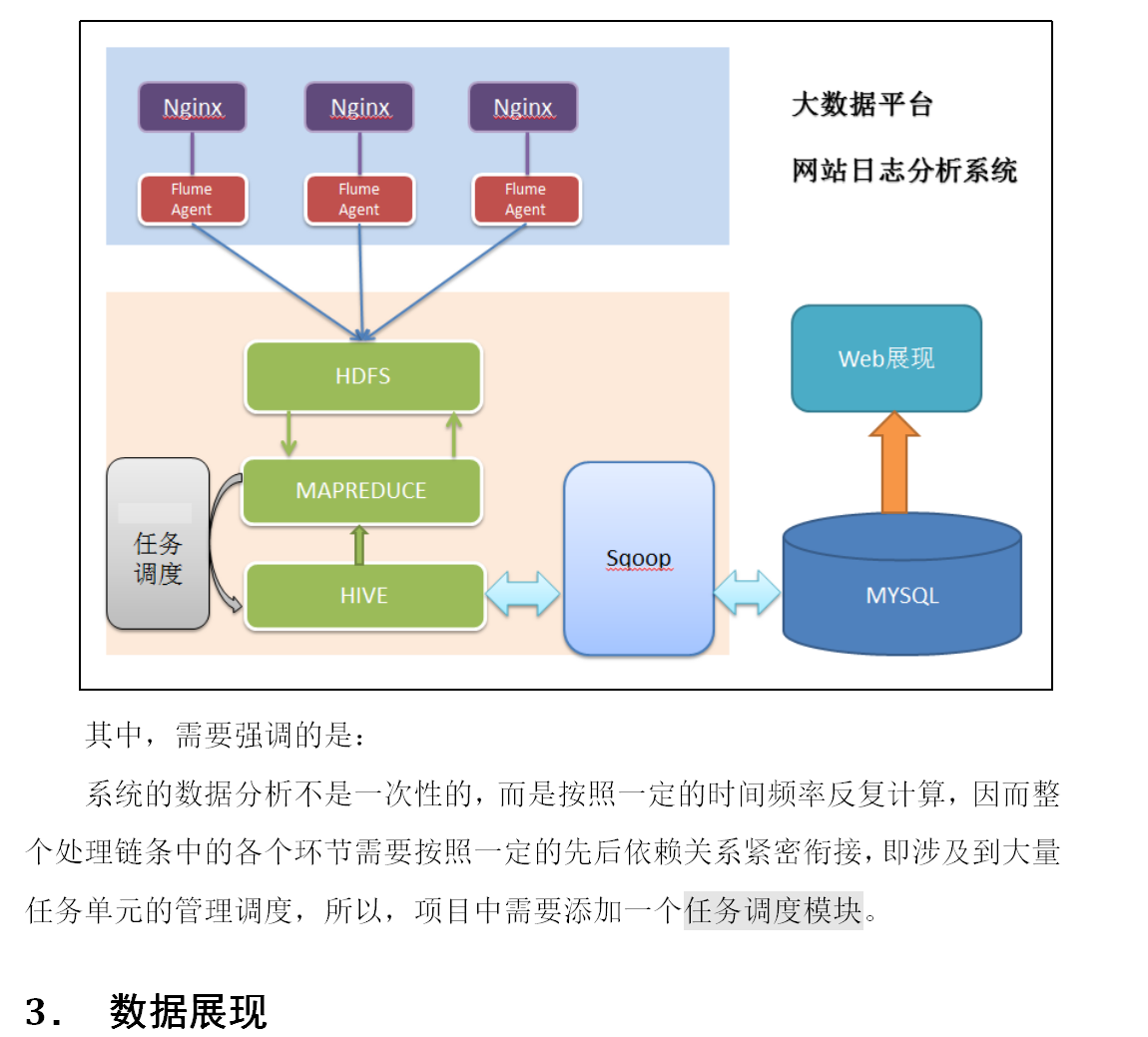
17-网站流量日志分析-数据处理流程


====================================================================================================================================================
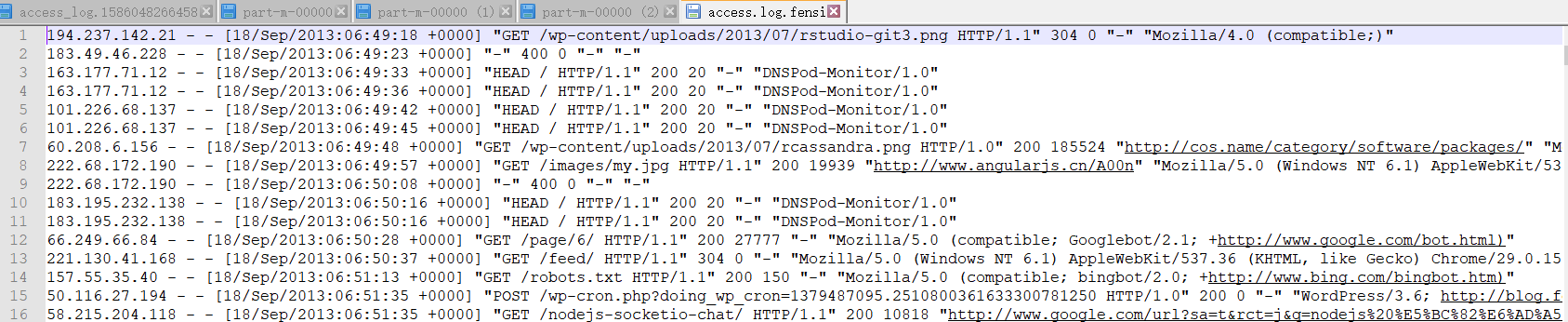
18-网站流量日志分析-数据采集




 =================================================================================================================================================================
=================================================================================================================================================================
19-网站流量日志分析-数据预处理

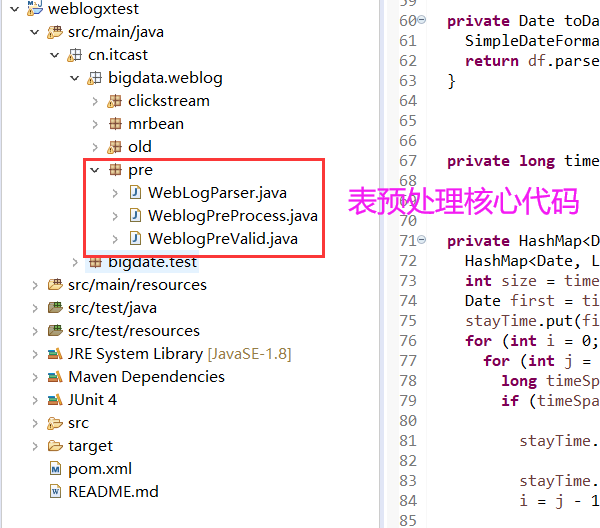


