1.HDFS概述



===============================================================================================================
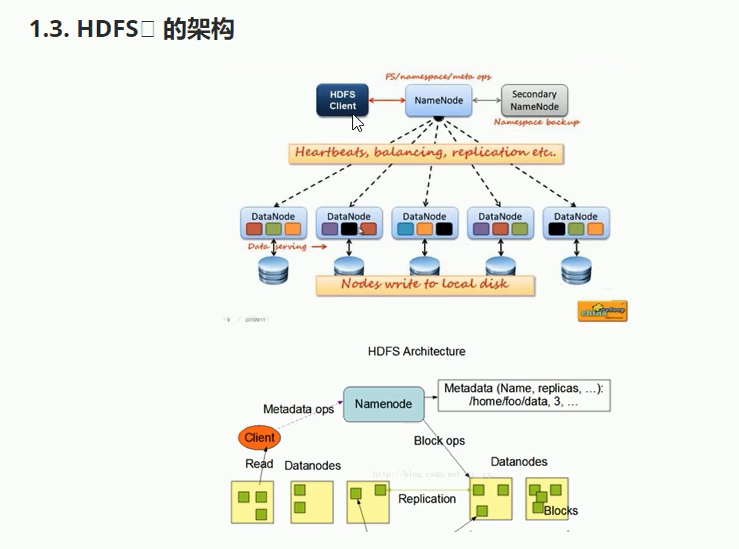
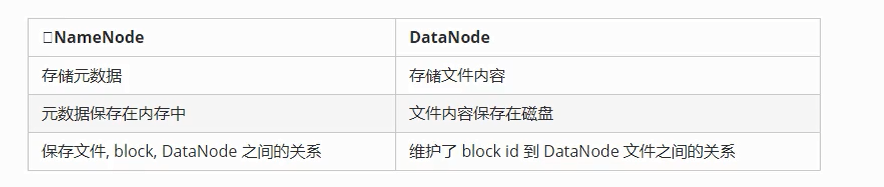
2-HDFS的namenode和datanode

========================================================================================================================
