined agent1.sources.r1.type = exec #tail -F /home/oss/cloud_iom/ktpt/iom-cloud-service/logs/iom-app-debug.log agent1.sources.r1.command = tail -F /home/oss/cloud_iom/ktpt/iom-cloud-service/logs/iom-app-debug.log # The channel can be defined as follows. #agent.sources.seqGenSrc.channels = memoryChannel agent1.sources.r1.channels = c1 # Each sink's type must be defined agent1.sinks.s1.type = hbase2 agent1.sinks.s1.table = iom_app_debug agent1.sinks.s1.columnFamily = log agent1.sinks.s1.serializer = org.apache.flume.sink.hbase2.RegexHBase2EventSerializer #agent1.sinks.s1.serializer.regex = \[(.*?)\]\ \[(.*?)\]\ \[(.*?)\]\ \[(.*?)\] #Specify the channel the sink should use agent1.sinks.s1.channel = c1 # Each channel's type is defined. agent1.channels.c1.type = memory # Other config values specific to each type of channel(sink or source) # can be defined as well # In this case, it specifies the capacity of the memory channel agent1.channels.c1.capacity = 100
这个脚本配置好,设置启动命令,使用nohup是为了之后采集器自己后期自动运行
nohup flume-ng --conf hadoop/flume/conf -f hadoop/flume/conf/flume-conf.properties -n agent1 -Dflume.root.logger=DEBUG,console &
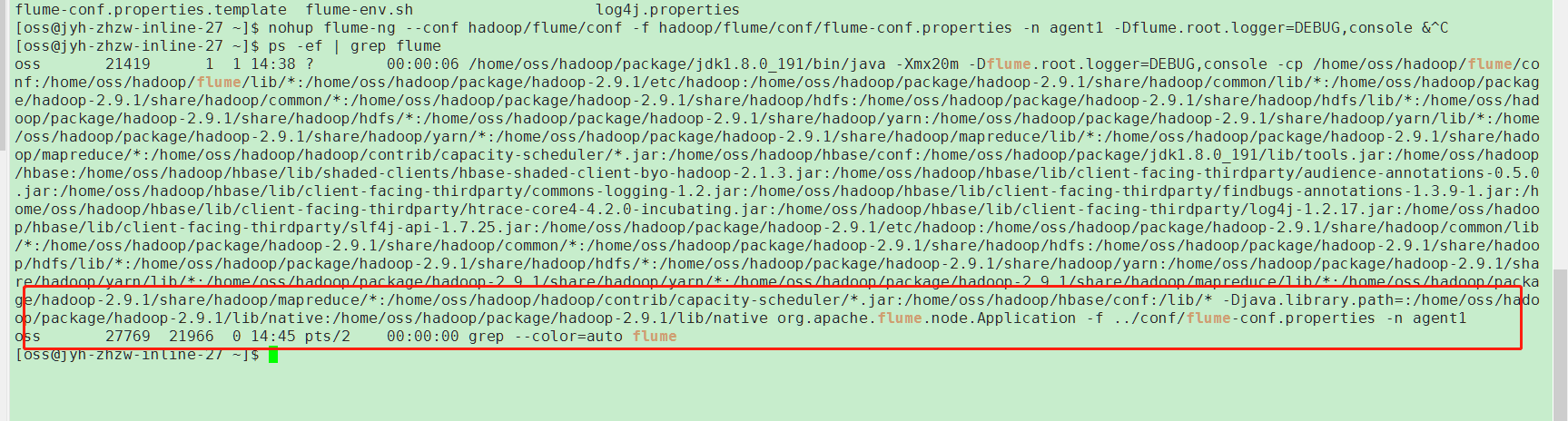
我的flume目录:

采集截图

日志文件截图
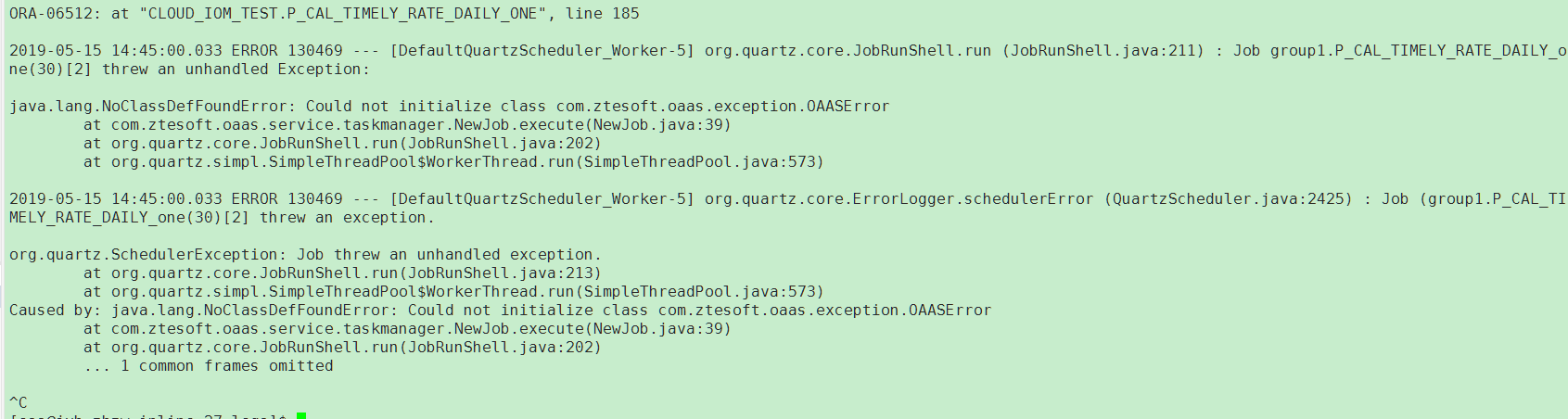
当然,这里是按行进行采集的(用的tail -F),但是shell脚本可以自己定义,只要type配置的是exec,后面sink对象也可以自己配置
第一步数据采集,第二步应该是想想如何进行数据分析,当然这样采集的数据直接分析的可能性也不太大,而且数据杂乱无序,我们还需要定义相应的逻辑先对数据进行清洗,然后再采集进去
这里这样采集是有问题的,正确的做法应该是
1.flume采集数据进入hdfs
2.MapReduce对采集进入的数据进行数据清洗,整理数据
3.MapReduce分析数据,解析入库进入hbase,或者直接保存到hdfs
4.sqoop 迁移数据到对应的数据库(mysql,Oracle)
5.根据解析之后的数据,查询Oracle制作报表图像,分析趋势,预测,或者定位问题关系