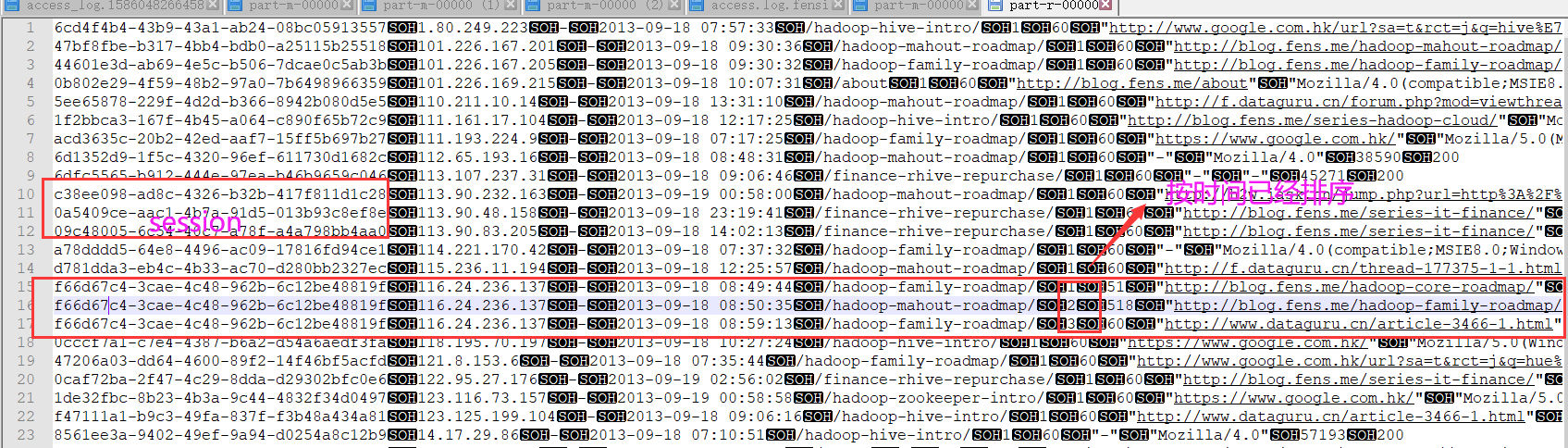
SOH为�01分隔符
=======================================================================================================================================================
20-网站流量日志分析-获取PageView表模型


=============================================================================================================================================================
21-网站流量日志分析-获取Visit表模型

2代表在session中访问了几个页面
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

=============================================================================================================================================================
22-网站流量日志分析-hive表数据导入