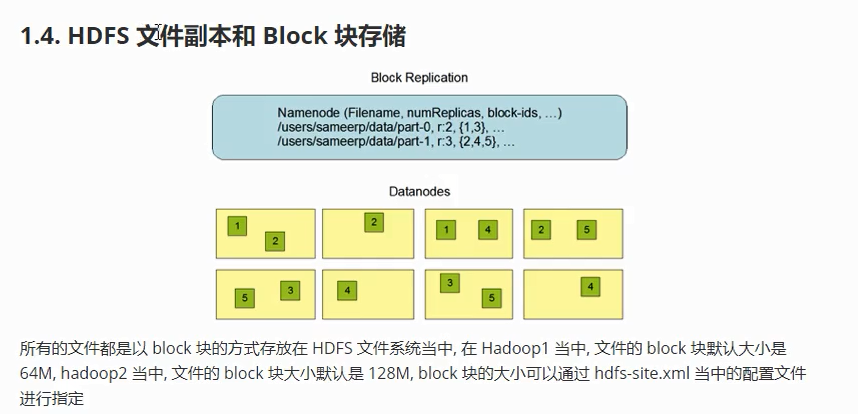
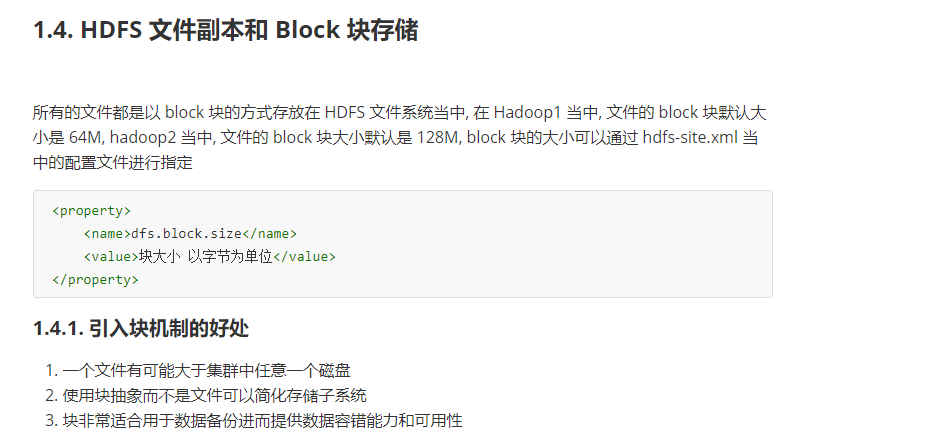
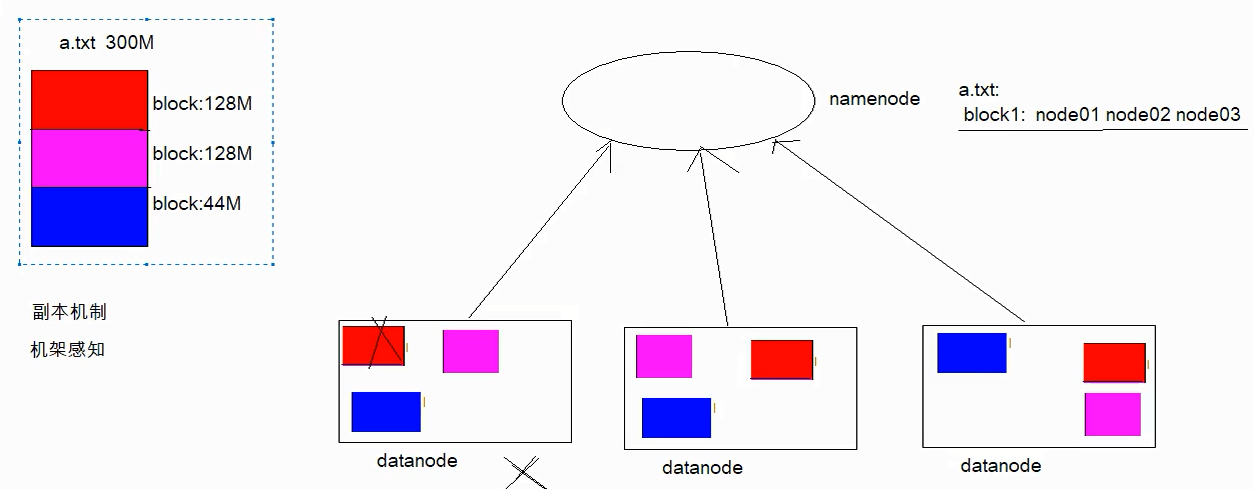
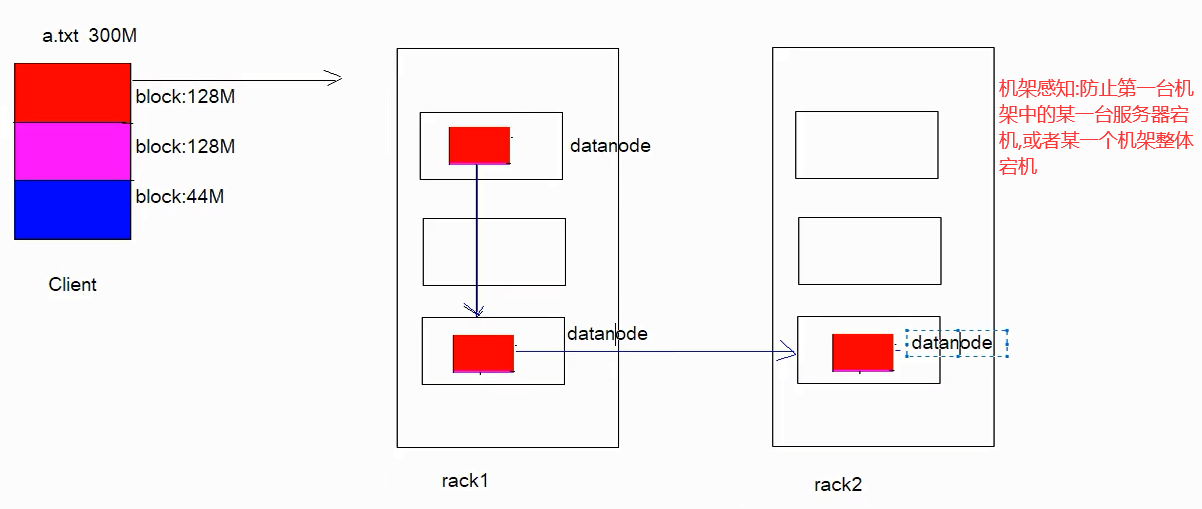
3-HDFS的文件副本机制

=================================================================================================================
4-HDFS的块缓存和访问权限

