一.用法解析:
fork()这个函数,可以说是名如其人了,众所周知fork这个单词本意为叉子,老外取学术名字的时候总会有一些象形的想法,于是就有了下图~
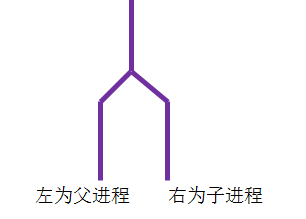
fork()函数是计算机程序设计中的分叉函数。也就是一个父进程会对应创建一个子进程。
那么问题来了,我们平常学的函数大多都是只有一个返回值,但fork()特别就特别在调用一次可以产生两个返回值!
fork()第一次返回的是子进程的ID(在父进程中返回子进程ID)
第二次返回的是0(在子进程中返回0)
总的来说,fork()可能有三种不同的返回值:
(1) 在父进程中,fork()返回新创建子进程的进程ID;
(2)在子进程中,fork()返回0;
(3)如果出现错误,fork()返回一个负值;
引用一位网友的话来解释pid的值为什么在父子进程中不同。
“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id, 因为子进程没有子进程,所以其pid为0.”
那么fork()是如何返回两次的呢?
第一步:create(创建子进程)
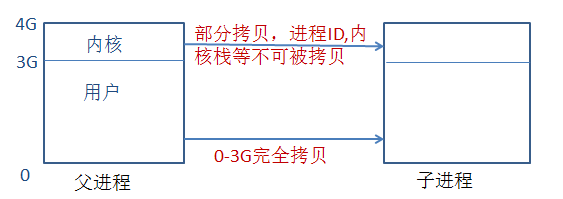
第二步:clone(相当于父进程对子进程进行初始化,把自己的0-3G用户空间完全的复制给子进程,下面会详细说)
return child_pid;(把自己的信息传递给子进程后,返回子进程ID)
接下来我们可以理解成在fork()函数完成一半时,父进程中断,切换到子进程,子进程接着走完剩下的一半fork()函数,即完成return 0,
这也就解释了为什么fork()函数返回子进程ID说明当前进程是父进程,返回0说明当前进程是子进程。
问题又来了,是否在子进程在创建时就进行clone操作呢?
当然不是,当我们发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,于是现在的linux提出了
父进程和子进程共享页面而不是复制页面,只有在子进程有写操作的时候,才进行clone操作,即读时共享,写时复制原则。具体的可以看这篇文章,大佬说的非常详细http://www.cnblogs.com/wuchanming/p/4495479.html
那么在进行父子进程的拷贝的时候,都拷贝哪些东西呢?
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
二.练手小题
1.fork()的连续调用:
下面的程序创建出多少进程?
fork();
fork();
fork();
fork();
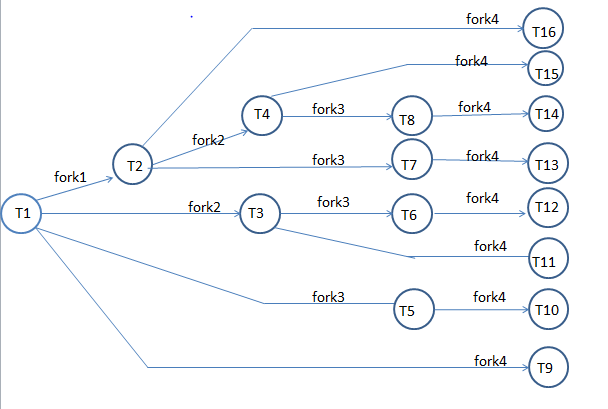
答案如上图,一共有16个进程,除去主函数的进程,产生了15个进程。
有人想通过调用printf("+");来统计创建了几个进程,这是不妥当的。具体原因如下代码:
1 #include <unistd.h> 2 #include <stdio.h> 3 int main() { 4 pid_t fpid;//fpid表示fork函数返回的值 5 //printf("fork!"); 6 printf("fork!/n"); 7 fpid = fork(); 8 if (fpid < 0) 9 printf("error in fork!"); 10 else if (fpid == 0) 11 printf("I am the child process, my process id is %d/n", getpid()); 12 else 13 printf("I am the parent process, my process id is %d/n", getpid()); 14 return 0; 15 }
执行结果如下:
fork!
I am the parent process, my process id is 3361
I am the child process, my process id is 3362
如果把语句printf("fork!/n");注释掉,执行printf("fork!");
则新的程序的执行结果是:
fork!I am the parent process, my process id is 3298
fork!I am the child process, my process id is 3299
程序的唯一的区别就在于一个/n回车符号,为什么结果会相差这么大呢?
这就跟printf的缓冲机制有关了,printf某些内容时,操作系统仅仅是把该内容放到了stdout的缓冲队列里了,并没有实际的写到屏幕上。但是,只要看到有/n 则会立即刷新stdout,因此就马上能够打印了。
运行了printf("fork!")后,“fork!”仅仅被放到了缓冲里,程序运行到fork时缓冲里面的“fork!” 被子进程复制过去了。因此在子进程度stdout缓冲里面就也有了fork! 。所以,你最终看到的会是fork! 被printf了2次!!!!
而运行printf("fork! /n")后,“fork!”被立即打印到了屏幕上,之后fork到的子进程里的stdout缓冲里不会有fork! 内容。因此你看到的结果会是fork! 被printf了1次!!!!
所以说printf("+");不能正确地反应进程的数量。
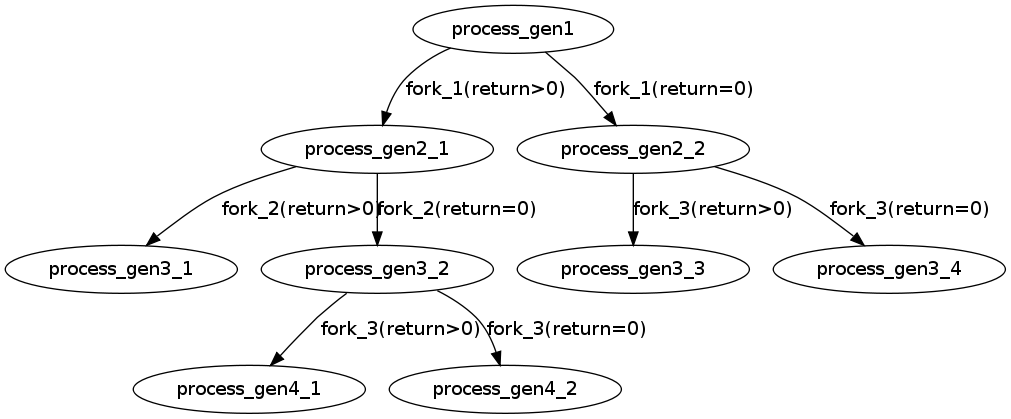
2.
1 fork(); 2 3 fork()&&fork()||fork(); 4 5 fork();
答案是总共20个进程,除去main进程,还有19个进程。
我们再来仔细分析一下,为什么是还有19个进程。
第一个fork和最后一个fork肯定是会执行的。
主要在中间3个fork上,可以画一个图进行描述。
这里就需要注意&&和||运算符。
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
fork()对于父进程和子进程的返回值是不同的,按照上面的A&&B和A||B的分支进行画图,可以得出5个分支。
参考资料:
http://blog.csdn.net/jason314/article/details/5640969