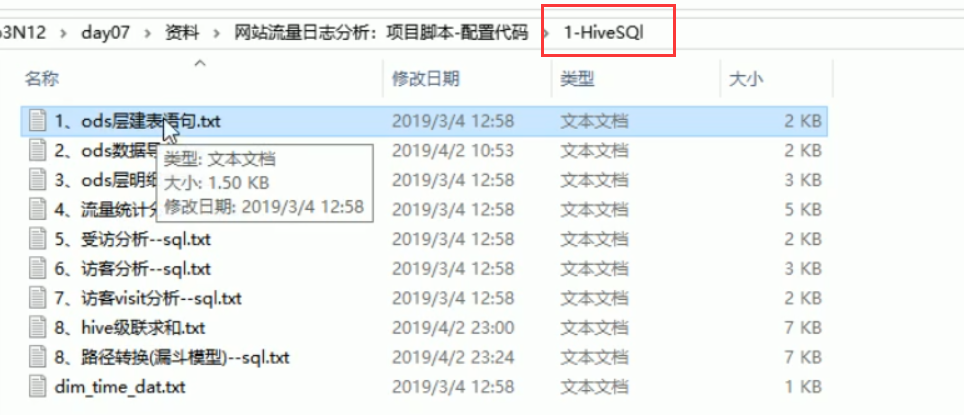
1、ods层建表语句.txt
原始数据表:对应mr清洗完之后的数据,而不是原始日志数据
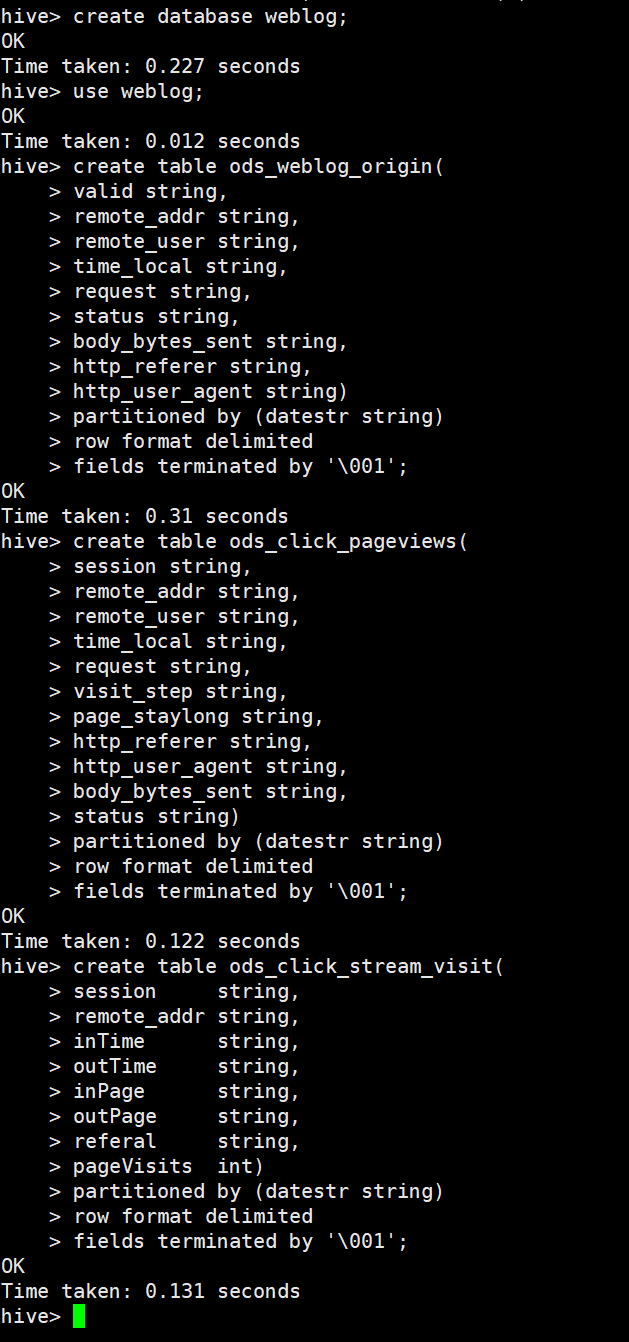
drop table if exists ods_weblog_origin;
create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by '�01';
---------------------------------------------------
点击流pageview表
drop table if exists ods_click_pageviews;
create table ods_click_pageviews(
session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited
fields terminated by '�01';
-----------------------------------------------
点击流visit表
drop table if exists ods_click_stream_visit;
create table ods_click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string)
row format delimited
fields terminated by '�01';
-------------------------------------------
维度表示例:
drop table if exists t_dim_time;
create table t_dim_time(date_key int,year string,month string,day string,hour string)
row format delimited fields terminated by ',';
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2、ods数据导入.txt
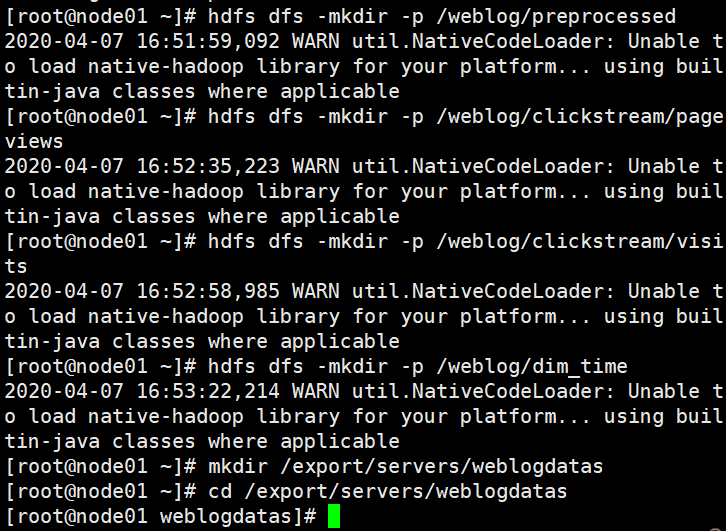
hdfs dfs -mkdir -p /weblog/preprocessed
hdfs dfs -mkdir -p /weblog/clickstream/pageviews
hdfs dfs -mkdir -p /weblog/clickstream/visits
hdfs dfs -mkdir -p /weblog/dim_time
hdfs dfs -put part-m-00000 /weblog/preprocessed
hdfs dfs -put part-r-00000 /weblog/clickstream/pageviews
hdfs dfs -put part-r-00000 /weblog/clickstream/visits
hdfs dfs -put dim_time_dat.txt /weblog/dim_time
设置hive本地模式运行
set hive.exec.mode.local.auto=true;
---------------------
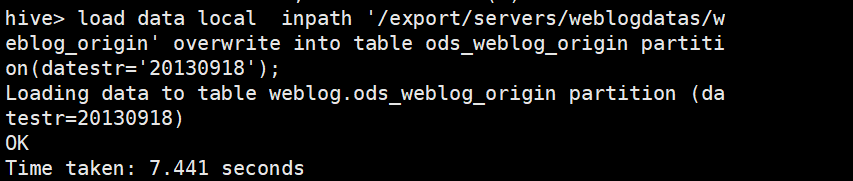
导入清洗结果数据到贴源数据表ods_weblog_origin
(datestr='20130918')这是一个分区
load data local inpath '/export/servers/weblogdatas/weblog_origin' overwrite into table ods_weblog_origin partition(datestr='20130918');
show partitions ods_weblog_origin;
select count(*) from ods_weblog_origin;
---------------------------------------------------------------------------
导入点击流模型pageviews数据到ods_click_pageviews表
load data local inpath '/export/servers/weblogdatas/pageView' overwrite into table ods_click_pageviews partition(datestr='20130918');
select count(*) from ods_click_pageviews;
-----------------------------------------------------------------------------
导入点击流模型visit数据到ods_click_stream_visit表
load data local inpath '/export/servers/weblogdatas/visit' overwrite into table ods_click_stream_visit partition(datestr='20130918');
----------------------------------------------------------------------------------------------------------------------
时间维度表数据导入
参考数据《dim_time_dat.txt》
load data inpath '/weblog/dim_time' overwrite into table t_dim_time;