注意:block只是个逻辑单位(说的时候只说这个文件是几个block)
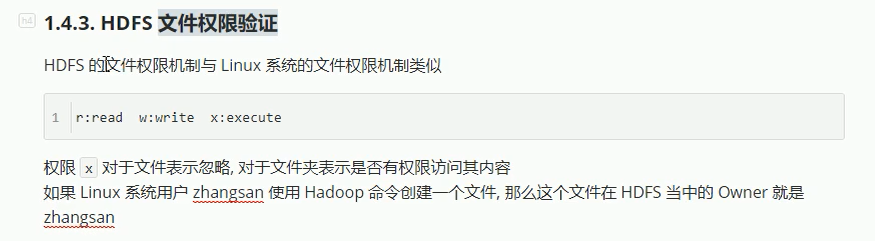
HDFS系统跟linux系统很像,也有一个根目录,根目录下有子目录


=============================================================================================================
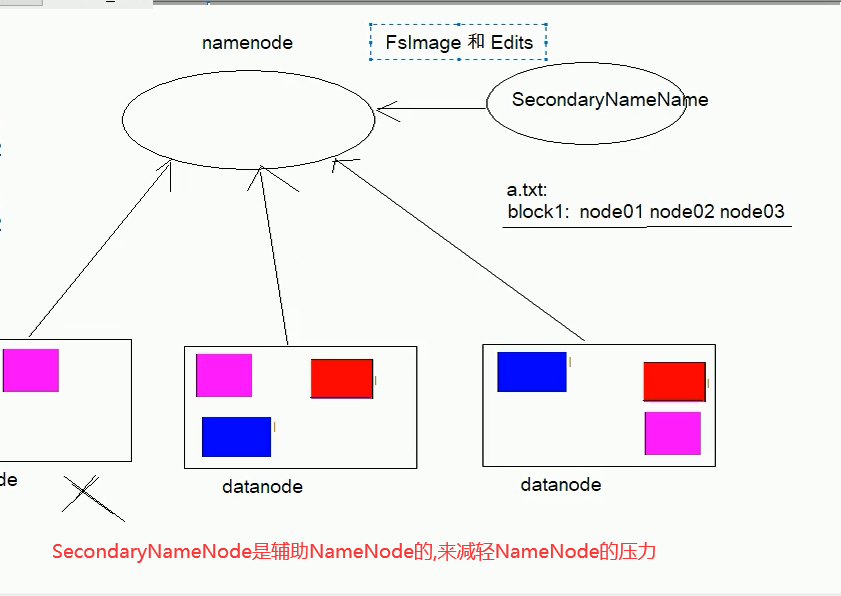
5-HDFS的Secondarynamenode工作机制

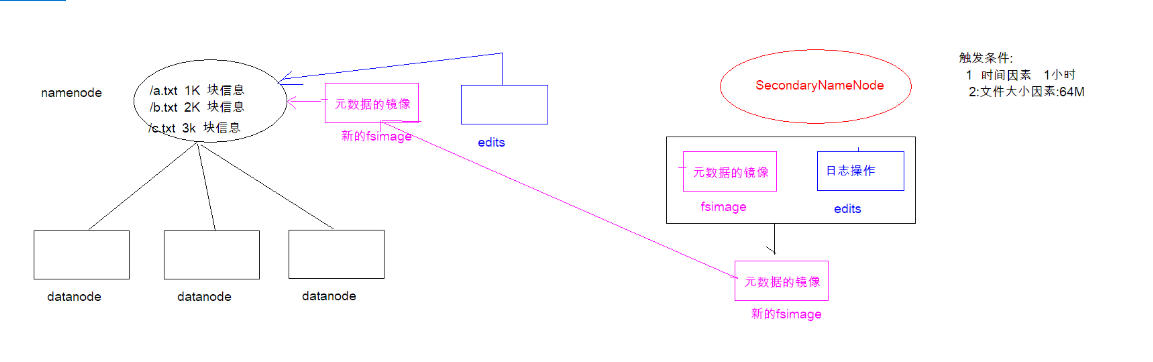
解释需要SecondaryNameNode?
