下面的图可能看不懂,你只需要读懂需求,自己用汉字结合现画图,然后就能了解下面的图是什么意思了!!!!!!!!!!!
转自https://www.cnblogs.com/JCSU/articles/1324032.html
一、关系数据理论
1. 关系模式
一个关系模式应当是一个五元组:R(U, D, DOM, F)
(1) R: 关系名;
(2) U: 一组属性;
(3) D: 属性组U中属性所来自的域;
(4) DOM: 属性到域的映射;
(5) F: 属性组U上的一组数据依赖;
由于(3)、(4)对模式设计关系不大,本章只把关系模式看作是一个三元组:R<U,F>,当且仅当U上的一个关系r满足F时,r称为关系模式R<U,F>的一个关系。
关系,作为一张二维表,对它有一个最起码的要求:每一个分量必须是不可分的数据项。满足了这个条件的关系模式就属于第一范式(1NF)。
2. 数据依赖
最重要的数据依赖是函数依赖(Functional Dependency,FD)和多值依赖(Multivalued Dependency,MVD)。
比如描述一个学生的关系,可以有学号(SNo)、姓名(SName)、系名(SDept)等几个属性。由于一个学号只对应一个学生,一个学生只在一个系学习。因而当“学号”值确定之后,学生的姓名及所在系的值也就唯一地确定了。属性间的这种依赖关系类似于数学中的函数y=f(x),自变量x确定之后,相应的函数值y也就唯一确定了。
类似的有SName=f(SNo),SDept=f(SNo),即SNo函数决定SName,SNo函数决定SDept,或者说SName和SDept函数依赖于SNo,记作SNo→SName, SNo→SDept。
[例1] 现在建立一个描述学校教务的数据库,该数据库涉及的对象包括学生的学号(SNo)、所在系(SDept)、系主任姓名(MName)、课程号(CNo)和成绩(Grade)。假设用一个单一的关系模式Student来表示,则该关系模式的属性集合为:
U={SNo, SDept, MName, CNo, Grade}
现实世界的已知事实告诉我们:
(1) 一个系有若干学生,但一个学生只属于一个系
(2) 一个系只有一名(正职)负责人
(3) 一个学生可以选修多门课程,每门课程有若干学生选修
(4) 每个学生学习每一门课程有一个成绩
于是得到属性组U上的一组函数依赖F:F={SNo→SDept, SDept→MName, (SNO, CNo)→Grade},如下图所示:
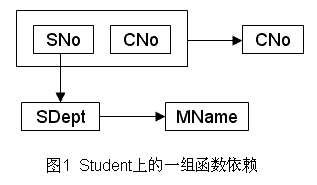
如果只考虑函数依赖这一种数据依赖,我们就得到了一个描述学生的关系模式:Student<U, F>。下表是某一时刻关系模式Student的一个实例,即数据表。
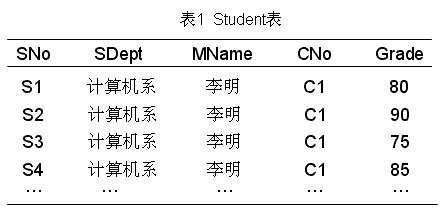
但是,这个关系模式存在以下问题:
1. 数据冗余太大
比如,每一个系的系主任姓名重复出现,重复次数与该系所有学生的所有课程成绩出现次数相同,这将浪费大量存储空间。
2. 更新异常(Update Anomalies)
由于数据冗余,当更新数据库中的数据时,系统要付出很大的代价来维护数据库的完整性,否则会面临数据不一致的危险。比如,某系更换系主任后,必须修改与该系学生有关的每一个元组。
3. 插入异常(Insertion Anomalies)
如果一个系刚成立,尚无学生,就无法把这个系及其系主任的信息存入数据库。
4. 删除异常(Deletion Anomalies)
如果某个系的学生全部毕业了,在删除该系学生信息的同时,把这个系及其系主任的信息也丢掉了。
鉴于存在以上种种问题,我们可以得出这样的结论:Student关系模式不是一个好的模式。一个“好”的模式应当不会发生插入、删除、更新异常,数据冗余应尽可能少。为什么会发生这些问题呢?这是因为这个模式中的函数依赖存在某些不好的性质。假如把这个单一的模式改造一下,分成3个关系模式(即做成3张表):
S(SNo, SDept, SNo→SDept);
SC(SNo, CNo, Grade, (SNo, CNo)→Grade);
DEPT(SDept, MName, SDept→MName)
这三个模式都不会发生插入、删除异常的毛病,数据的冗余也得到了控制。
3. 范式(Normal Formulas)
第一范式(1NF):在关系模式R中的每一个具体关系r中,如果每个属性值都是不可再分的最小数据单位,则称R是第一范式的关系。
第二范式(2NF):如果关系模式R(U,F)中的所有非主属性都完全依赖于任意一个候选关键字,则称关系R 是属于第二范式的。
【例】关系模式S-L-C (SNO,SDEPT, SLOC, CNO, GRADE)
其中SLOC为学生的住处,并且每个系的学生住在同一个地方。S-L-C的码为(SNO,CNO)。函数依赖有:
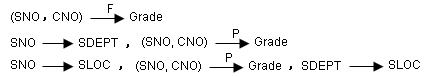
可以看到非主属性SDEPT,SLOC并不完全依赖于码。因此S-L-C不符合2NF。
一个关系模式不属于2NF,就会产生以下几个问题:
1) 插入异常。假若要插入一个学生,但该学生还未选课,即该学生无CNO,这样的元组就插不进S-L-C中。因为插入元组时必须给定码值,而这时码值的一部分分为空,因而学生的固有信息无法插入。
2) 删除异常。假定某个学生只选一门课,现在这门课不选了,要删除,由于CNO是主属性,删除了CNO,整个元组就必须跟着删除,使该学生的信息也删除了。
3) 修改复杂。某个学生需要转系,本来只需修改SDEPT分量。但因为关系模式S-L-C中还含有系的住处SLOC属性,因此还必须修改元组中的SLOC属性。另外,如果学生修改了k门课程,SDEPT和SLOC重复存储了k次,造成数据冗余,而且必须无遗漏地修改k个元组中的全部SDEPT和SLOC信息,造成修改的复杂化。
原因:分析上面的例子,可以发现问题在于有两种非主属性。一种如GRADE,它对码是完全函数依赖。另一种如SDEPT、SLOC对码是不完全函数依赖。
解决办法:分解单一的关系模式S-L-C变成两个关系模式。
第三范式(3NF):如果关系模式R(U,F)中的所有非主属性对任何候选关键字都不存在传递依赖,则称关系R是属于第三范式的。