--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------


--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

===========================================================================================================================================================
23-网站流量日志分析-hive表数据分析和导出
4、流量统计分析-- sql.txt
1. 流量分析
--------------------------------------------------------------------------------------------
--计算每小时pvs,注意gruop by语句的语法
select count(*) as pvs,month,day,hour from ods_weblog_detail group by month,day,hour;
--------------------------------------------------------------------------------------------
1.1. 多维度统计PV总量
--第一种方式:直接在ods_weblog_detail单表上进行查询
1.1.1 计算该处理批次(一天)中的各小时pvs
drop table if exists dw_pvs_everyhour_oneday;
create table if not exists dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string);
insert into table dw_pvs_everyhour_oneday partition(datestr='20130918')
select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a
where a.datestr='20130918' group by a.month,a.day,a.hour;
--计算每天的pvs
drop table if exists dw_pvs_everyday;
create table if not exists dw_pvs_everyday(pvs bigint,month string,day string);
insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a
group by a.month,a.day;
1.1.2 第二种方式:与时间维表关联查询
--维度:日
drop table dw_pvs_everyday;
create table dw_pvs_everyday(pvs bigint,month string,day string);
insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) a
join ods_weblog_detail b
on a.month=b.month and a.day=b.day
group by a.month,a.day;
--维度:月
drop table dw_pvs_everymonth;
create table dw_pvs_everymonth (pvs bigint,month string);
insert into table dw_pvs_everymonth
select count(*) as pvs,a.month from (select distinct month from t_dim_time) a
join ods_weblog_detail b on a.month=b.month group by a.month;
--另外,也可以直接利用之前的计算结果。比如从之前算好的小时结果中统计每一天的
Insert into table dw_pvs_everyday
Select sum(pvs) as pvs,month,day from dw_pvs_everyhour_oneday group by month,day having day='18';
--------------------------------------------------------------------------------------------
1.2 按照来访维度统计pv
--统计每小时各来访url产生的pv量,查询结果存入:( "dw_pvs_referer_everyhour" )
drop table if exists dw_pvs_referer_everyhour;
create table if not exists dw_pvs_referer_everyhour
(referer_url string,referer_host string,month string,day string,
hour string,pv_referer_cnt bigint) partitioned by(datestr string);
insert into table dw_pvs_referer_everyhour partition(datestr='20130918')
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,pv_referer_cnt desc;
--统计每小时各来访host的产生的pv数并排序
drop table dw_pvs_refererhost_everyhour;
create table dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string);
insert into table dw_pvs_refererhost_everyhour partition(datestr='20130918')
select ref_host,month,day,hour,count(1) as ref_host_cnts
from ods_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;
---------------------------------------------------------------------------
1.3 统计pv总量最大的来源TOPN
--需求:按照时间维度,统计一天内各小时产生最多pvs的来源topN
分组求topN,先分组,再求每组内的topN
--row_number函数
select ref_host,ref_host_cnts,concat(month,day,hour),
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour;
--综上可以得出
drop table dw_pvs_refhost_topn_everyhour;
create table dw_pvs_refhost_topn_everyhour(
hour string,
toporder string,
ref_host string,
ref_host_cnts string
)partitioned by(datestr string);
insert into table dw_pvs_refhost_topn_everyhour partition(datestr='20130918')
select t.hour,t.od,t.ref_host,t.ref_host_cnts from
(select ref_host,ref_host_cnts,concat(month,day,hour) as hour,
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour) t where od<=3;
---------------------------------------------------------------------------------------------
1.4 人均浏览页数
--需求描述:统计今日所有来访者平均请求的页面数。
--总页面请求数/去重总人数
drop table dw_avgpv_user_everyday;
create table dw_avgpv_user_everyday(
day string,
avgpv string);
insert into table dw_avgpv_user_everyday
select '20130918',sum(b.pvs)/count(b.remote_addr)
from
(
select remote_addr,count(1) as pvs from ods_weblog_detail where datestr='20130918'
group by remote_addr
) b;
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
5、受访分析--sql.txt
--各页面访问统计
各页面PV
select request as request,count(1) as request_counts from
ods_weblog_detail group by request having request is not null order by request_counts desc limit 20;
-----------------------------------------------
--热门页面统计
统计20130918这个分区里面的受访页面的top10