因为nameNode是存放在内存中的,故服务器宕机后会导致元数据丢失;这时候就需要将元数据持久化到磁盘上,就引出fsimage组文件和edits组文件;但是服务器不在短期内重启的话,这就导致edits日志组文件变得非常大,导致回复起来非常慢;这 时就引出了secondaryNamenode的概念,SecondaryNameNode主要负责将fsimage组文件和edits组文件合并成新的镜像,合并成新的之后,会清空edits日志操作组文件,这就保证了恢复的效率.
1.5.2. fsimage 中的文件信息查看
使用命令 hdfs oiv
cd /export/servers/hadoop-3.1.1/datas/namenode/namenodedatas
hdfs oiv -i fsimage_0000000000000000864 -p XML -o hello.xml
1.5.3. edits 中的文件信息查看
使用命令 hdfs oev
cd /export/servers/hadoop-3.1.1/datas/dfs/nn/edits
hdfs oev -i edits_0000000000000000865-0000000000000000866 -o myedit.xml -p XML
1.5.4. SecondaryNameNode 如何辅助管理 fsimage 与 edits 文件?
SecondaryNameNode 定期合并 fsimage 和 edits, 把 edits 控制在一个范围内
配置 SecondaryNameNode
SecondaryNameNode 在 conf/masters 中指定
在 masters 指定的机器上, 修改 hdfs-site.xml
<property>
<name>dfs.http.address</name>
<value>host:50070</value>
</property>
修改 core-site.xml, 这一步不做配置保持默认也可以
<!-- 多久记录一次 HDFS 镜像, 默认 1小时 -->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一次记录多大, 默认 64M -->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
1).SecondaryNameNode 通知 NameNode 切换 editlog
2).SecondaryNameNode 从 NameNode 中获得 fsimage 和 editlog(通过http方式)
3).SecondaryNameNode 将 fsimage 载入内存, 然后开始合并 editlog, 合并之后成为新的 fsimage
4).SecondaryNameNode 将新的 fsimage 发回给 NameNode
5).NameNode 用新的 fsimage 替换旧的 fsimage
特点
1).完成合并的是 SecondaryNameNode, 会请求 NameNode 停止使用 edits, 暂时将新写操作放入一个新的文件中 edits.new