drop table dw_hotpages_everyday;
create table dw_hotpages_everyday(day string,url string,pvs string);
insert into table dw_hotpages_everyday
select '20130918',a.request,a.request_counts from
(
select request as request,count(request) as request_counts
from ods_weblog_detail
where datestr='20130918'
group by request
having request is not null
) a
order by a.request_counts desc limit 10;
统计每日最热门页面的top10
select a.month,a.day,a.request ,concat(a.month,a.day),a.total_request
from (
select month,day, request,count(1) as total_request
from ods_weblog_detail
where datestr = '20130918'
group by request ,month ,day
having request is not null
order by total_request desc limit 10
) a
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6、访客分析--sql.txt
-- 独立访客
--需求:按照时间维度来统计独立访客及其产生的pv量
按照时间维度比如小时来统计独立访客及其产生的 pv 。
时间维度:时
drop table dw_user_dstc_ip_h;
create table dw_user_dstc_ip_h(
remote_addr string,
pvs bigint,
hour string);
insert into table dw_user_dstc_ip_h
select remote_addr,count(1) as pvs,concat(month,day,hour) as hour
from ods_weblog_detail
Where datestr='20130918'
group by concat(month,day,hour),remote_addr;
--在上述基础之上,可以继续分析,比如每小时独立访客总数
select count(1) as dstc_ip_cnts,hour from dw_user_dstc_ip_h group by hour;
时间维度:日
select remote_addr,count(1) as counts,concat(month,day) as day
from ods_weblog_detail
Where datestr='20130918'
group by concat(month,day),remote_addr;
时间维度: 月
select remote_addr,count(1) as counts,month
from ods_weblog_detail
group by month,remote_addr;
----------------------------------------------------------------------------------------
-- 每日新访客
-- 需求:将每天的新访客统计出来。
--历日去重访客累积表
drop table dw_user_dsct_history;
create table dw_user_dsct_history(
day string,
ip string)
partitioned by(datestr string);
--每日新访客表
drop table dw_user_new_d;
create table dw_user_new_d (
day string,
ip string)
partitioned by(datestr string);
select a.remote_addr ,a.day
from (
select remote_addr,'20130918' as day
from ods_weblog_detail newIp
where datestr ='20130918'
group by remote_addr
) a
left join dw_user_dsct_history hist
on a.remote_addr = hist.ip
where hist.ip is null;
--每日新用户插入新访客表
insert into table dw_user_new_d partition(datestr='20130918')
select tmp.day as day,tmp.today_addr as new_ip
from
(
select today.day as day,today.remote_addr as today_addr,old.ip as old_addr
from
(
select distinct remote_addr as remote_addr,"20130918" as day
from ods_weblog_detail where datestr="20130918"
) today
left outer join
dw_user_dsct_history old
on today.remote_addr=old.ip
) tmp
where tmp.old_addr is null;
--每日新用户追加到历史累计表
insert into table dw_user_dsct_history partition(datestr='20130918')
select day,ip from dw_user_new_d where datestr='20130918';
验证:
select count(distinct remote_addr) from ods_weblog_detail;
select count(1) from dw_user_dsct_history where datestr='20130918';
select count(1) from dw_user_new_d where datestr='20130918';
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
7、访客visit分析--sql.txt
-- 回头/单次访客统计
select remote_addr ,count(remote_addr) ipcount
from ods_click_stream_visit
group by remote_addr
having ipcount > 1
查询今日所有回头访客及其访问次数。
drop table dw_user_returning;
create table dw_user_returning(
day string,
remote_addr string,
acc_cnt string)
partitioned by (datestr string);
insert overwrite table dw_user_returning partition(datestr='20130918')
select tmp.day,tmp.remote_addr,tmp.acc_cnt
from
(select '20130918' as day,remote_addr,count(session) as acc_cnt from ods_click_stream_visit
group by remote_addr) tmp
where tmp.acc_cnt>1;
------------------------------------------------------------------------------------
-- 人均访问频次,使用所有的独立访问的人,即独立的session个数除以所有的去重IP即可
-- 人均访问的频次,频次表示我们来了多少个session
-- 次数都是使用session来进行区分,一个session就是表示一次
select count(session)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20130918';
select count(1)
from ods_click_stream_visit
where datestr ='20130918'
-- 人均页面浏览量,所有的页面点击次数累加除以所有的独立去重IP总和即可
select sum(pagevisits)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20130918';
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
8、hive级联求和.txt
create table t_salary_detail(username string,month string,salary int)
row format delimited fields terminated by ',';
load data local inpath '/export/servers/hivedatas/accumulate' into table t_salary_detail;
用户 时间 收到小费金额
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,7
A,2015-03,9
B,2015-03,11
B,2015-03,6
select username,month, sum(salary)
from t_salary_detail
group by username,month
需求:统计每个用户每个月总共获得多少小费
select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month;
+----------+-------------+---------+--+
| t.month | t.username | salsum |
+----------+-------------+---------+--+
| 2015-01 | A | 33 |
| 2015-02 | A | 10 |
| 2015-03 | A | 16 |
| 2015-01 | B | 30 |
| 2015-02 | B | 15 |
| 2015-03 | B | 17 |
+----------+-------------+---------+--+
需求:统计每个用户累计小费
+----------+-------------+---------+--+
| t.month | t.username | salsum | 累计小费
+----------+-------------+---------+--+
| 2015-01 | A | 33 | 33
| 2015-02 | A | 10 | 43
| 2015-03 | A | 16 | 59
| 2015-01 | B | 30 | 30
| 2015-02 | B | 15 | 45
| 2015-03 | B | 17 | 62
+----------+-------------+---------+--+
第一步:求每个用户的每个月的小费总和
select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month;
+----------+-------------+---------+--+
| t.month | t.username | salsum |
+----------+-------------+---------+--+
| 2015-01 | A | 33 |
| 2015-02 | A | 10 |
| 2015-03 | A | 16 |
| 2015-01 | B | 30 |
| 2015-02 | B | 15 |
| 2015-03 | B | 17 |
+----------+-------------+---------+--+
第二步:使用inner join 实现自己连接自己
select
A.* ,B.*
from
(select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month) A
inner join
(select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month) B
on A.username = B.username;
+----------+-------------+-----------+----------+-------------+-----------+--+
| a.month | a.username | a.salsum | b.month | b.username | b.salsum |
+----------+-------------+-----------+----------+-------------+-----------+--+
取这一个作为一组
| 2015-01 | A | 33 | 2015-01 | A | 33 |
| 2015-01 | A | 33 | 2015-02 | A | 10 |
| 2015-01 | A | 33 | 2015-03 | A | 16 |
取这两个作为一组
| 2015-02 | A | 10 | 2015-01 | A | 33 |
| 2015-02 | A | 10 | 2015-02 | A | 10 |
| 2015-02 | A | 10 | 2015-03 | A | 16 |
取这三个作为一组
| 2015-03 | A | 16 | 2015-01 | A | 33 |
| 2015-03 | A | 16 | 2015-02 | A | 10 |
| 2015-03 | A | 16 | 2015-03 | A | 16 |
| 2015-01 | B | 30 | 2015-01 | B | 30 |
| 2015-01 | B | 30 | 2015-02 | B | 15 |
| 2015-01 | B | 30 | 2015-03 | B | 17 |
| 2015-02 | B | 15 | 2015-01 | B | 30 |
| 2015-02 | B | 15 | 2015-02 | B | 15 |
| 2015-02 | B | 15 | 2015-03 | B | 17 |
| 2015-03 | B | 17 | 2015-01 | B | 30 |
| 2015-03 | B | 17 | 2015-02 | B | 15 |
| 2015-03 | B | 17 | 2015-03 | B | 17 |
+----------+-------------+-----------+----------+-------------+-----------+--+
每一步相对于上一步的结果
加参数继续变形
select
A.* ,B.*
from
(select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month) A
inner join
(select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month) B
on A.username = B.username
where B.month <= A.month;
+----------+-------------+-----------+----------+-------------+-----------+--+
| a.month | a.username | a.salsum | b.month | b.username | b.salsum |
+----------+-------------+-----------+----------+-------------+-----------+--+
| 2015-01 | A | 33 | 2015-01 | A | 33 | 33
| 2015-02 | A | 10 | 2015-01 | A | 33 | 43
| 2015-02 | A | 10 | 2015-02 | A | 10 |
| 2015-03 | A | 16 | 2015-01 | A | 33 | 59
| 2015-03 | A | 16 | 2015-02 | A | 10 |
| 2015-03 | A | 16 | 2015-03 | A | 16 |
| 2015-01 | B | 30 | 2015-01 | B | 30 | 30
| 2015-02 | B | 15 | 2015-01 | B | 30 | 45
| 2015-02 | B | 15 | 2015-02 | B | 15 |
| 2015-03 | B | 17 | 2015-01 | B | 30 | 62
| 2015-03 | B | 17 | 2015-02 | B | 15 |
| 2015-03 | B | 17 | 2015-03 | B | 17 |
+----------+-------------+-----------+----------+-------------+-----------+--+
第三步:从第二步的结果中继续通过a.month与a.username进行分组,并对分组后的b.salsum进行累加求和即可
select
A.username,A.month,max(A.salSum),sum(B.salSum) as accumulate
from
(select t.month,t.username,sum(salary) as salSum from t_salary_detail t group by t.username,t.month) A
inner join
(select t.month,t.username,sum(salary) as salSum from t_salary_detail t group by t.username,t.month) B
on A.username = B.username
where B.month <= A.month
group by A.username,A.month
order by A.username,A.month;
累计的消费进行求和
+-------------+----------+------+-------------+--+
| a.username | a.month | _c2 | accumulate |
+-------------+----------+------+-------------+--+
| A | 2015-01 | 33 | 33 |
| A | 2015-02 | 10 | 43 |
| A | 2015-03 | 16 | 59 |
| B | 2015-01 | 30 | 30 |
| B | 2015-02 | 15 | 45 |
| B | 2015-03 | 17 | 62 |
+-------------+----------+------+-------------+--+
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------