2).SecondaryNameNode 从 NameNode 中通过 Http GET 获得 edits, 因为要和 fsimage 合并, 所以也是通过 Http Get 的方式把 fsimage 加载到内存, 然后逐一执行具体对文件系统的操作, 与 fsimage 合并, 生成新的 fsimage, 然后通过 Http POST 的方式把 fsimage 发送给 NameNode. NameNode 从 SecondaryNameNode 获得了 fsimage 后会把原有的 fsimage 替换为新的 fsimage, 把 edits.new 变成 edits. 同时会更新 fstime
3).Hadoop 进入安全模式时需要管理员使用 dfsadmin 的 save namespace 来创建新的检查点
4).SecondaryNameNode 在合并 edits 和 fsimage 时需要消耗的内存和 NameNode 差不多, 所以一般把 NameNode 和 SecondaryNameNode 放在不同的机器上
=================================================================================================================
6-HDFS数据的写入过程
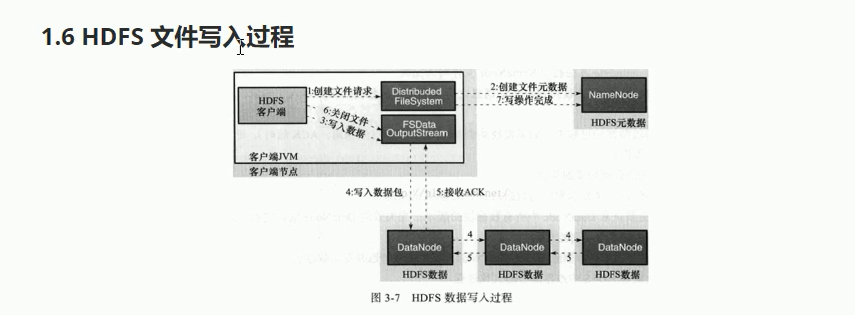
1).Client 发起文件上传请求, 通过 RPC 与 NameNode 建立通讯, NameNode 检查目标文件是否已存在, 父目录是否存在, 返回是否可以上传
2).Client 请求第一个 block 该传输到哪些 DataNode 服务器上
3).NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配, 返回可用的 DataNode 的地址如: A, B, C
Hadoop 在设计时考虑到数据的安全与高效, 数据文件默认在 HDFS 上存放三份, 存储策略为本地一份, 同机架内其它某一节点上一份, 不同机架的某一节点上一份。
4).Client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline ), A 收到请求会继续调用 B, 然后 B 调用 C, 将整个 pipeline 建立完成, 后逐级返回 client
5).Client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存), 以 packet 为单位(默认64K), A 收到一个 packet 就会传给 B, B 传给 C. A 每传一个 packet 会放入一个应答队列等待应答
6).数据被分割成一个个 packet 数据包在 pipeline 上依次传输, 在 pipeline 反方向上, 逐个发送 ack(命令正确应答), 最终由 pipeline 中第一个 DataNode 节点 A 将 pipelineack 发送给 Client
7).当一个 block 传输完成之后, Client 再次请求 NameNode 上传第二个 block 到服务 1
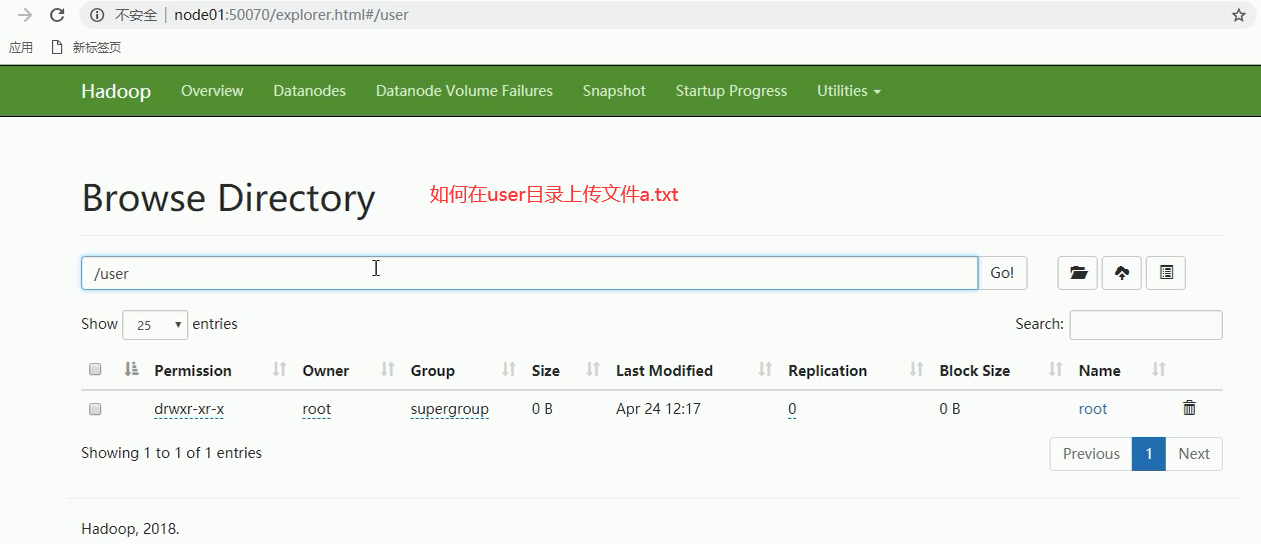
上传a.txt文件之后,如何将文件保存到这个系统呢?

==================================================================================================
7-HDFS数据的读取过程
如何实现下载a.txt的过程呢?