sqoop_export.sh(从hdfs导入daomysql数据库)
#!/bin/bash
if [ $# -eq 1 ]
then
cur_date=`date --date="${1}" +%Y-%m-%d`
else
cur_date=`date -d'-1 day' +%Y-%m-%d`
fi
echo "cur_date:"${cur_date}
year=`date --date=$cur_date +%Y`
month=`date --date=$cur_date +%m`
day=`date --date=$cur_date +%d`
table_name=""
table_columns=""
hadoop_dir=/user/rd/bi_dm/app_user_experience_d/year=${year}/month=${month}/day=${day}
mysql_db_pwd=biall_pwd2015
mysql_db_name=bi_tag_all
echo 'sqoop start'
$SQOOP_HOME/bin/sqoop export
--connect "jdbc:mysql://hadoop03:3306/biclick"
--username $mysql_db_name
--password $mysql_db_pwd
--table $table_name
--columns $table_columns
--fields-terminated-by '�01'
--export-dir $hadoop_dir
echo 'sqoop end'
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1.job
type=command
command=/export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop jar weblogparser.jar cn.itcast.bigdata.weblog.pre.WeblogPreProcess

也就是第一个mapreduce
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2.job
type=command
command=/export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop jar weblogparser.jar cn.itcast.bigdata.weblog.clickstream.ClickStreamPageView
dependencies=1

也就是第二个mapreduce
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
3,job
type=command
command=/export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop jar weblogparser.jar cn.itcast.bigdata.weblog.clickstream.ClickStreamVisit
dependencies=2