1).Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
2).NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址; 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
3).Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
4).底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
5).当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
6).读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
7).read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
8).最终读取来所有的 block 会合并成一个完整的最终文件。

=======================================================================================================
8-HDFS的shell操作命令
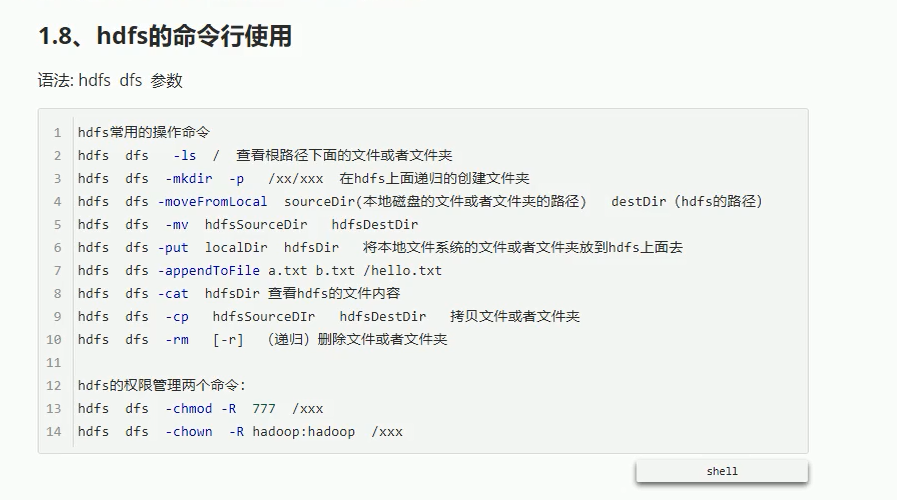














注意:尽量避免hdfs的小文件过多,因为这样会造成namenode的压力过大










===================================================================================================================
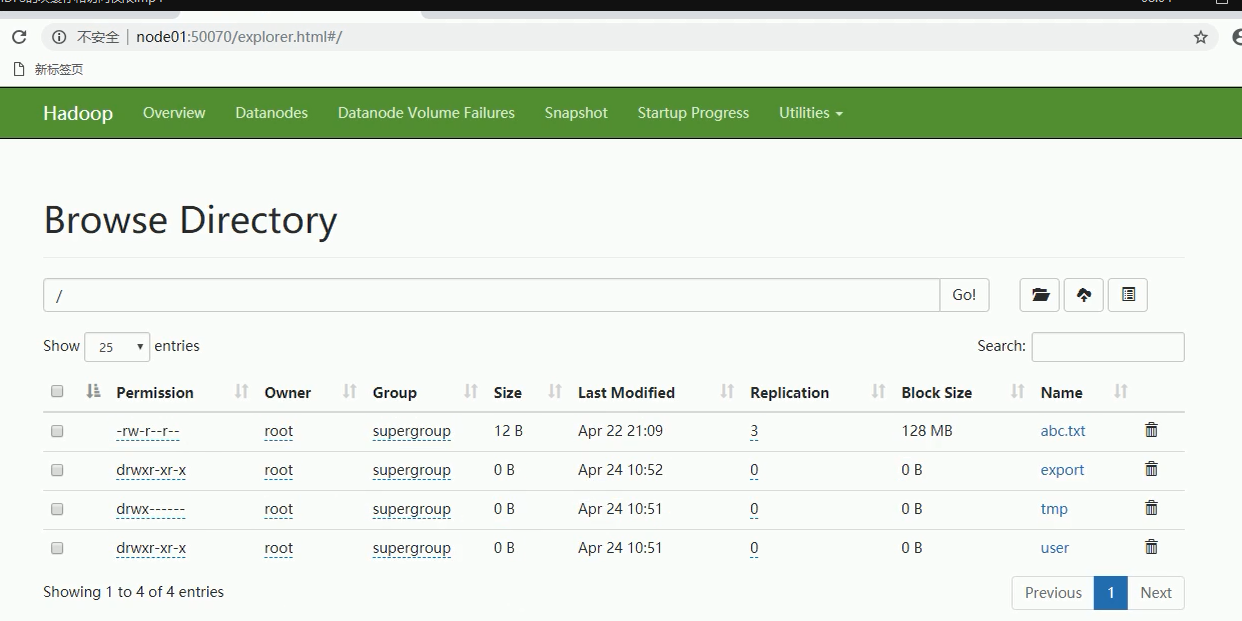
9-HDFS的页面操作