执行第三个mapreduce
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
4.job
type=command
command=sh 4.sh
dependencies=3

4.sh(导入hive仓库的脚本)
#!/bin/bash
#set java env
export JAVA_HOME=/export/servers/jdk1.8.0_141
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#获取时间信息
day_01=`date -d'-1 day' +%Y%m%d`
syear=`date --date=$day_01 +%Y`
smonth=`date --date=$day_01 +%m`
sday=`date --date=$day_01 +%d`
#预处理输出结果(raw)目录
log_pre_output="/weblog/'$day_01'/weblogPreOut"
#点击流clickStream模型预处理程序输出目录
pageView="/weblog/'$day_01'/pageViewOut"
#点击流visit模型预处理程序输出目录
visit="/weblog/'$day_01'/clickStreamVisit"
#目标hive表
ods_weblog_origin="weblog.ods_weblog_origin"
ods_click_pageviews="weblog.ods_click_pageviews"
ods_click_stream_visit="weblog.ods_click_stream_visit"
#导入数据到weblog.ods_weblog_origin
HQL_origin="load data inpath '$log_pre_output' overwrite into table $ods_weblog_origin partition(datestr='$day_01')"
echo $HQL_origin
/export/servers/hive-1.1.0-cdh5.14.0/bin/hive -e "$HQL_origin"
#导入点击流模型pageviews数据到
HQL_pvs="load data inpath '$pageView' overwrite into table ods_click_pageviews partition(datestr='$day_01')"
echo $HQL_pvs
/export/servers/hive-1.1.0-cdh5.14.0/bin/hive -e "$HQL_pvs"
#导入点击流模型visit数据到
HQL_vst="load data inpath '$visit' overwrite into table $ods_click_stream_visit partition(datestr='$day_01')"
echo $HQL_vst
/export/servers/hive-1.1.0-cdh5.14.0/bin/hive -e "$HQL_vst"
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
5.job
type=command
command=/export/servers/hive-1.1.0-cdh5.14.0/bin/hive -f "5.sql"
dependencies=4

5.sql(对hive中的数据进行分析)
create database if not exist weblog;
use weblog;
-- 1.1.1 计算该处理批次(一天)中的各小时pvs
drop table if exists dw_pvs_everyhour_oneday;
create table if not exists dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string);
insert into table dw_pvs_everyhour_oneday partition(datestr='20130918')
select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a
where a.datestr='20130918' group by a.month,a.day,a.hour;
-- 计算每天的pvs
drop table if exists dw_pvs_everyday;
create table if not exists dw_pvs_everyday(pvs bigint,month string,day string);
insert into table dw_pvs_everyday select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a group by a.month,a.day;
-- 统计每小时各来访url产生的pv量,查询结果存入:( "dw_pvs_referer_everyhour" )
drop table if exists dw_pvs_referer_everyhour;
create table if not exists dw_pvs_referer_everyhour (referer_url string,referer_host string,month string,day string,hour string,pv_referer_cnt bigint) partitioned by(datestr string);
insert into table dw_pvs_referer_everyhour partition(datestr='20130918') select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt from ods_weblog_detail group by http_referer,ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,pv_referer_cnt desc;
-- 统计每小时各来访host的产生的pv数并排序
drop table if exists dw_pvs_refererhost_everyhour;
create table if not exists dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string);
insert into table dw_pvs_refererhost_everyhour partition(datestr='20130918') select ref_host,month,day,hour,count(1) as ref_host_cnts from ods_weblog_detail group by ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,ref_host_cnts desc;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6.job
type=command
command=sh 6.sh
dependencies=5

6.sh
#!/bin/bash
#数据导出
/export/servers/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect jdbc:mysql://192.168.25.25:3306/weblog --username root --password admin --m 1 --export-dir /user/hive/warehouse/weblog.db/dw_pvs_everyday --table dw_pvs_everyday --input-fields-terminated-by '�01'
#数据导出
/export/servers/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect jdbc:mysql://192.168.25.25:3306/weblog --username root --password admin --m 1 --export-dir /user/hive/warehouse/weblog.db/dw_pvs_everyhour_oneday/datestr=20130918 --table dw_pvs_everyhour_oneday --input-fields-terminated-by '�01'
#数据导出
/export/servers/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect jdbc:mysql://192.168.25.25:3306/weblog --username root --password admin --m 1 --export-dir /user/hive/warehouse/weblog.db/dw_pvs_referer_everyhour/datestr=20130918 --table dw_pvs_referer_everyhour --input-fields-terminated-by '�01'
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
================================================================================================================================================
24-网站流量日志分析-数据的可视化-Echarts入门

iondex.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<html>
<head>
<script src="js/echarts.min.js"></script>
</head>
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style=" 600px;height:400px;"></div>
</body>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</html>
===========================================================================================================================================
25-网站流量日志分析-数据的可视化-案例分析结果可视化